









聚类分析法(Cluster Analysis) 是在多元统计分析中研究如何对样品(或指标)进行分类的一种统计方法,它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
聚类分析主要分为层次聚类,划分聚类和密度聚类。层次聚类方法(Hierarchical Clustering)就是通过对数据集按照某种方法进行层次分解,直到满足某种条件为止。原理就不多说了,我们今天主要来说下怎么使用R语言进行层次聚类分析,使用一个肉类数据,主要说的是27种肉类的营养数据,我们对它进行一个大致的分类,除此之外还需要NbClust、factoextra、igraph包,需先安装好。
我们先导入数据看一下
bc<-read.csv("E:/r/test/roulei.csv",sep=',',header=TRUE)
names(bc)
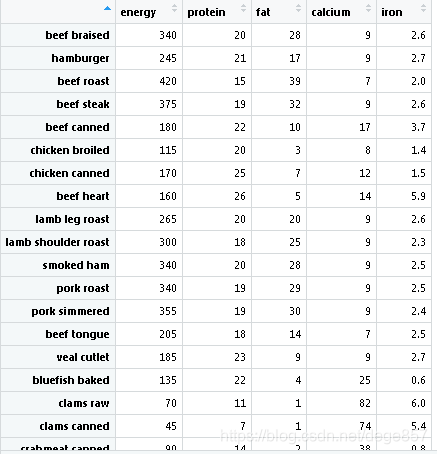
数据有5个参数,energy代表食物能量(卡路里),protein蛋白质,fat脂肪,calcium钙含量,iron铁含量,竖排是各种肉的名字,我就不一一解释了。
数据的变量差别很大,我们首先要把数据标准化,这样才有利于比较
bc.scaled<-scale(bc)##标准化数据
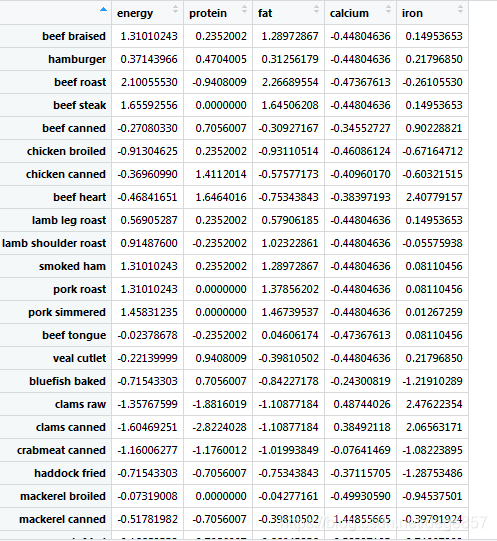
有了标准化数据我们就可以计算欧氏距离
d<-dist(bc.scaled)###计算欧氏距离
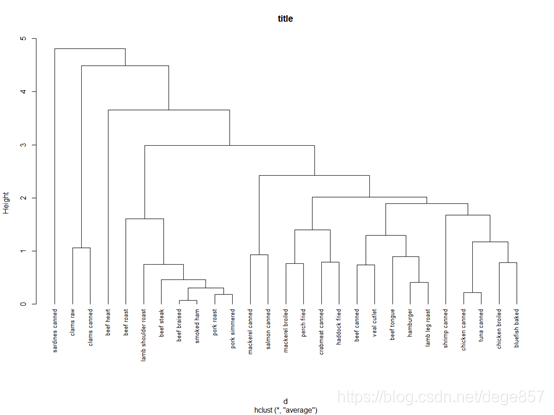
计算欧氏距离后我们就可以使用hclust函数进行层次聚类分析了
fit1<-hclust(d,method = "average")
plot(fit1,hang = -1,cex=.8,main = "title")
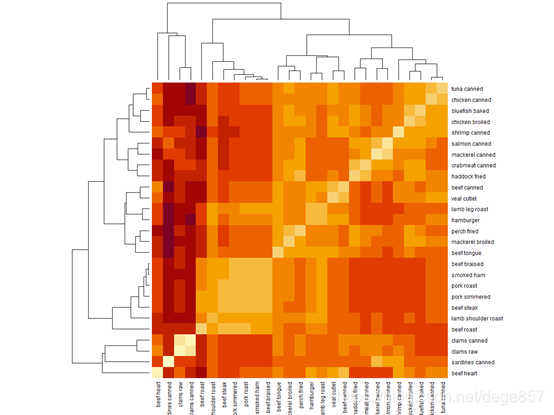
也可以使用热图的形式来表示
heatmap(as.matrix(d))
聚类分析中,聚类个数是比较重要的指标,我们可以使用NbClust包来进行投票
devAskNewPage(ask = T)
nc<-NbClust(bc.scaled,distance = "euclidean",min.nc = 2,max.nc = 15,
method = "average")
table(nc$Best.n[1,])
barplot(table(nc$Best.n[1,]),xlab = "No. of cluster")
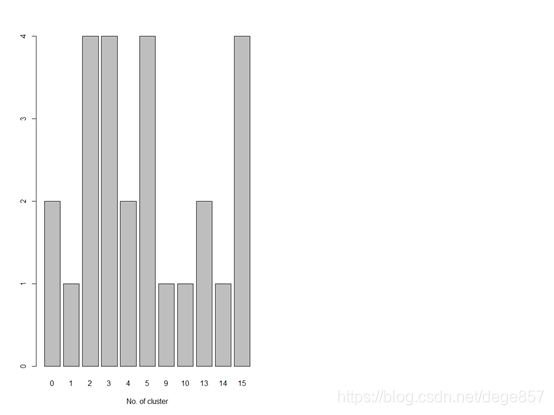
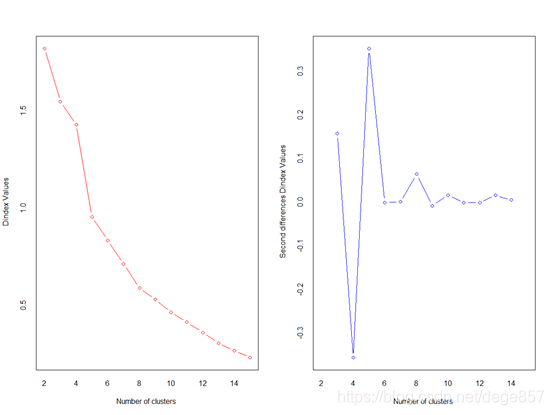
如上图所示分成4类有4个投票,2类有3个投票,结合上面两个图形,我们觉得分成4类是比较理想的。
得出了聚类的个数,我们可以使用factoextra,igraph包对它进行美化,首先画一张基础的分类图
library(factoextra)
library(igraph)
fviz_dend(fit1)
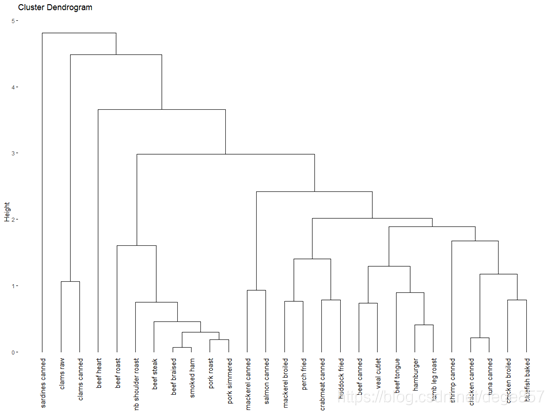
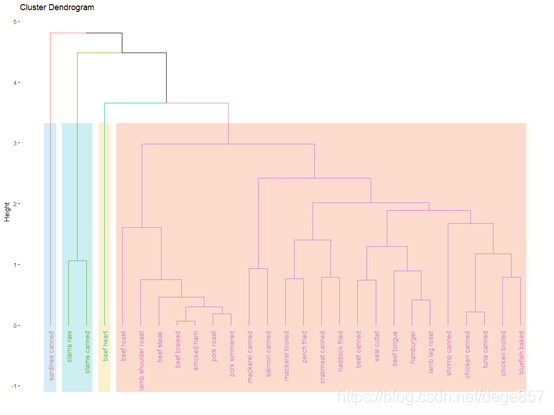
把它进行美化一下
fviz_dend(fit1,k=4,rect =T,rect_fill = T,
rect_border = c("#2E9FDF", "#00AFBB", "#E7B800", "#FC4E07"))##K为聚类个数,rect_border为区域颜色填充
添加语法horiz = TRUE可以把它变成横向
fviz_dend(fit1,k=4,rect =T,rect_fill = T,horiz = TRUE,
rect_border = c("#2E9FDF", "#00AFBB", "#E7B800", "#FC4E07"))
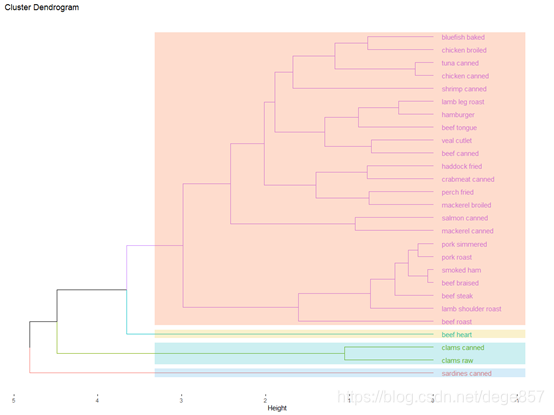
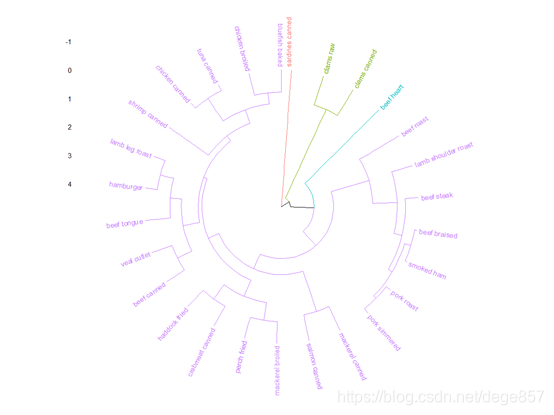
添加type = "circular"可以把它变成圆形的,好像最近很流行这种圆形的视图
fviz_dend(fit1,k=4,rect =T,rect_fill = T,type = "circular",
rect_border = c("#2E9FDF", "#00AFBB", "#E7B800", "#FC4E07"))
把type = "phylogenic"可以改成类似神经网络的视图
fviz_dend(fit1,k=4,rect =T,rect_fill = T,type ="phylogenic",
rect_border =c("#2E9FDF", "#00AFBB", "#E7B800", "#FC4E07"))

更多精彩文章请关注公众号:零基础说科研



















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











