







PRML学习总结之2——概率分布之一
本章主要介绍一些重要的概率分布,包括伯努利分布与二项分布,多项式分布,Beta分布,Dirichlet分布以及Gaussian分布。其中详细介绍了Gaussian分布。同时 介绍了指数家族(The Exponential Family)的一些性质。最后介绍了两种无参数的方法:核密度估计以及KNN。
基本的知识
1.先验分布(prior distribution)
即进行观察实验之前,凭借先验知识,假定的一个分布。
2.后验分布(posterior distribution)
进行观测试验后,根据观测值对先验分布修正后所得到的分布。其中根据Bayesian定理:
后验分布~先验*似然
3.共轭先验 (conjugate prior)
即先验分布与似然函数有相同的函数形式(下文具体讲解)。提出共轭先验的原因如下:通常我们利用Bayesian定理求解后验分布时,由于需要先验*似然函数,计算量往往很大,甚至会有无法求解的情况出现。但如果先验分布与似然函数有相同的函数形式,计算后验分布就十分简单了。
4.含参数方法(parameteric method)与无参数方法(non-parameteric method)
主要是指概率分布是否由一些参数控制,如Gaussian分布(由 μ 、 σ 控制 ),故为含参分布,利用Gaussian分布所使用的方法即为含参方法);无参方法则如KNN,其不受参数控制。
伯努利分布(Bernouli Distribution)与贝塔分布(Beta Distribution)
之所以将两个分布放在一起是因为两者为共轭先验分布,从下面分析可以看出。
1.Bernouli Distribution
假设抛一枚硬币,记为事件 X,正面朝上(X = 1)的概率为 μ , 则反面朝上(X= 0)的概率为 1−μ 。这样X就服从伯努利分布, 记作:
现在假设有随机样本集 D={x1,...xN} 相互独立,且都服从伯努利分布,我们可以很容易写出似然函数:
通过计算可以得到参数 μ 的似然估计值为:
若对抛硬币做N次独立重复试验,假设有m次正面朝上,则该分布变为了二项分布(binomial distribution),记作:
2.Beta Distribution
上部分讲到伯努利分布,并且用最大似然估计估计出了参数,我们在第1章的时候就已经了解到最大似然估计很容易出现过拟合的现象。 并且用Bayesian的方法可以有效的解决这一问题,但Bayesian方法虽好,由于需要假设先验分布,并且要计算与似然函数的乘积,因此十分复杂。有没有什么方法可以解决这一问题呢?答案是肯定的,我们前面提到过共轭先验的问题。只要先验分布与似然函数形式相同,计算量便可以大大降低,基于伯努利分布的似然函数的形式,我们引入Beta分布作为参数 μ 的先验分布,记作:
其中 Γ(x)=∫∞0μx−1e−μdu 成为伽马函数, a,b 一般被称作超参数(hyperparameter)
Beta函数的期望与方差为:
得到先验分布后,根据Bayesian定理,我们可以很容易求出后验分布,假设前面提及的样本集D中,正面朝上即( xi=1) 的个数为m, 反面朝上即( xi=0 )的个数为 l=N−m ,则后验分布有这样的形式:
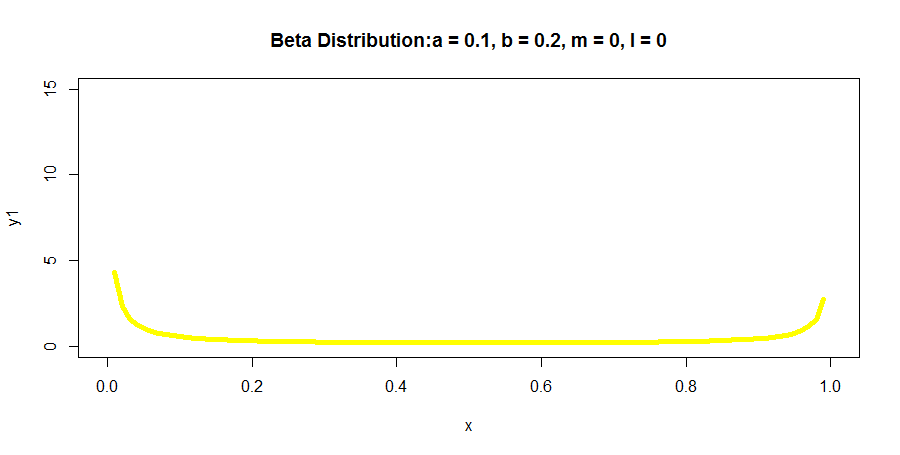
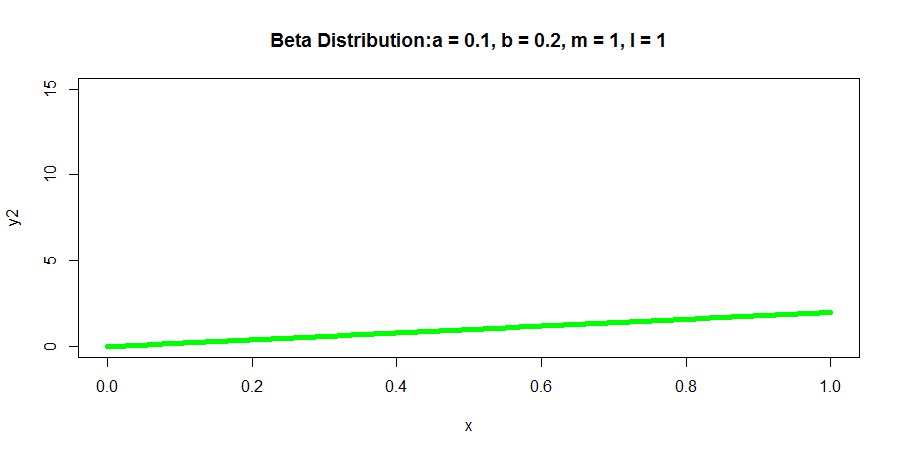
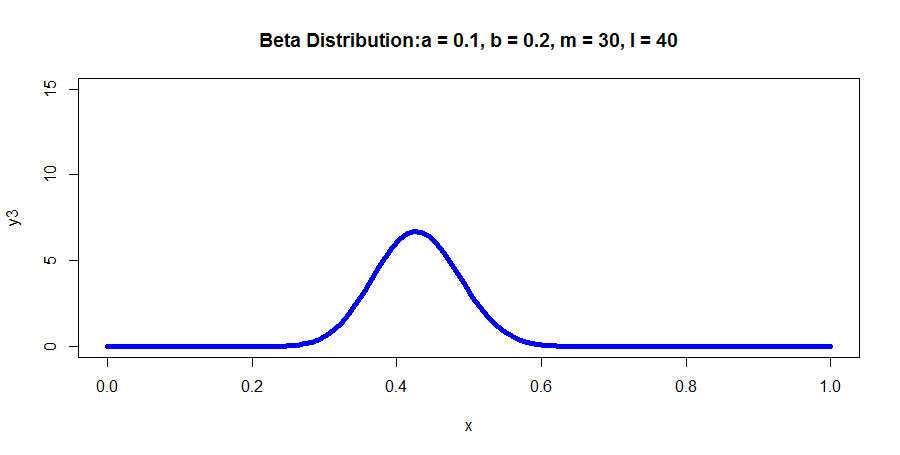
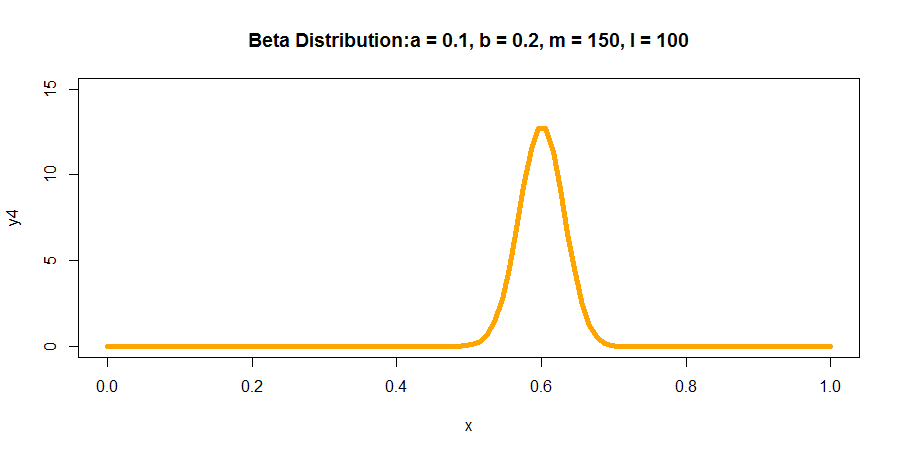
R语言代码如下所示:
plotBeta <- function(){
#生成序列点
x = seq(0, 1, length.out = 100)
#生成4个图形的y值
y1 <- dbeta(x, 0.1, 0.2)
y2 <- dbeta(x, 2, 1)
y3 <- dbeta(x, 30, 40)
y4 <- dbeta(x, 150, 100)
#绘制图形
plot(x, y1, col = "yellow", xlim = c(0,1), ylim = c(0,15), type = 'l',
lwd = 5, main = "Beta Distribution:a = 0.1, b = 0.2, m = 0, l = 0")
plot(x, y2, col = "green", xlim = c(0,1), ylim = c(0,15), type = 'l',
lwd = 5, main = "Beta Distribution:a = 0.1, b = 0.2, m = 1, l = 1")
plot(x, y3, col = "blue", xlim = c(0,1), ylim = c(0,15), type = 'l',
lwd = 5, main = "Beta Distribution:a = 0.1, b = 0.2, m = 30, l = 40")
plot(x, y4, col = "orange", xlim = c(0,1), ylim = c(0,15), type = 'l',
lwd = 5, main = "Beta Distribution:a = 0.1, b = 0.2, m = 150, l = 100")
}多项式分布(Multinominal Distribution)与狄利赫雷分布(Dirichlet Distribution)
1. 多变量伯努利分布与多项式分布
满足伯努利分布的随机变量只能有2种状态(binary variabal),但实际生活中往往有多种状态的情况存在,下面我们来考虑多种状态下的伯努利分布。为方便考虑应用1-of-K scheme,这种表示方法将随机变量用K维向量表示,假设该变量处于第i种状态,则 xi=1 ,向量中其他元素为0。举个例子,假设一个离散的随机变量x有5种状态(记作 x1,...,x5 ),且目前处于第2种状态,则 x=(0,1,0,0,0)T 。则x的分布可以表示为:
同样利用最大似然估计来估计参数的值,可以得到:
2. 狄利赫雷分布
和上文描述的一致,若要计算后验分布,就必须假设先验分布,同样利用共轭先验的特性,我们找到了可以作为先验分布的狄利赫雷分布,它与多变量伯努利分布的似然函数有相同的形式,其具体的函数表达如下:
同样利用Bayesian定理,可得到后验分布:
实际上来说,Beta分布与狄利赫雷分布形式上有很大的相似性,只是随机变量的状态数不同。而当把狄利赫雷分布的状态数当做2,也就变为了Beta分布。















 8196
8196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









