









 该文详细介绍了如何使用Keras训练深度学习网络对足球比赛中的白队、蓝队和裁判进行分类。首先,通过预处理和数据集划分构建模型,然后利用Keras构建网络结构并训练。接着,讨论了模型转换成ONNX格式以供C#应用程序使用。此外,还提到了YOLOv7在目标检测中的应用,以及如何配置和标注数据。最后,展示了如何在C#中集成ONNX模型进行人员分类预测。
该文详细介绍了如何使用Keras训练深度学习网络对足球比赛中的白队、蓝队和裁判进行分类。首先,通过预处理和数据集划分构建模型,然后利用Keras构建网络结构并训练。接着,讨论了模型转换成ONNX格式以供C#应用程序使用。此外,还提到了YOLOv7在目标检测中的应用,以及如何配置和标注数据。最后,展示了如何在C#中集成ONNX模型进行人员分类预测。
一、基础概念
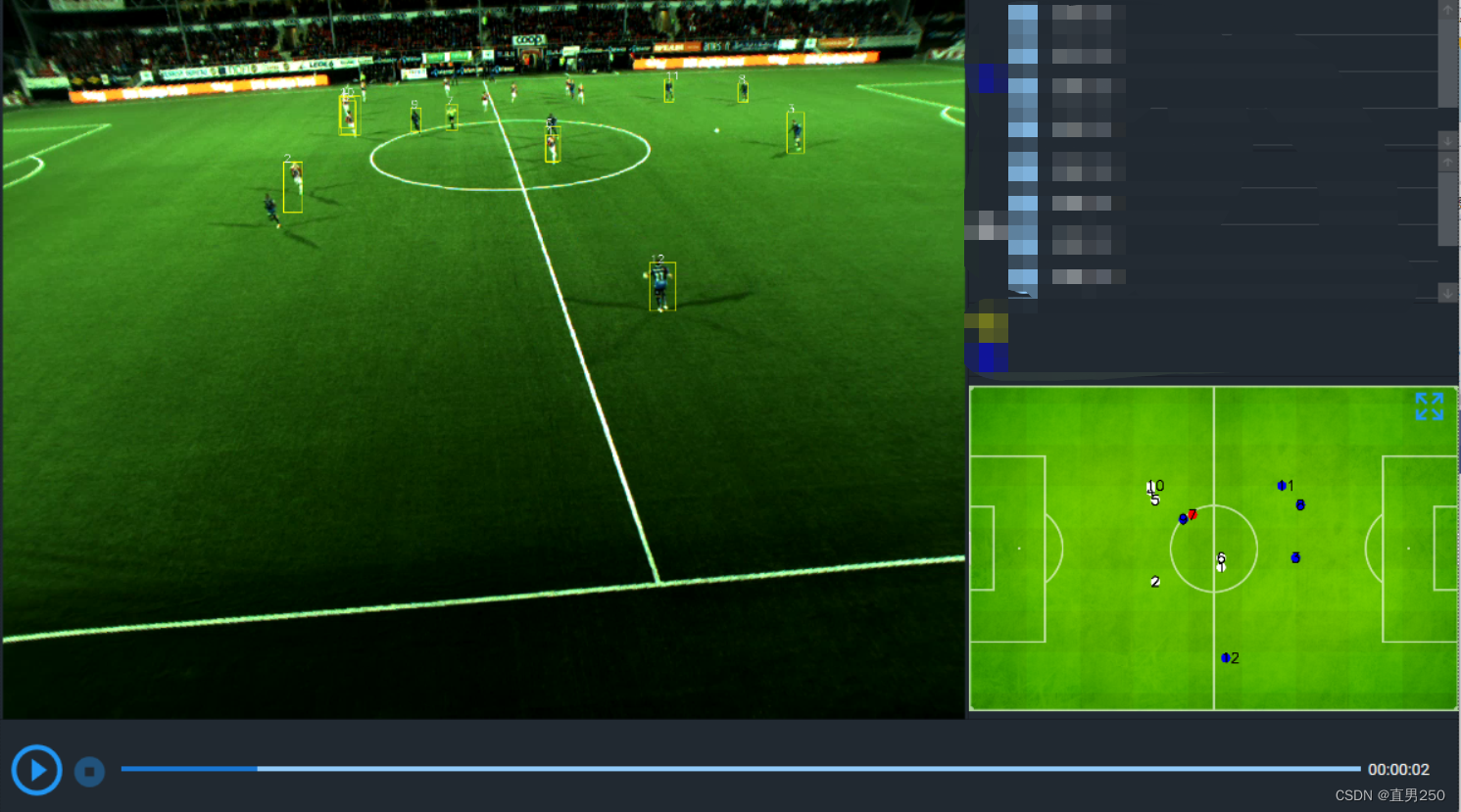
足球比赛中人员为:A队11人、B队11人、裁判,其中我们暂时不研究守门员。
需要将球场中的人员分类,并呈现在2D看板中。
1.1识别目标:
1)球场中的白队
2)球场中的蓝队
3)球场中的裁判
1.2 实现思路
方案一:自建深度学习网络Relu(主要介绍)
1)采用keras训练深度网络形成H5模型文件
2)H5文件转onnx文件
方案二:采用Yolo7训练网络
工程应用
二、训练Keras网络
依赖python包
autopep8==1.5.4
certifi==2020.6.20
chardet==3.0.4
cycler==0.10.0
idna==2.10
kiwisolver==1.2.0
matplotlib==3.3.1
mercurial==5.5
numpy==1.19.1
opencv-python==4.5.1.48
packaging==20.4
pandas==1.1.1
Pillow==7.2.0
pycodestyle==2.6.0
pyparsing==2.4.7
PyQt5==5.14.2
PyQt5-sip==12.11.0
pyqtgraph==0.11.0
python-dateutil==2.8.1
pytz==2020.1
requests==2.24.0
requests-cache==0.5.2
sip==5.4.0
six==1.15.0
toml==0.10.2
urllib3==1.25.11
依赖环境
Python 3.8 、 tensoflow 2.0(含keras)、
2.1 Python网络模型
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
import numpy as np
from keras.datasets import mnist
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
import os
import glob
import cv2
from google.colab.patches import cv2_imshow
import base64
from IPython.display import clear_output, Image
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
print(
'\n\nThis error most likely means that this notebook is not '
'configured to use a GPU. Change this in Notebook Settings via the '
'command palette (cmd/ctrl-shift-P) or the Edit menu.\n\n')
raise SystemError('GPU device not found')
tf.__version__, keras.__version__
# LABELS
BLUE, WHITE, REF = 0, 1, 2
def reading_files(path, label):
files = glob.glob(path)
data, labels = [], []
for file in files:
I = cv2.imread(file)
data.append(I)
l = np.zeros((3,))
l[label] = 1
labels.append(l)
return np.array(data, dtype=np.float32), np.array(labels, dtype=np.float32)
def load_data(shuffle=True):
X, Y = None, None
checker = lambda X, M: M if X is None else np.vstack([M, X])
for path, label in (("./blue/*.jpg", BLUE),
("./white/*.jpg", WHITE), ("./referee/*.jpg", REF)):
data, labels = reading_files(path, label)
X = checker(X, data)
Y = checker(Y, labels)
if shuffle:
initial_shape_X, initial_shape_Y = X.shape, Y.shape
feature_count = np.prod(np.array([*X.shape[1:]]))
whole_d = np.hstack([X.reshape(X.shape[0], -1), Y])
np.random.shuffle(whole_d)
X = whole_d[:, :feature_count].reshape(initial_shape_X)
Y = whole_d[:, feature_count:]
return X, Y
def des_label(label):
i = np.argmax(label)
return ("BLUE", "WHITE", "REFEREE")[i]
X, Y = load_data()
X.shape, Y.shape
# showing one image
print(des_label(Y[0]))
cv2_imshow(X[0])
# train test split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.1,
shuffle=True,
random_state=41)
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train,
test_size=0.15,
shuffle=True,
random_state=41)
X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, X_val.shape, Y_val.shape
# preprocess
scaler = MinMaxScaler()
main_shape_X_train = X_train.shape
main_shape_X_test = X_test.shape
scaler_train = scaler.fit(X_train.reshape(X_train.shape[0], -1))
X_train = scaler.transform(X_train.reshape(X_train.shape[0], -1)).reshape(main_shape_X_train)
X_test = scaler.fit_transform(X_test.reshape(X_test.shape[0], -1)).reshape(*main_shape_X_test)
np.max(X_train[0].ravel()), np.min(X_train[0].ravel()), X_train.shape
def naive_inception_module(layer_in, f1=2, f2=2, f3=2):
# 1x1 conv
conv1 = keras.layers.Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in)
# 3x3 conv
conv3 = keras.layers.Conv2D(f2, (3,3), padding='same', activation='relu')(layer_in)
# 5x5 conv
conv5 = keras.layers.Conv2D(f3, (5,5), padding='same', activation='relu')(layer_in)
# 3x3 max pooling
pool = keras.layers.MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in)
# concatenate filters, assumes filters/channels last
layer_out = keras.layers.concatenate([conv1, conv3, conv5, pool], axis=-1)
return layer_out
input_layer = keras.layers.Input([*X_train.shape[1:]])
second_layer = keras.layers.Conv2D(20, 5, padding="same")(input_layer)
th_layer = keras.layers.Activation("relu")(second_layer)
inception = naive_inception_module(th_layer)
inception = naive_inception_module(inception)
fo_layer = keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(inception)
fi_layer = keras.layers.Flatten()(fo_layer)
x_layer = keras.layers.Dense(250,
kernel_initializer=keras.initializers.HeNormal(),
kernel_regularizer=keras.regularizers.L1())(fi_layer)
s_layer = keras.layers.Activation(keras.activations.relu)(x_layer)
e_layer = keras.layers.Dropout(rate=0.5)(s_layer)
n_layer = keras.layers.Dense(100,
kernel_initializer=keras.initializers.HeNormal(),
kernel_regularizer=keras.regularizers.L1())(e_layer)
t_layer = keras.layers.Activation(keras.activations.relu)(n_layer)
ee_layer = keras.layers.Dropout(rate=0.5)(t_layer)
out_layer = keras.layers.Dense(3, activation="softmax")(ee_layer)
model = keras.models.Model(inputs=input_layer, outputs=out_layer)
model.summary()
# model lenet 5 or vgg-16
def make_model(input_shape, output_dim):
layers = []
# init_kernel = lambda shape, dtype=tf.int32: tf.random.normal(shape, dtype=dtype)
layers.append(keras.layers.Input(input_shape))
layers.append(keras.layers.Conv2D(20, 5, padding="same", input_shape=input_shape))
layers.append(keras.layers.Activation("relu"))
layers.append(keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
layers.append(keras.layers.Conv2D(20, 5, padding="same"))
layers.append(keras.layers.Activation("relu"))
layers.append(keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
layers.append(keras.layers.Conv2D(10, 5, padding="same"))
layers.append(keras.layers.Activation("relu"))
layers.append(keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
layers.append(keras.layers.Flatten())
layers.append(keras.layers.Dense(80,
kernel_initializer=keras.initializers.HeNormal(),
kernel_regularizer=keras.regularizers.L1()))
layers.append(keras.layers.Activation(keras.activations.relu))
layers.append(keras.layers.Dropout(rate=0.5))
layers.append(keras.layers.Dense(50,
kernel_initializer=keras.initializers.HeNormal(),
kernel_regularizer=keras.regularizers.L1()))
layers.append(keras.layers.Activation(keras.activations.relu))
layers.append(keras.layers.Dropout(rate=0.5))
layers.append(keras.layers.Dense(output_dim, activation="softmax"))
model = keras.models.Sequential(layers)
model.summary()
return model
model = make_model(input_shape=[*X_train.shape[1:]], output_dim=3)
# compiling
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.categorical_crossentropy,
metrics=["accuracy"])
datagen = ImageDataGenerator( # data augmentation
rotation_range=30,
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2,
fill_mode='nearest')
batch_size = 128
history = model.fit(datagen.flow(X_train, Y_train, batch_size=batch_size),
validation_data=(X_val, Y_val),
steps_per_epoch=len(Y_train) // batch_size, epochs=50, workers=6)
plt.figure(figsize=(15, 10))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.legend()
plt.grid(True)
plt.show()
history.history.keys()
model.evaluate(X_test, Y_test)
pred = model.predict(X_test)
np.argmax(pred, axis=1), Y_test
# apply my test
I = cv2.imread("./my_test/referee.png")
I1 = cv2.imread("./my_test/referee1.png")
I2 = cv2.imread("./my_test/white.png")
I = cv2.resize(I, (80, 80))
I1= cv2.resize(I1, (80, 80))
I2= cv2.resize(I2, (80, 80))
cv2_imshow(I1)
cv2_imshow(I)
print(I.shape, I.reshape(1, -1).shape)
X_my_test = np.vstack([[I], [I1], [I2]])
Y_my_labels = np.vstack([np.array([0, 1, 0]),
np.array([0, 0, 1]),
np.array([0, 0, 1])])
pred = model.predict(X_my_test)
print(X_my_test.shape, Y_my_labels.shape)
np.argmax(pred, axis=1), pred
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model.h5")
因深度学习核心是数据标注,标注的数据无法提供大家自行准备。
准备数据可参见《足球视频AI(三)——YOLOV7目标检测自训练模型》
生成《model.h5》《model.json》文件
2.2 Keras模型H5转Onnx
参见《AI机器学习(五)Keras h5转onnx C# ML 推理》
三、训练YoloV7网络
准备数据可参见《足球视频AI(三)——YOLOV7目标检测自训练模型》
3.1 配置项修改
1,predefined_classes.txt
“BLUE”, “WHITE”, “REFEREE”
索引值:0,1,2
2,coco.yaml
设置 nc:3
设置 names:[‘BLUE’,‘WHITE’,‘REFEREE’]
3,yolov7.yaml
设置 ‘nc:3‘
3.2 标注说明
帧图像标记三种类别,尽量将所有出现的人都标记出来,包括裁判、蓝队、白队
四、Keras模型的工程应用
YoloV7的模型应用,参见《足球视频AI(三)——YOLOV7目标检测自训练模型》
4.1 定义接口
public interface IClassific
{
bool UseClassic { get; set; }
/// <summary>
/// 加载模型
/// </summary>
void LoadModel();
/// <summary>
/// 预测
/// </summary>
/// <param name="inputs">多枚图像80x80的rgb</param>
/// <returns>分类结果</returns>
NDarray Predict(NDarray? inputs);
}
4.2 应用模型
public class ClassificWithOnnx : IClassific
{
private InferenceSession? session;
public ClassificWithOnnx(bool useClassic)
{
UseClassic = useClassic;
if (useClassic)
LoadModel();
}
public bool UseClassic { get; set; }
/// <summary>
/// <inheritdoc/>
/// </summary>
public void LoadModel()
{
session = new InferenceSession(Path.Combine(System.AppDomain.CurrentDomain.BaseDirectory, "Assets/model.onnx"));
}
/// <summary>
/// <inheritdoc/>
/// </summary>
public NDarray Predict(NDarray? inputs)
{
var inputTensor = inputs?.ToDenseTensor();
var input = new List<NamedOnnxValue> { NamedOnnxValue.CreateFromTensor<float>("input_11", inputTensor) };
var outputs = session?.Run(input).ToList().Last().AsEnumerable<float>().ToArray();
var outputarray = np.array<float>(outputs!);
var arr = outputarray.reshape(inputs!.shape.Dimensions[0], 3);
arr = np.argmax(arr, axis: 1);
return arr;
}
}
其中推理的首个网络层名字"input_11"查看方法及静态方法定义,参见《AI机器学习(五)Keras h5转onnx C# ML 推理》
4.3 人员分类
依赖《足球视频AI(二)——球员与球的目标检测》,先检测到人员,将人员的Bound图像裁剪,传递给分类函数。
[Fact]
public void TestPlayerClassific()
{
Mat roi;
NDarray? rois = null;
NDarray? labels = null;
List<YoloPrediction> lst;
var detector = new DetectorYolov7();
var classificor = new ClassificWithOnnx(true);
using (var mat = LoadImages.Load("field_2.jpg"))
{
lst = detector.Detect(mat);
lst.ForEach(prediction => {
var rect = prediction.Rectangle;
roi = new Mat(frame, GetBoundSize(rect,frame)).Clone();
roi = roi.Resize(new OpenCvSharp.Size(80, 80));
//添加待识别对象,供批量预测对象类型使用
var ndarray = roi.ToNDarray();
if (null == rois)
rois = ndarray;
else
rois = np.concatenate((rois, ndarray));
labels = classificor.Predict(rois);
}
}
Assert.True(labels?.item<int>(0)>=0);
}

















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









