







目录
一、前言
1.排序算法的分类
排序算法算是我们接触算法的第一课,排序算法在我们的生活中也无处不在,它也分成很多类

我们在本次将会探讨插入排序,在我的专栏里面也会有其他排序的讲解,本次我们先讲最基础的插入排序。
2.插入排序的直观理解

斗地主大家都打过吧,整理牌序的时候是不是得有一个过程,插入排序就类似这个过程,将较小的牌依次与前面的牌比较,然后找到合适的位置插入。
二、直接插入排序 (InsertSort)
1.思路
借助上面斗地主的思路,我们可以了解到插入排序的基本过程,那么作为
2.代码实现
嵌套两层循环,一层找要插入的牌,一层找插入位置
//逆序O(N^2) 最坏情况
//顺序O(N)
//插入排序
void InsertSort(int* a, int n) {
for(int i=0;i<n-1;++i){
int end=i;
int tmp = a[end + 1];
//若前面都大于插入数,end会走到-1
while (end >= 0) {
if (tmp < a[end]) {
a[end + 1] = a[end];
--end;
}
else
break;
}
a[end + 1] = tmp;
}
}3.复杂度分析
最坏的情况就是逆序排列,每个数都要遍历到最前面才可插入,这样时间复杂度大致为
最好的情况为顺序,每个数据在插入的时候和前一个数据比就可以找到位置,时间复杂度为
由于插入排序是原地排序,空间复杂度为
三、希尔排序 (ShellSort)
1.什么是希尔排序 & 为什么会有希尔排序
(1)希尔排序介绍
希尔排序(Shell's Sort)是插入排序的一种又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因 D.L.Shell 于 1959 年提出而得名。
(2)为什么会有希尔排序
<1> 改进插入排序的性能:插入排序在对大规模、基本无序的数据进行排序时效率较低,因为它每次只能将一个元素插入到已排序的序列中,并且在最坏情况下的时间复杂度为O(n²)。希尔排序通过引入“间隔”来比较和交换元素,可以大大减少数据移动的次数,从而提高效率。
<2> 引入间隔排序概念:希尔排序通过将数组分成若干子序列进行排序,每个子序列包含相隔一定间隔的元素。随着排序的进行,间隔逐渐减小,最终进行一次标准的插入排序。通过这种方式,希尔排序能够在初期快速减少无序程度,后期再进行精细排序,从而提高整体排序效率。
<3>减少逆序对:在希尔排序的每一轮中,由于是跨越式的插入排序,能够有效地减少逆序对(即正序元素对),这些逆序对是排序中需要调整的主要目标。随着增量的减少,整个数组逐渐接近全局有序。
(3)希尔排序实现思路
希尔排序的实现分为两个步骤,第一是预排序(希尔排序的精髓),第二是直接插入排序
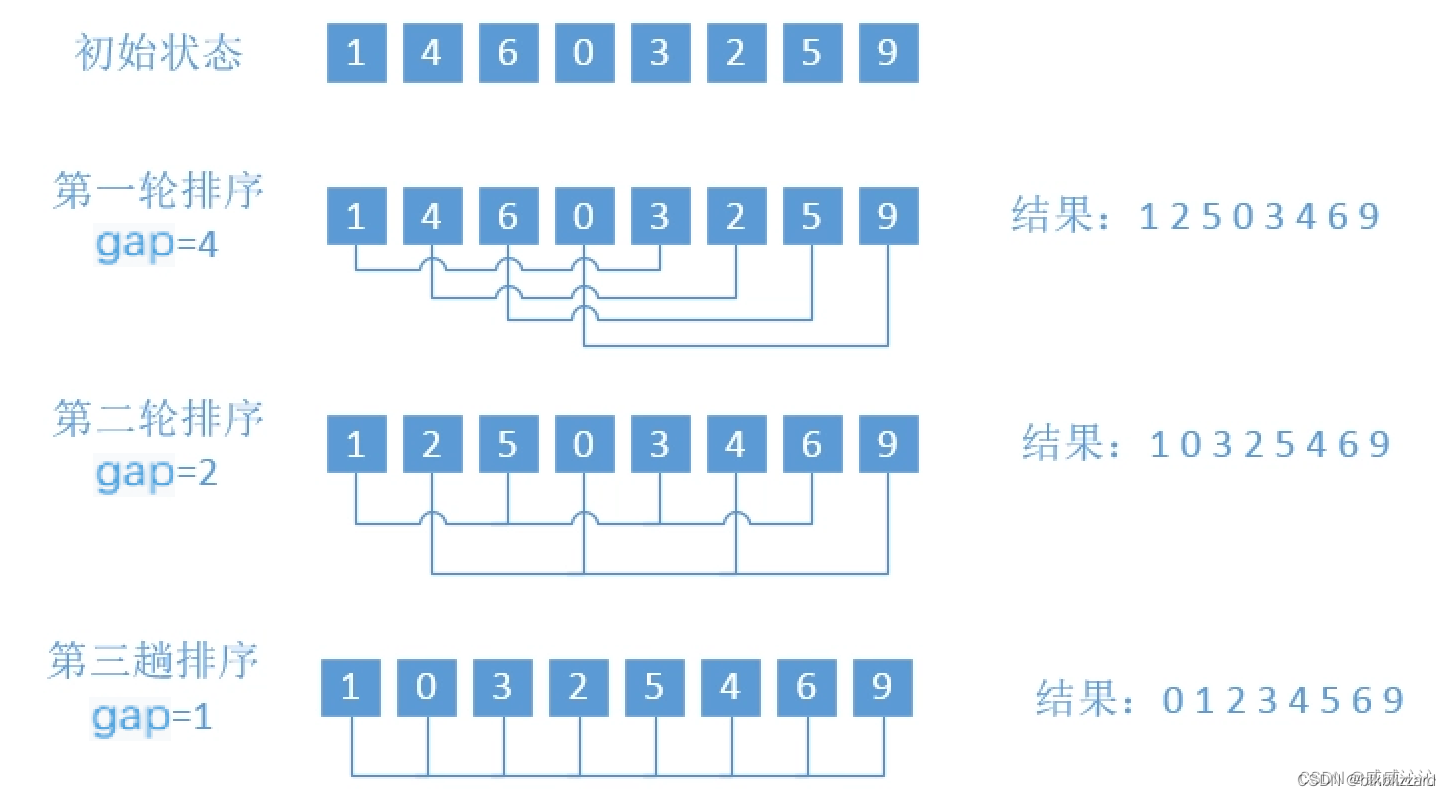
<1>预排序
为了达到分成若干子序的作用,我们需要设置一个gap,用来设置子序列中数据之间的间距。
这里的gap可以有不同的设置方法,gap在一轮希尔排序中不断缩小的值形成的序列我们称为增量序列,不同的增量序列的效率也不同,为我们在后面的优化部分会讲。
我这次使用的gap的变化为 { 3,2,1 }
<2>直接插入排序
预排序结束之后就是直接插入排序,经过预排序之后,直接插入排序的性能会大大提高。
2.代码实现
//希尔排序
void ShellSort(int* a, int n) {
int gap = 3;
//gap>1时为预排序
while(gap>1){
gap = gap / 3+1;
for (int i = 0; i < n - gap; ++i) {
int end = i;
int tmp = a[end + gap];
//若前面都大于插入数,end会走到-1
while (end >= 0) {
if (tmp < a[end]) {
a[end + gap] = a[end];
end -= gap;
}
else
break;
}
a[end + gap] = tmp;
}
}
}3.希尔排序算法的增量序列(优化)及其时间复杂度
我们已经知道了希尔排序的思路,其实希尔排序本就是指一种优化插入排序的思路。
根据我们前面所述,在希尔排序的体系下,设置不同的增量序列可以让排序的性能各不相同,也就为后来前仆后继的算法研究者莫大的空间去探索。
下面我将列举一些重要的增量序列及其时间复杂度供大家参考,也让大家直观地看看希尔排序到底比直接插入排序好在哪里,好了多少。
1. Shell 增量序列
- 序列:
- 时间复杂度: 最差情况下为
- 描述: 这是希尔排序最初提出时使用的序列。虽然简单,但不是最有效的,因为它在某些情况下仍然会导致较大的逆序对。
2. Hibbard 增量序列
- 序列:
- 时间复杂度: 最坏情况
- 描述: Hibbard 提出的序列通过保证每次都是以前一次的两倍加一的形式递增,可以避免某些大的逆序对。
3. Knuth 增量序列
- 序列:
- 时间复杂度: 平均情况
- 描述: 这是Donald Knuth提出的序列,它通过不断乘以3并加一来生成,直到序列中的数字超过排序数组的长度。
4. Sedgewick 增量序列
- 序列:
- 时间复杂度: 最坏情况
或
- 描述: Sedgewick 提出了几种不同的序列,设计目的是进一步减少在排序过程中的比较和移动次数。
5. Tokuda 增量序列
- 序列:
- 时间复杂度: 估计平均情况
- 描述: Tokuda 通过一个特定的数学公式来计算这个序列,旨在进一步优化希尔排序的性能。
6. Ciura 增量序列
- 序列:
- 时间复杂度: 经验序列,未详细分析
- 描述: Marcin Ciura的增量序列是基于实验数据的,其序列只列出了部分值,其余部分通常是前一个值的2.25倍。
四、总结
希尔排序的时间复杂度大致可以记为
插入排序是我们排序的开端,这是一场极大的连续剧,继续学习吧,要是你以后也去研究算法,说不定重心可以放在希尔排序上面

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









