







1 ) d ( x , y ) ≥ 0 , x , y ∈Ω ;
2 ) d ( x , y ) = 0 当且仅当 x = y ;
3 ) d ( x , y ) = d ( y , x ) , x , y ∈Ω ;
4 ) d ( x , y ) ≤ d ( x , z ) + d ( z , y ) , x , y , z ∈Ω 。
这一距离的定义是我们所熟知的,它满足正定性,对称性和三角不等式。在聚类
分析中,对于定量变量,最常用的是 Minkowski 距离

当 q = 1,2 或 q → +∞ 时,则分别得到


2.3byshev 距离

在 Minkowski 距离中,最常用的是欧氏距离,它的主要优点是当坐标轴进行正交
旋转时,欧氏距离是保持不变的。因此,如果对原坐标系进行平移和旋转变换,则变换
后样本点间的距离和变换前完全相同。
值得注意的是在采用 Minkowski 距离时,一定要采用相同量纲的变量。如果变量
的量纲不同,测量值变异范围相差悬殊时,建议首先进行数据的标准化处理,然后再计
算 距 离 。 在 采 用 Minkowski 距 离 时 , 还 应 尽 可 能 地 避 免 变 量 的 多 重 相 关 性
( multicollinearity )。多重相关性所造成的信息重叠,会片面强调某些变量的重要性。
由于 Minkowski 距离的这些缺点,一种改进的距离就是马氏距离,定义如下
2.4马氏( Mahalanobis )距离

其中 x , y 为来自 p 维总体 Z 的样本观测值, Σ 为 Z 的协方差矩阵,实际中 Σ 往往是不
知道的,常常需要用样本协方差来估计。马氏距离对一切线性变换是不变的,故不受量
纲的影响。
此外,还可采用样本相关系数、夹角余弦和其它关联性度量作为相似性度量。近年
来随着数据挖掘研究的深入,这方面的新方法层出不穷。



4.1最短距离法




又能够充分分离(即 D 12 很大),这时必然有 D = D 12 - D 1 - D 2 很大。因此,按定义可
以认为,两类 G 1 , G 2 之间的距离很大。离差平方和法最初是由 Ward 在 1936 年提出,
后经 Orloci 等人 1976 年发展起来的,故又称为 Ward 方法。
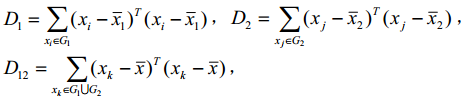

5.1 pdist函数
调用格式:Y=pdist(X,’metric’)
说明:用 ‘metric’指定的方法计算 X 数据矩阵中对象之间的距离。
X:一个m×n的矩阵,它是由m个对象组成的数据集,每个对象的大小为n(即n个特征值)。
metric’取值如下:
‘euclidean’:欧氏距离(默认);‘seuclidean’:标准化欧氏距离;
‘mahalanobis’:马氏距离;‘cityblock’:布洛克距离;
‘minkowski’:明可夫斯基距离;‘cosine’:
‘correlation’:
‘jaccard’:‘chebychev’:Chebychev距离。
5.2 squareform 函数
调用格式:Z=squareform(Y,..)
对于M个点的数据集X,pdist之后的Y将是具有M*(M-1)/2个元素的行向量。
Y这样的显示虽然节省了内存空间,但对用户来说不是很易懂,如果需要对这些距离进行特定操作的话,也不太好索引。MATLAB中可以用squareform把Y转换成方阵形式,方阵中<i,j>位置的数值就是X中第i和第j点之间的距离,显然这个方阵应该是个对角元素为0的对称阵。
5.3 linkage函数
调用格式:Z=linkage(Y,‘method’)
输入值说明:Y为pdist函数返回的M*(M-1)/2个元素的行向量,用‘method’参数指定的算法计算系统聚类树。
method:可取值如下:
‘single’:最短距离法(默认);
‘complete’:最长距离法;
‘average’:未加权平均距离法;
‘weighted’: 加权平均法;
‘centroid’:质心距离法;
‘median’:加权质心距离法;
‘ward’:内平方距离法(最小方差算法)
返回值说明:Z为一个包含聚类树信息的(m-1)×3的矩阵,其中前两列为索引标识,表示哪两个序号的样本可以聚为同一类,第三列为这两个样本之间的距离。另外,除了M个样本以外,对于每次新产生的类,依次用M+1、M+2、…来标识。
5.4 dendrogram函数
调用格式:[H,T,…]=dendrogram(Z,p,…)
说明:生成只有顶部p个节点的冰柱图(谱系图)。
为了表示Z矩阵,我们可以用更直观的聚类数来展示,方法为:dendrogram(Z), 产生的聚类数是一个n型树,最下边表示样本,然后一级一级往上聚类,最终成为最顶端的一类。纵轴高度代表距离列。
另外,还可以设置聚类数最下端的样本数,默认为30,可以根据修改dendrogram(Z,n)参数n来实现,1<n<M。dendrogram(Z,0)则表n=M的情况,显示所有叶节点。
5.5 cophenet函数
调用格式:c=cophenet(Z,Y)
说明:利用pdist函数生成的Y和linkage函数生成的Z计算cophenet相关系数。
cophene检验一定算法下产生的二叉聚类树和实际情况的相符程度,就是检测二叉聚类树中各元素间的距离和pdist计算产生的实际的距离之间有多大的相关性,另外也可以用inconsistent表示量化某个层次的聚类上的节点间的差异性。
5.6 cluster 函数
调用格式:T=cluster(Z,…)
说明:根据linkage函数的输出Z 创建分类。
5.7 clusterdata 函数
调用格式:T=clusterdata(X,…)
说明:根据数据创建分类。
When 0 < CUTOFF < 2, T = CLUSTERDATA(X,CUTOFF) is equivalent to:
Y = pdist(X, 'euclid');
Z = linkage(Y, 'single');
T = cluster(Z, 'cutoff', CUTOFF);
When CUTOFF is an integer >= 2, T = CLUSTERDATA(X,CUTOFF) isequivalent
to:
Y = pdist(X,'euclid');
Z = linkage(Y,'single');
T = cluster(Z,'maxclust',CUTOFF)
5.8 Inconsistent
S_i是除了叶节点外,所有深度低于(M+i)不超过DEPTH的节点(包括M+i节点自身)
而Inconsistent计算的是S_i的距离的平均值。
Then
Y(i,1) = mean(Z(S_i,3)), the mean height of nodes in S_i
Y(i,2) = std(Z(S_i,3)), the standard deviation of node heights in S_i
Y(i,3) = length(S_i), the number of nodes in S_i
Y(i,4) = (Z(i,3) - Y(i,1))/Y(i,2), the inconsistent value
The default value for DEPTH is 2.
计算深度会影响不一致系数的计算结果,计算深度比较大时,不一致系数的增量能反映出当前步引入的新样品与该类中心(涉及该类中所有样品)的距离远近,计算深度比较小时,不一致系数的增量仅能反映出当前步引入的新样品与上几步聚类中涉及的样品的中心的距离远近。















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









