






1.原理:
聚类分析是根据在数据中发现的描述对象及其关系的信息,将数据对象分组。目的是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内相似性越大,组间差距越大,说明聚类效果越好。
也就是说, 聚类的目标是得到较高的簇内相似度和较低的簇间相似度,使得簇间的距离尽可能大,簇内样本与簇中心的距离尽可能小
2.数据:
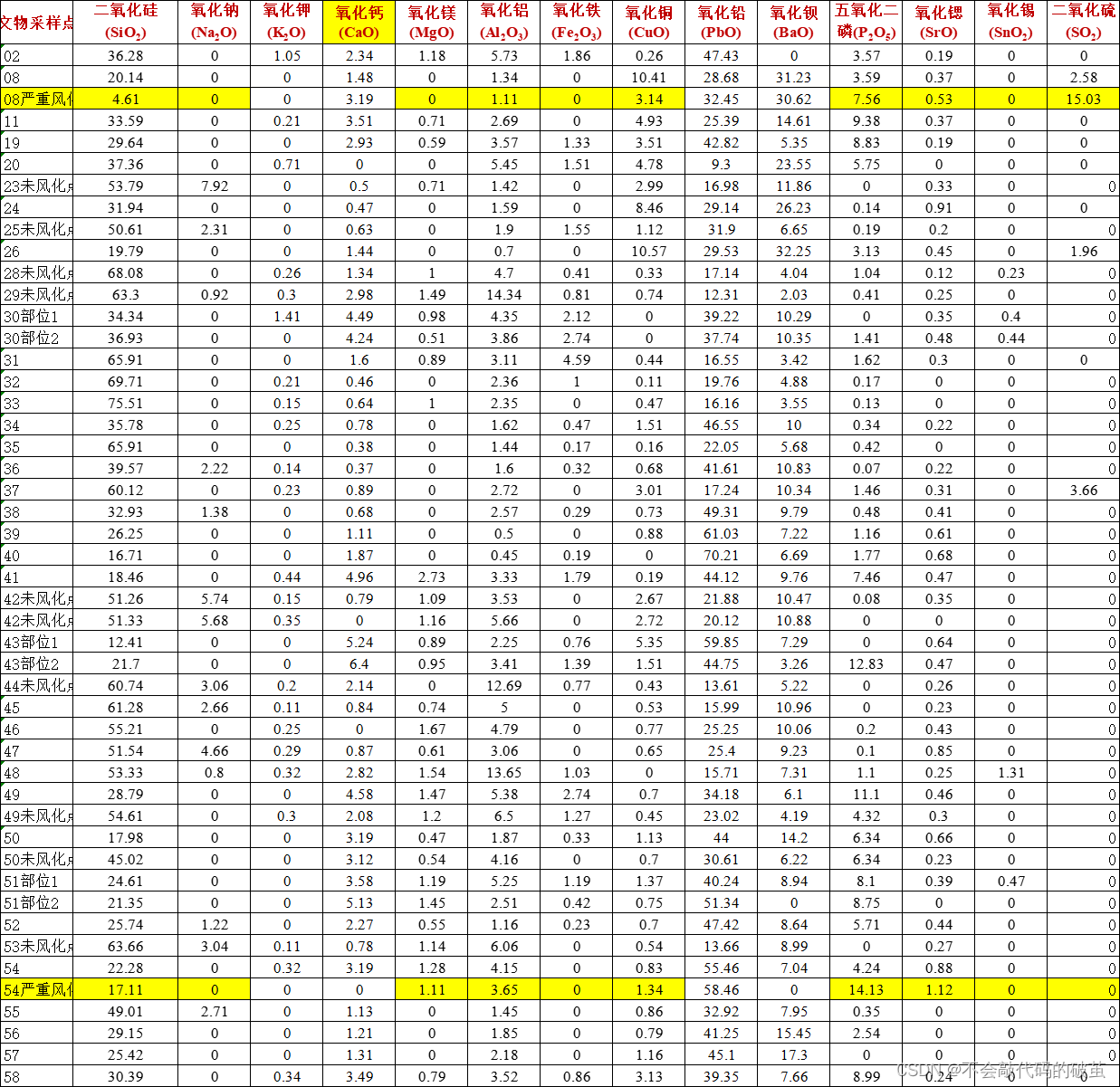
3.效果图:
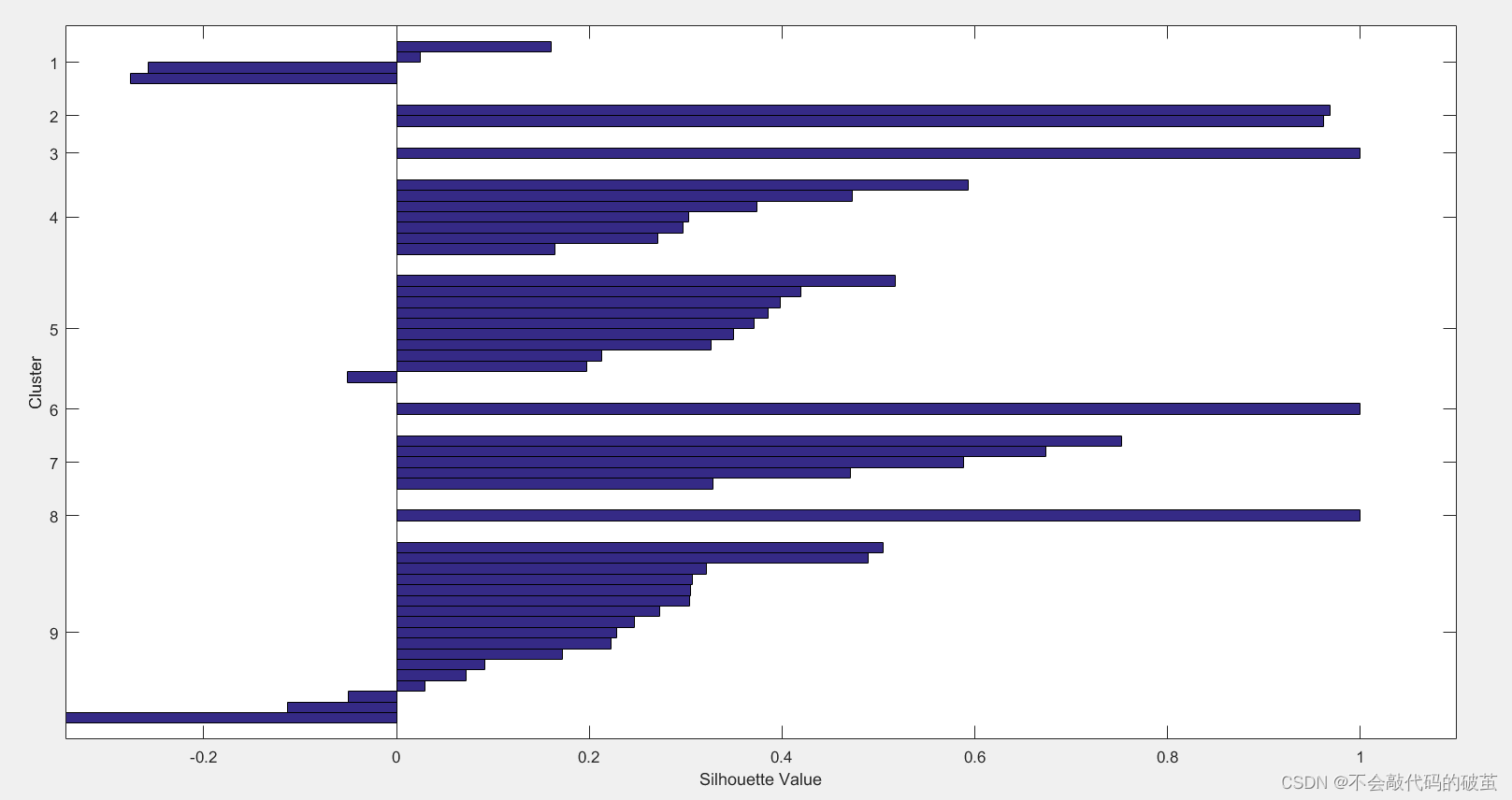
4.分类结果:
ans =
4×1 cell 数组
'02'
'29未风化点'
'30部位1'
'48'
ans =
2×1 cell 数组
'08'
'26'
ans =
cell
'08严重风化点'
ans =
7×1 cell 数组
'39'
'40'
'43部位1'
'50'
'52'
'54'
'54严重风化点'
ans =
10×1 cell 数组
'11'
'19'
'30部位2'
'41'
'43部位2'
'49'
'50未风化点'
'51部位1'
'51部位2'
'58'
ans =
cell
'20'
ans =
5×1 cell 数组
'23未风化点'
'42未风化点1'
'42未风化点2'
'47'
'53未风化点'
ans =
cell
'24'
ans =
17×1 cell 数组
'25未风化点'
'28未风化点'
'31'
'32'
'33'
'34'
'35'
'36'
'37'
'38'
'44未风化点'
'45'
'46'
'49未风化点'
'55'
'56'
'57'
5.分类代码:
function test9()
[data,textdata]=xlsread('F:\铅钡1');
X=zscore(data);%%把数据标准化
num=9;%%分类个数
startdata=(X([1 2 3 4 5 6 7 8 9],:));%%初始凝聚点
idx=kmeans(X,num,'start',startdata);%%进行k均值聚类
[S,H]=silhouette(X,idx);%%返回轮廓值
countryname=textdata(2:end,1);%%提取编号名称
countryname(idx==1)
countryname(idx==2)
countryname(idx==3)
countryname(idx==4)
countryname(idx==5)
countryname(idx==6)
countryname(idx==7)
countryname(idx==8)
countryname(idx==9)

















 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











