







上一篇文章中,我们了解到了Kafka中的特有术语以及topic的相关概念,详细内容可以参考 kafka学习笔记(二):理解Kafka集群与Topic。接下来我们将使用 Java 语言调用 Kafka的相关 API,今天首先了解一下对于Producer的相关操作。
添加依赖
首先我们添加maven依赖,包括下面两个依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.10.2.1</version>
</dependency>
基础知识
这里的producer或者cosumer实际是开发人员开发的程序,如果开发的程序用于发送消息到 Kafka,那么这个程序就是 Producer 生产者。如果开发的程序用于读取 Kafka 中的消息,那么这个程序就是 Consumer 消费者。Kafka 提供了 Java 客户端 API,开发者可以使用这些 API 开发应用程序,与 Kafka 交互。
producer 程序用于创建新消息,发送到 kafka 集群。在其他的消息系统中,producer 可能被称为 publisher 或者 writer。一般情况下,一个新消息会被生产者发送到到一个特定的 topic 上。默认情况下,producer 不关心消息发送到哪个 partition 上,producer 会使消息在所有的 partition 中均匀分布。
在某些情况下,producer 会将消息发送到特定的 partition 上(可以使用消息 key 和自定义 partitioner 用来生成 key 的 hash 值,从而将消息映射到一个特定的 partition 上)。开发向 kafka 发送消息的程序,主要会考虑以下几点:
- 发送的每条消息是否都很重要或者说是否可以接受消息的丢失?
- 可以接受偶尔收到重复的消息吗?
- 对消息延迟时间长短和吞吐量有严格的要求吗?
例如在银行交易系统中,对消息的要求是严格的,既不允许丢失消息也不允许重复收到消息,消息延迟要在 500 毫秒以内,需要每秒百万条消息的吞吐量(所有涉及到钱的场景中都类似)。另一种场景,比如存储网站的点击事件信息到 Kafka,此种场景,一些消息的丢失或者重复是可以接受的,消息延迟也可以很高,只要对用户体验没有影响就可以(比如说常见的创建订单后进行发短信的业务,可以允许发短信业务一定的延时)。不同的场景,不同的需求,会影响 producer API 的使用方式及配置方式。
开发 Producer 程序
实验开始前记得先启动 Kafka 集群,具体操作见实验一。我们将使用 Eclipse 开发工具开发 Producer 程序,发送消息到 Kafka。
首先需要创建 KafkaProducer 对象。KafkaProducer 对象需要 3 个必备的属性:bootstrap.servers、key.serializer、value.serializer。
在 MyFirstProducer 类的 main 方法中编写代码:
package com.bupt.kafka.producer;
/**
* @author melooo
* @date 2021/10/13 8:53 下午
*/
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class MyFirstProducer {
public static void main(String[] args) {
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
//向kafka集群发送消息,除了消息值本身,还包括key信息,key信息用于消息在partition之间均匀分布。
//发送消息的key,类型为String,使用String类型的序列化器
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//发送消息的value,类型为String,使用String类型的序列化器
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//创建一个KafkaProducer对象,传入上面创建的Properties对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(kafkaProps);
/**
* 使用ProducerRecord<String, String>(String topic, String key, String value)构造函数创建消息对象
* 构造函数接受三个参数:
* topic--告诉kafkaProducer消息发送到哪个topic;
* key--告诉kafkaProducer,所发送消息的key值,注意:key值类型需与前面设置的key.serializer值匹配
* value--告诉kafkaProducer,所发送消息的value值,即消息内容。注意:value值类型需与前面设置的value.serializer值匹配
*/
ProducerRecord<String, String> record = new ProducerRecord<>("mySecondTopic", "messageKey", "hello kafka");
try {
//发送前面创建的消息对象ProducerRecord到kafka集群
//发送消息过程中可能发送错误,如无法连接kafka集群,所以在这里使用捕获异常代码
producer.send(record);
producer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
启动命令行终端,依次运行如下命令:
# 进入kafka bin目录
cd /usr/local/Cellar/kafka/2.6.0/bin
#启动命令行消费者,消费前面Java开发的生产者发送到mySecondTopic上的消息
./kafka-console-consumer --bootstrap-server localhost:9092 --topic mySecondTopic
运行 MyFirstProducer java 类,然后查看启动 kafka-console-consumer 的命令行终端,可以看到发送消息打印到了命令行终端上。运行结果如图所示:

可以看出,通过设置 Properties 对象的不同参数,可以完成对 producer 对象的控制。Kafka 官方文档中列出了所有的配置参数,请自行查看。上述代码片段实例化了一个 producer,接着调用 send() 方法发送消息。
有三个主要方法用来发送消息:
- Fire-and-forget(发送即忘记):此方法用来发送消息到 broker,不关注消息是否成功到达。大部分情况下,消息会成功到达 broker,因为 Kafka 是高可用的,并且 producer 会自动重试发送。但是,还是会有消息丢失的情况;本实验用的就是这种方法。
- Synchronous Send(同步发送):发送一个消息,send() 方法返回一个 Future 对象,使用此对象的 get() 阻塞方法,可以根据 send() 方法是否执行成功来做出不同的业务处理。此方法关注消息是否成功到达,但是由于使用了同步发送,消息的发送速度会很低,即吞吐量降低。
- Asynchronous Send(异步发送):以回调函数的形式调用 send() 方法,当收到 broker 的响应,会触发回调函数执行。此方法既关注消息是否成功到达,又提高了消息的发送速度。
同步发送
创建名称为 MySecondProducer 的 java 类,然后在 MySecondProducer 类的 main 方法中编写代码:
package com.bupt.kafka.producer;
/**
* @author melooo
* @date 2021/10/13 9:07 下午
*/
import java.util.Properties;
import java.util.concurrent.Future;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class MySecondProducer {
public static void main(String[] args) {
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(kafkaProps);
ProducerRecord<String, String> record =new ProducerRecord<>("mySecondTopic", "messageKey", "hello kafka");
try {
Future<RecordMetadata> future = producer.send(record);
//producer的send方法返回Future对象,我们使用Future对象的get方法来实现同步发送消息。
//Future对象的get方法会产生阻塞,直到获取kafka集群的响应,响应结果分两种:
//1、响应中有异常:此时get方法会抛出异常,我们可以捕获此异常进行相应的业务处理
//2、响应中无异常:此时get方法会返回RecordMetadata对象,此对象包含了当前发送成功的消息在Topic中的offset、partition等信息
RecordMetadata recordMetadata = future.get();
long offset=recordMetadata.offset();
int partition=recordMetadata.partition();
System.out.println("the message offset : "+offset+" ,partition:"+partition+"?");
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行 MySecondProducer java 类,然后查看启动 kafka-console-consumer.sh 的命令行终端,可以看到发送消息打印到了命令行终端上。开发同步发送消息的 Producer 程序关键在于 producer 的 send 方法返回的 Future 对象,通过 Future 对象我们可以知道消息是否发送成功,如果发送成功,可以继续发送下一条消息。如果发送失败,可以再次发送或者存储起来。
异步发送
package com.bupt.kafka.producer;
/**
* @author melooo
* @date 2021/10/13 9:16 下午
*/
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class MyThirdProducer {
public static void main(String[] args) {
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
//向kafka集群发送消息,除了消息值本身,还包括key信息,key信息用于消息在partition之间均匀分布。
//发送消息的key,类型为String,使用String类型的序列化器
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//发送消息的value,类型为String,使用String类型的序列化器
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//创建一个KafkaProducer对象,传入上面创建的Properties对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(kafkaProps);
/*
* 使用ProducerRecord<String, String>(String topic, String key, String value)构造函数创建消息对象
* 构造函数接受三个参数:
* topic--告诉kafkaProducer消息发送到哪个topic;
* key--告诉kafkaProducer,所发送消息的key值,注意:key值类型需与前面设置的key.serializer值匹配
* value--告诉kafkaProducer,所发送消息的value值,即消息内容。注意:value值类型需与前面设置的value.serializer值匹配
*/
ProducerRecord<String, String> record = new ProducerRecord<>("mySecondTopic", "messageKey", "hello kafka3");
try {
//发送消息时,传入一个实现了Callback接口的对象,此时发送消息不会阻塞,发送完成后,会调用Callback接口的onCompletion方法。
producer.send(record, new DemoProducerCallback());
producer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
上面的代码中使用了一个实现了 Callback 接口的对象 DemoProducerCallback,这个类需要我们创建,实现 org.apache.kafka.clients.producer.Callback 接口,在接口方法 onCompletion 中编写如下代码:使用多线程方式发送消息
package com.bupt.kafka.producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.RecordMetadata;
/**
* @author melooo
* @date 2021/10/13 9:16 下午
*/
public class DemoProducerCallback implements Callback {
//消息发送完成后,调用此方法,如果kafka的响应有异常,则此方法参数exception的值不为null
//如果kafka的响应无异常,则此方法参数exception的值为null,在生产环境中,可以根据不同的响应,作出不同的业务处理。
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
//在生产环境中,可以作出相应的业务处理。在这里我们只是简单的打印出异常。
e.printStackTrace();
} else {
//如果响应无异常,打印出消息的offset和partition信息
long offset = recordMetadata.offset();
int partition = recordMetadata.partition();
String topic = recordMetadata.topic();
System.out.println("the message topic: " + topic + ",offset: " + offset + ",partition: " + partition);
}
}
}
使用多线程方式发送消息
package com.bupt.kafka.producer;
/**
* @author melooo
* @date 2021/10/13 9:29 下午
*/
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class MultiThreadProducer extends Thread {
//声明KafkaProducer类型的全局变量,由于在多线程环境,所以声明为final类型
private final KafkaProducer<String, String> producer;
//声明用于存储topic名称的全局变量,由于在多线程环境,所以声明为final类型
private final String topic;
//设置一次发送消息的条数
private final int messageNumToSend = 10;
/**
* 多线程Producer构造函数 在构造函数中创建KafkaProducer对象
*
* @param topicName Topic名称
*/
public MultiThreadProducer(String topicName) {
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<String, String>(kafkaProps);
topic = topicName;
}
/**
* 生产者线程执行函数,循环发送消息。
*/
@Override
public void run() {
//用于记录已发送信息的条数,同时作为消息的key值。
int messageNo = 0;
while (messageNo <= messageNumToSend) {
String messageContent = "Message_" + messageNo;
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, messageNo + "", messageContent);
producer.send(record, new DemoProducerCallback());
messageNo++;
}
//刷新缓存,将消息发送到kafka集群
producer.flush();
}
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
new MultiThreadProducer("mySecondTopic").start();
}
}
}
先运行 MultiThreadProducer java 类,然后查看启动 kafka-console-consumer 的命令行终端,可以看到发送消息打印到了命令行终端上。运行结果类似下图:
<img src="/Users/melooo/Library/Application Support/typora-user-images/image-20211016013508274.png" alt=“image-20211016013508274” style=“zoom: 33%;” /
发送消息的总体流程
我们用一个流程图来表示发送消息到 Kafka 集群的基本步骤:
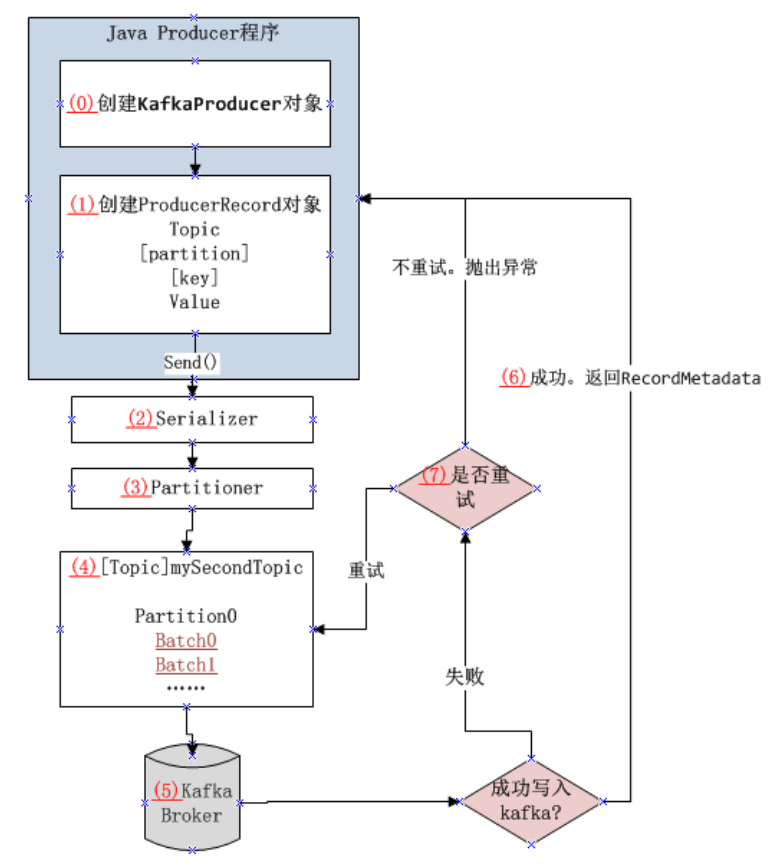
图中对每一步都标注了号码,从(0)–(7),对应说明如下:
- (0) :创建 KafkaProducer 对象,此对象接收 Properties 类型的参数,我们配置了 bootstrap.servers、key.serializer、value.serializer 三个参数。
- (1) :接着创建了一个 ProducerRecord 对象,创建此对象时,我们传入了 topic、消息的 key 和消息的 value 等参数。然后我们使用(0)步骤中创建的 KafkaProducer 对象的 send 方法将消息发送了出去。上面两个步骤是我们开发的 Producer 程序所完成的工作。消息发送出去之后,接下来发生了什么呢?
- (2) :消息发送出去之后,首先,KafkaProducer 对象会对消息的 key 和 value 进行序列化,序列化后的数据才可以通过网络传输。使用的序列化类就是我们配置的 key.serializer 和 value.serializer 两个参数的值所指向的类。
- (3) :接着,消息会发送到 partitioner,partitioner 负责将消息发送到 topic 的某个 partition。如果我们在创建 ProducerRecord 对象时声明了分区,那么 partitioner 会直接返回声明的分区。如果没有声明分区,partitioner 会选一个分区,通常会基于消息的 key 值做分区选择。一旦分区选定,producer 就知道了:消息要发送到哪个 topic 的哪个分区。
- (4) :接着,producer 会把发送到相同 topic,相同 partition 的消息进行打包,形成 Batch,后续消息,如果有相同的 topic 和 partition,都会添加到相应的 Batch 中。producer 会启动一个独立的线程,将这些打包的消息批量发送到对应的 kafka broker。
- (5) :当 broker 收到消息,会发回一个响应。
- (6) :如果消息成功写入 Kafka,会响应一个 RecordMetadata 对象到 Java Producer 程序,其中包括 topic、partition 和 offset 等信息。如果消息没有成功写 入 Kafka,将会响应一个错误 error。
- (7) :当 producer 收到一个错误响应,producer 会尝试重发消息,当尝试次数达到配置的值时,仍未发送成功,此时会返回一个错误到 Java Producer 程序。
以上就是 Java Producer 程序发送消息的整个过程。
Producer中的配置参数
创建 KafkaProducer 对象,此对象接收 Properties 类型的参数,我们配置了 bootstrap.servers、key.serializer、value.serializer 三个参数,这三个参数是必备的。三个参数的含义详解如下:
bootstrap.servers:kafka brokers 的 host:port 列表。此列表中不要求包含集群中所有的 brokers,producer 会根据连接上的 broker 查询到其他 broker。建议列表中至少包含两个 brokers,因为这样即使一个 broker 连接不上,可以连接另一个 broker,从而提高程序的健壮性。key.serializer:消息 key 部分的序列化器。Producer 接口使用了泛型来定义key.serializer,以此发送任何 Java 对象。代码中KafkaProducer<String, String>第一个 String 表示key.serializer是 String 类型的,第二个 String 表示value.serializer是 String 类型的。Producer 必须知道如何将这些 Java 对象转换为二进制数组 byte arrays,以用于网络传输。key.serializer应该设置为一个全路径名的类,这个类实现了org.apache.kafka.common.serialization.Serializer接口,producer 使用这个类将 key 对象序列化为 byte array。Kafka 客户端包中有ByteArraySerializer,StringSerializer,IntegerSerializer三种类型的序列化器,如果发送常用类型的消息,不需要自定义序列化器。注意,即使发送只包含 value 的消息,也要设置key.serializer。value.serializer:消息 value 部分的序列化器。与key.serializer含义相同,其值可以与key.serializer相同,也可以不同。
producer 更多参数的配置信息,参见官方文档:http://kafka.apache.org/documentation/ 。














 1006
1006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









