







读后感
第一章是一个摘要性的故事梗概,故事的主角是属性变量和相应变量之间的对应关系。这个关系 f(x) 是不确定的,我们可知道的只有各别数据对,运用它们如何得知两者的关系呢?这便是问题的产生了。
对于这样概括属性变量与依赖变量之间关系的概念,我们称之为模型。建立模型的好处是即可以分析概括,又可以对潜在的未来进行预测。
那么像函数一样,我们第一个会接触到的模型是什么? 线性模型就是属性和相应之间是类似线性的关系。
线性模型的构建便是 y = mx + c(m, c 为常量)m 和 c实际上都是为了增加我们线性模型灵活性而额外增加的参数,最基本的线性关系我们都知道是y = x,即二者正相关。
在书上举出的关于短跑成绩与年份这一组预测量中,时间t和年份x并不是单单正相关。这是我们主观上从零散到点图上获得的信息。
但是对于具体的m,c应该分别取什么样的数值,这并不是直观可以解决的问题,牵扯到我们认为怎样的模型,是一个好的模型。
设我们预测的模型是
t = mx +c
通常我们用真实值与预测值之间的平方差来衡量预测的精确性。我们称之为损失函数Ln()

而对于整个数据集上,则选择了平均损失来衡量全局的精确性
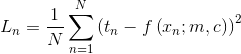
这样一来,寻找最合适参数m和c的任务实际上转变为了寻找令上式最小值时相对应的m和c的取值。平方损失最小化是最小二乘误差法的基础。
通过对损失函数分别求导数,我们可以获得相应的参数解。
在上述得到的简单线性模型拟合小数据集的过程中,这个方式是有局限性的,我们的属性变量只是一个单一的变量,或者说仅仅是一个单独的数字,而实际上,一个数字是不足以让我们描述更加复杂的情况的,我们可能需要的是一个属性的集合来代替单个的数字。
同样是短跑问题,仅仅用年份作为属性变量从逻辑上便缺乏说服力,我们需要的可能是奥运会年份与每个运动员个人最好成绩,如用s1,s2,s3……一直到s8表示运动员在8个赛道上分别曾经达到的最好成绩,那么我们所需要的线性模型可能更加复杂,如下
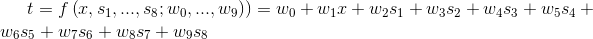
幸运的是,我们有向量和矩阵帮助我们。
这里我们将矩阵向量的基础略过。继续在向量条件下的问题讨论。
损失可以表示为:
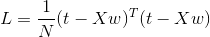
对上式进行w偏微分,可以得到
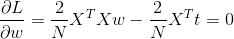
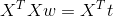
最后得到矩阵公式为:
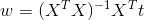
再将该式展开后,发现对各w参数的计算仍然符合之前单独数值计算的情况。
现在回过头来看,我们用线性函数对奥运会年份时间与奥运会100米短跑成绩间建立模型,但是主观上我们知道这是很受局限性的。它意味着按照这样的趋势,这样的递减会一直继续下去,其最后所需时间可能是负值。















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









