









结论
- 这个 RAG 实现再次是遵循代理方法来创建有弹性、知识密集型的对话用户界面的另一个很好的例子。
- 从两个角度来看,图形方法也出现了。图形方法适用于代理流;例如 LangChain 的 LangGraph、LlamaIndex Workflows 和 Deepset 的 Haystack Studio。知识也采用图形方法,其中花费更多时间在数据发现和数据设计上,以创建更强大的数据拓扑。
- WeKnow-RAG 也是 RAG 的一种多阶段方法,它符合最近的发展,即引入复杂性以创建更具弹性和多方面的解决方案。
- WeKnow-RAG 的这种方法包括自我评估机制。
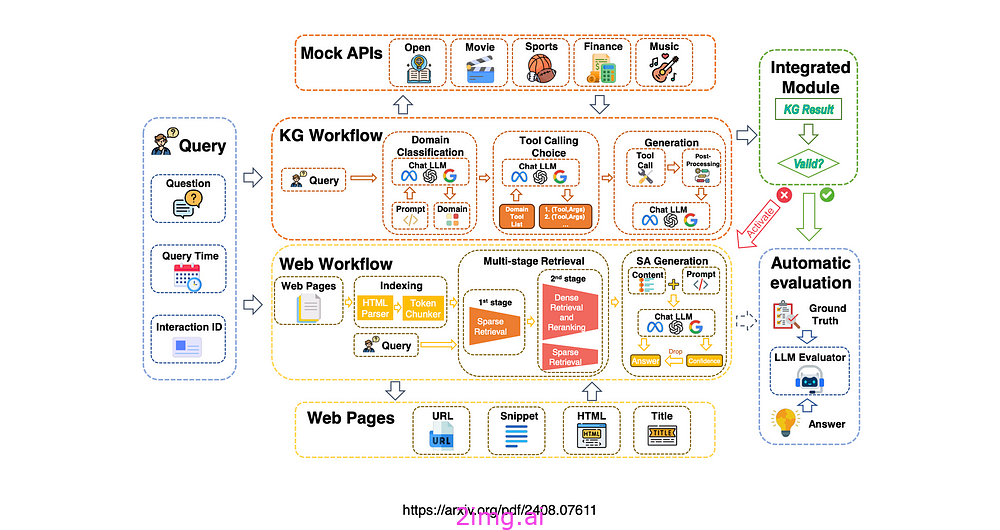
- KG 用于特定领域的查询,而解析和分块用于网络检索数据。
- 此实现将知识库和 RAG/Chunking 方法结合起来,用于数据设计可能或不可能的情况。通常,技术会相互对立,要么是其中一种情况,要么是另一种情况。这里说明,有时答案介于两者之间。
介绍
本研究考虑一种特定领域的 KG 增强 RAG 系统,该系统旨在适应各种查询类型和领域,提高事实和复杂推理任务的性能。
介绍了一种网页的多阶段检索方法,利用稀疏和密集检索技术来有效地平衡信息检索的效率和准确性。
实施了法学硕士的自我评估机制,使他们能够评估对生成的答案的信心,从而减少幻觉并提高整体反应质量。
提出了一种自适应框架,智能地结合基于 KG 和基于 Web 的 RAG 方法,以适应不同领域的特征和信息变化率。
自适应智能代理
WeKnow-RAG 将 Web 搜索和知识图谱集成到检索增强生成 (RAG) 架构中,改进了通常依赖密集向量相似性搜索进行检索的传统 RAG 方法。
虽然这些传统方法将语料库分成文本块并专门使用密集检索系统,但它们通常无法有效地处理复杂的查询。
与分块相关的挑战
RAG 分块实现面临几个挑战:
- 元数据和混合搜索的限制:使用元数据过滤或混合搜索的方法受到元数据预定义范围的限制,从而限制了系统的灵活性。
- 粒度问题:在向量空间块内实现正确的细节级别很困难,导致响应可能相关但对于复杂查询来说不够精确。
- 信息检索效率低下:这些方法通常会检索大量不相关的数据,从而增加计算成本并降低响应的质量和速度。
- 过度检索:过多的数据检索可能会使系统不堪重负,从而更难识别最相关的块。
这些挑战强调了需要更精细的分块策略和检索机制来提高 RAG 系统的相关性和效率。
为什么选择KG
有效的 RAG 系统应该优先检索最相关的信息,同时尽量减少不相关的内容。
知识图谱 (KG) 通过提供实体及其关系的结构化和精确表示来实现这一目标。
与向量相似度不同,KG 将事实组织成简单、可解释的知识三元组(例如,实体 - 关系→实体)。
知识图谱可以随着新数据的增加而不断扩展,专家可以开发特定领域的知识图谱,以确保专业领域的准确性和可靠性。许多近期发展都体现了这种方法,研究也越来越关注如何利用该领域的基于图的方法。
老实说,知识图谱是我想要提高技能的一个领域,因为我觉得我对这项技术的理解还不够深入。
以下是音乐领域中用于查询知识图谱的函数调用提示的摘录。完整版包含几个附加功能。
"System":"You are an AI agent of linguist talking to a human. ... For all questions you MUST use one of the functions provided. You have access to the following tools":{
"type":"function",
"function":{
"name":"get_artist_info",
"description":"Useful for when you need to get information about an artist, such as singer, band",
"parameters":{
"type":"object",
"properties":{
"artist_name":{
"type":"string",
"description":"the name of artist or band"
},
"artist_information":{
"type":"string",
"description":"the kind of artist information, such as birthplace, birthday, lifespan, all_works, grammy_count, grammy_year, band_members"
}
},
"required":[
"artist_name",
"artist_information"
]
}
}
}"...
To use these tools you must always respond in a Python function
call based on the above provided function definition of the tool! For example":{
"name":"get_artist_info",
"params":{
"artist_name":"justin bieber ",
"artist_information":"birthday"
}
}"User":{
"query"
}最后
WeKnow-RAG 将图谱中的结构化知识与灵活的密集向量检索相结合,提高了 LLM 的准确性和可靠性。该系统使用特定领域的知识图谱来提高事实和复杂查询的性能,并采用多阶段网络检索技术来平衡效率和准确性。
此外,它还采用了自我评估机制,以减少 LLM 生成的答案中的错误。该框架智能地结合了基于 KG 和基于 Web 的方法,适应不同的领域和信息变化的速度,确保在动态环境中实现最佳性能。
根据研究,WeKnow-RAG 在大量测试中表现出色,这是有道理的,因为这种方法与被认为是近期最有前景的技术和架构方法相一致。
















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











