








树是存储数据的一种重要数据结构。对一个数据集合进行维护的过程中涉及的操作有查找,更新(插入,删除)。树的优点在于不要求连续空间,更新复杂度小。常见的有:
一、二叉搜索树
优点:实现简单
缺点:效率不够稳定,多次操作后可能导致树的结构不平衡。
改进:在插入和删除的过程中,加入调整策略使得树保持平衡(AVL)
二、B树
一种多路搜索树,节点存储关键字,m个关键字将节点划分为m+1个区间,对应m+1棵子树。
对于非叶子节点:
(1)根节点儿子数目 【2,m】,m > 2
(2)非叶子非根节点儿子数目 【m/2,m】
(3)对于某一节点的关键字序列为p1<p2,则子树分别存储 (.., p1), (p1, p2)和(p2, p3)的数据
(3)所有叶子节点位于同一层
搜索:
从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;搜索性能与二分查找一样。由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为:
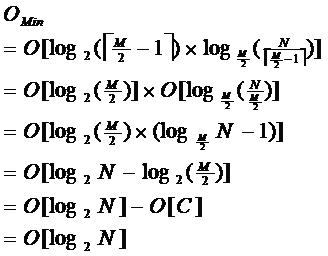
B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题
插入:如果节点已满,则将节点一分为二
删除:将不足m/2的节点合并
三、B+树
和B-树类似,但
(1)非叶子结点的子树指针与关键字个数相同,结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树
(2)所有关键字均在叶节点中出现,叶子节点新增一个链接指针将所有关键字连起来
特性
(1)所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
(2)非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
(3)区域查找方便,适合文件索引系统,传统关系型数据库(Oracle/MySQL/PostgreSQL…),其主要的索引结构,使用的是B+树,InnoDB引擎的表数据,整个都是以B+树的组织形式存放的。
关于分裂的优化【2】
四、B*树
类似于B+树,但空间利用率更高
(1)非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
(2)分裂时会影响兄弟的数据,因此多了一个兄弟指针。当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
引用
【1】http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
【2】从MySQL Bug#67718浅谈B+树索引的分裂优化,http://hedengcheng.com/?p=525















 170万+
170万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









