






 本文介绍了语音处理中常用的Mel spectrogram概念,展示了如何通过librosa库计算并可视化信号的短时傅里叶变换和梅尔频率倒谱图,以帮助理解其在语音分类中的应用。
本文介绍了语音处理中常用的Mel spectrogram概念,展示了如何通过librosa库计算并可视化信号的短时傅里叶变换和梅尔频率倒谱图,以帮助理解其在语音分类中的应用。
简介
语音处理中 常常需要用到mel spectrogram,比如在语音分类中常常会把把信号signal变成图片spectrogram的形式, 然后用分类图片的算法(比如CNN)来分类语音。 本文主要介绍什么是mel specgrogram以及如何通过librosa来获取spectrogram 和mel spectrogram
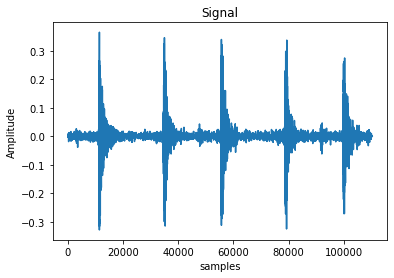
信号signal
常说一个信号是多少多少赫兹的,指的是 这个信号 每秒有多少个取值点。44.1kHZ的声音就是 这个声音每秒有44100个取值。
读取声音:
import librosa
import matplotlib.pyplot as plt
%matplotlib inline
y, sr = librosa.load('./sample.wav')
plt.plot(y)
plt.title('Signal')
plt.title('Signal')
plt.xlabel('samples')
plt.ylabel('Amplitude')
傅里叶变换(Fourier Transform)
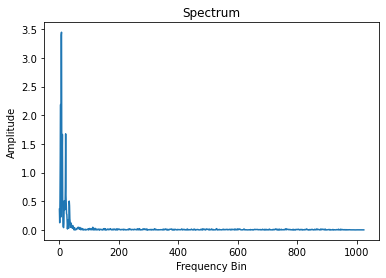
每个信号都可以看成不同频率的sine或者cosine的信号单元合成, 通过快速傅里叶变换(Fast Fourier Transform)可以分解一个信号到不同频率的信号单元:
import numpy as np
n_fft=2048
ft = np.abs(librosa.stft(y[:n_fft], hop_length=n_fft+1))
plt.plot(ft)
plt.title('Spectrum')
plt.xlabel('Frequency Bin')
plt.ylabel('Amplitude')
短时傅里叶变换
声音的频率可能会随着时间而变化,所以对长信号来说直接用FFT来分解整个信号会不妥, 所以用到短时傅里叶变换(short time fourier transform), 只是把信号分成很多小段, 在每小段上进行FFT运算。

window length 是每小段的长度, 某一小段计算完以后,会计算下一小段,hop lenth就是两个小段之间的跳跃间隔。最后得到的STFT就是这些小段FFT的堆加, 每一小段有 Amplitude 和Frequency信息,以及这一小段所在的Time信息。把这些信息汇总到图片上 就得到了Spectrogram.
Spectrogram
由于人类会对低频低音高的片段更感兴趣,所以会对通过FFT变换得到的Amplitude 和Frequency 信息进行log运算, 压缩高频和高音高的部分:
import librosa.display
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max) #将音高变为分贝。log运算
librosa.display.specshow(spec, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Spectrogram')
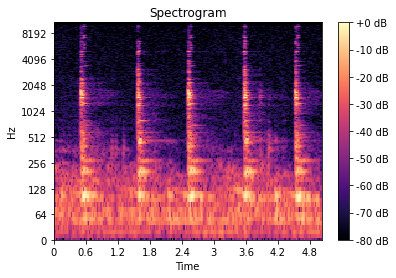
颜色表示分贝。
The Mel Scale
人类对低频信号更敏感, 你可以很容易区分500HZ 和1000HZ的声音, 但区分不清楚9000HZ和9500HZ的声音。 但在物理上却很容易区分。 把频率信号做一个非线性映射:
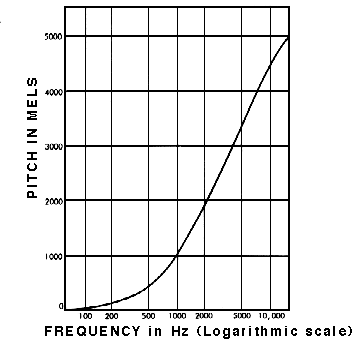
这样 人类对不同频率声音的区分 可以直接通过数值差异来显示了。
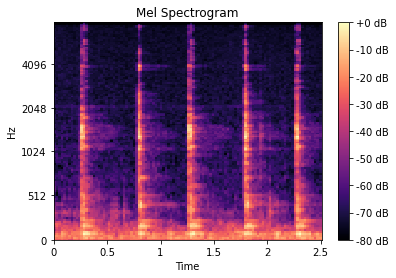
Mel spectrogram
Mel spectrogram和spectrogram的区别就是 mel spectrogram的频率是mel scale变换后的频率(你可以想象把Spectrogram整体往下压,)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
总结
应用 librosa库可以很容易计算spectrogram和mel spectrogram, 至于用哪个效果会好(还有个MFCC)要根据自己的实验结果来。

















 3743
3743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









