







12月30日,云安全联盟大中华区正式发布《2021中国零信任全景图》(第二版)。
作为国内云安全CWPP领导厂商,安全狗此次也凭借强大的零信任落地产品入选全景图多个领域,成为杰出的厂商代表。
云隙:落地零信任概念的最佳实践
安全狗旗下的云隙自适应微隔离系统可实现采集工作负载之间的网络流量,自动生成访问关系拓扑图等功能,同时根据可视化的网络访问关系拓扑图,用户可快速看清各类业务所使用的端口和协议,并以精细到业务级别的访问控制策略、进程白名单、文件访问权限等安全手段,科学、高效、安全地实现对开发环境、测试环境和生产环境严格微隔离。在产品落地的过程中,各个模块进行联动,模块间数据联通,形成闭环系统,同时可结合安全狗云眼产品赋予用户资产安全体系攻击防御、精细化的访问控制能力以及行为合规能力,落实零信任安全理念。
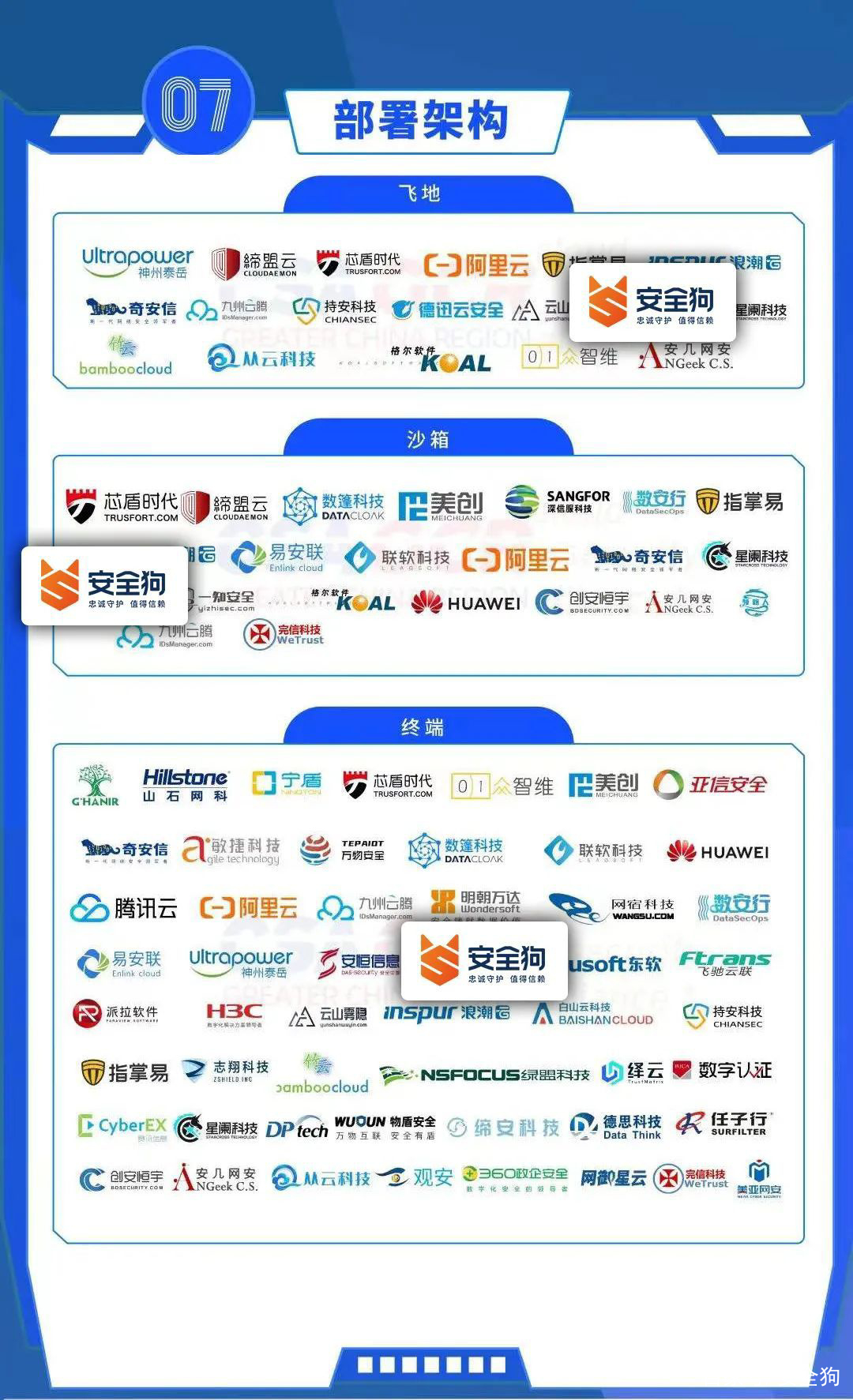
凭借在公司整体安全实力、保护的业务范围和对象、技术、服务模式、部署架构等多个层面上的良好表现,安全狗此次也入选全景图的多个领域:
公司类型:原有安全厂商增加零信任业务。
被保护对象:设备、设施或工作负载;应用。
业务类型:产品和解决方案;咨询服务;治理服务。
技术类型:SDP;微隔离。
服务模式:私有化;云化。
部署架构:飞地;沙箱;终端。





作为已经成熟发挥安全作用并且落实零信任概念的产品,安全狗技术团队也在持续更新和优化云隙。在今年,云隙还迎来了V4.0重大版本更新。在此版本中,云隙网络隔离能力得到了重大优化,一系列新功能亮点引起关注,如:业务拓扑新增多维度流量合并功能、策略基于流量自学习可自动生成策略规则、采用流量跟踪(conntrack)专利技术采集业务流量、在主机维度网络隔离基础上能够适配容器环境,实现全方位的精细化隔离与防护策略管理,提高网络安全隔离能力,优化用户使用体验。系列功能的优化与新增,使得流量管理更加精细化,让想借端口、IP或者难以解决的系统顽固漏洞为跳板,横向入侵业务系统的不法黑客无机可趁。
值得关注的是,云隙还凭借强大的安全实力,受到业界和企业用户的广泛认可:作为(云)工作负载安全产品解决方案的组成产品,云隙和云眼、云甲一同入选国际权威机构Gartner的《2021年云工作负载保护平台(CWPP)市场指南》报告;在ISC中国网络安全创新能力百强上,安全狗也入选零信任领域;此外,安全狗云隙服务案例还入选CSA《零信任落地案例集》;安全狗基于零信任的大数据安全保护体系也入选了工信部的大数据产业发展试点示范项目。多重荣誉资质的获得,都是国内外权威机构对安全狗云隙守护实力的认可与信赖。
此次安全狗入选CSA《2021中国零信任全景图》多个领域分类,不仅是安全狗技术团队在2021年期间紧抓关键安全技术、打造契合企业用户安全需求的研发实力表现,同时也是多方专家对安全狗安全能力稳定输出和团队服务水平的认可。未来,安全狗将以此为激励,践行“守护数字世界 助力网络强国”的理念,不断打造和完善自身的安全产品体系,助力更多企业用户抓住云原生、零信任等新兴技术,护航其业务安全发展,为其在数字经济转型和网络强国建设中持续赋能。















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









