







论文:用神经网络求解混合整数规划
1.摘要
(1)文章目的:
混合整数规划(MIP)求解器一般使用一系列启发式算法来求解。而机器学习算法能 够通过利用数据实例之间的共享结构,构造更好的启发式算法。
(2)文章工作:
将学习算法应用于 Diving 和 Branching 两个子任务,即 Neural Diving 和 Neural Branching。其中 Neural Diving 即使用神经网络为整型变量生成部分的解,其余的变量使用Scip求解器求解(个人理解是为了防止决策变量过多的问题)。其中 Neural Branching 使用神经网络来选择分支变量,并使用树来进行定界。 Neural Branching 是使用模仿全强分支的方式实现的。
(3)文章效果:
使用真实数据集进行训练并测试,每个数据集包含1e3-1e6个变量。评判标准为原始-对偶差距,在五个最大的数据集中,三个效果分别比Scip好1.5、2和1e4倍,第四个以五倍的速度获得了10%的间隔,最后一个和Scip相当。
2. 背景介绍
(1)Neural Diving:查找高质量部分变量。训练一个深度神经网络来产生输入MIP的整数变量的多个部分赋值,剩余的未分配变量通过使用Scip求解变小的子mip来求得。
(2)Neural Branching:分支定界算法中,在给定节点上选择分支变量是决定搜索效率的关键因素。训练一个深度神经网络策略来模拟专家策略所做的选择。模拟目标是全强分支。
3. 贡献
(1)提出 Neural Diving,在相同数据集中实现了以平均3-10倍的速度实现了1%的平均原始间隙。在一个数据集中SCIP在时间限制内未达到1%的平均原始间隙,而神经潜水则达到。
(2)提出了 Neural Branching ,通过模仿一种新的基于ADMM的可伸缩专家策略,学习分支策略以用于分支定界算法。在大数据集上,ADMM专家在相同的运行时间内生成1.4倍和12倍以上的训练数据。在四个数据集上,学习到的策略显著优于SCIP的分支启发式算法,在大时间限制下的保持实例上具有2-20×更好的平均双差距。
(3)将 Neural Diving 和Neural Branching 相结合,在五个MIPs最大的数据集中的四个数据集上,在平均原始-对偶差距方面,取得明显优于SCIP的性能,同时与第五个数据集的性能相匹配。
4. 混合整数线性规划背景
混合整数线性规划的形式为
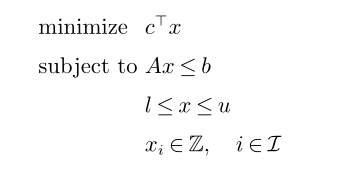
其中允许l和u取无穷大的值,表明变量对于没有下限或上限。部分赋值指我们固定了一些变量值,但不是全部变量。可行分配指满足问题(1)中所有约束的分配,而最优分配或解决方案是指使目标最小化的可行分配。
4.1 线性规划松弛
如果去掉问题中的整数约束,那么它就变成了一个线性规划(LP),它是凸的,可以有效地求解。松弛问题的最优值保证为原问题的下界,因为去除约束只能扩展可行集。将把任何下界称为对偶界。
4.2 分支定界
解决MIPs的一个常见过程是递归地构建一个搜索树,在每个节点上分配部分整数,并使用在每个节点上收集的信息最终收敛到最优分配。在每一步中,我们必须选择一个叶子节点,从中“分支”。在这个节点上,我们可以求解LP松弛,在这里,我们将该节点上固定变量的范围约束到其指定值。
这为我们提供了一个关于该节点的任何其他子节点的真实目标值的有效下限。如果这个界限大于已知的可行分配,那么我们可以安全地修剪搜索树的这一部分,因为该节点的子树中不可能存在原始问题的最优解。
一旦选择了一个变量,我们就进行一个分支步骤,将两个子节点添加到当前节点。一个节点将选定变量的域约束为大于或等于其父节点处LP松弛值的上限。另一个节点将选定变量的域约束为小于或等于其LP松弛值的下限。树被更新,过程再次开始。这种算法称为分支定界算法。
4.3 原始启发式
原始启发式是一种试图找到可行但不一定是最优的变量分配的方法。任何此类可行分配都提供了MIP最优值的保证上界。在MIP求解过程中的任何一点上发现的任何这样的边界都称为原始边界。
4.4 原始-对偶间隙
在运行分支定界时,跟踪全局原始定界(任何可行赋值的最小目标值)和全局对偶定界(分支定界树所有叶子的最小对偶定界)。可以将这些结合起来定义次优差距
gap=global primal bound−global dual bound.
通过构造,间隙总是非负的,如果间隙为零,那么我们就解决了问题,对应于原始界的可行点是最优的,而对偶界是最优的证明。在实践中,当相对间隙低于某些值时,产生最佳原始解决方案作为近似最优解决方案。
5.MIP表示与神经网络结构
使用的深度学习架构是一种图神经网络形式,主要是图卷积网络。
5.1 将MIP表示为图神经网络的输入
使用MIP的二部图表示,方程可用于定义二部图,其中图中的一组n个节点对应于被优化的n个变量,其他m个节点对应于m个约束。
初始的二部图设定为每个变量和约束都有自己的特征,每个变量都对应约束,若变量在约束中,则他们之间的的边为1,否则为0。
图结构如下:

5.2 神经网络结构
这里使用图卷积神经网络来作为网络模型,用于做特征提取。
GCN的输入是由节点集V、边集E和图邻接矩阵a定义的图G=(V,E,a)。单层GCN学习为输入图的每个节点计算H维连续向量表示,称为节点嵌入。
网络表示:
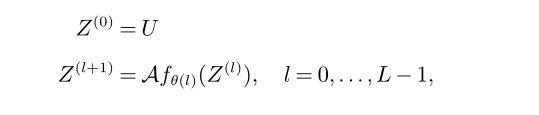
5.3 架构的改进
(1)在图的表示中,使用约束中的系数来代表边的系数。
(2)在图神经网络中,第l+1层的特征由第l层与第l+1层concat组成。
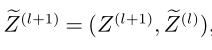
(3)对每层输出时加入layer norm层
当在每一层使用具有高维边缘嵌入的此类网络时,它们的内存使用量可能会比GCN高得多,GCN只需要邻接矩阵,并且可能不适合GPU内存,除非以精度为代价减少层数。GCN更适合我们扩展到大规模MIPs的目标。
6.评价指标
6.1 间隙
对 Neural Diving :
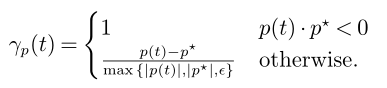
对 Neural Branching :
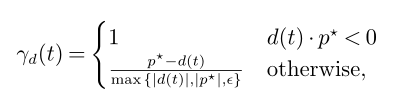
对两者结合:
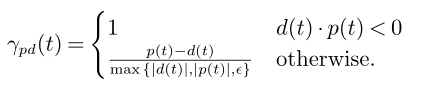
6.2 Survival图
Survival图显示了已解决的测试集MIPs的分数作为运行时间的函数。
6.3 校准时间
所有数据集和比较的总评估工作量需要160000多个MIP解算,以及近一百万个CPU和GPU小时。为了满足计算需求,我们使用了一个共享的、异构的计算集群。
6.4 校准的SCIP
比较的主要基线是SCIP7.0.1,其参数针对每个测试数据集进行了调整。SCIP强调预解、原始启发式和切割的“元参数”,每个参数都有四种可能的设置(默认、关闭、积极、快速)。对于每个数据集,我们对4^3=64个组合进行穷举搜索,以找到在3小时的时间限制内在200个验证MIP的子集上产生最佳平均原始-对偶间隙的设置。称之为基线校准SCIP。
6.5 随机种子的性能变化
为使环境固定,改变了SCIP使用的随机种子参数。
7. Neural Diving
目标为通过模型生成MIP的部分整数变量。这里使用SCIP获得了大量高质量变量解,作为训练集标签。整个模型可以分为预测模型和分类模型两部分,其中分类模型通过神经网络来预测哪些节点被选中进行预测,其中预测模型对于被选中的变量预测值,其余未被选中的变量被用SCIP来求解。
7.1 预测模型
预测为一个监督学习,模型如下,将二部图输入图卷积,经过mlp输出各个变量为某值的概率。训练数据时使用SCIP找到每个实例所有的可行解

对于一次输出x由xi(i1,2,…N),输出概率p(x|M),定义如下:
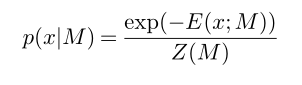
其中M是实例样本,E(x|M)为实例M的一组解x的能量函数:
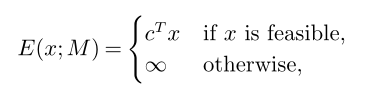
Z(M):
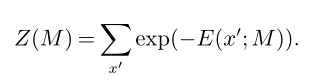
7.1.1 训练
在训练过程中损失函数是
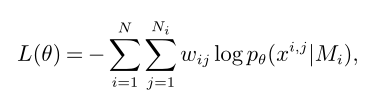
权重定义如下
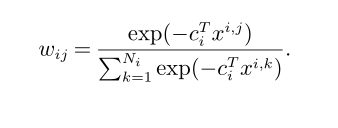
即希望求得的解是可行,且每一个x效果都是好的。
7.1.2 条件独立模型
这里认为对于依次输出x,x的每一位都是独立同分布的。即
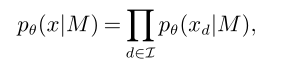
7.1.3 扩展到整数变量
主要的挑战是:a)整型变量的最大值可能在不同的实例中有很大的差异,b)它可能非常大。比如假设一个固定的最大基数,效率很低,而且很难学习。
这里通过把整数变量转化为二进制变量来解决。从最高有效位到最低有效位,因此二进制位数就是:

但整数变量的最大值不确定,因此引入超参数nb确定每个变量最大位数。使用一个神经网络来预测nb的数量,如果真实位数大于nb仍然可以把证书收紧到2^nb-1
7.2 分类模型
经过以上训练还存在一个问题,就是求解时解不一定是可行的。因此可以做部分求解,其余部分由SCIP来解决。
因此这里使用一个二分类器,决定将进行预测的变量并保证覆盖率。
其网络输出仍然是每个变量被选中的概率,其选中概率如下:
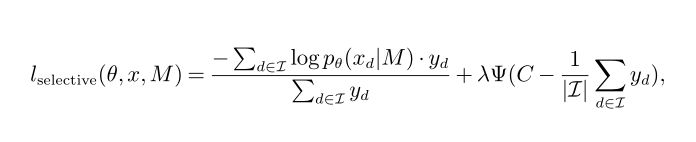
其中,yd代表xd是否应被选择,其中C是覆盖率阈值,ψ是二次惩罚项,λ是覆盖相对重要性的超参数。
其损失函数如下,期望被选择的变量作用最大。
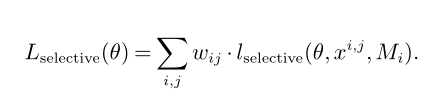
在完成预测后可以进行解的邻域搜索。
7.2.1 生成部分赋值
使用选择模型获得被选择的变量,再使用预测模型获得这些变量的值。
7.2.2 顺序和并行子MIPs求解
上一步中生成的子MIP可以彼此完全独立地求解,从而允许我们并行搜索所有子MIP的解决方案。
实验结果:

8. Neural Branching
分支定界过程在每次迭代中决定两个:展开哪个叶节点,以及在哪个变量上分支。变量选择决策的质量直接影响分支定界效果。这里使用模仿学习来学习strong branching的专家经验。
8.1 专家策略
我们想要一个专家策略,通过构建小的分支定界树解决MIPs,做出良好的分支决策。经验上完全强分支倾向于使用比竞争方法更少的步骤。
这里使用一个网络模型学习强分支变量分布,从分布里进行选择。
对于实际的MIP求解,FSB的每一步计算成本通常非常高,以至于在运行时间变得非常高之前,它只能用于几个分支定界步骤。SCIP的默认变量选择策略,可靠伪成本分支。
8.1.1 ADMM批量LP求解
虽然单纯形算法原则上可以并行化,但对于几个密切相关的LPs,将计算批处理在一起并不容易。为了以合理的成本扩展到大量候选变量,我们使用交替方向乘数法(ADMM)编写了自己的批量LP解算器。可以同时处理我们在GPU上处理的批次中的多个LPs。这可以解决完全强分支中的所有LPs,大大快于按顺序运行SOPLEX。
采样速度:

8.1.2 模仿学习
在这里模仿学习是一个监督学习过程。在本文中有三种模仿变种:专家策略克隆、 随机移动蒸馏、DAgger。
(1) 专家策略克隆
预测专家在每个节点的输出,但存在偏离专家轨道后无效的问题。
(2) 随机移动蒸馏
在使用专家经验时以10%的概率执行随机操作,可以在一个MIP上多次运行专家轨迹,每次生成略有不同的数据。在本文中每个MIP运行了5次。
(3) DAgger
DAgger方法中首先使用专家经验训练一个智能体,在分支定界过程中使用该策略来做决策,同时每一步获得专家经验的输出作为学习目标,在此基础上重新训练智能体。
这里使用三种模式作为超参数,对三种模式都进行训练,选择其中最好的。
8.1.3 实现细节
每个变量的分数:
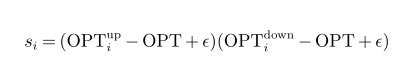
OPT表示分支的节点处LP的目标值。
每个变量的概率分布:
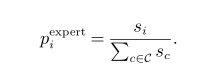
在MIPs的训练集上,使用随机移动或使用DAgger初始化运行ADMM expert,并记录每个节点上的专家分数。模型的输入时二部图,输出是候选集C上的分类分布。训练时,神经网络具有专家分数的节点特征,并通过将最后一层的激活传递给softmax,为该批中的每个节点生成一组概率。
损失函数使用交叉熵:
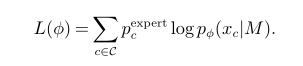
效果:

9. 联合评价
考虑将神经分支和神经潜水结合SCIP的所有四种可能的方法:
1)单独调节SCIP
2)Neural Branching + Neural Diving 使用两种神经启发法
3)仅使用 Neural Branching
4)Tuned SCIP + Neural Diving
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









