







 文章提出了InvariantCausalImitationLearning(ICIL)算法,旨在解决模仿学习在不同环境下的泛化问题。ICIL通过学习因果表征,去除无关噪声,以提升策略的泛化性能。实验表明,ICIL在控制任务中优于标准模仿学习方法,能更好地适应环境变化。
文章提出了InvariantCausalImitationLearning(ICIL)算法,旨在解决模仿学习在不同环境下的泛化问题。ICIL通过学习因果表征,去除无关噪声,以提升策略的泛化性能。实验表明,ICIL在控制任务中优于标准模仿学习方法,能更好地适应环境变化。
论文阅读 Invariant Causal Imitation Learning for Generalizable Policies
1. 主要内容(个人理解)
这篇文章主要设计了一种模仿学习算法,提升了算法的泛化性。主要思想是:一般的模仿学习算法泛化性不好的原因是观测函数往往既包含对于决策动作有因果关系的状态,又包含与决策无关的状态(噪声状态)。因此本文动机为找到观测中是动作原因的状态进行决策。
2. introduction
(1)目标:找到真正重要的因果表征。例子:例如,当模仿理想的驾驶行为时,背景可能会发生变化,但动作应仅取决于汽车和道路特征。另一个例子包括当房间中的闪电条件发生变化,但环境的物理动态保持不变的情况。
(2)对于因果关系可以看作下图:
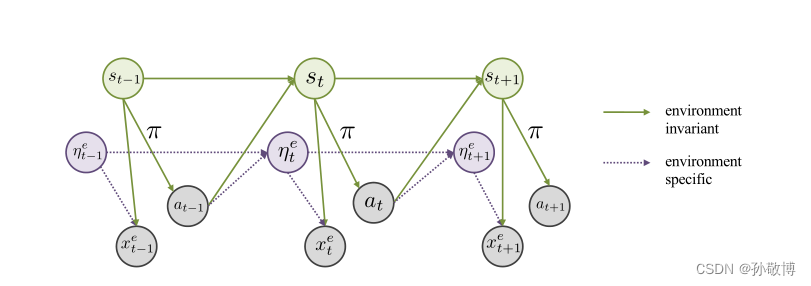
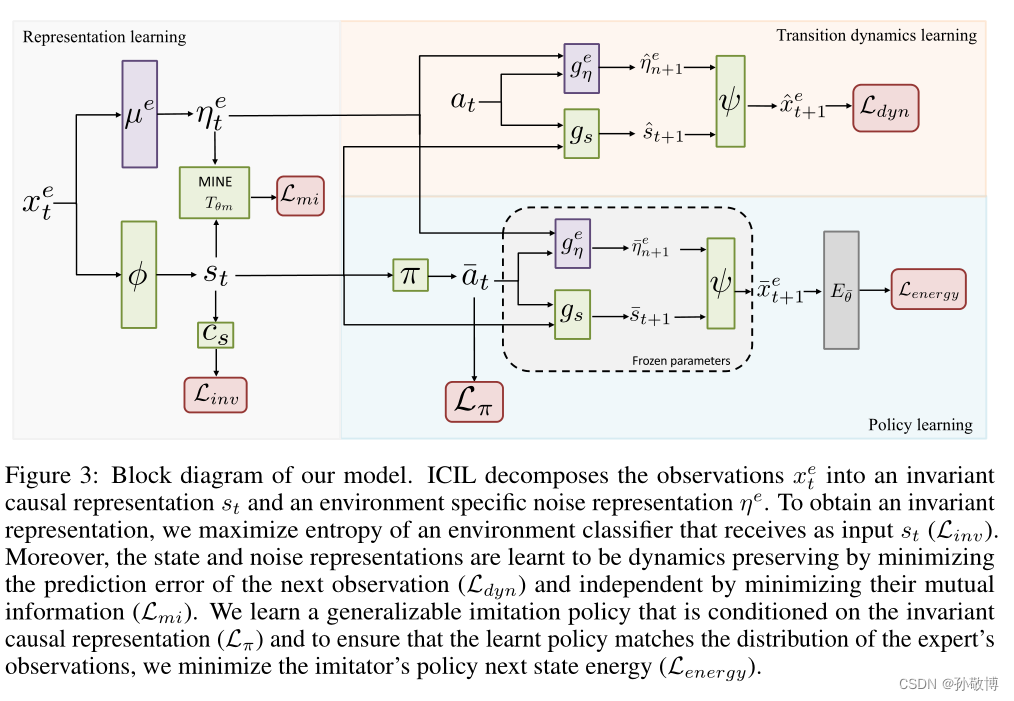
观测可以包括直接导致动作的因果观测s和与动作无关的噪声观测η。其中下一个因果观测s由上一时刻的因果观测与动作共同导致,下一个噪声观测η由上一时刻的噪声观测与动作共同导致。其中因果观测s应该是对于不同环境不变的观测。我们希望恢复不变状态表示st,以便学习到的策略很好地推广到新环境。
(3)贡献:
-
首先,为了满足图1中的因果关系,ICIL学习动态保持表示,并通过最小化它们的相互信息来确保学习到的因果和噪声表示在一定程度上是独立的。
-
第二,为了鼓励学习到的模仿政策保持在专家政策访问的状态分布的支持范围内,ICIL估计专家观察的能量,并使用正则化来最小化模仿者政策的下一个状态能量。
-
第三,我们根据控制和医疗环境中的批量模仿学习基准评估ICIL。
3. 问题公式化
-
观测结构
首先,假设来自专家政策所依赖的不同环境的观察结果有一个共同的潜在结构。找到这样的结构可以让我们丢弃不相关的因素作为学习政策的输入,从而提高泛化性。
假设3.1:(共享潜在结构)考虑将每个环境e中的观测值xe分解为两个分量:不变表示s和噪声项η(即伪相关)。策略只依赖于s,空间s是非空的。 -
环境结构
第二,为了学习仅依赖于s的策略,我们必须假设可用的训练环境实际上是不同的,以便我们可以使用这些环境中的数据学习不变状态表示,并将其与噪声表示分离:
假设3.2(环境干预):每个可用的训练环境e对应于该环境观察空间的一个或多个维度上的硬或软干预(这些维度不构成演示者行为的任何因果关系)。 -
因果关系
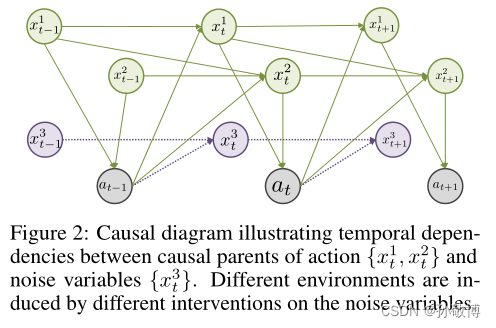
4. 方法
4.1 学习因果表征
为了满足图1中的因果图并学习最小的因果表示,我们需要满足以下条件:(1)st应在环境中保持不变,(2)st和ηt应保持动态,(3)st和ηt应彼此独立。
1.为满足(1),在共享状态表示st上训练环境分类器,使用交叉熵作为分类损失。使用对抗损失来最大化熵值。
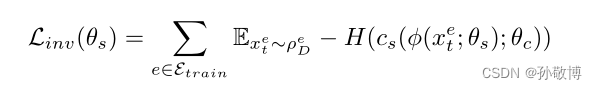
- 在所有可能的不变表示中,我们特别寻找一个也保持过渡动力学的表示,满足条件(2)。为了确保状态和噪声表示是动态保持的,还学习了状态变量的过渡动力学,包括:
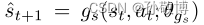
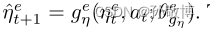
和
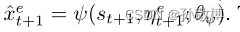
因此动态重建的损失函数为:
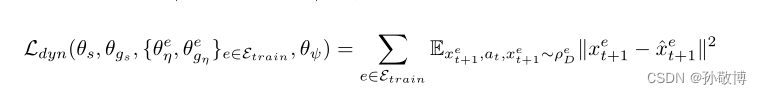
- 最后,为了确保状态表示和噪声表示在每一个条件(3)下是边缘独立的,最小化了它们之间的相互信息。我们使用互信息神经估计(MINE)框架,该框架提供了一种使用神经网络估计互信息的方法。特别地,MINE使用神经信息度量I(U,V)来近似随机变量U和V之间的互信息。
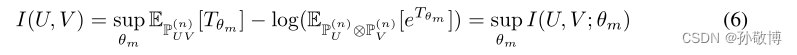
其中PUV是(U,V)的联合度量,PU,PV是边际分布。P(n)表示与n个i.i.d样本相关的经验分布。神经信息度量I(U,V)可以以任意精度近似互信息。因此,我们将以下实际损失函数添加到我们的优化目标中,该目标寻求最小化状态表示和噪声表示之间的相互信息:
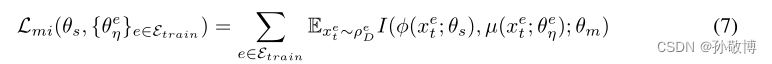
4.2 严格批量设置中匹配专家行为
在因果表示的基础上,我们将学习一种可推广的策略。 在严格的批量设置中,使其与演示者的行为相匹配。首先,我们首先要满足以下条件并最小化专家行动的负对数可能性:
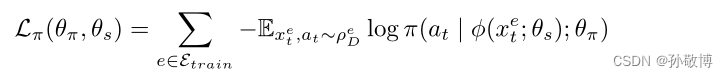
然而,只有这个目标对应于执行行为克隆,这具有众所周知的局限性。为了减轻复合误差,我们需要某种形式的附加正则化,以激励模仿策略保持在专家观察的分布范围内。
在在线设置中,一种流行的方法是确保模拟策略的展开分布与专家策略的展开分配相匹配,例如,通过最小化某种形式其诱导的占用率测量之间的差异。然而,这需要对真实环境或模拟器进行交互式访问,以执行中间策略的推出,这在我们的设置中是不可能的。相反,我们提出了一种利用学习到的过渡动力学的方法。对于任何当前观察xt我们将鼓励通过遵循模仿策略获得下一个观察结果“xt+1”保持在专家的占用测量范围内。
考虑使用基于能量的模型(EBM)来近似专家的占用测量,以便
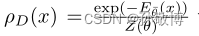
和
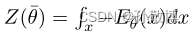
是分段函数(E是能量函数)。
我们将E通过神经网络参数化。不可能通过最大可能性直接训练EBM,因为Z涉及在x的整个输入域上进行积分,这是不切实际的。相反,我们使用对比散度对能量函数E进行预训练。对比度差异降低了来自专家占用分布的观察的能量,并增加了专家占用分布之外的观察能量。
为了激励模仿策略保持在专家观察的分布范围内,我们对其进行训练,以最小化通过以下方式获得的下一次观察的能量,给定当前观察结果:
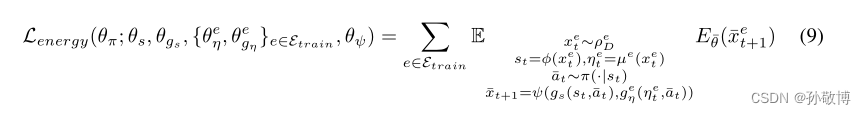
这有效地为停留在专家占用测量的高密度区域内的模仿策略分配了高“奖励”,而为偏离该策略分配了低“奖励”。这可以被视为对在线模仿方法的一种调整,在这种情况下,期望值会高于预期值。
4.3 整体框架
5. 实验
5.1 实验设置
基准我们将ICIL与严格批量模仿学习的标准方法进行比较:行为克隆(BC);学徒学习奖励正则化分类(RCAL),通过对隐含奖励的稀疏正则化,结合了动态意识;V值DICE(VDICE)[2],它使用非策略目标来估计分配匹配所需的分配比率;以及基于能量的分布匹配(EDM),其联合学习模仿者策略及其状态分布的能量模型。这些方法寻求从单一环境中找到与专家行为大致匹配的策略,而不是在设计时考虑到一般性。因此,我们通过使用IRMv1目标及其最初定义的模仿风险来增强这些基准,以获得其他基准:BC-IRM、RCAL-IRM、VDICE-IRM和EDM-IRM。
5.2 gym实验
我们对OpenAI gym的以下控制任务进行了实验[47]:Acrobot[49]、Cartpole[50]、LunarLander[47]和BeamRider[51]。对于每个任务,我们使用来自RL Baselines Zoo[52]和Stable OpenAI Baseline[53]的预训练RL代理来获得专家策略。然后,我们采用类似于[7]中的方法,在两种不同的环境中获得专家演示的数据集。特别是,对于Acrobot[49]、Cartpole[50]和LunarLander[47],我们将伪关联添加到每个控制任务的状态空间和环境标识符中。
每个环境中的伪相关性是原始状态空间中变量子集的不同乘法因子。不变的因果状态由每个控制任务的状态空间中的原始变量表示。我们通过1乘和2乘伪相关的乘法因子,我们在从U采样的乘法因子的环境中进行测试。对于BeamRider[51],类似于[7],不同的相机角度用于训练和测试环境。特别是,我们使用两个训练环境,其中游戏帧分别向左和向右旋转10度,而测试环境没有旋转。旋转将应用于每个环境中所有轨迹的整个帧。然而,请注意,尽管有旋转,状态变量的动力学以及它们如何影响动作保持不变。
我们改变了每个环境中演示轨迹的数量,我们将其作为每个基准的输入,并根据在测试环境中部署学习到的模仿策略所获得的平均回报对其进行评估。图4显示了在10次运行中获得的平均结果和标准误差,对于每一次运行,我们在不同的轨道上对基准进行训练,并使用新采样的乘法因子在测试环境中进行评估,以计算伪相关性。我们注意到,我们的方法始终优于基准,并且能够更好地推广到未知的目标环境。此外,我们通常发现,将IRMv1目标[6]与现有方法一起用于严格的批量模仿学习并不能提高性能,并导致更不稳定的训练。有关其他结果,请参见附录F,我们在附录F中进行了消融研究,以调查用于训练ICIL的损失函数中的不同项对总体性能的影响,比较训练环境与测试环境的性能,并评估增加伪相关性大小的鲁棒性。

代码:
https://github.com/vanderschaarlab/mlforhealthlabpub
https://github.com/ioanabica/Invariant-Causal-Imitation-Learning

















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









