







一 序
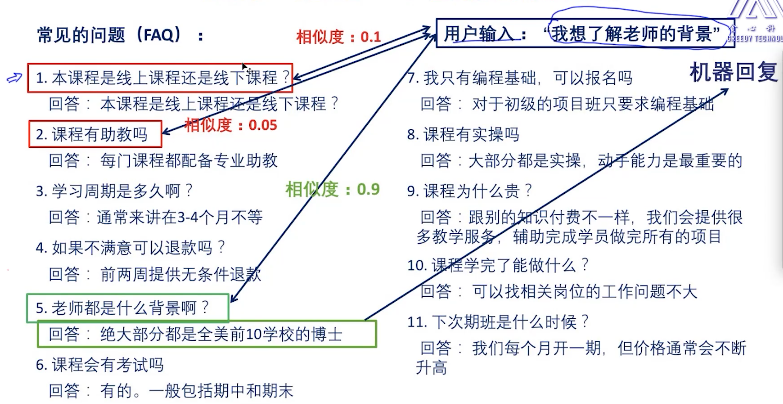
问答系统:有给定的问题。根据用户的输入,匹配相关的问答。
二 处理流程
这里通常有两种方式:1种是用正则,2是计算相似度。
基于概率的,是需要训练数据的。
通用处理流程:
先分词,后门的预处理操作:spell correctness(拼写纠错)、找出原形、stopwords(停用词过滤)、word filter(过滤词)、同义词
文本--->向量的方法:boolean vector(布尔向量)、conf vector(统计词出现的频率)、TF-IDF、word2vec(词向量)、seq2seq
为什么要转换为向量,因为有了向量就能计算相似度。
计算相似度(前一步转换的2个向量):欧式距离、cos 距离、jacrad 距离
排序:-》过滤 返回结果
三 方案
智能问答系统。上面的方案:
基于已有的问答,去匹配是一种。
还有就是根据知识图谱(实体抽取、关系抽取),从查询中提取实体,然后从知识图谱查找关联节点。进而找到答案。
************************
后面的一节,跨度比较大。跳到:心理学与DL 深度学习。
老师用巴布洛夫的狗试验,来对比机器学习,狗通过不断训练获得了铃声响起和有食物可吃之间的联系,就是类似的给机器属入X,输出Y。反复训练之后,机器也会对输入的X输出Y的期望。这两者是类似的。词向量模型训练好之后,以后不断更新、训练,不然很多新词识别不好类似于消退,
泛化与DL的过拟合。
泛化:
泛化能力用来表征学习模型对于未知数据的预测能力。通常使用测试集中的数据来近似泛化能力(就是大部跑模型,小部分做测试)。
从生活来看,教小孩过马路看汽车,类似的摩托车也会注意到。
过拟合:
当某个模型过度的学习训练数据中的细节和噪音,以至于模型在新的数据上表现很差。
老师给的例子是“一朝被蛇咬十年怕井绳”,你不只是对蛇害怕,甚至对类似的绳子就是太泛化了。
分化:
在巴布洛夫的狗试验的中,如果声音赫兹不一样,多次训练后狗会识别出差别,只针对性产生反应。
再DL中,相当于输入类似的X与X1,一开始因为泛化的存在,机器都会输出Y,随着训练的进行,机器也会对X与X1 有个辨别的过程。
总结下:经典条件反射,就是一个连接,分别给与X,Y,中间是黑盒,多次重复后,X跟Y就是有个联结。
不合理性:不一定靠简单的训练就能产生效果,只是关注端到端的。
斯金纳的鼠:
斯金纳箱里有一块踏板,踏板被踩下去后,会有老鼠爱吃的糖球投放进来。当老鼠无意中踩到踏板时,糖球出现了。而当它踩踏其他位置时,没有食物出来。老鼠意识到踩踏板会有糖球,它会更频繁的去踩踏板。这就是操作条件学习的过程。虽然动物也需要建立起两个刺激之间的偶联,但动物的反应却是需要花功夫去学习的,是在机体意识控制下的自主行为。
强化学习:

相关术语有:
- 智能体agent、目标goal、环境environment、观察、状态state、行动action、奖励reward。
奖励机制非常重要。强化学习的过程是不断尝试,并记录所处的状态和行为,找到某个状态下奖励最大的行为。
心理学上分为:正强化、负强化,正惩罚,负惩罚。强化学习上只有两个。
Hubel和Wiesel 的猫
Hubel和Wiesel的猫的试验,提出脑部的视觉处理是基于层级结构。也就是说,视觉处理不是由单个处理器一步完成,而是经过了一层一层的处理。最简单的信息在较低的层级完成,信息逐级被萃取,并随着层级提高而加深。这启发了其他研究者,提出卷积神经网络结构(CNN)。
而且大脑的不同的区域,负责不同的功能。生活中的例子,小孩学语言快。类似外语的例子,中序才开始学习的,非母语环境,后面几年不用很快遗忘。















 7039
7039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









