







 本文介绍了如何搭建一个简单的问答系统,包括数据读取、文本预处理(如停用词过滤、词频分析)、文本表示(如TF-IDF、WordVec、BERT)和相似度匹配。此外,还涉及了倒排索引表的创建和使用,以及拼写纠错算法的实现,以提高用户输入的准确性。
本文介绍了如何搭建一个简单的问答系统,包括数据读取、文本预处理(如停用词过滤、词频分析)、文本表示(如TF-IDF、WordVec、BERT)和相似度匹配。此外,还涉及了倒排索引表的创建和使用,以及拼写纠错算法的实现,以提高用户输入的准确性。
这是贪心上面的某个项目,我拿来学习分享的!!!
数据集代码链接见:https://gitee.com/lj857335332/question-answering-system
引言
下面展示对话系统框架:
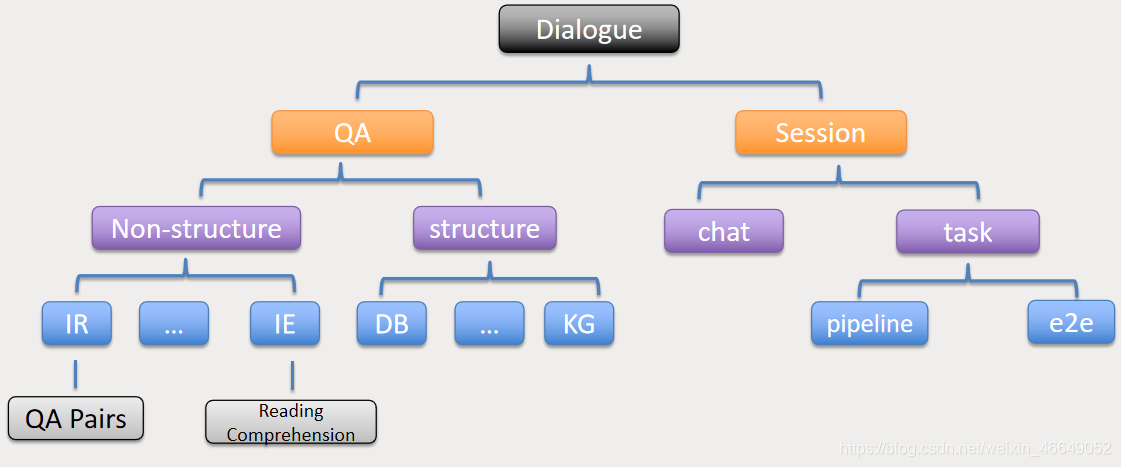
从框架方面,对话系统可以分为问答系统与多轮对话系统。本文着重讲解基于检索形式的问答系统。问答系统又包括结构化的问答系统与非结构化的问答系统。其中涉及的技术包括信息检索与语义匹配技术。涉及到的算法有TF-IDF算法、Jieba分词(中文)、停用词的去除(英文)等文本处理到文本匹配这方面的内容。这种基于检索形式的问答系统在现实中非常常见,比如:百度搜索、谷歌搜索等。文本的组织形式如下:

下面展示基于检索式的问答系统的流程:
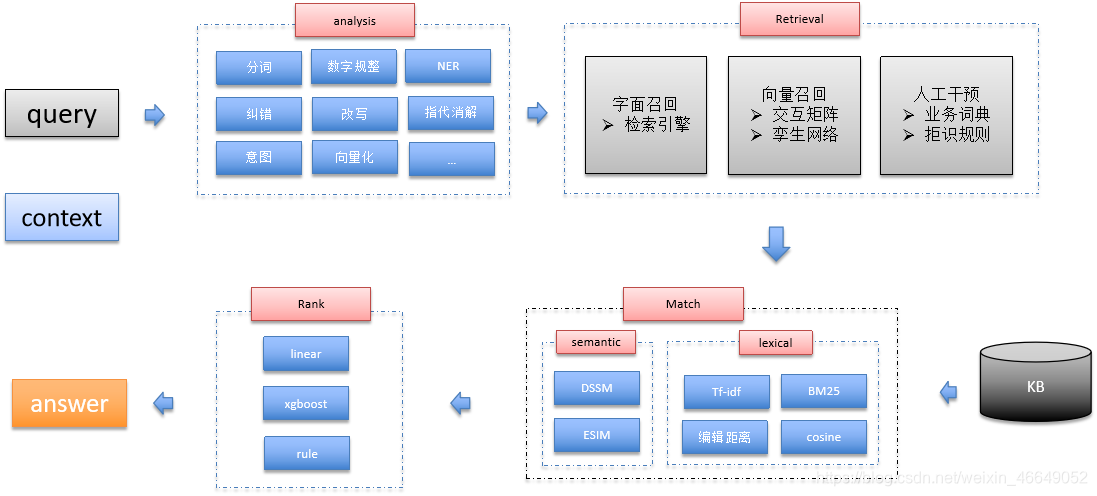
一、问答系统任务介绍
问答系统所需要的数据已经提供,对于每一个问题都可以找得到相应的答案,所以可以理解为每一个样本数据是 <问题、答案>。 那系统的核心是当用户输入一个问题的时候,首先要找到跟这个问题最相近的已经存储在库里的问题,然后直接返回相应的答案即可(但实际上也可以抽取其中的实体或者关键词)。 举一个简单的例子:
假设我们的库里面已有存在以下几个<问题,答案>:
- <"贪心学院主要做什么方面的业务?”, “他们主要做人工智能方面的教育”>
- <“国内有哪些做人工智能教育的公司?”, “贪心学院”>
- <“人工智能和机器学习的关系什么?”, “其实机器学习是人工智能的一个范畴,很多人工智能的应用要基于机器学习的技术”>
- <“人工智能最核心的语言是什么?”, ”Python“>
假设一个用户往系统中输入了问题 “贪心学院是做什么的?”, 那这时候系统先去匹配最相近的“已经存在库里的”问题。 那在这里很显然是 “贪心学院是做什么的”和“贪心学院主要做什么方面的业务?”是最相近的。 所以当我们定位到这个问题之后,直接返回它的答案 “他们主要做人工智能方面的教育”就可以了。 所以这里的核心问题可以归结为计算两个问句(query)之间的相似度。
1. 模块介绍
问答系统项目涉及的模块包括:
- 文本的读取: 需要从相应的文件里读取
(问题,答案) - 文本预处理: 清洗文本很重要,需要涉及到
停用词过滤等工作 - 文本的表示: 如果表示一个句子是非常核心的问题,这里会涉及到
tf-idf,Glove以及BERT Embedding - 文本相似度匹配: 在基于检索式系统中一个核心的部分是计算文本之间的
相似度,从而选择相似度最高的问题然后返回这些问题的答案 - 倒排表: 为了加速搜索速度,我们需要设计
倒排表来存储每一个词与出现的文本 - 词义匹配:直接使用倒排表会忽略到一些意思上相近但不完全一样的单词,我们需要做这部分的处理。我们需要提前构建好
相似的单词然后搜索阶段使用 - 拼写纠错:我们不能保证用户输入的准确,所以第一步需要做用户输入检查,如果发现用户拼错了,我们需要及时在后台改正,然后按照修改后的在库里面搜索
- 文档的排序: 最后返回结果的排序根据文档之间
余弦相似度有关,同时也跟倒排表中匹配的单词有关
2. 数据介绍
项目中需要的数据:
train-v2.0.json: 这个数据包含了问题和答案的pair, 但是以JSON格式存在,需要编写parser来提取出里面的问题和答案。glove.6B: 这个文件需要从网上下载,下载地址为:https://nlp.stanford.edu/projects/glove/, 请使用d=200的词向量(将)spell-errors.txt这个文件主要用来编写拼写纠错模块。 文件中第一列为正确的单词,之后列出来的单词都是常见的错误写法。 但这里需要注意的一点是我们没有给出他们之间的概率,也就是p(错误|正确),所以我们可以认为每一种类型的错误都是同等概率vocab.txt这里列了几万个英文常见的单词,可以用这个词库来验证是否有些单词被拼错testdata.txt这里搜集了一些测试数据,可以用来测试自己的spell corrector。这个文件只是用来测试自己的程序。
3. 项目工具介绍
在本次项目中,你将会用到以下几个工具:
sklearn。具体安装请见:http://scikit-learn.org/stable/install.html sklearn包含了各类机器学习算法和数据处理工具,包括本项目需要使用的词袋模型,均可以在sklearn工具包中找得到。jieba,用来做分词。具体使用方法请见 https://github.com/fxsjy/jiebabert embedding: https://github.com/imgarylai/bert-embeddingnltk:https://www.nltk.org/index.html
二、搭建问答系统
首先,对训练数据进行处理:读取文件与预处理
文本的读取: 需要从文本中读取数据,此处需要读取的文件是train-v2.0.json,并把读取的文件存入一个列表里(list)文本预处理: 对于问题本身需要做一些停用词过滤等文本方面的处理可视化分析: 对于给定的样本数据,做一些可视化分析来更好地理解数据
1. 文本读取
把给定的文本数据读入到qlist和alist当中,这两个分别是列表,其中qlist是问题的列表,alist是对应的答案列表
q l i s t = [ " 问 题 1 " , “ 问 题 2 ” , “ 问 题 3 ” . . . . ] a l i s t = [ " 答 案 1 " , " 答 案 2 " , " 答 案 3 " . . . . ] qlist = ["问题1", “问题2”, “问题3” ....]\\ alist = ["答案1", "答案2", "答案3" ....] qlist=["问题1",“问题2”,“问题3”....]alist=["答案1","答案2","答案3"....]
# 把给定的文本数据读入到```qlist```和```alist```当中,这两个分别是列表,其中```qlist```是问题的列表,```alist```是对应的答案列表
def read_corpus():
"""
读取给定的语料库,并把问题列表和答案列表分别写入到 qlist, alist 里面。
qlist = ["问题1", “问题2”, “问题3” ....]
alist = ["答案1", "答案2", "答案3" ....]
务必要让每一个问题和答案对应起来(下标位置一致)
"""
# 问题列表
qlist = []
# 答案列表
alist = []
# 文件名称
filename = 'data/train-v2.0.json'
# 加载json文件
datas = json.load(open(filename, 'r'))
# 下面将通过字典索引提取问题与答案
data = datas['data']
for d in data:
paragraph = d['paragraphs']
for p in paragraph:
qas = p['qas']
for qa in qas:
# print(qa)
# 处理is_impossible为True时answers空
if (not qa['is_impossible']):
qlist.append(qa['question'])
alist.append(qa['answers'][0]['text'])
# print(qlist[0])
# print(alist[0])
assert len(qlist) == len(alist) # 确保长度一样
return qlist, alist
# 读取给定的语料库,并把问题列表和答案列表分别写入到 qlist, alist
qlist, alist = read_corpus()
2. 可视化分析
统计一下在qlist中总共出现了多少个单词? 总共出现了多少个不同的单词(unique word)?这里需要做简单的分词,对于英文我们根据空格来分词即可,其他过滤暂不考虑(只需分词)。
words_qlist = dict()
for q in qlist:
# 以空格为分词,都转为小写
words = q.strip().split(' ')
for w in words:
if w.lower() in words_qlist:
words_qlist[w.lower()] += 1
else:
words_qlist[w.lower()] = 1
word_total = len(words_qlist)
print(word_total)
统计一下qlist中出现1次,2次,3次… 出现的单词个数, 然后画一个plot。 这里的x轴是单词出现的次数(1,2,3,…), y轴是单词个数。从左到右分别是 出现1次的单词数,出现2次的单词数,出现3次的单词数。
import matplotlib.pyplot as plt
import numpy as np
# counts:key出现N次,value:出现N次词有多少
counts = dict()
for w, c in words_qlist.items():
if c in counts:
counts[c] += 1
else:
counts[c] = 1
# 以histogram画图
fig, ax = plt.subplots()
ax.hist(counts.values(), bins=np.arange(0, 250, 25), histtype='step', alpha=0.6, label="counts")
ax.legend()
ax.set_xlim(0, 250)
ax.set_yticks(np.arange(0, 500, 50))
plt.show()
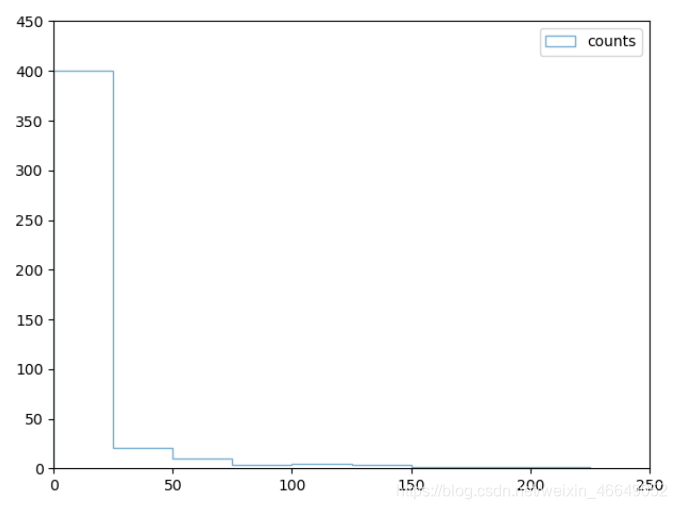
3. 文本预处理
文本预处理一般用到如下的方法:
- 停用词过滤 (去网上搜一下 “english stop words list”,会出现很多包含停用词库的网页,或者直接使用NLTK自带的)
- 转换成lower_case: 这是一个基本的操作
- 去掉一些无用的符号: 比如连续的感叹号!!!, 或者一些奇怪的单词。
- 去掉出现频率很低的词:比如出现次数少于10,20… (想一下如何选择阈值)
- 对于数字的处理: 分词完只有有些单词可能就是数字比如44,415,把所有这些数字都看成是一个单词,这个新的单词我们可以定义为 “#number”
- lemmazation(词性还原): 在这里不要使用stemming(词干提取), 因为stemming的结果有可能不是valid word。
3.1 无用符号过滤
import nltk
from nltk.corpus import stopwords
import codecs
import re
# 去掉一些无用的符号
def tokenizer(ori_list):
# 利用正则表达式去掉无用的符号
# compile 函数用于编译正则表达式,[]用来表示一组字符
# \s匹配任意空白字符,等价于 [\t\n\r\f]。
SYMBOLS = re.compile('[\s;\"\",.!?\\/\[\]\{\}\(\)-]+')
new_list = []
for q in ori_list:
# split 方法按照能够匹配的子串将字符串分割后返回列表
words = SYMBOLS.split(q.lower().strip())
new_list.append(' '.join(words))
return new_list
3.2 停用词过滤
# 去掉question的停用词
def removeStopWord(ori_list):
new_list = []
# nltk中stopwords包含what等,但是在QA问题中,这算关键词,所以不看作关键词
restored = ['what', 'when', 'which', 'how', 'who', 'where']
# nltk中自带的停用词库,加载英语停用词
english_stop_words = list(
set(stopwords.words('english'))) # ['what','when','which','how','who','where','a','an','the'] #
# 将在QA问答系统中不算停用词的词去掉
for w in restored:
english_stop_words.remove(w)
for q in ori_list:
# 将每个问句的停用词去掉
sentence = ' '.join([w for w in q.strip().split(' ') if w not in english_stop_words])
# 将去掉停用词的问句添加至列表中
new_list.append(sentence)
return new_list
3.3 去掉低频率的词
def removeLowFrequence(ori_list, vocabulary, thres=10):
"""
去掉低频率的词
:param ori_list: 预处理后的问题列表
:param vocabulary: 词频率字典
:param thres: 频率阈值,可以基于数据实际情况进行调整
:return: 新的问题列表
"""
# 根据thres筛选词表,小于thres的词去掉
new_list = []
for q in ori_list:
sentence = ' '.join([w for w in q.strip().split(' ') if vocabulary[w] >= thres])
new_list.append(sentence)
return new_list
3.4 处理数字
在文本匹配时,如果数字较多,就会造成噪声。
def replaceDigits(ori_list, replace='#number'):
"""
将数字统一替换为replace,默认#number
:param ori_list: 预处理后的问题列表
:param replace:
:return:
"""
# 编译正则表达式:匹配1个或多个数字
DIGITS = re.compile('\d+')
new_list = []
for q in ori_list:
# re.sub用于替换字符串中的匹配项,相当于在q中查找连续的数字替换为#number
q = DIGITS.sub(replace, q)
# 将处理后的问题字符串添加到新列表中
new_list.append(q)
return new_list
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









