







一 序
本文 属于极客时间机器学习40讲学习笔记系列。
15 | 从回归到分类:联系函数与降维
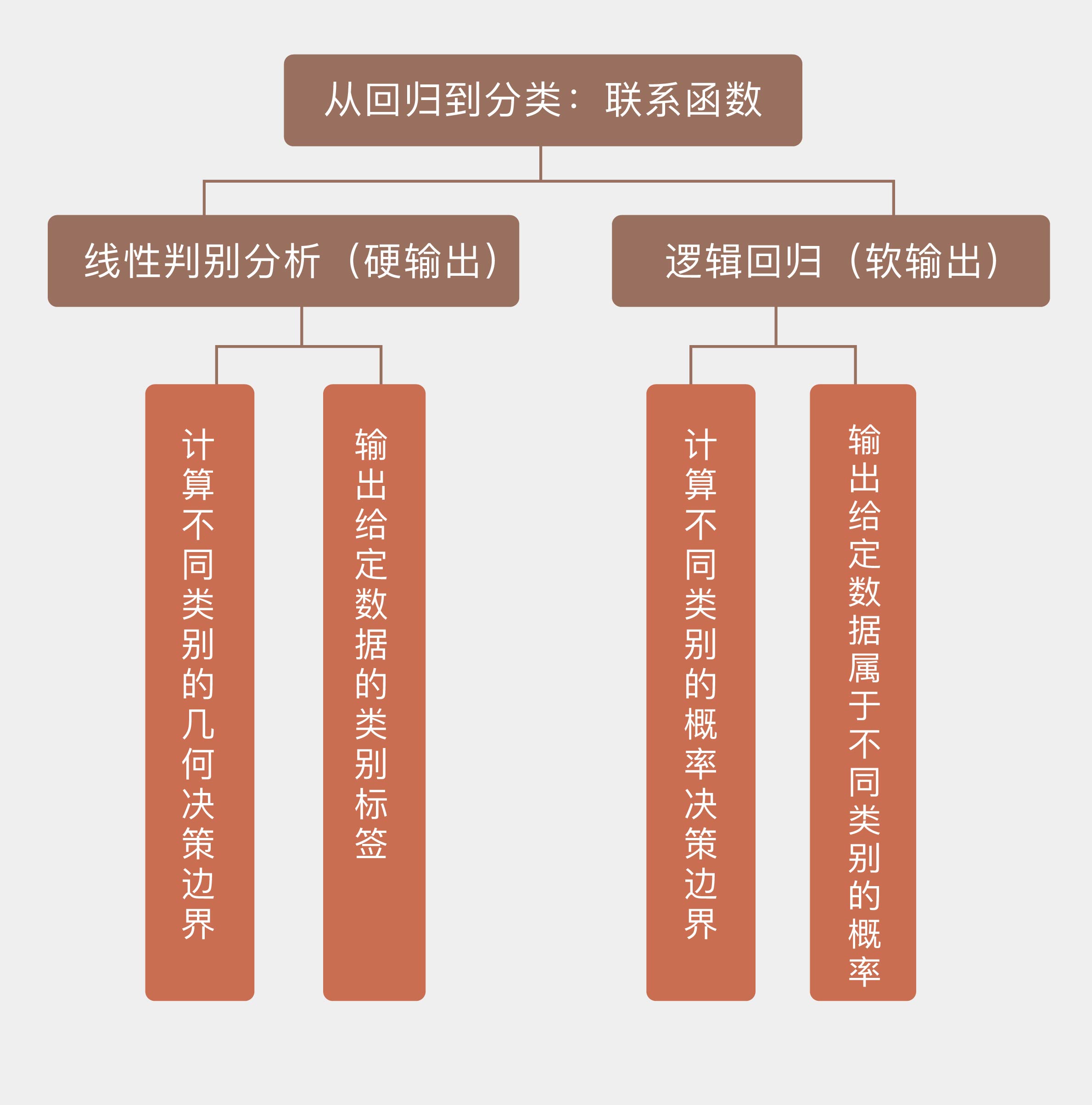
线性模型初被用来解决回归问题(regression),实际应用中最常用来解决分类问题。将回归结果转化为分类结果,其实就是将属性的线性组合转化成分类的标准,具体的操作方式有两种:一种是直接用阈值区分回归结果,根据回归值与阈值的关系直接输出样本类别的标签;另一种是用似然度区分回归结果,根据回归值和似然性的关系输出样本属于某个类别的概率。这两类输出可以分别被视为硬输出和软输出。
硬输出是对数据的分类边界进行建模。实现硬输出的函数,也就是将输入数据映射为输出类别的函数叫作判别函数(discriminant)。判别函数可以将数据空间划分成若干个决策区域,每个区域对应一个输出的类别。不同判别区域之间的分界叫作决策边界(decision boundary),对应着判别函数取得某个常数时所对应的图形。用线性模型解决分类问题,就意味着得到的决策边界具有线性的形状。
最简单的判别函数就是未经任何变换的线性回归模型 ,它将回归值大于某个阈值(可以通过调整截距 b设置为 0)的样本判定为正例,小于阈值的样本则判定为负例。
我们先来看看基于软输出的分类方法。软输出利用的是似然度,需要建立关于数据的概率密度的模型,常见的具体做法是对线性回归的结果施加某种变换,其数学表达式可以写成:
这里的被称为联系函数(link function),其反函数
则被称为激活函数(activation function)。正是联系函数架起了线性模型从回归到分类的桥梁。
最典型的软输出分类模型就是逻辑回归,逻辑回归(logistic regression)是基于概率的分类算法,估计的是样本归属于某个类别的后验概率,那么根据贝叶斯定理,二分类问题中的后验概率就可以写成
对这个表达式做个简单的变量代换,就可以得到
这里的表示对数几率函数(logistic function),也就是逻辑回归的联系函数,这个非线性的联系函数可以将任意输入映射到 [0, 1] 之间。对数几率函数的自变量 a可以改写成
逻辑回归并不能直接给出参数的解析解,因此需要结合最优化的方法使用。确定参数最常用的方式是使用最大似然估计(maximum likelihood estimation),找到如训练数据匹配度最高的一组参数。在二分类问题中,若假设当
属于类
时,输出的分类结果 r为 1,属于类
时,输出的分类结果 r 为 0,那么每个单独的分类结果都满足参数为
的两点分布,所有结果构成的向量
就会满足二项分布,这时的似然概率就可以写成分类结果的连乘
对似然概率求对数并求解最大值,就可以得到最优的参数了。
之前学习对数据进行线性降维和非线性降维方法,降维不光是数据预处理的一种手段,它还可以用来执行分类任务——本质上讲,分类问题就是将高维的数据投影到一维的类别标签上。好的分类算法既要让相同类别的数据足够接近,又要让不同类别的数据足够远离。基于这一原则进行分类的方法就是线性判别分析。
将线性模型扩展到分类问题中时,线性判别分析和逻辑回归作为两种具有代表性的模型,虽然实现的方式有所不同,但本篇所介绍的两种解决分类问题的方法在思想上是一致的,那就是根据数据的概率密度来实现分类。这两种基于似然度(likelihood-based)的模型在执行分类任务时不是以每个输入样本为单位,而是以每个输出类别为单位,将每个类别的数据看作不同的整体,并寻找它们之间的分野。相比之下,支持向量机使用的支持向量就是每个类别中若干个具有代表性的特例。
在 Scikit-learn 中,线性判别分析在模块 discriminant_analysis 中实现,逻辑回归则在模块 linear_model 中实现。由于逻辑回归需要使用有标签的数据,因而原来的回归数据就不能使用了。
对于二分类问题,LDA针对的是:数据服从高斯分布,且均值不同,方差相同。
对于二分类问题,QDA针对的是:数据服从高斯分布,且均值不同,方差不同。















 68
68











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









