







回归与分类
回归:在数学表示,数值是一个连续性的,要预测的一个值。回归分析是一种预测性的建模技术,它研究的是因变量和自变量之家的关系,这种技术通常用于预测分析,通过使用直线或曲线来拟合数据点,目标是使曲线到数据点的距离差异最小。
分类:分类模型可以将回归模型的输出离散化,数值是离散型的
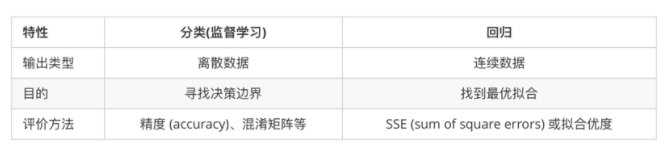
总结:定量输出为回归,即连续的变量预测,可以输出任意实数;定性输出为分类,即离散的变量预测,只能输出离散的值。
举例:预测明天的气温是多少度,这是一个回归问题;预测明天是阴天,晴天还是雨天,这是一个分类问题。
一、线性回归
定义:
线性回归是回归分析问题中的一种,线性回归假设自变量和因变量之间线性相关,即满足一个一元或多元一次方程,通过构建损失函数,来求解损失函数的参数。
能够用一个直线较为准确地描述数据之间的关系,这样当出现新的数据的时候,就能够预测出一个简单的值。
举例:
小王想要在商场开一家咖啡店,首先需要预测一下开这家店,是否可以赚钱呢?最后的应收取决于投入的成本,以及最后的收入。于是小王开始计算成本(包括:房屋费,设备费,装修费,人工费等等),而这些成本费是可以量化的。那么计算收入的时候,应该如何计算呢?这个时候就需要前提调研,统计数据,这份数据指的是商场的日均人流量和商场中同类型的咖啡店日均销售收入之间的关系。

这份数据不够直观,将人流量与销售收入之间的关系,以散点图的形式表示出来:

这个散点图看起来像一条直线,思考:可否采用线性回归模型来表示人流量与销售收入之间的这种关系!
线性回归:用一条直线表示两个变量之间的关系,当有了这个关系,再知道某一个变量的情况下,就能很容易得推算出另一个变量的数值,在我们这个例子中,这两个变量就是日均人流量和日均销售收入。

这里涉及到几个概念:第一个就是自变量,这里指的是商场的日均人流量,一般用x表示,第二个就是因变量,被预测的变量称为因变量,一般用y表示,这里指的是日均销售收入,还有一个就是线性方程,一条直线可以用y=kx+b来表示。
现在引入线性回归的概念:一个自变量和一个因变量,两者之间的关系可以用一条直线近似表示,这种回归被称为简单线性回归。
问题:
如何得到更合适的线性方程(如何得到这条直线)----->这条直线有多个画法,怎么找到最合适的呢,最能体现自变量和因变量之间的关系呢?

求解:
方法一:最小二乘法
方法二:梯度下降法,梯度下降法的核心内容是对自变量进行不断的更新(针对两个参数求偏导),使得目标函数不断逼近最小值的过程。这里主要讲述第一种方法。
(1)由线性回归可以估计y=kx+b
估计出来的值日均销售收入,用y冒来表示。而实际日均销售收入,用y来表示。我们希望y冒和y越相近越好,代表我们估计的值越准确。


这就是所谓的最小二乘法,这个平方和越大,代表预测值和实际值之间的差距越大,相反,这个平方和越小,代表预测值和实际值之间的差距越小。当这个平方和为0时,显然,估计值和实际值完全相同。
问题:
如何求解最小二乘法?
求解:
数学家已经推导出计算公式,即损失函数分别对两个参数求导,令导数等于0,即最小值。
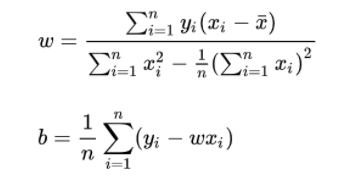
扩展:
(1)使用python的sklearn这个库来求解简单的线性回归方程或者使用matlab求解线性回归模型或者spss求解线性回归方程
视频教程:https://www.bilibili.com/video/BV1sJ411z7zJ
(2)多维线性回归
同样的操作,只不过损失函数的最小值,需要涉及到矩阵运算
二、逻辑回归
逻辑回归是做什么的?
逻辑回归是数据挖掘中的一种算法,用来解决二分类问题。
分类问题:
多种不同的动物以及它们的特征,比如青蛙,鸽子,猪,蝙蝠,鲸鱼等动物,特征有体温,胎生,水生,飞行,有腿等,那么每种动物属于不同的种类,有一条新的数据,知道它的一些特征,预测其属于哪一种类。这个问题就是一种分类问题。
这种判断每条数据所属类别的问题就叫做分类问题。

二分类问题:
目标列只有两种情况时,就是二分类问题

定义:
逻辑回归=线性回归+sigmoid函数

如何把回归变成分类呢?
依然回归上述咖啡店的场景,假如这家咖啡店的销售收入y小于130的时候,这家咖啡店是亏钱的,当销售收入y大于130的时候,这家咖啡店是赚钱的。从图中可以看出,红色这部分是亏钱,蓝色这部分是赚钱,那么映射到x轴,x小于等于14是亏钱的,x大于14是赚钱的,所以就将回归问题转换为分类问题。

sigmoid函数
回到前面的问题:逻辑回归=线性回归+sigmoid函数,其实就是上面例子中,通过某种转换方式,把回归问题转换为分类问题。直接理解sigmoid函数,就是下面这幅图:
这条函数图,定义域的取值范围是任意实数,而值域的取值范围是0-1之间的任意实数,当自变量趋于负无穷的时候,函数值趋于0,当自变量趋于正无穷的时,函数趋于1.

sigmoid函数是怎么起作用的?
线性回归模型的预测结果y=wx+b,该预测值可能是负无穷到正无穷之间的任意值。将该结果作为sigmoid函数的输入,经过sigmoid函数的转变,可以将最后的结果轻易的转换为0-1之间的某个数。
经过sigmoid函数后,我们还做这样一个操作,当函数的值小于0.5的时候,我们将其预测为0;当函数的值大于0.5的时候,我们将其预测为1------>这样我们就得到一个二分类的结果了。

逻辑回归公式推导


梯度下降法:
梯度:在微积分中,对多元函数的参数求偏导数,求得的各个参数的偏导数以向量的形式表示出来,就是梯度。
梯度的几何意义就是:函数变化增加最快的地方。沿着梯度向量的方向,梯度增加最快,更加容易找到函数的最大值,沿着梯度向量的反方向,梯度减少最快,更容易找到函数的最小值。
应用:在机器学习中,在最小化损失函数的时候,可以采用梯度下降法来一步步的迭代,得到最小化的损失函数和模型参数值。
直观解释:
比如我们位于大山上的某处位置,此时我们不知道如何下山,于是决定走一步算一步,也就是没走到一个位置的时候,就求解当前位置的梯度,沿着梯度的反方向,也就是最陡峭的位置向下走一步,然后继续求解当前位置的梯度,这样一步步的走下去,一直走到觉得我们已经到了山脚,其实,这样走下去,有可能我们不能走到山脚,而是走到了某一个局部的山峰低处。即梯度下降不一定能够找到局部的最优解,也可能是一个局部的最优解,但是,当我们的损失函数时凸函数,梯度下降法得到的解一定是全局最优解。




梯度下降算法:
- 批量梯度下降法(BGD)
- 随机梯度下降法(SGD)
- 小批量梯度下降法(MBGD)
参考链接:https://www.cnblogs.com/pinard/p/5970503.html
三、神经网络
用简单通俗的方式讲一下神经网络,简单来说,神经网络是一种模仿生物神经网络的结构和功能的数学模型,神经网络不仅仅是用来识别图片中的动物是猫还是狗,他现在也被应用于非常广泛的领域,比如我们熟知的自动驾驶,人脸识别,AI换脸等等,这些都是基于神经网络实现的。




通常我们在看论文或者一些学术报告中,看到的神经网络可能非常复杂,但是不要被它的高深外表所吓到。


我们知道大脑是由神经元组成的,几百亿个神经元组合起来构成了可以感知复杂世界并知道我们行动的大脑,但这其中的每一个神经元都只是决定要不要给下一个神经元发射信号而已。神经网络也是一样的,我们先从最简单的神经元说起,其实这其中的每一个神经元都可以理解成一个简单的逻辑回归算法。
举例说明
小王在商场开咖啡店的例子,必须要做的一件事就是预测一下咖啡店每天会有多少人进店,以此来判断咖啡店是否盈利。
假如他知道开在其他商场的同类咖啡店,每日进店人数和商场日均人流量的关系,那他就可以根据商场人流量来预测咖啡店的进店人数,只需要一个简单的线性回归就可以了,就是这样一条直线

一元线性回归就是输入特征只有一个,比如在这个例子中就只有商场人流量,那多元线性回归就是指输入的特征有多个,这种通过几个特征来预测结果的方式可以类比为一个神经元。稍有不同的是,神经网络里的神经元的线性回归还要经过一层激活函数(sigmoid函数),即逻辑回归里的两个函数嵌套关系,这样就避免了多个神经元连接之后,由于线性关系导致的深层无效了,其实每个神经元就只做了这么一点事情


咖啡店这个例子再丰富一点是这样的,小王想要预测他的咖啡店是否能盈利,他现在已经取得了一些数据,包括商场的人流量,人均消费水平,消费类型,性别比例,年龄分布等等信息。根据不同的数据,他能推测出不同的信息,比如通过人流量,消费类型和年龄分布可以推测出进店人数,根据人均消费,消费类型和性别比例,可以预测出人均购买咖啡的单价,再根据一些其他信息可以推测出买甜品的价格。这其中每一个源泉都是线性回归加上激活函数(sigmoid函数)的一个组合,当获得了进店人数,人均购买咖啡价格,人均购买甜品价格之后,又可以以这三种数据为输入,进一步进行预测,来推断出咖啡店是否盈利

小王根据最原始的特征,通过这样两层的预测就得到了他想要的结果,这样一个模型就是一个简单的神经网络了。在神经网络中最左侧这一层是一些输入的特征值,我们称为输入层。中间这一层是隐藏层,最右侧是输出结果,称之为输出层.

中间层之所以被称之为隐藏层,是因为在实际的神经网络中并不像前面例子中介绍的这样简单,目前还没有办法很好的解释中间各个节点所代表的含义,通过增加隐藏层的成熟和神经元的数量,可以构造出更加复杂的神经网络,在数据量大的情况下,层数的增加可以解决更复杂的问题,网址:https://playground.tensorflow.org/

学习神经网络非常有用的网站,可视化地展示了一些数据,展示了神经网络的构造,以及学习率,激活函数等
2013年纽约大学发表了一篇论文,这篇论文可视化了用于图像识别领域的卷积神经网络的不同层,第一层能识别出一些线条,第二层可以识别出简单的形状,第三层能识别出一些局部的信息,到第四层和第五层的时候,已经能识别出一些完整的图像了。




当然神经网路还是有一些相对复杂的结构的。比如卷积神经网络,加入了卷积层和池化层,使其在图像识别领域拥有了一席之地。再比如循环神经网络引入了记忆单元,使其在解决语音识别这种前后关联的问题中更有优势。
强烈推荐这个网站(https://playground.tensorflow.org/),可以动手搭建一个简单的神经网络体验一下,如果你想深入学习神经网络,那么吴恩达的课程绝对是不二选择,在推荐一本书deep learning界的“圣经”:Deep Learning

b站up主:等等很简单

四、深度学习
深度学习,按照我的个人理解就是多层神经网络。

深度学习的特点:
- 自动提取特征
- 通用的网络结构
传统上,识别一只猫需要提取特征,提取特征就有很多人工设计的环节,比如识别眼睛,眼睛下面有鼻子,鼻子下面有嘴巴等等,但是深度学习可以自动提取特征(只管告诉他这就是猫,进行训练即可),训练完成以后,就可以得到想要的结果。第二个特点就是深度学习是一个通过的网络结构,比如今天识别猫,明天识别狗,还是给他这样的网络结构,唯一的区别就是输入数据的时候是不同的,这就是深度学习使用的一些优点。
如何使用深度学习:

第一部分:数据预处理,需要消耗人工成本,在CV领域,包括三部分:分类,分割,检测

第二部分:训练
迁移学习:数据量不够,拿人的照片,狗的照片训练,训练完以后有基础的黑箱模型,在这个黑箱模型的基础上,再把猫的照片拿去训练,可以弥补没有足够多猫的照片数据的缺陷。

第三部分:测试及部署
















 7888
7888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









