







第一章 简介
1.1 同步
通常,“同步”意味着两件事情同时发生。在计算机系统中,同步更为通用;它指的是事件之间的关系 - 甚至是任何数量的事件,以及任何类型的关系(之前,期间,之后)。
计算机程序员经常关注同步约束,这是与事件顺序有关的要求。例子包括:
- 顺序执行(序列化):事件A必须在事件B之前发生。
- 相互排斥:事件A和事件B不得同时发生。
在现实生活中,我们经常使用时钟来检查并强制执行同步约束。我们如何知道A是否发生在B之前?如果我们知道两个事件发生的时间,就可以比较时间。
在计算机系统中,我们经常需要在没有时钟的情况下满足同步约束,或者因为没有统一的时钟,或者因为我们在事件发生时不能记录有足够精确的分辨率的时间。
这就是本书的内容:用于实施同步约束的软件技术。
1.2 执行模型
为了理解软件同步,您必须拥有计算机程序运行方式的模型。 在最简单的模型中,计算机按顺序执行一个接一个的指令。 在这个模型中,同步问题是可以忽略的;我们可以通过查看程序来判断事件的顺序。 如果语句A出现在语句B之前,A将先执行。
有两种情况会让事情变得复杂。一种情况是计算机是并行的,这意味着它有多个处理器在同时运行。在这种情况下,并不是很容易知道一个处理器上的某条语句是否在另一个处理器上的某条语句之前执行。
另一种情况是单处理器正在运行多个线程。线程是一系列顺序执行的指令。如果有多个线程,处理器可以先执行某个线程一段时间,然后切换到另一个,依此类推。
通常,程序员无法控制每个线程何时运行;这个是操作系统(特别是调度程序)决定的。那么,再重申一次,程序员无法判断不同线程中的语句会在何时执行(谁先谁后)。
出于同步的考虑,多处理器并行模型和单处理器多线程模型之间并没有区别。问题是相同的,即在一个处理器内(或一个线程内)我们能知道执行的顺序,但是在处理器之间(或者线程之间)我们是不可能知道的。
举一个现实世界的例子可能会使这一点更清楚。想象一下你和你的朋友鲍勃住在不同的城市,有一天吃饭的时候,你突然想知道那天中午你们谁先吃午饭。你怎么才能知道?
显然你可以打电话给他,问他什么时候吃午饭。但是如果你在你的手表显示11点59分开始吃午饭,鲍勃在他的手表显示12点01分开始吃午饭,你能确定谁先吃吗?除非你们的手表都对过时,并且走时非常准。但这可不一定哦。
计算机系统面临同样的问题,因为即使他们的时钟通常是准确的,它们的精度总是有限的。此外,大多数情况下,计算机无法记录事情发生的时间。有太多事情发生得太快,无法记录所有事件发生的确切的时间。
思考:假设鲍勃愿意遵循简单的指示,你有什么方法可以保证明天你会比鲍勃先吃午饭吗?
1.3 使用消息进行序列化
一种解决方案是告诉鲍勃在你给他打电话之前不要吃午饭。 然后,你确保在吃完午餐前不要打电话。 这种方法可能看起来毫无用处,但是,这种消息传递的办法却是解决许多同步问题的真正方案。 冒着挑战显而易见的事实的危险,请考虑下面这个时间表。
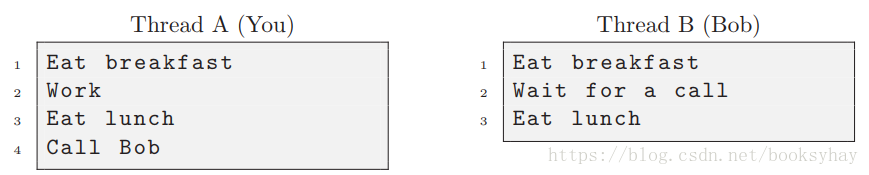
第一列是您执行的操作列表; 换句话说,你的执行线程。 第二列是Bob的执行线程。 在一个线程中,我们总能确定事情发生的顺序。 我们可以用下面的式子来表示事件发生的顺序。

其中,关系a1 <a2表示a1发生在a2之前。
一般情况下,无法比较来自不同线程的事件;例如,我们不知道谁先吃早餐(是a1 <b1?)
但是通过消息传递(电话)我们可以告诉谁先吃午餐(a3 <b3)。 假设Bob没有其他朋友,除了你之外,他不会接到其他电话,所以b2 > a4。 结合所有的关系,我们得到:
这就能证明你比鲍勃先吃午饭。
在这种情况下,我们会说你和鲍勃按顺序地吃午餐,因为我们知道事件发生的顺序。但你们可能是同时(并发)地吃早餐,因为我们不能确定谁先谁后。
当我们谈论并发事件时,很可能会说它们在同一个时刻发生,或者说同时发生。 作为简写,这样是可以的,只要你记住严格的定义:
如果我们不能通过查看程序来判断两个事件谁将首先发生,那么他们就是并发的。
有时,在程序运行之后,我们可以知道谁先发生了,但是,即便可以,通常也不能保证,下一次我们会得到同样的结果。
1.4 非决定论
并发程序通常是非确定性的,这意味着通过查看程序不可能告诉它在执行时会发生什么。
这是一个非确定性程序的简单示例:

因为两个线程并发执行,所以执行顺序取决于调度程序。 在该程序的给定的任何执行期间,输出可能是“yes no”或者“no yes”。
非确定性是使并发程序难以调试的事情之一。程序可能连续1000次正常工作,然后在第1001次运行时崩溃,具体取决于调度程序的特定策略。
通过测试几乎找不出这种类型的错误;只有仔细编程才能避免它。
1.5 共享变量
大多数情况下,大多数线程中的大多数变量都是局部变量,这意味着它们属于单个线程,没有其他线程可以访问它们。只要能确保这一点,往往不会有太多的同步问题,因为线程之间没有交互。
但通常一些变量在两个或多个线程之间共享;这是线程相互交互的方式之一。例如,在线程之间传递信息的一种方法是一个线程读取另一个线程写入的值。
如果线程是不同步的,那么我们无法通过查看程序来判断,“读者”读到的是“写者”写入的新值还是已经存在的旧值(“读者-写者”问题)。因此,许多应用程序强制执行“读者”在“写者”写入之前不能读取的约束。这正是1.3节中的序列化问题。
线程交互的其他方式是并发写入(两个或多个写入器)和并发更新(两个或多个线程执行读取后写入)。接下来的两节将讨论这些相互作用。共享变量的另一种可能的用途是并发读取,这通常不会产生同步问题。
1.5.1 并发写入
在以下示例中,x是由两个写入者访问的共享变量。

打印的x的值是多少? 所有这些语句执行后,x的最终值是多少? 它取决于语句的执行顺序,称为执行路径。 一条可能的路径是a1 <a2 <b1,在这种情况下,程序的输出为5,但最终值为7。
思考:什么路径会输出5,并且x的最终值也是5?
思考:什么路径会输出7,并且x的最终值是7?
思考:是否存在输出7,并且x的最终值为5的路径? 你能证明这个吗?
回答这些问题是并发编程的一个重要部分:可能的路径是什么,可能产生的影响是什么。 我们能否证明给定的(理想的)效果是必然的,或者(不良的)效果是不可能发生的?
1.5.2 并发更新
更新是这样的一种操作,它先读取变量的值,根据旧值计算新值,并写入新值。最常见的更新类型是增量运算,其中新值是旧值加1。 以下示例显示了共享变量count,由两个线程同时更新。

乍一看,这里存在的同步问题并不明显。只有两个执行路径,它们产生相同的结果。问题是这些操作在执行前会被翻译成机器语言,而在机器语言中,更新需要两个步骤,即读取和写入。 如果我们用临时变量temp重写代码,问题就更明显了。

现在考虑以下执行路径:
假设x的初始值为0,它的最终值是多少? 因为两个线程读取相同的初始值,所以它们写入相同的值。变量只增加一次,这可能是程序员没有想到的。
这种问题是微妙的,因为在高级程序中,并不总是能够分辨出哪些操作是在一个步骤中执行而哪些操作可以被中断。实际上,一些计算机提供了一个在硬件中实现并且不能被中断的增量指令。不能被中断的操作被认为是原子的。
那么如果我们不知道哪些操作是原子的,我们如何编写并发程序呢?一种可能性是收集关于每个硬件平台上的每个操作的特定信息。这种方法的缺点是显而易见的。
最常见的替代方案是保守假设所有更新和所有写入都不是原子的,并使用同步约束来控制对共享变量的并发访问。
最常见的约束是相互排除,或者叫互斥,我在1.1节中提到过。互斥可确保一次只有一个线程访问共享变量,从而消除了本节中的各种同步错误。
思考:假设100个线程同时运行以下程序:
(如果您不熟悉Python,for循环会运行100次更新。)

所有线程完成后,可能的最大计数值是多少?可能的最小值是多少?
提示:第一个问题很简单; 第二个不是。
1.5.3 使用消息实现互斥
与序列化一样,可以使用消息传递实现互斥。 例如,假设您和Bob操作从远程站监控的核反应堆。大多数时候,你们两个都在看警示灯,但你们都可以休息一下去吃午餐。谁先吃午餐并不重要,但重要的是,你们不要同时吃午餐,不要让反应堆掉下来!
思考:找出一个强制执行这些限制的消息传递系统(电话呼叫)。假设没有时钟,你无法预测午餐何时开始或持续多长时间。 所需的最少的消息数量是多少?














 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









