









本文的论文来自:
Notes on Convolutional Neural Networks, Jake Bouvrie。
这个主要是CNN的推导和实现的一些笔记,再看懂这个笔记之前,最好具有CNN的一些基础。这里也先列出一个资料供参考:
[1] Deep Learning(深度学习)学习笔记整理系列之(七)
[2] LeNet-5, convolutional neural networks
[3]卷积神经网络
[4] Neural Network for Recognition of Handwritten Digits
[5] Deep learning:三十八(Stacked CNN简单介绍)
[6] Gradient-based learning applied to document recognition.
[7]Imagenet classification with deep convolutional neural networks.
另外,这里有个matlab的Deep Learning的toolbox,里面包含了CNN的代码,在下一个博文中,我将会详细注释这个代码。这个笔记对这个代码的理解非常重要。
下面是自己对其中的一些知识点的理解:
《Notes on Convolutional Neural Networks》
一、介绍
这个文档讨论的是CNNs的推导和实现。CNN架构的连接比权值要多很多,这实际上就隐含着实现了某种形式的规则化。这种特别的网络假定了我们希望通过数据驱动的方式学习到一些滤波器,作为提取输入的特征的一种方法。
本文中,我们先对训练全连接网络的经典BP算法做一个描述,然后推导2D CNN网络的卷积层和子采样层的BP权值更新方法。在推导过程中,我们更强调实现的效率,所以会给出一些Matlab代码。最后,我们转向讨论如何自动地学习组合前一层的特征maps,特别地,我们还学习特征maps的稀疏组合。
二、全连接的反向传播算法
典型的CNN中,开始几层都是卷积和下采样的交替,然后在最后一些层(靠近输出层的),都是全连接的一维网络。这时候我们已经将所有两维2D的特征maps转化为全连接的一维网络的输入。这样,当你准备好将最终的2D特征maps输入到1D网络中时,一个非常方便的方法就是把所有输出的特征maps连接成一个长的输入向量。然后我们回到BP算法的讨论。(更详细的基础推导可以参考UFLDL中“反向传导算法”)。
2.1、Feedforward Pass前向传播
在下面的推导中,我们采用平方误差代价函数。我们讨论的是多类问题,共c类,共N个训练样本。
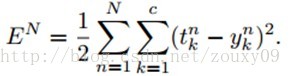
这里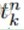
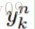
因为在全部训练集上的误差只是每个训练样本的误差的总和,所以这里我们先考虑对于一个样本的BP。对于第n个样本的误差,表示为:
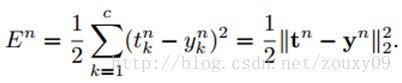
传统的全连接神经网络中,我们需要根据BP规则计算代价函数E关于网络每一个权值的偏导数。我们用l来表示当前层,那么当前层的输出可以表示为:
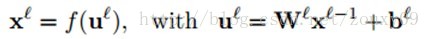
输出激活函数f(.)可以有很多种,一般是sigmoid函数或者双曲线正切函数。sigmoid将输出压缩到[0, 1],所以最后的输出平均值一般趋于0 。所以如果将我们的训练数据归一化为零均值和方差为1,可以在梯度下降的过程中增加收敛性。对于归一化的数据集来说,双曲线正切函数也是不错的选择。
2.2、Backpropagation Pass反向传播
反向传播回来的误差可以看做是每个神经元的基的灵敏度sensitivities(灵敏度的意思就是我们的基b变化多少,误差会变化多少,也就是误差对基的变化率,也就是导数了),定义如下:(第二个等号是根据求导的链式法则得到的)
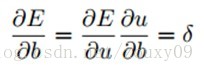
因为∂u/∂b=1,所以∂E/∂b=∂E/∂u=δ,也就是说bias基的灵敏度∂E/∂b=δ和误差E对一个节点全部输入u的导数∂E/∂u是相等的。这个导数就是让高层误差反向传播到底层的神来之笔。反向传播就是用下面这条关系式:(下面这条式子表达的就是第l层的灵敏度,就是)
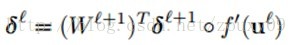
这里的“◦”表示每个元素相乘。输出层的神经元的灵敏度是不一样的:
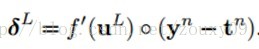
最后,对每个神经元运用delta(即δ)规则进行权值更新。具体来说就是,对一个给定的神经元,得到它的输入,然后用这个神经元的delta(即δ)来进行缩放。用向量的形式表述就是,对于第l层,误差对于该层每一个权值(组合为矩阵)的导数是该层的输入(等于上一层的输出)与该层的灵敏度(该层每个神经元的δ组合成一个向量的形式)的叉乘。然后得到的偏导数乘以一个负学习率就是该层的神经元的权值的更新了:
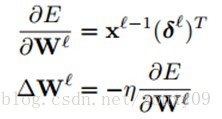
对于bias基的更新表达式差不多。实际上,对于每一个权值(W)ij都有一个特定的学习率ηIj。
三、Convolutional Neural Networks 卷积神经网络
3.1、Convolution Layers 卷积层
我们现在关注网络中卷积层的BP更新。在一个卷积层,上一层的特征maps被一个可学习的卷积核进行卷积,然后通过一个激活函数,就可以得到输出特征map。每一个输出map可能是组合卷积多个输入maps的值:
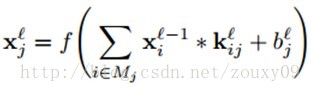
这里Mj表示选择的输入maps的集合,那么到底选择哪些输入maps呢?有选择一对的或者三个的。但下面我们会讨论如何去自动选择需要组合的特征maps。每一个输出map会给一个额外的偏置b,但是对于一个特定的输出map,卷积每个输入maps的卷积核是不一样的。也就是说,如果输出特征map j和输出特征map k都是从输入map i中卷积求和得到,那么对应的卷积核是不一样的。
3.1.1、Computing the Gradients梯度计算
我们假定每个卷积层l都会接一个下采样层l+1 。对于BP来说,根据上文我们知道,要想求得层l的每个神经元对应的权值的权值更新,就需要先求层l的每一个神经节点的灵敏度δ(也就是权值更新的公式(2))。为了求这个灵敏度我们就需要先对下一层的节点(连接到当前层l的感兴趣节点的第l+1层的节点)的灵敏度求和(得到δl+1),然后乘以这些连接对应的权值(连接第l层感兴趣节点和第l+1层节点的权值)W。再乘以当前层l的该神经元节点的输入u的激活函数f的导数值(也就是那个灵敏度反向传播的公式(1)的δl的求解),这样就可以得到当前层l每个神经节点对应的灵敏度δl了。
然而,因为下采样的存在,采样层的一个像素(神经元节点)对应的灵敏度δ对应于卷积层(上一层)的输出map的一块像素(采样窗口大小)。因此,层l中的一个map的每个节点只与l+1层中相应map的一个节点连接。
为了有效计算层l的灵敏度,我们需要上采样upsample 这个下采样downsample层对应的灵敏度map(特征map中每个像素对应一个灵敏度,所以也组成一个map),这样才使得这个灵敏度map大小与卷积层的map大小一致,然后再将层l的map的激活值的偏导数与从第l+1层的上采样得到的灵敏度map逐元素相乘(也就是公式(1))。
在下采样层map的权值都取一个相同值β,而且是一个常数。所以我们只需要将上一个步骤得到的结果乘以一个β就可以完成第l层灵敏度δ的计算。
我们可以对卷积层中每一个特征map j重复相同的计算过程。但很明显需要匹配相应的子采样层的map(参考公式(1)):
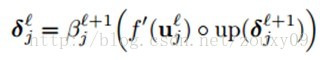
up(.)表示一个上采样操作。如果下采样的采样因子是n的话,它简单的将每个像素水平和垂直方向上拷贝n次。这样就可以恢复原来的大小了。实际上,这个函数可以用Kronecker乘积来实现:
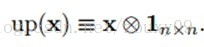
好,到这里,对于一个给定的map,我们就可以计算得到其灵敏度map了。然后我们就可以通过简单的对层l中的灵敏度map中所有节点进行求和快速的计算bias基的梯度了:
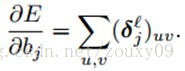
最后,对卷积核的权值的梯度就可以用BP算法来计算了(公式(2))。另外,很多连接的权值是共享的,因此,对于一个给定的权值,我们需要对所有与该权值有联系(权值共享的连接)的连接对该点求梯度,然后对这些梯度进行求和,就像上面对bias基的梯度计算一样:
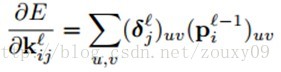
这里,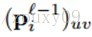
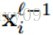
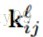
咋一看,好像我们需要煞费苦心地记住输出map(和对应的灵敏度map)每个像素对应于输入map的哪个patch。但实际上,在Matlab中,可以通过一个代码就实现。对于上面的公式,可以用Matlab的卷积函数来实现:
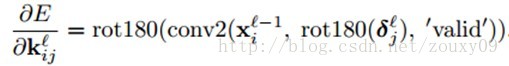
我们先对delta灵敏度map进行旋转,这样就可以进行互相关计算,而不是卷积(在卷积的数学定义中,特征矩阵(卷积核)在传递给conv2时需要先翻转(flipped)一下。也就是颠倒下特征矩阵的行和列)。然后把输出反旋转回来,这样我们在前向传播进行卷积的时候,卷积核才是我们想要的方向。
3.2、Sub-sampling Layers 子采样层
对于子采样层来说,有N个输入maps,就有N个输出maps,只是每个输出map都变小了。
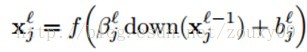
down(.)表示一个下采样函数。典型的操作一般是对输入图像的不同nxn的块的所有像素进行求和。这样输出图像在两个维度上都缩小了n倍。每个输出map都对应一个属于自己的乘性偏置β和一个加性偏置b。
3.2.1、Computing the Gradients 梯度计算
这里最困难的是计算灵敏度map。一旦我们得到这个了,那我们唯一需要更新的偏置参数β和b就可以轻而易举了(公式(3))。如果下一个卷积层与这个子采样层是全连接的,那么就可以通过BP来计算子采样层的灵敏度maps。
我们需要计算卷积核的梯度,所以我们必须找到输入map中哪个patch对应输出map的哪个像素。这里,就是必须找到当前层的灵敏度map中哪个patch对应与下一层的灵敏度map的给定像素,这样才可以利用公式(1)那样的δ递推,也就是灵敏度反向传播回来。另外,需要乘以输入patch与输出像素之间连接的权值,这个权值实际上就是卷积核的权值(已旋转的)。
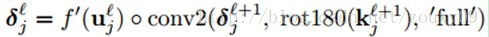
在这之前,我们需要先将核旋转一下,让卷积函数可以实施互相关计算。另外,我们需要对卷积边界进行处理,但在Matlab里面,就比较容易处理。Matlab中全卷积会对缺少的输入像素补0 。
到这里,我们就可以对b和β计算梯度了。首先,加性基b的计算和上面卷积层的一样,对灵敏度map中所有元素加起来就可以了:
而对于乘性偏置β,因为涉及到了在前向传播过程中下采样map的计算,所以我们最好在前向的过程中保存好这些maps,这样在反向的计算中就不用重新计算了。我们定义:
这样,对β的梯度就可以用下面的方式计算:
3.3、Learning Combinations of Feature Maps 学习特征map的组合
大部分时候,通过卷积多个输入maps,然后再对这些卷积值求和得到一个输出map,这样的效果往往是比较好的。在一些文献中,一般是人工选择哪些输入maps去组合得到一个输出map。但我们这里尝试去让CNN在训练的过程中学习这些组合,也就是让网络自己学习挑选哪些输入maps来计算得到输出map才是最好的。我们用αij表示在得到第j个输出map的其中第i个输入map的权值或者贡献。这样,第j个输出map可以表示为:
需要满足约束:
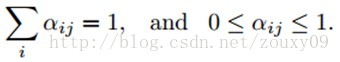
这些对变量αij的约束可以通过将变量αij表示为一个组无约束的隐含权值cij的softmax函数来加强。(因为softmax的因变量是自变量的指数函数,他们的变化率会不同)。
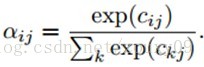
因为对于一个固定的j来说,每组权值cij都是和其他组的权值独立的,所以为了方面描述,我们把下标j去掉,只考虑一个map的更新,其他map的更新是一样的过程,只是map的索引j不同而已。
Softmax函数的导数表示为:
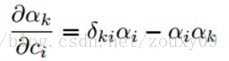
这里的δ是Kronecker delta。对于误差对于第l层变量αi的导数为:
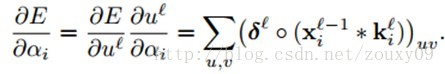
最后就可以通过链式规则去求得代价函数关于权值ci的偏导数了:
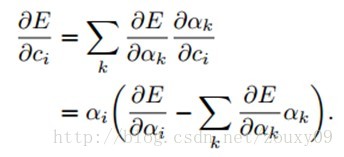
3.3.1、Enforcing Sparse Combinations 加强稀疏性组合
为了限制αi是稀疏的,也就是限制一个输出map只与某些而不是全部的输入maps相连。我们在整体代价函数里增加稀疏约束项Ω(α)。对于单个样本,重写代价函数为:
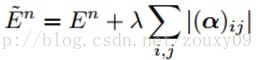
然后寻找这个规则化约束项对权值ci求导的贡献。规则化项Ω(α)对αi求导是:
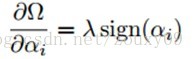
然后,通过链式法则,对ci的求导是:
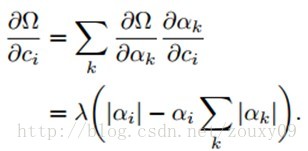
所以,权值ci最后的梯度是:
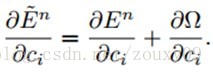
3.4、Making it Fast with MATLAB
CNN的训练主要是在卷积层和子采样层的交互上,其主要的计算瓶颈是:
1)前向传播过程:下采样每个卷积层的maps;
2)反向传播过程:上采样高层子采样层的灵敏度map,以匹配底层的卷积层输出maps的大小;
3)sigmoid的运用和求导。
对于第一和第二个问题,我们考虑的是如何用Matlab内置的图像处理函数去实现上采样和下采样的操作。对于上采样,imresize函数可以搞定,但需要很大的开销。一个比较快速的版本是使用Kronecker乘积函数kron。通过一个全一矩阵ones来和我们需要上采样的矩阵进行Kronecker乘积,就可以实现上采样的效果。对于前向传播过程中的下采样,imresize并没有提供在缩小图像的过程中还计算nxn块内像素的和的功能,所以没法用。一个比较好和快速的方法是用一个全一的卷积核来卷积图像,然后简单的通过标准的索引方法来采样最后卷积结果。例如,如果下采样的域是2x2的,那么我们可以用2x2的元素全是1的卷积核来卷积图像。然后再卷积后的图像中,我们每个2个点采集一次数据,y=x(1:2:end,1:2:end),这样就可以得到了两倍下采样,同时执行求和的效果。
对于第三个问题,实际上有些人以为Matlab中对sigmoid函数进行inline的定义会更快,其实不然,Matlab与C/C++等等语言不一样,Matlab的inline反而比普通的函数定义更非时间。所以,我们可以直接在代码中使用计算sigmoid函数及其导数的真实代码。
本文的代码来自githup的Deep Learning的toolbox,(在这里,先感谢该toolbox的作者)里面包含了很多Deep Learning方法的代码。是用Matlab编写的(另外,有人翻译成了C++和Python的版本了)。本文中我们主要解读下CNN的代码。详细的注释见代码。
里面包含的是我对一个作者的CNN笔记的翻译性的理解,对CNN的推导和实现做了详细的介绍,看明白这个笔记对代码的理解非常重要,所以强烈建议先看懂上面这篇文章。
下面是自己对代码的注释:
cnnexamples.m
- clear all; close all; clc;
- addpath('../data');
- addpath('../util');
- load mnist_uint8;
- train_x = double(reshape(train_x',28,28,60000))/255;
- test_x = double(reshape(test_x',28,28,10000))/255;
- train_y = double(train_y');
- test_y = double(test_y');
- %% ex1
- %will run 1 epoch in about 200 second and get around 11% error.
- %With 100 epochs you'll get around 1.2% error
- cnn.layers = {
- struct('type', 'i') %input layer
- struct('type', 'c', 'outputmaps', 6, 'kernelsize', 5) %convolution layer
- struct('type', 's', 'scale', 2) %sub sampling layer
- struct('type', 'c', 'outputmaps', 12, 'kernelsize', 5) %convolution layer
- struct('type', 's', 'scale', 2) %subsampling layer
- };
- % 这里把cnn的设置给cnnsetup,它会据此构建一个完整的CNN网络,并返回
- cnn = cnnsetup(cnn, train_x, train_y);
- % 学习率
- opts.alpha = 1;
- % 每次挑出一个batchsize的batch来训练,也就是每用batchsize个样本就调整一次权值,而不是
- % 把所有样本都输入了,计算所有样本的误差了才调整一次权值
- opts.batchsize = 50;
- % 训练次数,用同样的样本集。我训练的时候:
- % 1的时候 11.41% error
- % 5的时候 4.2% error
- % 10的时候 2.73% error
- opts.numepochs = 10;
- % 然后开始把训练样本给它,开始训练这个CNN网络
- cnn = cnntrain(cnn, train_x, train_y, opts);
- % 然后就用测试样本来测试
- [er, bad] = cnntest(cnn, test_x, test_y);
- %plot mean squared error
- plot(cnn.rL);
- %show test error
- disp([num2str(er*100) '% error']);
cnnsetup.m
- function net = cnnsetup(net, x, y)
- inputmaps = 1;
- % B=squeeze(A) 返回和矩阵A相同元素但所有单一维都移除的矩阵B,单一维是满足size(A,dim)=1的维。
- % train_x中图像的存放方式是三维的reshape(train_x',28,28,60000),前面两维表示图像的行与列,
- % 第三维就表示有多少个图像。这样squeeze(x(:, :, 1))就相当于取第一个图像样本后,再把第三维
- % 移除,就变成了28x28的矩阵,也就是得到一幅图像,再size一下就得到了训练样本图像的行数与列数了
- mapsize = size(squeeze(x(:, :, 1)));
- % 下面通过传入net这个结构体来逐层构建CNN网络
- % n = numel(A)返回数组A中元素个数
- % net.layers中有五个struct类型的元素,实际上就表示CNN共有五层,这里范围的是5
- for l = 1 : numel(net.layers) % layer
- if strcmp(net.layers{l}.type, 's') % 如果这层是 子采样层
- % subsampling层的mapsize,最开始mapsize是每张图的大小28*28
- % 这里除以scale=2,就是pooling之后图的大小,pooling域之间没有重叠,所以pooling后的图像为14*14
- % 注意这里的右边的mapsize保存的都是上一层每张特征map的大小,它会随着循环进行不断更新
- mapsize = floor(mapsize / net.layers{l}.scale);
- for j = 1 : inputmaps % inputmap就是上一层有多少张特征图
- net.layers{l}.b{j} = 0; % 将偏置初始化为0
- end
- end
- if strcmp(net.layers{l}.type, 'c') % 如果这层是 卷积层
- % 旧的mapsize保存的是上一层的特征map的大小,那么如果卷积核的移动步长是1,那用
- % kernelsize*kernelsize大小的卷积核卷积上一层的特征map后,得到的新的map的大小就是下面这样
- mapsize = mapsize - net.layers{l}.kernelsize + 1;
- % 该层需要学习的参数个数。每张特征map是一个(后层特征图数量)*(用来卷积的patch图的大小)
- % 因为是通过用一个核窗口在上一个特征map层中移动(核窗口每次移动1个像素),遍历上一个特征map
- % 层的每个神经元。核窗口由kernelsize*kernelsize个元素组成,每个元素是一个独立的权值,所以
- % 就有kernelsize*kernelsize个需要学习的权值,再加一个偏置值。另外,由于是权值共享,也就是
- % 说同一个特征map层是用同一个具有相同权值元素的kernelsize*kernelsize的核窗口去感受输入上一
- % 个特征map层的每个神经元得到的,所以同一个特征map,它的权值是一样的,共享的,权值只取决于
- % 核窗口。然后,不同的特征map提取输入上一个特征map层不同的特征,所以采用的核窗口不一样,也
- % 就是权值不一样,所以outputmaps个特征map就有(kernelsize*kernelsize+1)* outputmaps那么多的权值了
- % 但这里fan_out只保存卷积核的权值W,偏置b在下面独立保存
- fan_out = net.layers{l}.outputmaps * net.layers{l}.kernelsize ^ 2;
- for j = 1 : net.layers{l}.outputmaps % output map
- % fan_out保存的是对于上一层的一张特征map,我在这一层需要对这一张特征map提取outputmaps种特征,
- % 提取每种特征用到的卷积核不同,所以fan_out保存的是这一层输出新的特征需要学习的参数个数
- % 而,fan_in保存的是,我在这一层,要连接到上一层中所有的特征map,然后用fan_out保存的提取特征
- % 的权值来提取他们的特征。也即是对于每一个当前层特征图,有多少个参数链到前层
- fan_in = inputmaps * net.layers{l}.kernelsize ^ 2;
- for i = 1 : inputmaps % input map
- % 随机初始化权值,也就是共有outputmaps个卷积核,对上层的每个特征map,都需要用这么多个卷积核
- % 去卷积提取特征。
- % rand(n)是产生n×n的 0-1之间均匀取值的数值的矩阵,再减去0.5就相当于产生-0.5到0.5之间的随机数
- % 再 *2 就放大到 [-1, 1]。然后再乘以后面那一数,why?
- % 反正就是将卷积核每个元素初始化为[-sqrt(6 / (fan_in + fan_out)), sqrt(6 / (fan_in + fan_out))]
- % 之间的随机数。因为这里是权值共享的,也就是对于一张特征map,所有感受野位置的卷积核都是一样的
- % 所以只需要保存的是 inputmaps * outputmaps 个卷积核。
- net.layers{l}.k{i}{j} = (rand(net.layers{l}.kernelsize) - 0.5) * 2 * sqrt(6 / (fan_in + fan_out));
- end
- net.layers{l}.b{j} = 0; % 将偏置初始化为0
- end
- % 只有在卷积层的时候才会改变特征map的个数,pooling的时候不会改变个数。这层输出的特征map个数就是
- % 输入到下一层的特征map个数
- inputmaps = net.layers{l}.outputmaps;
- end
- end
- % fvnum 是输出层的前面一层的神经元个数。
- % 这一层的上一层是经过pooling后的层,包含有inputmaps个特征map。每个特征map的大小是mapsize。
- % 所以,该层的神经元个数是 inputmaps * (每个特征map的大小)
- % prod: Product of elements.
- % For vectors, prod(X) is the product of the elements of X
- % 在这里 mapsize = [特征map的行数 特征map的列数],所以prod后就是 特征map的行*列
- fvnum = prod(mapsize) * inputmaps;
- % onum 是标签的个数,也就是输出层神经元的个数。你要分多少个类,自然就有多少个输出神经元
- onum = size(y, 1);
- % 这里是最后一层神经网络的设定
- % ffb 是输出层每个神经元对应的基biases
- net.ffb = zeros(onum, 1);
- % ffW 输出层前一层 与 输出层 连接的权值,这两层之间是全连接的
- net.ffW = (rand(onum, fvnum) - 0.5) * 2 * sqrt(6 / (onum + fvnum));
- end
cnntrain.m
- function net = cnntrain(net, x, y, opts)
- m = size(x, 3); % m 保存的是 训练样本个数
- numbatches = m / opts.batchsize;
- % rem: Remainder after division. rem(x,y) is x - n.*y 相当于求余
- % rem(numbatches, 1) 就相当于取其小数部分,如果为0,就是整数
- if rem(numbatches, 1) ~= 0
- error('numbatches not integer');
- end
- net.rL = [];
- for i = 1 : opts.numepochs
- % disp(X) 打印数组元素。如果X是个字符串,那就打印这个字符串
- disp(['epoch ' num2str(i) '/' num2str(opts.numepochs)]);
- % tic 和 toc 是用来计时的,计算这两条语句之间所耗的时间
- tic;
- % P = randperm(N) 返回[1, N]之间所有整数的一个随机的序列,例如
- % randperm(6) 可能会返回 [2 4 5 6 1 3]
- % 这样就相当于把原来的样本排列打乱,再挑出一些样本来训练
- kk = randperm(m);
- for l = 1 : numbatches
- % 取出打乱顺序后的batchsize个样本和对应的标签
- batch_x = x(:, :, kk((l - 1) * opts.batchsize + 1 : l * opts.batchsize));
- batch_y = y(:, kk((l - 1) * opts.batchsize + 1 : l * opts.batchsize));
- % 在当前的网络权值和网络输入下计算网络的输出
- net = cnnff(net, batch_x); % Feedforward
- % 得到上面的网络输出后,通过对应的样本标签用bp算法来得到误差对网络权值
- %(也就是那些卷积核的元素)的导数
- net = cnnbp(net, batch_y); % Backpropagation
- % 得到误差对权值的导数后,就通过权值更新方法去更新权值
- net = cnnapplygrads(net, opts);
- if isempty(net.rL)
- net.rL(1) = net.L; % 代价函数值,也就是误差值
- end
- net.rL(end + 1) = 0.99 * net.rL(end) + 0.01 * net.L; % 保存历史的误差值,以便画图分析
- end
- toc;
- end
- end
cnnff.m
- function net = cnnff(net, x)
- n = numel(net.layers); % 层数
- net.layers{1}.a{1} = x; % 网络的第一层就是输入,但这里的输入包含了多个训练图像
- inputmaps = 1; % 输入层只有一个特征map,也就是原始的输入图像
- for l = 2 : n % for each layer
- if strcmp(net.layers{l}.type, 'c') % 卷积层
- % !!below can probably be handled by insane matrix operations
- % 对每一个输入map,或者说我们需要用outputmaps个不同的卷积核去卷积图像
- for j = 1 : net.layers{l}.outputmaps % for each output map
- % create temp output map
- % 对上一层的每一张特征map,卷积后的特征map的大小就是
- % (输入map宽 - 卷积核的宽 + 1)* (输入map高 - 卷积核高 + 1)
- % 对于这里的层,因为每层都包含多张特征map,对应的索引保存在每层map的第三维
- % 所以,这里的z保存的就是该层中所有的特征map了
- z = zeros(size(net.layers{l - 1}.a{1}) - [net.layers{l}.kernelsize - 1 net.layers{l}.kernelsize - 1 0]);
- for i = 1 : inputmaps % for each input map
- % convolve with corresponding kernel and add to temp output map
- % 将上一层的每一个特征map(也就是这层的输入map)与该层的卷积核进行卷积
- % 然后将对上一层特征map的所有结果加起来。也就是说,当前层的一张特征map,是
- % 用一种卷积核去卷积上一层中所有的特征map,然后所有特征map对应位置的卷积值的和
- % 另外,有些论文或者实际应用中,并不是与全部的特征map链接的,有可能只与其中的某几个连接
- z = z + convn(net.layers{l - 1}.a{i}, net.layers{l}.k{i}{j}, 'valid');
- end
- % add bias, pass through nonlinearity
- % 加上对应位置的基b,然后再用sigmoid函数算出特征map中每个位置的激活值,作为该层输出特征map
- net.layers{l}.a{j} = sigm(z + net.layers{l}.b{j});
- end
- % set number of input maps to this layers number of outputmaps
- inputmaps = net.layers{l}.outputmaps;
- elseif strcmp(net.layers{l}.type, 's') % 下采样层
- % downsample
- for j = 1 : inputmaps
- % !! replace with variable
- % 例如我们要在scale=2的域上面执行mean pooling,那么可以卷积大小为2*2,每个元素都是1/4的卷积核
- z = convn(net.layers{l - 1}.a{j}, ones(net.layers{l}.scale) / (net.layers{l}.scale ^ 2), 'valid');
- % 因为convn函数的默认卷积步长为1,而pooling操作的域是没有重叠的,所以对于上面的卷积结果
- % 最终pooling的结果需要从上面得到的卷积结果中以scale=2为步长,跳着把mean pooling的值读出来
- net.layers{l}.a{j} = z(1 : net.layers{l}.scale : end, 1 : net.layers{l}.scale : end, :);
- end
- end
- end
- % concatenate all end layer feature maps into vector
- % 把最后一层得到的特征map拉成一条向量,作为最终提取到的特征向量
- net.fv = [];
- for j = 1 : numel(net.layers{n}.a) % 最后一层的特征map的个数
- sa = size(net.layers{n}.a{j}); % 第j个特征map的大小
- % 将所有的特征map拉成一条列向量。还有一维就是对应的样本索引。每个样本一列,每列为对应的特征向量
- net.fv = [net.fv; reshape(net.layers{n}.a{j}, sa(1) * sa(2), sa(3))];
- end
- % feedforward into output perceptrons
- % 计算网络的最终输出值。sigmoid(W*X + b),注意是同时计算了batchsize个样本的输出值
- net.o = sigm(net.ffW * net.fv + repmat(net.ffb, 1, size(net.fv, 2)));
- end
cnnbp.m
- function net = cnnbp(net, y)
- n = numel(net.layers); % 网络层数
- % error
- net.e = net.o - y;
- % loss function
- % 代价函数是 均方误差
- net.L = 1/2* sum(net.e(:) .^ 2) / size(net.e, 2);
- %% backprop deltas
- % 这里可以参考 UFLDL 的 反向传导算法 的说明
- % 输出层的 灵敏度 或者 残差
- net.od = net.e .* (net.o .* (1 - net.o)); % output delta
- % 残差 反向传播回 前一层
- net.fvd = (net.ffW' * net.od); % feature vector delta
- if strcmp(net.layers{n}.type, 'c') % only conv layers has sigm function
- net.fvd = net.fvd .* (net.fv .* (1 - net.fv));
- end
- % reshape feature vector deltas into output map style
- sa = size(net.layers{n}.a{1}); % 最后一层特征map的大小。这里的最后一层都是指输出层的前一层
- fvnum = sa(1) * sa(2); % 因为是将最后一层特征map拉成一条向量,所以对于一个样本来说,特征维数是这样
- for j = 1 : numel(net.layers{n}.a) % 最后一层的特征map的个数
- % 在fvd里面保存的是所有样本的特征向量(在cnnff.m函数中用特征map拉成的),所以这里需要重新
- % 变换回来特征map的形式。d 保存的是 delta,也就是 灵敏度 或者 残差
- net.layers{n}.d{j} = reshape(net.fvd(((j - 1) * fvnum + 1) : j * fvnum, :), sa(1), sa(2), sa(3));
- end
- % 对于 输出层前面的层(与输出层计算残差的方式不同)
- for l = (n - 1) : -1 : 1
- if strcmp(net.layers{l}.type, 'c')
- for j = 1 : numel(net.layers{l}.a) % 该层特征map的个数
- % net.layers{l}.d{j} 保存的是 第l层 的 第j个 map 的 灵敏度map。 也就是每个神经元节点的delta的值
- % expand的操作相当于对l+1层的灵敏度map进行上采样。然后前面的操作相当于对该层的输入a进行sigmoid求导
- % 这条公式请参考 Notes on Convolutional Neural Networks
- % for k = 1:size(net.layers{l + 1}.d{j}, 3)
- % net.layers{l}.d{j}(:,:,k) = net.layers{l}.a{j}(:,:,k) .* (1 - net.layers{l}.a{j}(:,:,k)) .* kron(net.layers{l + 1}.d{j}(:,:,k), ones(net.layers{l + 1}.scale)) / net.layers{l + 1}.scale ^ 2;
- % end
- net.layers{l}.d{j} = net.layers{l}.a{j} .* (1 - net.layers{l}.a{j}) .* (expand(net.layers{l + 1}.d{j}, [net.layers{l + 1}.scale net.layers{l + 1}.scale 1]) / net.layers{l + 1}.scale ^ 2);
- end
- elseif strcmp(net.layers{l}.type, 's')
- for i = 1 : numel(net.layers{l}.a) % 第l层特征map的个数
- z = zeros(size(net.layers{l}.a{1}));
- for j = 1 : numel(net.layers{l + 1}.a) % 第l+1层特征map的个数
- z = z + convn(net.layers{l + 1}.d{j}, rot180(net.layers{l + 1}.k{i}{j}), 'full');
- end
- net.layers{l}.d{i} = z;
- end
- end
- end
- %% calc gradients
- % 这里与 Notes on Convolutional Neural Networks 中不同,这里的 子采样 层没有参数,也没有
- % 激活函数,所以在子采样层是没有需要求解的参数的
- for l = 2 : n
- if strcmp(net.layers{l}.type, 'c')
- for j = 1 : numel(net.layers{l}.a)
- for i = 1 : numel(net.layers{l - 1}.a)
- % dk 保存的是 误差对卷积核 的导数
- net.layers{l}.dk{i}{j} = convn(flipall(net.layers{l - 1}.a{i}), net.layers{l}.d{j}, 'valid') / size(net.layers{l}.d{j}, 3);
- end
- % db 保存的是 误差对于bias基 的导数
- net.layers{l}.db{j} = sum(net.layers{l}.d{j}(:)) / size(net.layers{l}.d{j}, 3);
- end
- end
- end
- % 最后一层perceptron的gradient的计算
- net.dffW = net.od * (net.fv)' / size(net.od, 2);
- net.dffb = mean(net.od, 2);
- function X = rot180(X)
- X = flipdim(flipdim(X, 1), 2);
- end
- end
cnnapplygrads.m
- function net = cnnapplygrads(net, opts)
- for l = 2 : numel(net.layers)
- if strcmp(net.layers{l}.type, 'c')
- for j = 1 : numel(net.layers{l}.a)
- for ii = 1 : numel(net.layers{l - 1}.a)
- % 这里没什么好说的,就是普通的权值更新的公式:W_new = W_old - alpha * de/dW(误差对权值导数)
- net.layers{l}.k{ii}{j} = net.layers{l}.k{ii}{j} - opts.alpha * net.layers{l}.dk{ii}{j};
- end
- end
- net.layers{l}.b{j} = net.layers{l}.b{j} - opts.alpha * net.layers{l}.db{j};
- end
- end
- net.ffW = net.ffW - opts.alpha * net.dffW;
- net.ffb = net.ffb - opts.alpha * net.dffb;
- end
cnntest.m
- function [er, bad] = cnntest(net, x, y)
- % feedforward
- net = cnnff(net, x); % 前向传播得到输出
- % [Y,I] = max(X) returns the indices of the maximum values in vector I
- [~, h] = max(net.o); % 找到最大的输出对应的标签
- [~, a] = max(y); % 找到最大的期望输出对应的索引
- bad = find(h ~= a); % 找到他们不相同的个数,也就是错误的次数
- er = numel(bad) / size(y, 2); % 计算错误率
- end















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









