






This Article Is From:https://examples.javacodegeeks.com/enterprise-java/apache-hadoop/hadoop-hello-world-example/
About Raman Jhajj
建议先看英文再看翻译:翻译使用的是Google翻译。
1.介绍
Hadoop是一个Apache软件基金会项目。 它是源自Google MapReduce和Google文件系统的开源版本。
它设计用于跨越通常在商品标准硬件上运行的系统集群的大数据集的分布式处理。
Hadoop被设计为假设所有硬件迟早失效,并且系统应该是鲁棒的并且能够自动处理硬件故障。
Apache Hadoop由两个核心组件组成,它们是:
1. 分布式文件系统简称Hadoop分布式文件系统或HDFS。
2. MapReduce作业的框架和API。
在这个例子中,我们将演示Hadoop框架的第二个组件,称为MapReduce,我们将通过Word Count Example(Hadoop生态系统的Hello World程序)来实现,但首先我们将了解MapReduce实际上是什么。
MapReduce基本上是一个软件框架或编程模型,它使用户能够编写程序,以便可以在集群中的多个系统上并行处理数据。 MapReduce由两部分Map和Reduce组成。
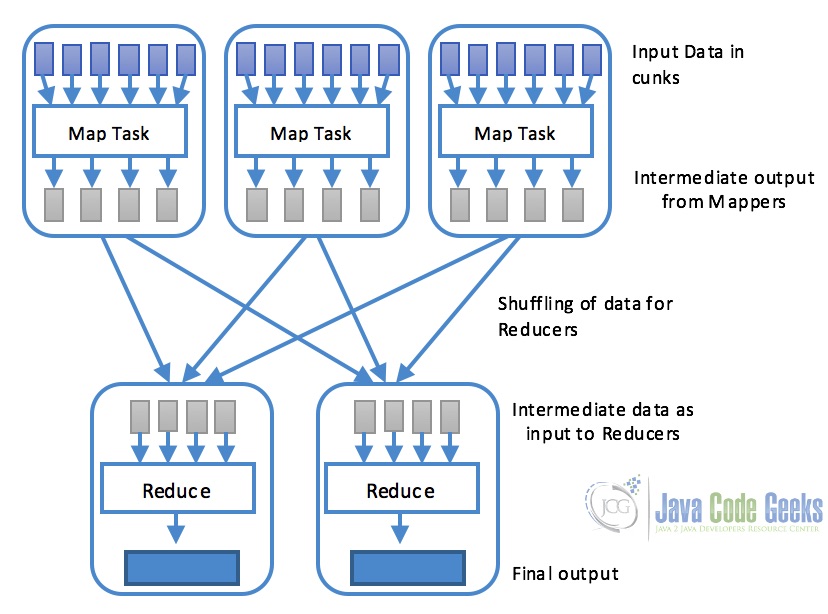
- Map:使用map()函数执行映射任务,该函数基本上执行过滤和排序。 该部分负责处理一个或多个数据块并产生通常称为中间结果的输出结果。 如下图所示,map任务通常是并行处理的,前提是映射操作是彼此独立的
- Reduce:通过reduce()函数执行减少任务,并执行汇总操作。 它负责合并每个Map任务产生的结果
2.Hadoop Word-Count示例
Word-Count示例是Hadoop和MapReduce的“Hello World”程序。 在此示例中,程序由MapReduce作业组成,该作业计算文件中每个单词的出现次数。 该作业由Map和Reduce两部分组成。 Map任务映射文件中的数据,并对提供给映射函数的数据块中的每个字进行计数。 这个任务的结果被传递给reduce,它将数据组合并在磁盘上输出最终结果。
2.1设置
我们将使用Maven为Hadoop字计数示例设置一个新项目。 在Eclipse中设置一个maven项目,并向pom.xml添加以下Hadoop依赖项。 这将确保我们具有对Hadoop核心库的所需访问权限。
pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>添加依赖关系后,我们准备好写我们的word-count代码。
2.2Mapper(映射器)代码
映射器任务负责基于空间对输入文本进行标记化,并创建单词列表,然后遍历所有标记并发出每个单词的键值对,计数为1,例如<Hello,1> 。 以下是MapClass,它需要扩展MapReduce Mapper类并覆盖map()方法。 此方法将接收要处理的输入数据的一块。 当这个方法被调用时,函数的value参数将把数据标记为字,并且上下文将写入中间输出,然后将其发送到一个reducer。
MapClass.java
package com.javacodegeeks.examples.wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MapClass extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer st = new StringTokenizer(line," ");
while(st.hasMoreTokens()){
word.set(st.nextToken());
context.write(word,one);
}
}
}2.3Reducer代码
以下代码片段包含ReduceClass,它扩展了MapReduce Reducer类并覆盖reduce()函数。 此函数在map方法之后调用,并接收键,在这种情况下是字以及相应的值。 Reduce方法对值进行迭代,在最终将单词和单词出现次数写入输出文件之前,将它们相加并将其减少为单个值。
ReduceClass.java
package com.javacodegeeks.examples.wordcount;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ReduceClass extends Reducer{
@Override
protected void reduce(Text key, Iterable values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
Iterator valuesIt = values.iterator();
while(valuesIt.hasNext()){
sum = sum + valuesIt.next().get();
}
context.write(key, new IntWritable(sum));
}
}2.4把它放在一起,驱动程序类
所以现在当我们的map和reduce类准备好了,现在是时候把它放在一起作为一个单一的工作,这是在一个叫做driver类的类。 此类包含用于设置和运行作业的main()方法。 以下代码检查正确的输入参数,它们是输入和输出文件的路径。 随后设置和运行作业。 最后,它通知用户作业是否成功完成。 带有字数的结果文件和相应的出现次数将出现在提供的输出路径中。
WordCount.java
package com.javacodegeeks.examples.wordcount;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool{
public static void main(String[] args) throws Exception{
int exitCode = ToolRunner.run(new WordCount(), args);
System.exit(exitCode);
}
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s needs two arguments, input and output
files\n", getClass().getSimpleName());
return -1;
}
Job job = new Job();
job.setJarByClass(WordCount.class);
job.setJobName("WordCounter");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
int returnValue = job.waitForCompletion(true) ? 0:1;
if(job.isSuccessful()) {
System.out.println("Job was successful");
} else if(!job.isSuccessful()) {
System.out.println("Job was not successful");
}
return returnValue;
}
}3.运行示例
测试代码实现。 我们可以从Eclipse本身运行程序用于测试目的。 首先,创建一个带有虚拟数据的input.txt文件。 为了测试的目的,我们在项目根目录中创建了一个带有以下文本的文件。
input.txt
This is the example text file for word count example also knows as hello world example of the Hadoop ecosystem.
This example is written for the examples article of java code geek
The quick brown fox jumps over the lazy dog.
The above line is one of the most famous lines which contains all the english language alphabets.在Eclipse中,传递项目参数中的输入文件和输出文件名。 以下是参数的样子。 在这种情况下,输入文件位于项目的根目录中,这就是为什么只需要filename,但如果输入文件位于其他位置,则应提供完整的路径。
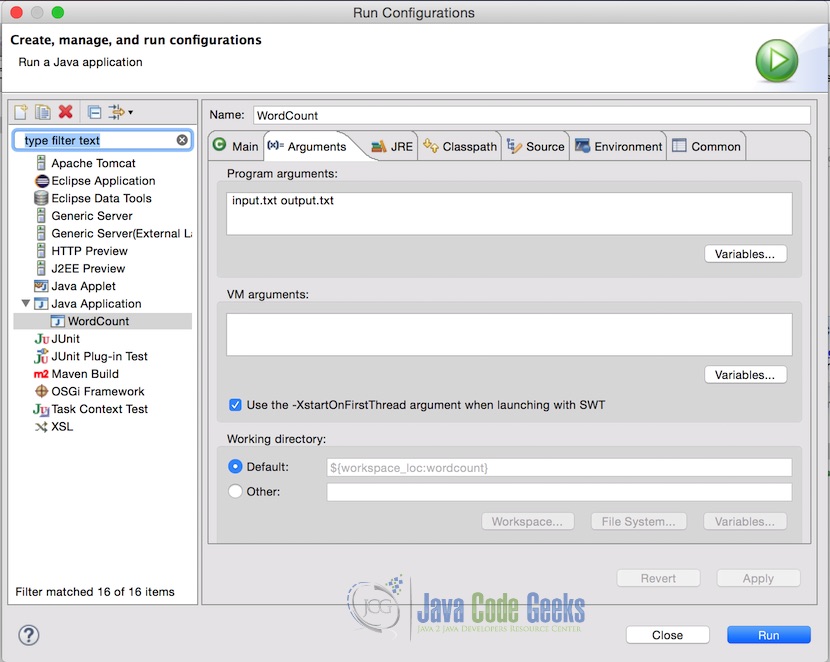
注意:确保输出文件不存在。 如果存在,程序将抛出一个错误。
设置参数后,只需运行应用程序。 成功完成应用程序后,控制台将显示输出
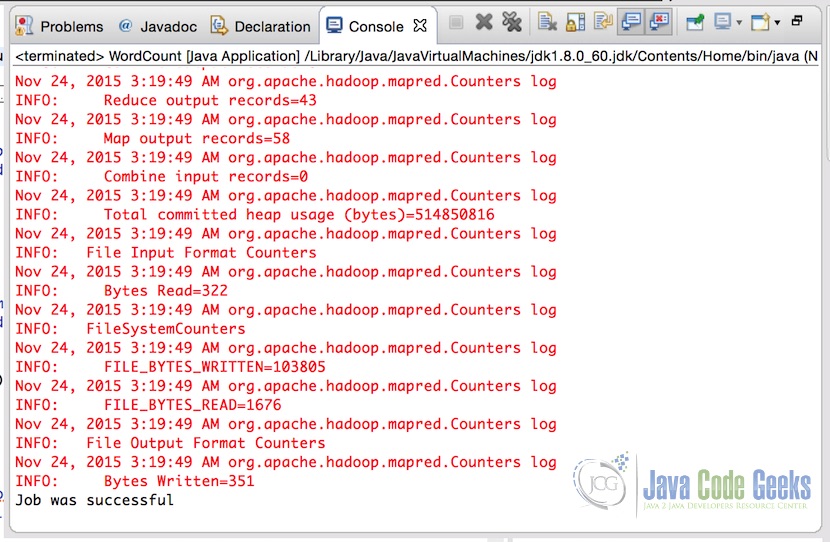
我们特别感兴趣的最后一行:
Job was successful这表示MapReduce作业的成功执行。 这意味着输出文件写入参数中提供的目标。 以下是所提供输入的输出文件的样子。
输出:
Hadoop 1
The 2
This 2
above 1
all 1
alphabets. 1
also 1
article 1
as 1
brown 1
code 1
contains 1
count 1
dog. 1
ecosystem. 1
english 1
example 4
examples 1
famous 1
file 1
for 2
fox 1
geek 1
hello 1
is 3
java 1
jumps 1
knows 1
language 1
lazy 1
line 1
lines 1
most 1
of 3
one 1
over 1
quick 1
text 1
the 6
which 1
word 1
world 1
written 1
4.下载完整的源代码
这是Hadoop MapReduce的Word Count(Hello World)程序的示例。
注:为提供持续可下载,已备份源代码至百度网盘:http://pan.baidu.com/s/1dEVrgyP















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









