





Hadoop版本:1.1.2
集成开发平台:Eclipse SDK 3.5.1
原创作品,转载请标明:http://blog.csdn.net/yming0221/article/details/9013381
1. 首先定义DFS Location(具体的环境搭建请看前面的博文)
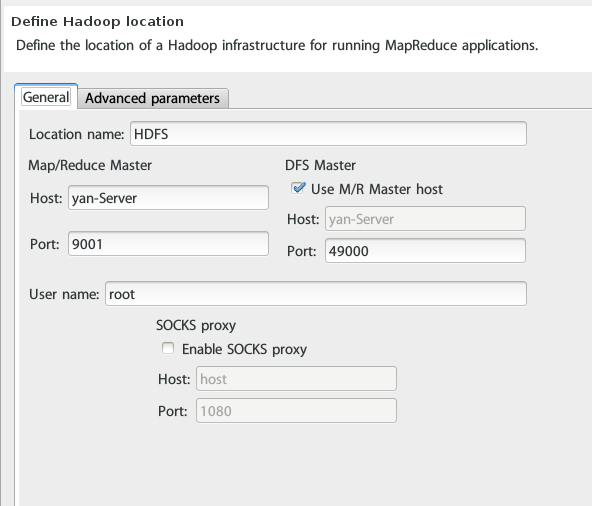
2.下面即是Hello World实例
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class wordcount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(wordcount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3. 运行结果
13/06/03 14:45:52 INFO input.FileInputFormat: Total input paths to process : 2
13/06/03 14:45:52 WARN snappy.LoadSnappy: Snappy native library not loaded
13/06/03 14:45:52 INFO mapred.JobClient: Running job: job_local_0001
13/06/03 14:45:52 INFO util.ProcessTree: setsid exited with exit code 0
13/06/03 14:45:52 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@2b96021e
13/06/03 14:45:52 INFO mapred.MapTask: io.sort.mb = 100
13/06/03 14:45:53 INFO mapred.MapTask: data buffer = 79691776/99614720
13/06/03 14:45:53 INFO mapred.MapTask: record buffer = 262144/327680
13/06/03 14:45:53 INFO mapred.MapTask: Starting flush of map output
13/06/03 14:45:53 INFO mapred.MapTask: Finished spill 0
13/06/03 14:45:53 INFO mapred.Task: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
13/06/03 14:45:53 INFO mapred.LocalJobRunner:
13/06/03 14:45:53 INFO mapred.Task: Task 'attempt_local_0001_m_000000_0' done.
13/06/03 14:45:53 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@3621767f
13/06/03 14:45:53 INFO mapred.MapTask: io.sort.mb = 100
13/06/03 14:45:53 INFO mapred.MapTask: data buffer = 79691776/99614720
13/06/03 14:45:53 INFO mapred.MapTask: record buffer = 262144/327680
13/06/03 14:45:53 INFO mapred.MapTask: Starting flush of map output
13/06/03 14:45:53 INFO mapred.MapTask: Finished spill 0
13/06/03 14:45:53 INFO mapred.Task: Task:attempt_local_0001_m_000001_0 is done. And is in the process of commiting
13/06/03 14:45:53 INFO mapred.LocalJobRunner:
13/06/03 14:45:53 INFO mapred.Task: Task 'attempt_local_0001_m_000001_0' done.
13/06/03 14:45:53 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@76d6d675
13/06/03 14:45:53 INFO mapred.LocalJobRunner:
13/06/03 14:45:53 INFO mapred.Merger: Merging 2 sorted segments
13/06/03 14:45:53 INFO mapred.Merger: Down to the last merge-pass, with 2 segments left of total size: 53 bytes
13/06/03 14:45:53 INFO mapred.LocalJobRunner:
13/06/03 14:45:53 INFO mapred.JobClient: map 100% reduce 0%
13/06/03 14:45:53 INFO mapred.Task: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
13/06/03 14:45:53 INFO mapred.LocalJobRunner:
13/06/03 14:45:53 INFO mapred.Task: Task attempt_local_0001_r_000000_0 is allowed to commit now
13/06/03 14:45:53 INFO output.FileOutputCommitter: Saved output of task 'attempt_local_0001_r_000000_0' to output
13/06/03 14:45:53 INFO mapred.LocalJobRunner: reduce > reduce
13/06/03 14:45:53 INFO mapred.Task: Task 'attempt_local_0001_r_000000_0' done.
13/06/03 14:45:54 INFO mapred.JobClient: map 100% reduce 100%
13/06/03 14:45:54 INFO mapred.JobClient: Job complete: job_local_0001
13/06/03 14:45:54 INFO mapred.JobClient: Counters: 22
13/06/03 14:45:54 INFO mapred.JobClient: File Output Format Counters
13/06/03 14:45:54 INFO mapred.JobClient: Bytes Written=25
13/06/03 14:45:54 INFO mapred.JobClient: FileSystemCounters
13/06/03 14:45:54 INFO mapred.JobClient: FILE_BYTES_READ=18029
13/06/03 14:45:54 INFO mapred.JobClient: HDFS_BYTES_READ=63
13/06/03 14:45:54 INFO mapred.JobClient: FILE_BYTES_WRITTEN=213880
13/06/03 14:45:54 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=25
13/06/03 14:45:54 INFO mapred.JobClient: File Input Format Counters
13/06/03 14:45:54 INFO mapred.JobClient: Bytes Read=25
13/06/03 14:45:54 INFO mapred.JobClient: Map-Reduce Framework
13/06/03 14:45:54 INFO mapred.JobClient: Reduce input groups=3
13/06/03 14:45:54 INFO mapred.JobClient: Map output materialized bytes=61
13/06/03 14:45:54 INFO mapred.JobClient: Combine output records=4
13/06/03 14:45:54 INFO mapred.JobClient: Map input records=2
13/06/03 14:45:54 INFO mapred.JobClient: Reduce shuffle bytes=0
13/06/03 14:45:54 INFO mapred.JobClient: Physical memory (bytes) snapshot=0
13/06/03 14:45:54 INFO mapred.JobClient: Reduce output records=3
13/06/03 14:45:54 INFO mapred.JobClient: Spilled Records=8
13/06/03 14:45:54 INFO mapred.JobClient: Map output bytes=41
13/06/03 14:45:54 INFO mapred.JobClient: CPU time spent (ms)=0
13/06/03 14:45:54 INFO mapred.JobClient: Total committed heap usage (bytes)=683409408
13/06/03 14:45:54 INFO mapred.JobClient: Virtual memory (bytes) snapshot=0
13/06/03 14:45:54 INFO mapred.JobClient: Combine input records=4
13/06/03 14:45:54 INFO mapred.JobClient: Map output records=4
13/06/03 14:45:54 INFO mapred.JobClient: SPLIT_RAW_BYTES=226
13/06/03 14:45:54 INFO mapred.JobClient: Reduce input records=4文件输出结果:
hadoop 1
hello 2
world 1
4. 结果分析
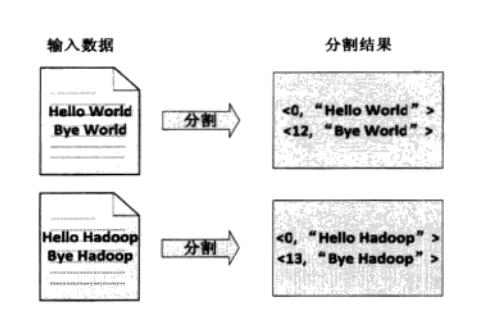
4.1 首先文件会被切割成splits,大文件切割成小文件块,这里文件都很小,一个文件就是一个split,然后将文件按行分割,分割成<key,value>对。该步骤是由MapReduce自动完成。如下图
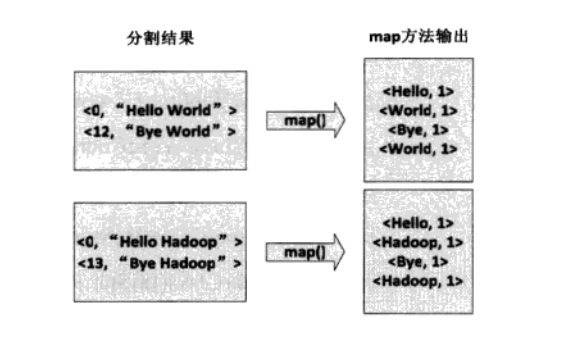
4.2 将上面的<key,value>对交给用户定义的map处理,生成<key1,value1>键值对
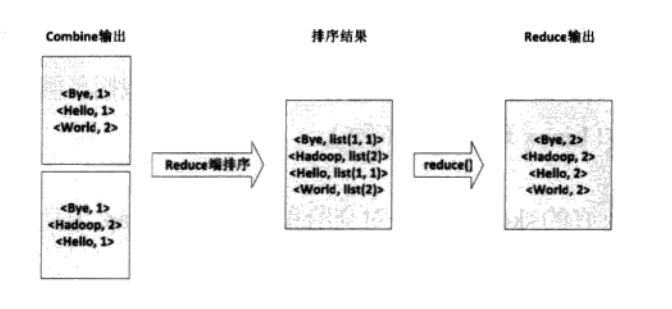
4.3 得到<key1,value1>后Mapper会按照key1对其进行排序。如果定义了Combine函数,将会对这些排序后的相同的键值对进行合并。然后进行交给Reducer。一般情况下该函数和reduce函数设置成相同的。得到<key2,value2>键值对
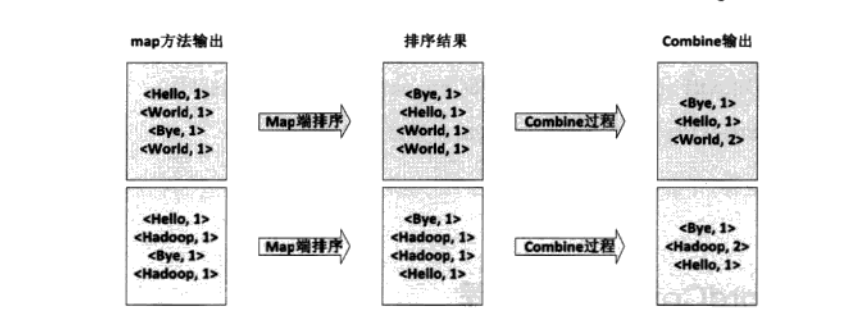
4.4 生成的中间结果交给Reduce处理,Reduce端首先把收来的数据进行排序,生成<key3,list(value3)>键值(可能是多个)对,然后交给用户定义的reduce函数处理。最后生成最后的<key4,value4>键值对,并输出到DFS文件中。















 3510
3510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









