






Benchmarking Regression Methods: A comparison with CGAN [arXiv 1905.12868]
简介
GAN几乎没有应用在具有小尺寸输出空间的问题上。一个很好的例子就是涉及映射的归纳学习的回归问题: 输出( y ∈ R m y∈\mathbb R^m y∈Rm)是输入( x ∈ R n x∈\mathbb R^n x∈Rn)的连续随机函数, y = f ( x , z ) y = f(x, z) y=f(x,z), z ∈ R k z∈\mathbb R^k z∈Rk表示噪声, f : R n × R k → R m f: \mathbb R^n×\mathbb R^k→\mathbb R^m f:Rn×Rk→Rm,其中m很小(例如,m = 1或只有几个)。
解决回归问题的标准方法是 将输出 y y y 作为 均值函数 m ( x ) m(x) m(x) 和噪声项 z z z 的 和 的概率模型( y = m ( x ) + z y=m(x)+z y=m(x)+z); 把噪声设为高斯分布( z ∼ N ( 0 , Σ ) z∼ \mathcal N(0,Σ) z∼N(0,Σ))也是很常见的。这样做是为了方便,这样观测数据的似然likelihood可以用封闭的形式cloaed form表示。但是,在现实世界中,输出的随机性通常是由输入变量的缺失或噪声引起的。这种真实的情况最好使用一个隐式模型来表示,在这个模型中,一个额外的噪声向量 z z z包含在 x x x中作为输入( y = f ( x , z ) y=f(x, z) y=f(x,z))。CGAN自然适合设计这样的隐式模型。本文在这方面迈出了第一步,并将现有的回归方法与CGAN进行了比较。
但是,我们注意到,现有的混合密度网络(MDN) 和XGBoost之类的方法在概率和平均绝对误差方面优于CGAN。这两种方法都比CGAN相对容易训练。 CGAN需要更多的创新,以相对于现有的回归求解器具有可比的建模和易于培训。总之,对于建模不确定性,MDN更好,而在精确预测更重要的情况下,XGBoost更好。
传统回归与CGAN处理的回归
传统回归方法中的大多数以加法方式对噪声建模: y = f ^ ( x ) + z y=\hat f(x)+z y=f^(x)+z。加性噪声建模additive noise modeling 还有一些扩展类型:异方差回归heteroscedastic regression,选择其中的噪声 z z z作为 x x x的函数;多模态后验的回归regression with multi-modal posteriors, p ( y ∣ x ) p(y | x) p(y∣x)是多模态分布。通常,为每种此类建模开发一套单独的方法,例如扩展的异方差GP方法[3]。
上述所有模型都是
y
=
f
(
x
,
z
)
y = f(x, z)
y=f(x,z) 的特例。同样,在现实世界的系统中,噪声如何进入真正的
y
y
y 生成过程通常是未知的,因此,理想情况下,最好将其置于非参数方法中以形成
f
f
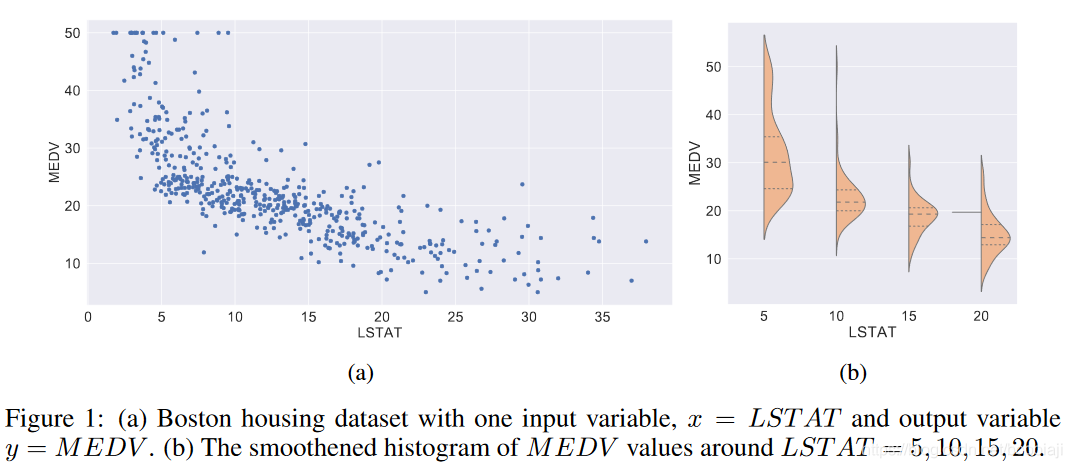
f。例如,在许多情况下,由于一些输入变量是未知的,并且与已知变量以非线性方式结合在一起。通常,未知变量集的维数也是未知的。用Boston Housing dataset举例,在x取不同值时,需要对应不同值的z。
 求解
y
=
f
(
x
,
z
)
y = f(x, z)
y=f(x,z) 的主要困难在于它是一个隐式概率模型,因此,要形成并使用密度函数
p
(
y
∣
x
)
p(y | x)
p(y∣x) 很难。条件生成对抗网络(CGAN)正好可以解决这一难题。CGAN使用一个辅助的非参数函数(如DNN)来模拟 公式中的隐式概率输出模型 与 训练样本所表示的真实
p
(
y
∣
x
)
p(y | x)
p(y∣x) 之间的损失函数(如Jenson-Shannon或KL散度)。
求解
y
=
f
(
x
,
z
)
y = f(x, z)
y=f(x,z) 的主要困难在于它是一个隐式概率模型,因此,要形成并使用密度函数
p
(
y
∣
x
)
p(y | x)
p(y∣x) 很难。条件生成对抗网络(CGAN)正好可以解决这一难题。CGAN使用一个辅助的非参数函数(如DNN)来模拟 公式中的隐式概率输出模型 与 训练样本所表示的真实
p
(
y
∣
x
)
p(y | x)
p(y∣x) 之间的损失函数(如Jenson-Shannon或KL散度)。
但是,CGAN主要应用于图像等领域,其中图像的尺寸(n, m) 较大(数千),噪声尺寸(k) 较小(十至二十个)。很少有人努力探索使用CGAN解决 k≥m 的回归问题。本文旨在填补这一空白。我们实现了用于回归分析的基本CGAN,而无需对超参数进行任何广泛的调整。我们采用最新的回归方法,例如高斯过程(Gaussian processes, GPs),深层神经网络(Deep neural nets, DNN)和XGboost作为基准方法来比较和评估CGAN。使用综合数据集,我们证明,CGAN具有自然的,更好的建模复杂噪声形式的能力。我们还对七个现实世界的数据集进行了实验,以证明即使是我们对CGAN的直接适应也可以与最新的回归方法竞争。最后,我们指出了CGAN回归的几个优点和改进。因此,非常有必要对CGAN在回归上的应用进行进一步的研究,重点是提高CGAN的性能,效率和鲁棒性。
建立 用于生成接近基础数据的分布 的模型一直是机器学习研究的主题。大多数生成模型都采用概率密度函数的特定形式(例如一个具有高斯加性噪声的 均值的非线性函数 a nonlinear function for the mean)来最大化数据的似然。可以使用核方法,深层网络,增强树boosted trees等来形成非线性函数。也可以在这种设计上应用贝叶斯方法以获得改善的似然性——一个很好的例子是高斯过程(GP)。对于更复杂的噪声形式,例如异方差噪声,必须建立专门的模型[3]。生成对抗网络(GAN)已被证明具有使用隐式概率建模生成基础分布的真实样本的强大能力,且没有对概率密度函数的性质进行任何特定假设。
然而,大多数研究集中在具有较大结构化输出空间的图像域上。很少有人将GAN应用于其他类型的问题,例如回归通常具有较小的输出空间的问题。在这项研究中,我们隐式地使用 y = f ( x , z ) y = f(x, z) y=f(x,z)生成了连续输出分布,其中zhasa指定了分布并且使用深网建模 f f f;我们使用CGAN方法设计此模型。 Chapfuwa等 [Adversarial time-to-event modeling] 特别将CGAN与生存分析一起用于事件建立时间模型。
实验设置
我们使用标准的CGAN公式,其中鉴别器网络对应于最小化真实和模型 p ( y ∣ x ) p(y | x) p(y∣x)分布之间的Jenson-Shannon散度。或者,可以使用Wasserstein GAN或f-GAN的思想来最小化KL散度[10]。请注意,这些模型中的每一个都优化了不同的损失函数,这可能会影响性能。
我们在每个实验中报告两个指标:负对数预测密度(NLPD)和平均绝对误差(MAE)。 NLPD被视为主要的关注指标,因为对于许多现实世界的回归问题而言,研究估计值的不确定性非常重要。
使用Parzen窗口计算的NLPD 由于CGAN隐式建模 p ( y ∣ x ) p(y | x) p(y∣x),因此只能为每个给定的x生成y的样本。在GAN文献中,使用Parzen窗利用这些样本近似 p ( y ∣ x ) p(y | x) p(y∣x),然后将其用于评估NLPD。我们在本文中也做同样的事情。我们为每个x生成100个样本,以构建Parzen窗口分布。请注意,概率密度可以取无限的正值,因此NLPD可以为负。
MAE 给定一个测试数据集 { ( x i , y i ) } i = 1 N \{(x_i,y_i)\} ^N_{i = 1} {(xi,yi)}i=1N,用于定义为 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ \tfrac1N∑^N_{i = 1} | y_i- \hat y_i | N1∑i=1N∣yi−y^i∣的回归数的MAE。其中 y ^ i \hat y_i y^i 是回归器在 x = x i x = x_i x=xi 处返回的单个中心值a single central value。对于产生分布 p ( y ∣ x i ) p(y | x_i) p(y∣xi) 的回归变量 (回归方程的独立变量,回归因子),我们定义 y ^ i \hat y_i y^i 为 p ( y ∣ x i ) p(y | x_i) p(y∣xi) 的中位数;注意,中位数是使平均绝对误差最小的中心估计。对于GP, p ( y ∣ x i ) p(y | x_i) p(y∣xi) 是高斯型,因此 y ^ i \hat y_i y^i 是模型返回的 p ( y ∣ x i ) p(y | x_i) p(y∣xi) 的平均值。对于CGAN,我们针对给定的 x i x_i xi生成一个100 y值的样本,并将样本点的中位数设为 y i y_i yi。
-
m
(
x
i
)
m(x_i)
m(xi)和
σ
2
(
x
i
)
\sigma^2(x_i)
σ2(xi)是点 xi 的均值和方差。NLPD对预测和不确定性的估计很敏感
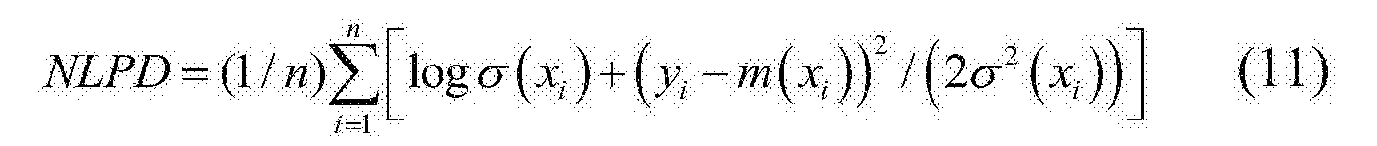
报告指标时的置信和不确定性 给定CGAN方法评估的潜在不确定性(取决于从 p ( y ∣ x ) p(y | x) p(y∣x) 采样出的样本),我们报告了10次运行评估的均值。我们发现这些不同样本的评估值标准差比均值小( < 1 0 − 3 <10^{-3} <10−3)。在后面的部分中,当我们报告评估指标时,它们是10次运行的平均值;粗体值意味着该方法在该度量上显著优于其他模型。
数据集 我们使用两种类型的数据集:合成数据集和真实数据集。我们生成了四个数据集,这些数据集在公式 y = f ( x , z ) y=f(x, z) y=f(x,z) 中的噪声和 f f f 函数的性质方面越来越复杂。这些数据集的描述及其结果在下节中给出。我们使用了七个真实的数据集(有关结果,请参见第7节),这些数据集取自http://www.dcc.fc.up.pt/~ltorgo/Regression/DataSets.html。
预处理 对合成数据和现实世界数据使用了不同的预处理策略。在现实世界中的实验中,输入特征被缩放为零均值和单位方差。在合成数据集上,我们不对特征进行缩放,因为它们已经具有合理标准化的输入和输出范围。
基准模型 大多数从业人员都使用GP,DNN和Boosted树(XGboost)作为最新的回归求解器。对于GP,我们使用GPy软件包[12]进行自动超参数优化。我们尝试了径向基核函数(RBF)和有理二次(Quad)核。我们将Keras [13]用于DNN。对于XGboost,我们使用XGboost软件包[7]。所有这些模型都基于加性高斯噪声模型。虽然GP直接提供NLPD值,但我们使用高斯似然假设来计算DNN和XGboost的NLPD值。
超参数调整超 参数调整是使用验证集完成的。调整超参数以最大程度地减少NLPD,因为这是我们关注的主要指标。
我们将DNN用于CGAN。以下是我们实验中使用的CGAN架构的详细信息。我们在所有实验中都使用一种基本架构。生成器使用六层网络。我们通过三层MLP分别输入输入x和噪声z,并将输出表示连接到三层网络。除了使用线性激活的最后一层,我们使用指数线性单位(ELU) 作为激活函数。从z到最终线性单元的直接连接可以帮助建模附加噪声,但这不是必需的。我们通常发现ELU比诸如ReLU,leaky-ReLU或tanh的激活更好地工作。鉴别器使用四层网络。它通过单个非线性层馈送输入x和y,然后将连接的输出传递给三层MLP,后者的最后一层使用sigmoid激活。
上面的架构在综合数据集上运行良好。通常,以下选择的每层神经元数量通常效果很好:40个神经元用于复杂噪声数据集(异方差和多模态),而15个神经元用于简单加性噪声数据集(线性和正弦波)。对于现实世界的数据集,我们增加了层和神经元的数量。对于现实世界的数据集,我们使用七层网络,其中x和噪声z的一层大小为100,其输出被连接并传递到另一组大小为50的六层。对于DNN baseline,我们使用相同的体系结构,但使用ReLU激活,因为在我们的实验中效果更好。
我们使用Adam优化器并以{ 1 0 − 2 , 1 0 − 3 , 1 0 − 4 10^{−2}, 10^{−3}, 10^{−4} 10−2,10−3,10−4}的学习率对其进行调整。我们发现生成器的学习速率为 1 0 − 4 10^{−4} 10−4,鉴别器的学习速率为 1 0 − 3 10^{−3} 10−3。生成器的学习速度降低从10−3衰减可能会有所改善。
在合成实验中,epoch固定为2000,在现实世界数据集中,epoch固定为500。鉴别器与生成器的训练步长之比设置为1。损失曲线稳定并收敛于随机鉴别器预测的交叉熵 Loss curvesare stable and converge to the cross entropy of a random discriminator prediction。在我们的实验中,batch size 为100。在所有实验(包括合成和现实数据集)上,噪声z的尺寸都固定为同样的值。我们在研究中增加z的维度,以分析更高维度的噪声的影响。实验是在具有16GB RAM和2.7 GHz处理器速度的计算机上进行的。使用Tesla M4024GB GPU卡时,没有发现明显的加速。
可视化实验 可视化图用于合成数据集,将CGAN与基线方法进行比较。为了避免混乱,在基线方法中,我们仅使用GP(RBF)。我们取关键的x值,并使用高斯核密度估计器绘制条件概率密度。为此,对于每种方法(CGAN或其他方法),在每个xiwe处都从p(y | xi)形成大小为200的样本。由于使用了核密度估计器,因此在某些图中我们可能看不到GP的完美高斯分布。为了进一步研究通过这些方法生成(预测)的分布,我们还绘制了从CGAN和GP生成的样本。
加性噪声(Additive noise)
我们首先考虑具有加性噪声 y = f ( x ) + z y = f(x)+ z y=f(x)+z的回归方案,这是大多数回归模型所做的假设。我们将z设为高斯噪声。期望使用通用回归模型,例如GP,DNN和XGboost,因为它们可以显式地模拟加性高斯噪声,因此有望在其上表现良好。这是CGAN的基本测试,尽管设计是通过隐式建模进行的,但它也应该能够轻松地对高斯噪声建模。
高斯噪声数据集(线性) 我们首先生成一个标准的高斯噪声数据集,其中
y
=
x
+
z
y = x + z
y=x+z,其中
x
∼
N
(
4
,
3
)
x\sim N(4,3)
x∼N(4,3) 和
z
∼
N
(
3
,
3
)
z\sim N(3,3)
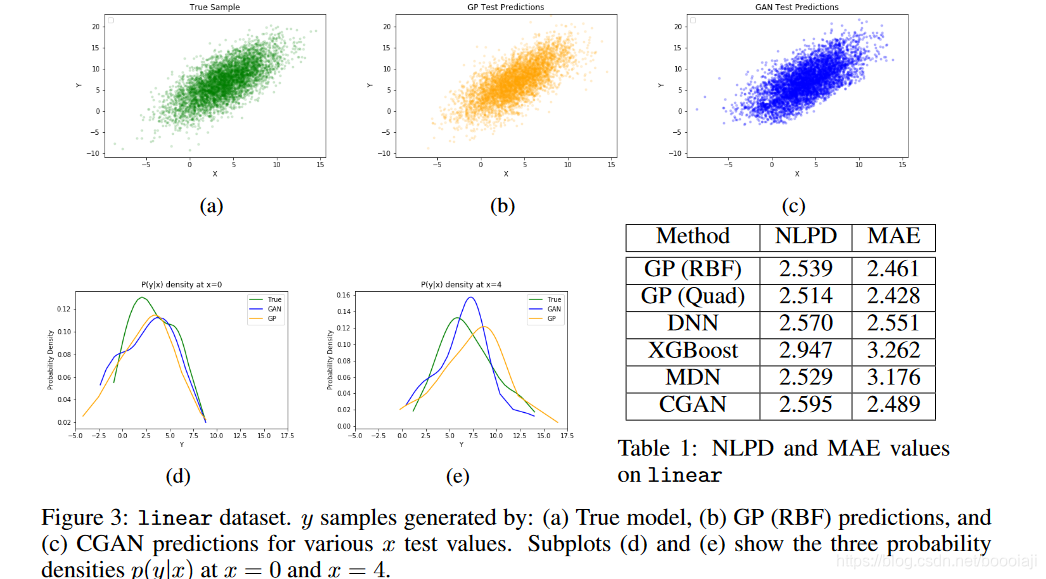
z∼N(3,3)。图3显示了真实模型GP和CGAN的生成样本。显然,与CGAN相比,GP产生的样本云看起来更类似于真实样本。图3还列出了测试数据上所有方法的NLPD和MAE度量值。在NLPD和MAE指标方面,回归方法之间没有显着差异。由于这里
f
(
x
)
=
x
f(x)= x
f(x)=x非常简单,因此我们接下来尝试一个复杂的
f
f
f,以查看CGAN是否能够以更复杂的f建模简单噪声。
正弦数据集(正弦) 我们使用高斯噪声,但使用
y
=
s
i
n
(
x
)
+
z
y = sin(x)+ z
y=sin(x)+z 来生成
x
x
x的更复杂函数,其中
z
∼
N
(
0
,
1
)
z\sim \mathcal N(0,1)
z∼N(0,1),
x
∼
U
[
−
4
,
4
]
x\sim \mathcal U [-4,4]
x∼U[−4,4]和
U
\mathcal U
U 是均匀分布。对于非线性回归模型(例如GP),这也是一个简单的问题。图5显示了通过这些方法生成的样本以及true函数。同样在这里,GP显然比CGAN产生更真实的样本。该图还给出了测试数据上的NLPD和MAE指标值,而CGAN的性能则略低。这种情况还表明,CGAN能够使用简单的线性加性噪声形式对输入和输出之间的复杂功能关系进行建模。即使具有加性噪声形式,当噪声为单峰噪声但呈现对称尾部(例如指数噪声)时,CGAN仍比GP有优势(例如,请参见补充材料)。自然的下一步是研究通常在现实世界中遇到的非加性复杂噪声形式。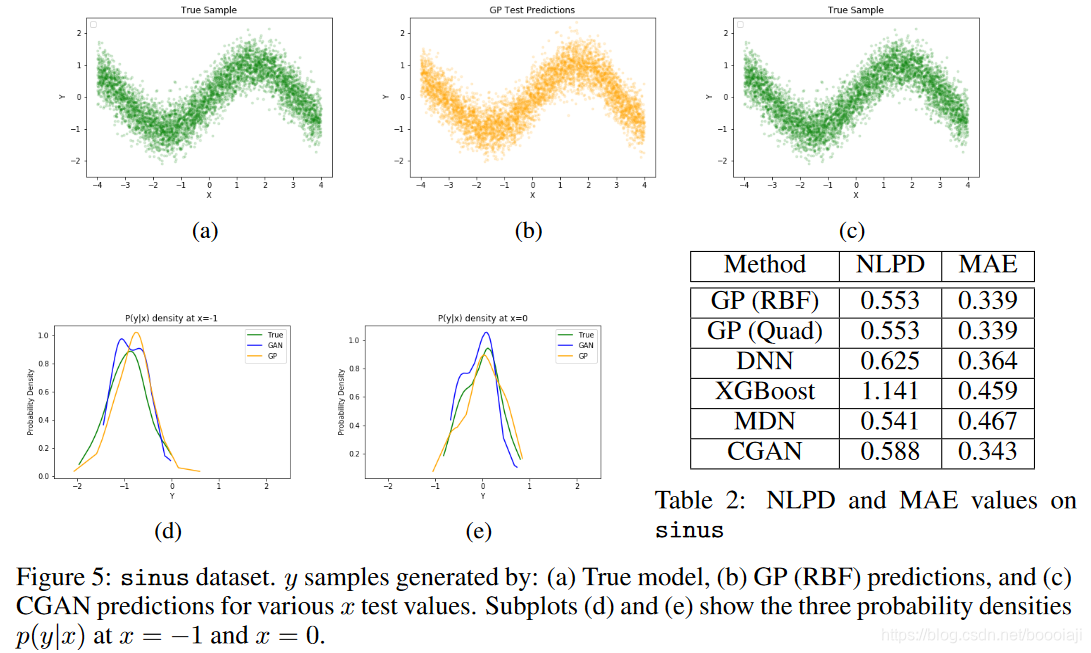
异方差噪声(Heteroscedastic noise)
先前的数据集使用独立于x的加性噪声形式。但是,现实世界中的现象表现出更复杂的噪声。我们生成的数据集具有异方差噪声(异方差),即依赖x的噪声。我们使用以下生成过程:
y
=
x
+
h
(
x
,
z
)
y = x + h(x,z)
y=x+h(x,z) 其中
h
(
x
,
z
)
=
(
0.001
+
0.5
∣
x
∣
)
×
z
h(x,z)=(0.001 + 0.5 | x |) \times z
h(x,z)=(0.001+0.5∣x∣)×z 和
z
∼
N
(
1
,
1
)
z \sim N(1,1)
z∼N(1,1)。该数据集的感兴趣区域interesting region约为 x = 0;与input x的其他区域相比,该区域的噪声很小。图7显示了通过这些方法生成的样本以及真实样本分布。与无法捕获异方差噪声结构的GP相比,CGAN生成的采样更为真实,其他基准也是如此。 CGAN的NLPD值也更好,如表3所示。虽然使用异随机GP heteroschedastic GPs 也可以使GP在该数据集上表现更好,但这里要注意的重要一点是,尽管使用的CGAN架构与之前线性数据集中CGAN的架构相似,它也很容易地学习到了,说明CGAN可以对非常不同类型的噪声进行建模。这证明了CGAN具有建模复杂噪声形式的能力。但是,正如预期的那样,MDN在此处表现最佳,因为它会将噪声建模为高斯混合噪声。
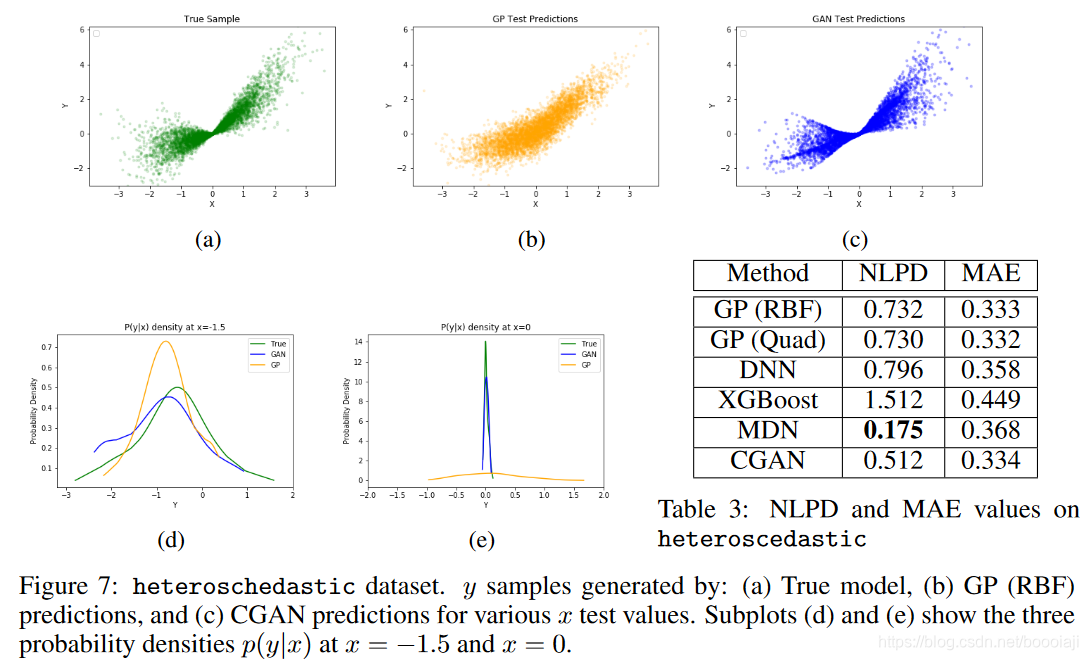
超越回归:多模式后验
接下来,我们假设噪声与噪声之间的相互作用更为复杂。我们构建了一个具有多模态 p ( y ∣ x ) p(y | x) p(y∣x) 分布(multi-modal)的简单数据集,该分布也随 x x x 改变,以检查CGAN是否可以捕获这种复杂的分布。显然,基线方法在此任务上不利。这种分布可能发生在现实世界中的现象中,例如某些动态系统会根据温度等潜在因素在多个状态之间切换。这会创建场景,其中相同的inputx可以映射到y的两个值。文献中很少有用于多峰回归的模型。
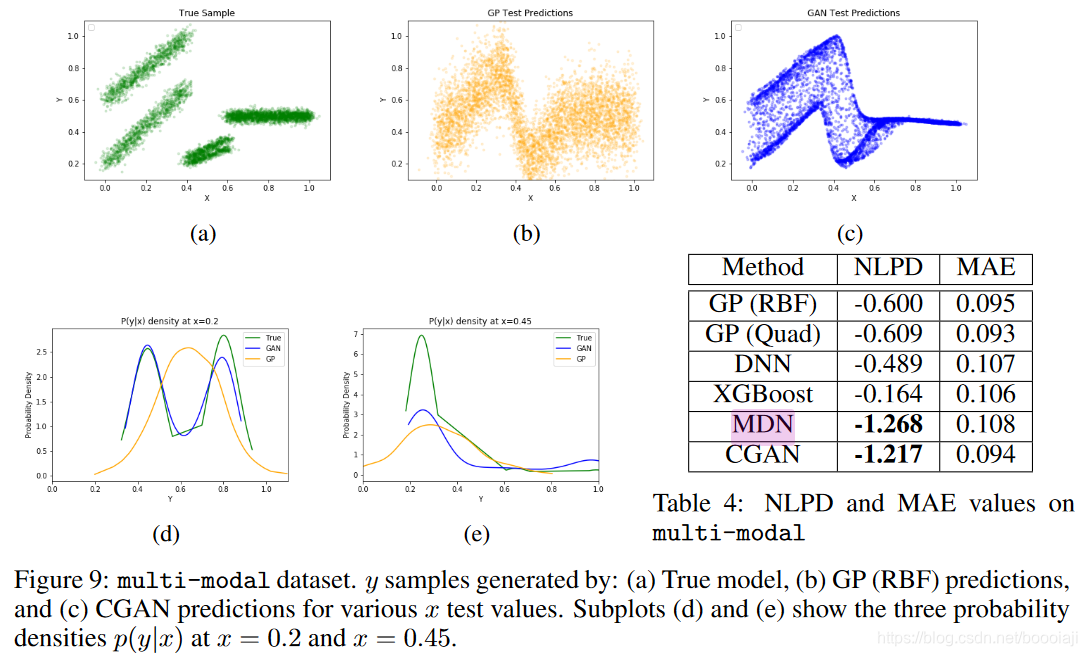
我们使用以下过程来生成多模态数据,其中y为: 0.4 < x 0.4 <x 0.4<x 时为 1.2 x + 0.03 z 1.2x + 0.03z 1.2x+0.03z 或 x + 0.6 + 0.03 z x + 0.6 + 0.03z x+0.6+0.03z;当 0.4 ≤ x < 0.6 0.4≤x<0.6 0.4≤x<0.6 时为 0.5 x + 0.01 z 0.5x + 0.01z 0.5x+0.01z 或 0.6 x + 0.01 z 0.6x + 0.01z 0.6x+0.01z ; 当 0.6 ≤ x 0.6≤x 0.6≤x 时为 0.5 + 0.02 z 0.5 + 0.02z 0.5+0.02z ,其中 z ∼ N ( 0 , 1 ) z\sim \mathcal N(0,1) z∼N(0,1) 和 x ∼ U [ 0 , 1 ] x\sim \mathcal U [0,1] x∼U[0,1]。
图9显示了生成的测试样本以及GP和CGAN预测的样本。 CGAN清楚地显示了对基础数据的多峰性质进行建模的出色能力,而GP却无法做到,因为GP只能为给定的x生成(单峰)高斯分布。这也导致GP在
x
≥
0.6
x≥0.6
x≥0.6区域的性能较差,因为它很难在不同区域匹配噪声。文献中很少有用于多峰回归的模型,令人鼓舞的是,CGAN可以对其进行隐式建模。这证明了CGAN能够捕获复杂的条件分布,而其他回归方法对此也需要进行特殊修改。以上证明了与使用CGAN进行回归相关的强大功能,其他侧重于拟合中心统计量的加性噪声模型在。但是,使用每个点的高斯似然混合显式建模噪声的MDN与CGAN相当。这对于像天气或物理过程这样的领域非常重要,在该领域中,对所有可能的情况进行建模比对均值进行建模更为重要。多里安飓风不断变化的路径发生的风流情节就是这种现象的例证,在这种现象中,对可能的路径进行建模比平均拟合更为重要。
 值得注意的是,ELU激活函数可以平滑生成的y分布的总体形状。应用稀疏激活(例如ReLU)可以帮助降低平滑度(请参阅附录)。
值得注意的是,ELU激活函数可以平滑生成的y分布的总体形状。应用稀疏激活(例如ReLU)可以帮助降低平滑度(请参阅附录)。
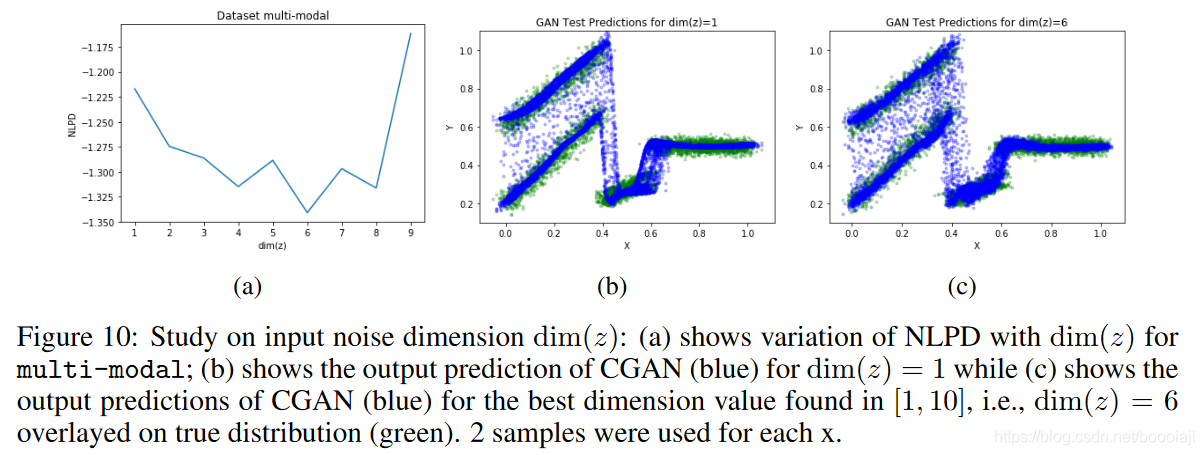
增加噪声的维数 为了研究噪声维数对CGAN性能的影响,我们将
k
=
d
i
m
(
z
)
k = dim(z)
k=dim(z)在
{
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
}
\{1,2,3,4,5,6,7,8,9\}
{1,2,3,4,5,6,7,8,9}上变化。图10(a) 显示了NLPD值,因为我们增加了噪声的维数。我们 在 k = 6 得到了最低的NLPD = −1.34。为了指出这种选择 dim(z) 的好处,我们显示了图10中在dim(z)= 1 和 dim(z)= 6 生成的CGAN预测样本。正确设置噪声维数时,可以忠实于真实的分布密度。这些结果表明,对于具有复杂噪声的问题,使用较高维度的噪声可以帮助获得改进的性能。
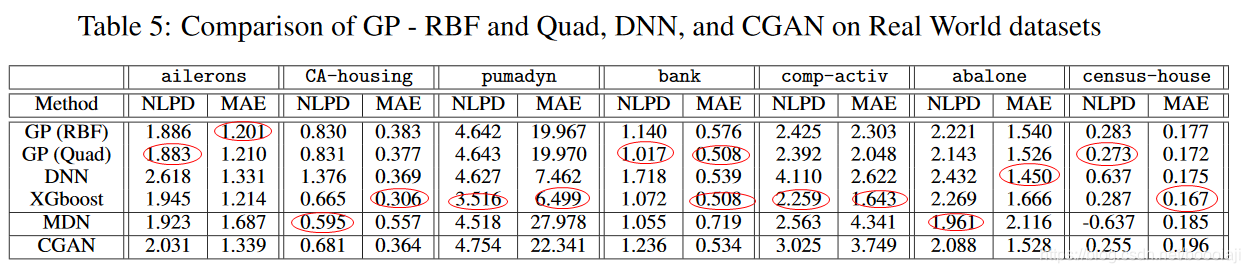
真实世界数据集
我们在七个现实世界的数据集上进行了实验:ailerons, CA-housing, pumadyn, bank, comp-activ, abalone, and census-house。表5描绘了这些数据集的结果。总体而言,在MAE指标上XGboost的性能最优,而MDN在四个数据集上的NLPD值最高(其他三个数据集接近最优)。但是,虽然XGBoost显然在所有数据集中均名列前茅,但没有一种方法可以在所有数据集中明显胜出。自高斯抽样以来,MDN的MAE指标较低,它倾向于产生一些荒谬的异常值,从而使MAE得分更高。尽管CGAN在最先进的方法上具有竞争力,但在预测或建模噪声方面不如XGBoostor MDN好。 MDN的噪声建模能力也得到了综合数据集的证实。
训练规模的影响
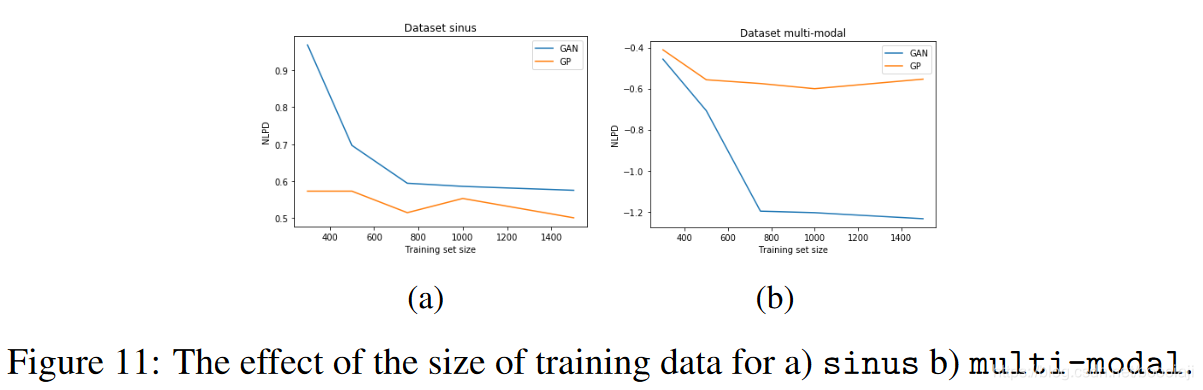
像其他贝叶斯方法一样,GP在较小的数据集上表现良好。这是因为这些方法使用权重空间中的后验对预测进行平均。 CGAN没有此属性,因为它仅使用一组权重。鉴于此,当训练样本量变小时,有必要研究CGAN与GP相比的表现。随着训练量N的减小,我们在图11的正弦波和多模态报告结果。这里我们取N为{300,500,750,1000,1500}。我们注意到,GP的性能在训练集大小的范围内是稳定的。 CGAN的训练集大小减少。有趣的是,在多模式数据集上,我们发现在300个以下实例中,GP的表现与CGAN一样。这是因为,数据量很小时,CGAN也无法很好地消除多模式噪声。
结论
本文的主要观点是:(a)在回归的背景下对CGAN的解释是一种建模一般噪声形式的好方法,例如 p ( y ∣ x ) p(y | x) p(y∣x) 是 y y y 的多模态; (b)指出,即使是简单的实现CGAN也可以与最新方法竞争。 CGAN还有其他优点:它可以更自然地模拟噪声;而且,它可以在一种表述和实现中处理不同类型的回归模型。而且,与CGAN相比,对于大型结构化领域(例如图像),由于以下原因,它的设置和设计要简单得多:(a)不需要生成函数f的任何专家级设置; (b)噪声维度k可以选择等于或大于输出 y y y 的维度m,因此,很容易避免“零”梯度问题; (c)由于回归问题对于给定的x具有一种或至多几种模式,因此“遗漏模式”或“模式崩溃”问题并不令人担忧。因此,CGAN值得进一步探索以解决回归问题。
但是,正如我们在现实世界和人工合成实验中所展示的那样,CGAN任重道远,MDN和XGBoost等方法具有出色的噪声建模和预测能力。还要注意的另一点是,由于对抗的复杂性,CGAN需要大量的超参数进行训练,而MDN和XGBoost的调参则相对较容易——只需少量的努力。 MDN可以像多模式示例中所示的,和CGAN一样对复杂的噪声形式进行建模,并且具有与CGAN中的隐式形式不同的显式似然训练。
在本文中,我们仅对一维输出数据集(m = dim(y)= 1)进行了实验,这对于评估具有多个非线性相关输出的数据集的CGAN很有用。例如,在金融和天气预报等应用程序中涉及许多未知变量的应用程序,可以从CGAN的应用程序中受益匪浅。
未来的工作也有许多通用的方向。在本文中,我们采用了标准的CGAN鉴别器,该鉴别器对应于最小化Jenson-Shannon散度。由于最大似然性对应于最小化KL散度,因此[10]中的 f-GAN 思想可用于适当地改变鉴别器,这可能会导致更好的NLPD泛化。适于回归的可伸缩CGAN实现的设计是另一个关键方向。设计CGAN的贝叶斯版本[19]会在小型训练数据集上大有裨益。通过这些措施,可以更好地执行CGAN的实现,我们可以返回对当前最佳的回归求解器进行更彻底的CGAN基准测试。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









