







原文 :https://www.statisticshowto.com/wilcoxon-signed-rank-test/

转载:https://www.cnblogs.com/djx571/p/10216940.html
Wilcoxon有符号秩检验(也称为Wilcoxon有符号秩和检验)是一种非参数检验。当统计数据中使用“非参数”一词时,并不意味着您对总体一无所知。这通常意味着总体数据没有正态分布。如果两个数据样本来自重复观察,那么它们是匹配的。利用Wilcoxon Signed-Rank检验,在不假设数据服从正态分布的前提下,判断出相应的数据总体分布是否相同。也即,如果数据对之间的差异是非正态分布的,则应使用Wilcoxon Signed-Rank检验。
有两个稍微不同的测试版本:
Wilcoxon有符号秩检验(The Wilcoxon signed rank) 将样本中值与假设中值进行比较。
Wilcoxon配对有符号秩检验(Wilcoxon matched-pairs signed rank test) 计算每组匹配对之间的差异,然后按照与有符号秩检验相同的步骤将样本与某个中值进行比较。
术语“ Wilcoxon”通常用于两种测试。 这通常不会造成混淆,因为数据匹配或不匹配是很明显的。
这个检验的零假设(H0)是两个样本的中位数相等。它通常用于:
作为 单样本t检验 或 配对t检验 的非参数替代。
对于 没有数字刻度的有序(排序)分类变量。
How to Run the Test by Hand
运行测试的要求:
● 数据必须是匹配的。
● 因变量必须是连续的(即您必须能够区分小数点后第n位的值)。
● 要达到最高准确性,应该没有并列的排序。如果排序是相等的,有一个变通方法(见下面步骤5之后)。
样例问题:以下2组治疗数据的中值是否存在差异?
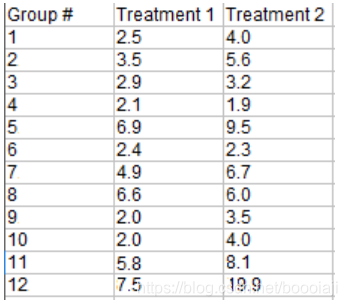
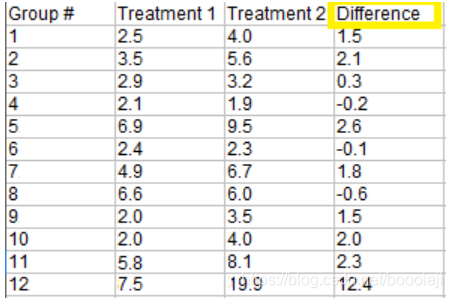
Step 1: 从治疗1中减去治疗2得到差异
注意:如果你只有一组样本,计算每个变量和0之间的差(假设中值),而不是2组对之间的差
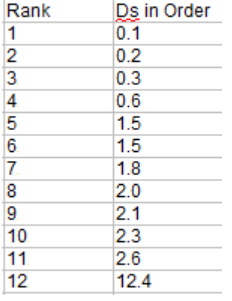
Step 2:将差异按顺序排列(下图第二列),然后进行排序。按顺序排列时忽略这个符号。
Step 3:创建第三列,并注意差异的符号(您在步骤2中忽略的那个)
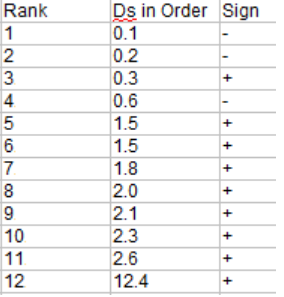
接下来的两个步骤将计算Wilcoxon带符号的秩和:
Step 4: 计算负差的秩和(第3步图中带负号的秩和)。你在这里加起来,而不是实际的差异:
W– = 1 + 2 + 4 = 7
Step 5:计算正差异的秩和(步骤3图中带正号的)。
W+ = 3 + 5.5 + 5.5 + 7 + 8 + 9 + 10 + 11 + 12 = 71
这里看 Wilcoxon 检验之 rank-sum 与 signed-rank 更清晰
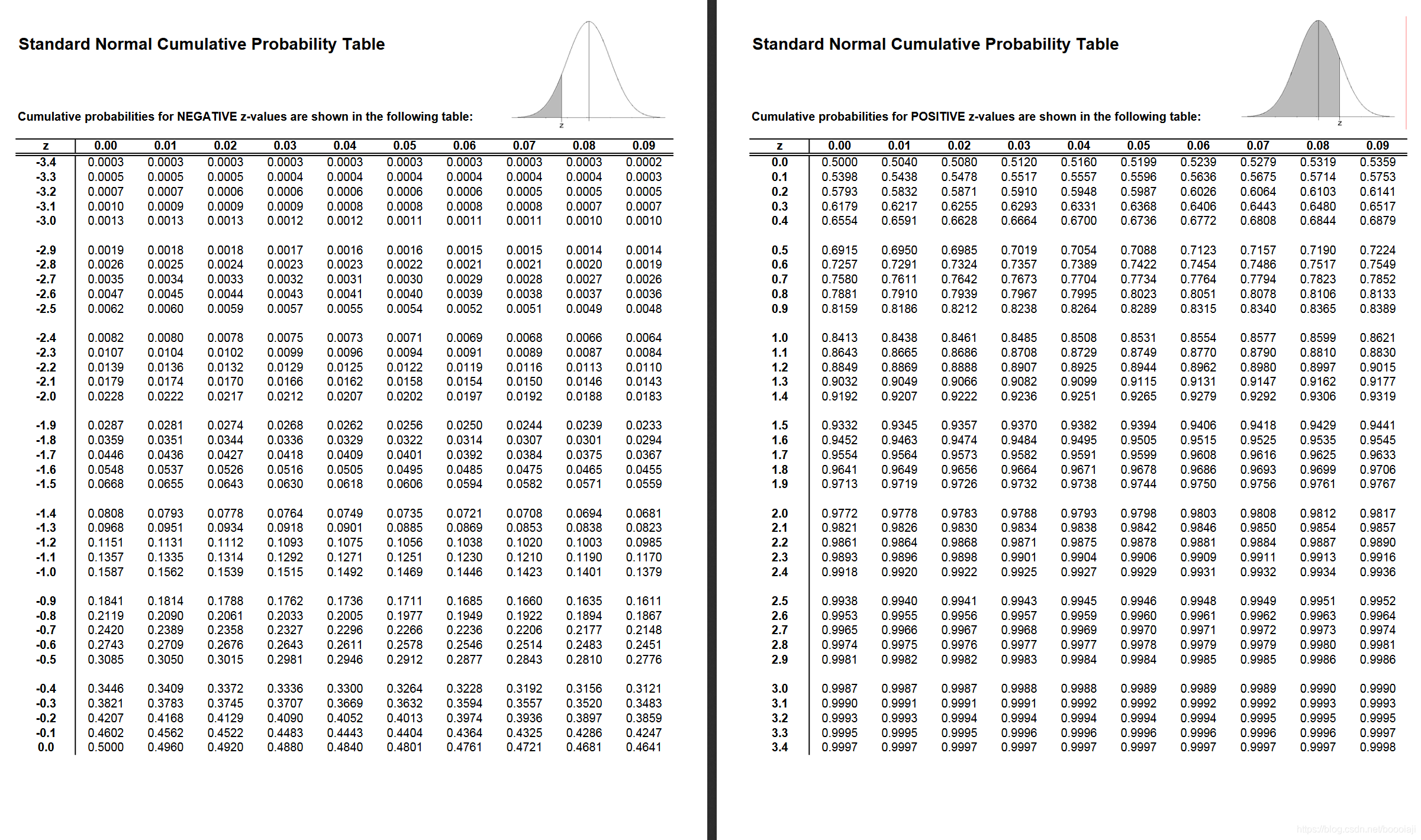
Using the Normal Approximation with Wilcoxin Signed Ranks
您可以使用上述信息做什么? 如果 观测/对 的值 n(n + 1) / 2 大于 20,则可以使用正态近似。 这组数据满足此要求: 12(12 + 1) / 2 = 78。z分数公式有几个修改/注意事项:
使用 W + 或 W– 中较小的一个作为检验统计量。
对 平均值 μ 使用以下公式:n(n + 1)/ 4。
对 σ 使用以下公式:
n
(
n
+
1
)
(
2
n
+
1
)
/
24
\sqrt{n(n + 1)(2n + 1)/ 24}
n(n+1)(2n+1)/24
如果您拥有并列序号,则必须为
t
t
t 个并列排序将
σ
σ
σ 降低
(
t
3
−
t
)
/
48
(t^3-t)/48
(t3−t)/48。 有两个并列等级(5.5 + 5.5),因此将 σ 减小 (8-2) / 48 = 0.125。
z得分为:

在z表中查找此分数,我们得到0.9880 (0.99396-0.00604) 的面积,等于0.012的两尾p值。 这是一个很小的p值,强烈表明中位数存在显着差异。
How to Run the Wilcoxon Signed Rank Test using Technology
Excel / Open Office:下载此电子表格(由BioStatHandbook提供)。
R:您可以在RCompanion.org上找到示例代码。
用R计算Wilcoxin
在名为immer的内建数据集中,记录了1931年和1932年同一领域的大麦产量。收益率数据显示在数据框的Y1和Y2列中。
问题(problem):在不假设数据为正态分布的情况下,以0.05显著性水平检验数据集immer中1931年和1932年的大麦产量是否具有相同的数据分布。
Solution:
零假设是两个样本年的大麦产量是相同的。为了验证这个假设,我们使用wilcox。测试函数对匹配的样本进行比较。对于配对测试,我们将“配对”参数设置为TRUE。由于p值为0.005318,小于0.05的显著性水平,我们拒绝原假设。
wilcox.test(immer$Y1, immer$Y2, paired=TRUE) ,#其中其它参数如 exact, correct选择不同的话,可能p值结果不同,根据实际情况选择

python计算
import scipy.stats
x=[57.07168,46.95301,31.86423,38.27486,77.89309,76.78879,33.29809,58.61569,18.26473,62.92256,50.46951,19.14473,22.58552,24.14309]
y=[8.319966,2.569211,1.306941,8.450002,1.624244,1.887139,1.376355,2.521150,5.940253,1.458392,3.257468,1.574528,2.338976]
scipy.stats.ranksums(x, y)


















 9076
9076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









