







文章
网络模型训练与保存参考利用GPU训练网络模型,并且加载的网络模型也是该篇文章中的代码训练出来的。
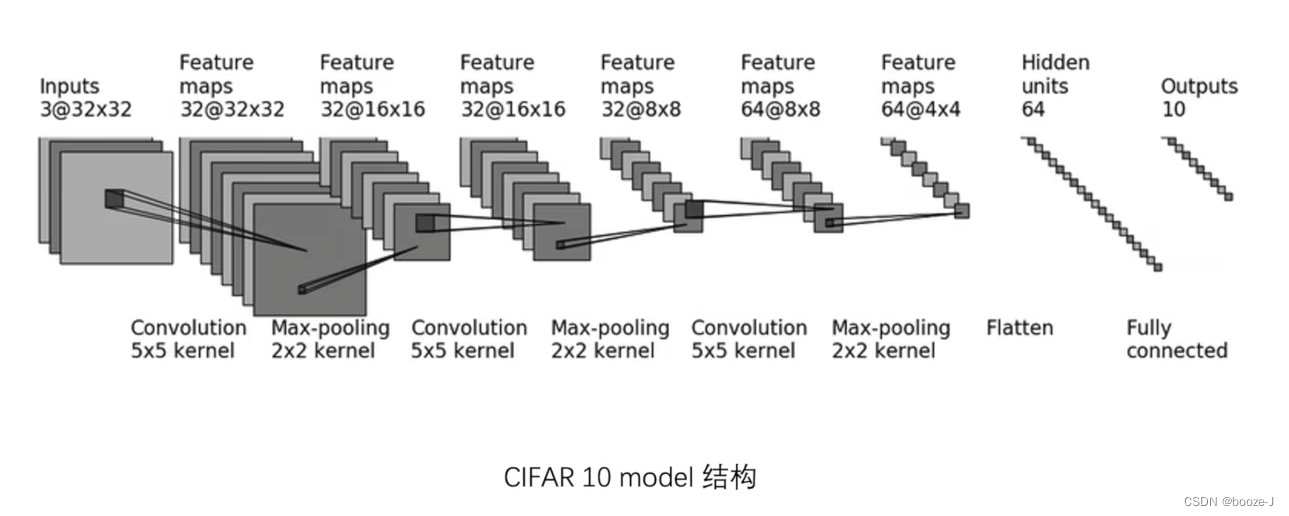
验证模型示例代码:
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
# 获取图片存放路径
image_path = "./images/img.png"
# 读取图片
image = Image.open(image_path)
# 读取的图片类型为 <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=296x183 at 0x1FBD755E340>
print("image:\n",image)
image = image.convert("RGB")
'''接下来要对image进行通道转换,因为png格式是四通道的,除RGB三通道外,还有一个透明度通道。所以我们调用image = image.convert("RGB"),保留其颜色通道
当然,如果图片本来就是三个颜色通道,经过此操作,不变。加上这一步之后可以适应png,jpg各种格式的图片、
'''
# [Resize](https://pytorch.org/vision/stable/generated/torchvision.transforms.Resize.html?highlight=resize#torchvision.transforms.Resize)
# 为什么要进行Resize这一步呢?是因为我们这个网络模型的要求输入是32*32大小的图片
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
# 将image转化为合适的类型
image = transform(image)
print("image:\n",image.shape) # torch.Size([3, 32, 32])
# 搭建神经网络(单独开一个文件存放网络模型)
class Booze(nn.Module):
def __init__(self):
super(Booze, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
# 加载网络模型
model = torch.load("./model/obj_0.pth")
# 将图片转化为四维的(3,32,32) -> (1,3,32,32)
image = torch.reshape(image,(1,3,32,32))
# 定义测试所用的设备 模型的训练方式的不同(GPU训练、CPU训练) 测试时的数据类型也不一样
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 查看模型
print(model)
model.eval() # 测试的时候,这一步大家也许经常遗忘
with torch.no_grad(): # # 这一步大家也许经常遗忘
# 模型如果是使用cuda训练的,则测试的时候也需要使用cuda类型的数据进行测试
output = model(image.to(device))
'''
tensor([[-1.1961, 0.1016, 0.6076, 0.5585, 0.4856, 0.4466, 0.4176, 0.3158,
-1.4603, -0.5929]], device='cuda:0')
可以看到output含10个数据,每个数据代表着测试图片属于该类的一个概率
'''
print(output)
# 打印出测试图片使用网络模型预测的类别 发现和实际类别不同哈 原因是因为该网络模型的训练次数较少 增加训练批次和调整学习率可以得到更精准的网络模型
print(output.argmax(1).item())
一些需要注意的点在代码中的注释有详细的描述。
注意
- png格式是四通道的,除RGB三通道外,还有一个透明度通道。所以我们调用
image = image.convert("RGB"),保留其颜色通道当然,如果图片本来就是三个颜色通道,经过此操作,不变。 - 在将待预测图片传入网络模型中预测之前,需要先进行预处理,图片大小是否符合输入要求,图片格式和维度是否符合要求等等。
- 模型如果是使用cuda训练的,则测试的时候也需要使用cuda类型的数据进行测试
- 打印出测试图片使用网络模型预测的类别,发现和实际类别不同,原因是因为该网络模型的训练次数较少或者学习率不合适,增加训练批次和调整学习率可以得到更精准的网络模型。
















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











