







文章
1.准备数据集
这里我们以数据集CIFAR10为例。有关数据集CIFAR10的介绍详细可见此处,数据集的使用可以参照pytorch中常用数据集的使用方法
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Booze
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./CIFAR10',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root='./CIFAR10',train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
2.利用DataLoader加载数据集
DataLoader具体使用可以参照之前的博客Dataloader的使用
# 利用dataloader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
3.创建神经网络模型
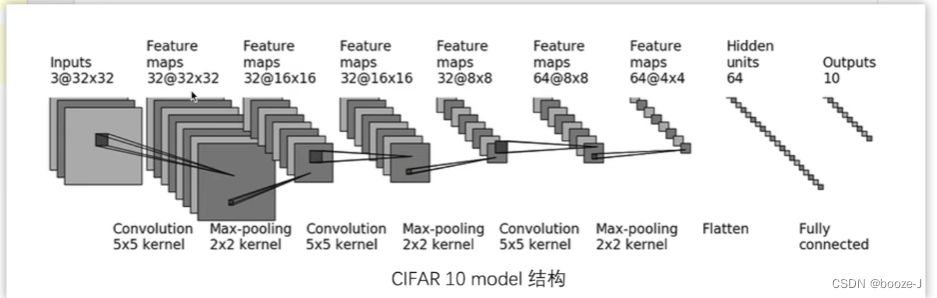
我们按照下面这张网络模型图,单独创建一个python文件用来写网络模型,神经网络的搭建具体可以参考神经网络-使用Sequential搭建神经网络:
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
# 搭建神经网络(单独开一个文件存放网络模型)
class Booze(nn.Module):
def __init__(self):
super(Booze, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
# 验证网络正确性
if __name__ =="__main__":
obj = Booze()
input = torch.ones(64,3,32,32)
output = obj(input)
# torch.Size([64, 10]) 可以看到他有64行数据,因为batch_size=64,然后每一行数据上面有10个数据,这个数据代表它每张图片再10个类别上的概率
print(output.shape)
搭建完网络模型之后最好验证一下网络模型的正确性。
4.创建损失函数
损失函数官方文档,根据情况的不同要选择合适的损失函数,损失函数的简单使用可以参考损失函数与反向传播
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
5.定义优化器
优化器的简单使用可以参考pytorch-优化器
# 定义优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(obj.parameters(),lr = learning_rate)
6.设置训练网络的一些参数
这些参数都是可选的,像是epoch也可以直接写在循环中,单独设置一个变量是为了更好修改,而且也更加清晰,而total_train_step和total_test_step可以用来计算步数,在使用tensorboard可视化传入参数时会用到。
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step=0
# 记录测试的次数
total_test_step=0
# 训练的轮数
epoch = 10
7.模型训练
for i in range(epoch):
print("-------------第{}轮训练开始------------".format(i+1))
# 训练步骤开始 [train()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.train)
obj.train()
for data in train_dataloader:
imgs,targets = data
outputs = obj(imgs)
# 计算输出值与目标值的损失
loss = loss_fn(outputs,targets)
# 优化器优化模型:
# 利用优化器将梯度清零
optimizer.zero_grad()
# 利用反向传播得到每个参数节点的一个梯度
loss.backward()
optimizer.step()
total_train_step += 1
# 每隔100步 打印并添加到tensorboard中一次
if total_train_step%100==0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
上面又有一个点需要科普一下,writer.add_scalar("train_loss",loss.item(),total_train_step)可以看到这里面的第二个参数是loss.item(),那么item()的作用是什么呢?

从这可以看出item()方法的作用吧,相当于把tensor数据类型中的数字取出来了。不理解的话你还可以看官方文档的解释。
8.模型测试
for i in range(epoch):
print("-------------第{}轮训练开始------------".format(i+1))
# 训练步骤开始 [train()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.train)
obj.train()
for data in train_dataloader:
imgs,targets = data
outputs = obj(imgs)
# 计算输出值与目标值的损失
loss = loss_fn(outputs,targets)
# 优化器优化模型:
# 利用优化器将梯度清零
optimizer.zero_grad()
# 利用反向传播得到每个参数节点的一个梯度
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step%100==0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始:
# 注意在测试的过程中不需要对模型进行调优
obj.eval() # [eval()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.eval)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
outputs = obj(imgs)
loss = loss_fn(outputs,targets)
total_test_loss+=loss
accurcay = (outputs.argmax(1)==targets).sum()
total_accuracy+=accurcay
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
writer.add_scalar('test_loss',total_test_loss,total_test_step)
total_test_step+=1
可以看到在训练前,有一句obj.train(), 测试前有一句obj.eval()它们的作用是什么呢?
可以看到官方文档对train()和eval()的解释
- train() - This has any effect only on certain modules. See documentations of particular modules for details of their behaviors in training/evaluation mode, if they are affected, e.g. Dropout, BatchNorm, etc.
- eval() - This has any effect only on certain modules. See documentations of particular modules for details of their behaviors in training/evaluation mode, if they are affected, e.g. Dropout, BatchNorm, etc.
大概意思加上这两句话,会对网络模型其中一些网络层训练和测试时有影响,这边建议加上。
另外上面还涉及到了计算正确率的部分,这个时候就用到了一个方法argmax可以看到官方文档对argmax的解释:
- Returns the indices of the maximum value of all elements in the input tensor.
通俗点说就是将tensor数据中最大值的索引值返回,当遇到分类问题的时候,通常返回的outputs是一个tensor数据类型的列表,列表中的每个数据代表着测试样本属于每个种类的概率,使用argmax取出最大值相当于是取出概率最大的种类。将预测取出来的种类与目标种类对比就可以判断预测是否正确,所有测试样本进行对比也就可以得到预测正确的个数,再利用预测正确个数除以总的测试样本数,便可以得到预测正确率。
# 计算一批次预测种类和目标种类一致的个数(计算一批次预测正确的个数)
accurcay = (outputs.argmax(1)==targets).sum()
# 将所有批次预测种类和目标种类一致的个数累加得到测试样本中预测正确的个数
total_accuracy+=accurcay
# 预测正确的个数除以预测总数便可以得到预测正确率
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
9.训练测试过程可视化
这部分的代码是穿插在训练与测试代码中的,就是使用tensorboard对训练的过程进行可视化,具体使用可以参考前面的Tensorboard的使用。
# 添加tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("-------------第{}轮训练开始------------".format(i+1))
# 训练步骤开始 [train()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.train)
obj.train()
for data in train_dataloader:
imgs,targets = data
outputs = obj(imgs)
# 计算输出值与目标值的损失
loss = loss_fn(outputs,targets)
# 优化器优化模型:
# 利用优化器将梯度清零
optimizer.zero_grad()
# 利用反向传播得到每个参数节点的一个梯度
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step%100==0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始:
# 注意在测试的过程中不需要对模型进行调优
obj.eval() # [eval()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.eval)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
outputs = obj(imgs)
loss = loss_fn(outputs,targets)
total_test_loss+=loss
accurcay = (outputs.argmax(1)==targets).sum()
total_accuracy+=accurcay
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
writer.add_scalar('test_loss',total_test_loss,total_test_step)
total_test_step+=1
10.模型的保存
具体使用也可以参照前面的网络模型的保存与读取
# 这里有个format()格式化,是因为每批次的模型都保存了,避免命名重复,导致网络模型的覆盖。
torch.save(obj,"./model/obj_{}.pth".format(i))
print("模型已保存")
完整代码:
train.py
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Booze
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./CIFAR10',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root='./CIFAR10',train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用dataloader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
obj = Booze()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(obj.parameters(),lr = learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step=0
# 记录测试的次数
total_test_step=0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("-------------第{}轮训练开始------------".format(i+1))
# 训练步骤开始 [train()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.train)
obj.train()
for data in train_dataloader:
imgs,targets = data
outputs = obj(imgs)
# 计算输出值与目标值的损失
loss = loss_fn(outputs,targets)
# 优化器优化模型:
# 利用优化器将梯度清零
optimizer.zero_grad()
# 利用反向传播得到每个参数节点的一个梯度
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step%100==0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始:
# 注意在测试的过程中不需要对模型进行调优
obj.eval() # [eval()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.eval)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
outputs = obj(imgs)
loss = loss_fn(outputs,targets)
total_test_loss+=loss
accurcay = (outputs.argmax(1)==targets).sum()
total_accuracy+=accurcay
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
writer.add_scalar('test_loss',total_test_loss,total_test_step)
total_test_step+=1
torch.save(obj,"./model/obj_{}.pth".format(i))
print("模型已保存")
writer.close()
model.py
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
# 搭建神经网络(单独开一个文件存放网络模型)
class Booze(nn.Module):
def __init__(self):
super(Booze, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
# 验证网络正确性
if __name__ =="__main__":
obj = Booze()
input = torch.ones(64,3,32,32)
output = obj(input)
# torch.Size([64, 10]) 可以看到他有64行数据,因为batch_size=64,然后每一行数据上面有10个数据,这个数据代表它每张图片再10个类别上的概率
print(output.shape)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











