







一、Vmware16下载
1、在Vmware官网下载

2、下载后,自行安装。点击打开Vmware

二、下载CentOS 7 64位
1、输入CentOS官网地址https://www.centos.org/,并点击下载页面进行下载

2、选择CentOS 7 64位

3、此处我选择下载的是阿里云的


4、下载完成,保存到相应的存放路径即可。

三、创建虚拟机
1、点击新建虚拟机

2、选择典型安装(有些小的功能可以选择自定义安装)。

3、选择稍后安装操作系统(方便后续安装可视化界面)

4、选择已经下载好的操作系统和版本(我的是Linux的CentOS 7)

5、给虚拟机命名并选择系统选择存储位置


6、指定磁盘容量一般选择默认(虚拟磁盘存储为单个或者多个文件一般影响不大)

7、选择自定义硬件,一般根据自己电脑设置。(1)此处内存修改为2G;(2)CD/DVD(IDE)设置,选择使用ISO映像文件,填写下载好的CentOS 7系统的保存路径。最后关闭,完成配置。




四、启动虚拟机
1、开启虚拟机

2、启动后会自动install CentOS 7,等待安装完成

3、选择语言

4、选择“软件选择(S)”,选择GNOME桌面


5、开始安装


6、设置root密码和创建用户,完成配置后,并重启


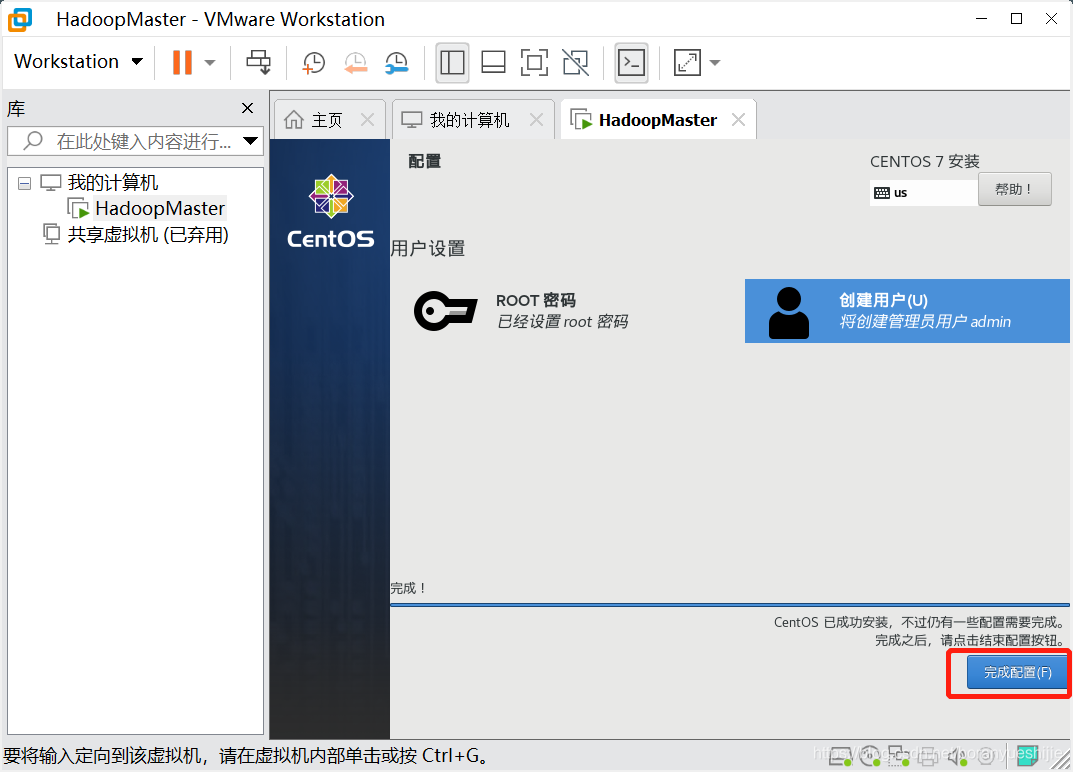

7、许可证授权,并完成配置


8、继续



9、完成

五、网络配置(NAT模式)
1、本机以连接无线网络为例
2、打开"网络与Internet"设置

3、右键无线网络的“状态”、“属性”

4、设置“共享”,并确定保存

5、启动虚拟机,点击“编辑虚拟机设置”

6、网络适配器设置为NAT模式
 7、点击“编辑”,打开虚拟网络编辑器进行设置,然后确认保存
7、点击“编辑”,打开虚拟网络编辑器进行设置,然后确认保存

8、点击“开启此虚拟机”

9、启动虚拟机后,进行网络测试。右键“打开终端”输入:
ping www.baidu.com
或者打开浏览器输入网页:

10、完成网络配置。
六、设置固定IP地址
此设置挺重要。动态IP会使个节点连接失败,每次都需手动修改配置文件,挺麻烦的,而静态IP则无此顾虑。
此处以主节点的虚拟机为例:
点击右上角的“关机”按钮,在菜单中选择“有线设置”

点击设置

输入如下信息
地址:输入自定义的IP,如192.168.XXX.XXX
子网掩码:可以通过命令ifconfig中查看,一般是255.255.255.0
网关:可以通过命令cat /etc/resolv.conf查看,如192.168.1.1
DNS:与网关一致

点击应用,设置完毕。
其他两个节点同理操作。
七、通过克隆生成两个slave、slave1从节点
选择主节点,点击克隆生成从节点



选择完整的克隆

master、slave、slave1节点要放在同一个目录下

slave节点克隆完毕。slave1节点同样的操作。















 1577
1577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









