







一、Azkaban调度Hadoop Mapreduce
…
二、Azkaban调度Hive
1、创建linux执行文件(.sh格式),文件包含hive的执行脚本。
参考:link.
[admin@master ~]$ vim hive_uidcount.sh
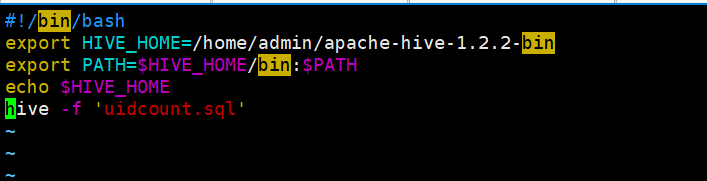
2、创建Azkaban的JOB文件(.job格式),文件中执行hive_uidcount.sh
[admin@master ~]$ vim hive_uidcount.job
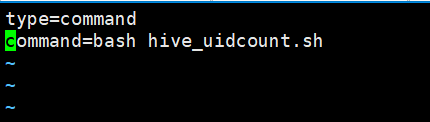
3、把hive_uidcount.sh 和hive_uidcount.job进行压缩为文件hive_uidcount_job.zip(.zip格式)
[admin@master ~]$ zip -r hive_uidcount_job.zip hive_uidcount.sh hive_uidcount.job

4、登录azkaban

5、创建project

6、将hive_uidcount_job.zip文件上传


7、执行



















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









