







 本文详细介绍了使用Scrapy爬取好大夫在线网站数据的过程,包括需求分析、爬取路径、解决逐级抓取、信息汇总、处理动态内容及限速策略。在爬取过程中,通过Request对象和回调函数实现页面间导航,利用meta传递信息,使用PhantomJS处理动态内容,并设置DOWNLOAD_DELAY防止被封禁。
本文详细介绍了使用Scrapy爬取好大夫在线网站数据的过程,包括需求分析、爬取路径、解决逐级抓取、信息汇总、处理动态内容及限速策略。在爬取过程中,通过Request对象和回调函数实现页面间导航,利用meta传递信息,使用PhantomJS处理动态内容,并设置DOWNLOAD_DELAY防止被封禁。
背景
运营需求是需要爬取好大夫的数据,爬取路径如下:
第一级:抓取所有科室:
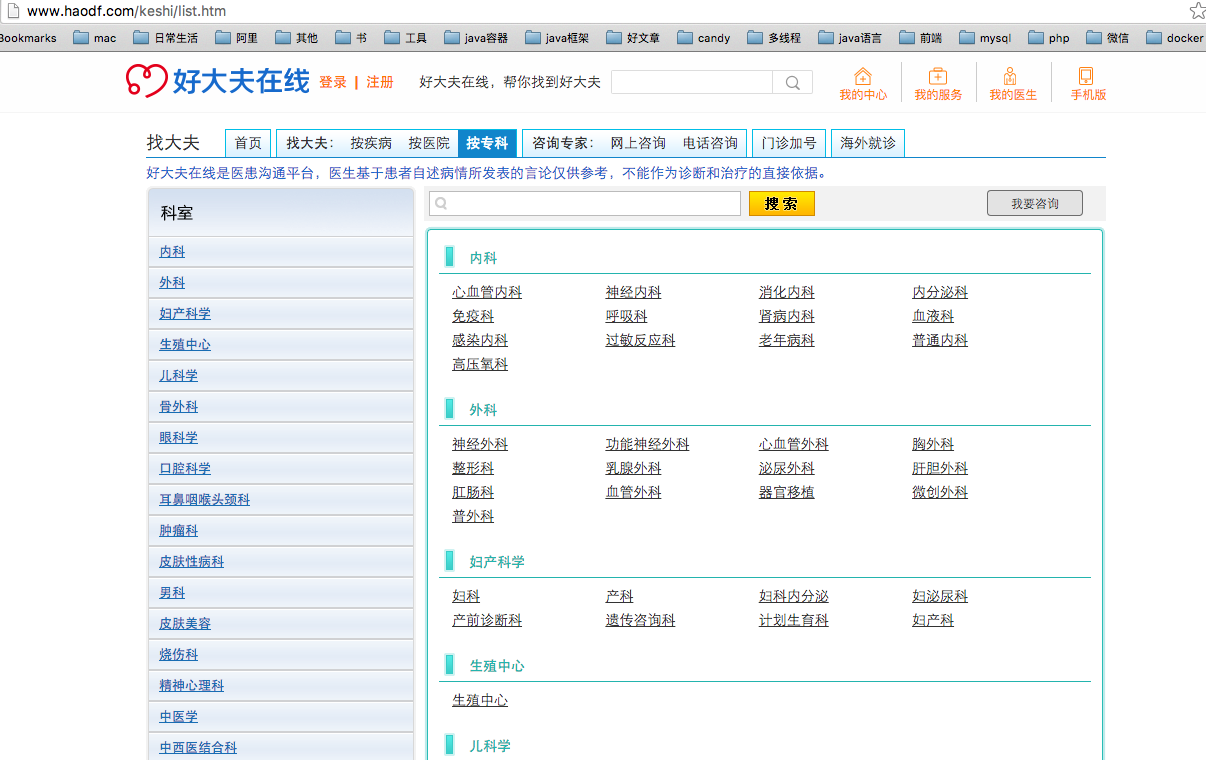
第二级:每个科室对应的好评科室

第三级:科室推荐专家
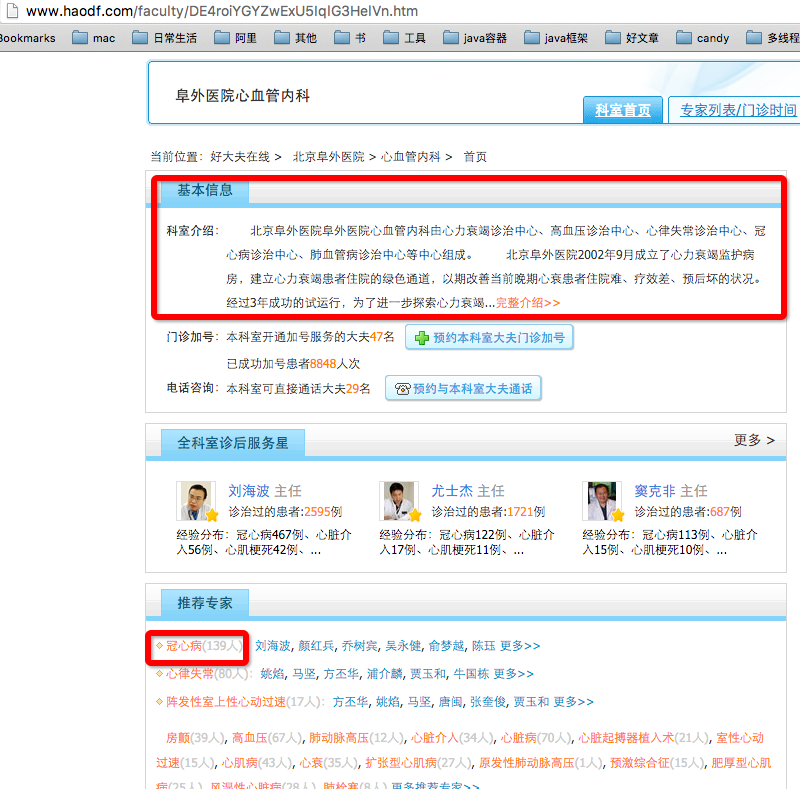
第四级:推荐专家
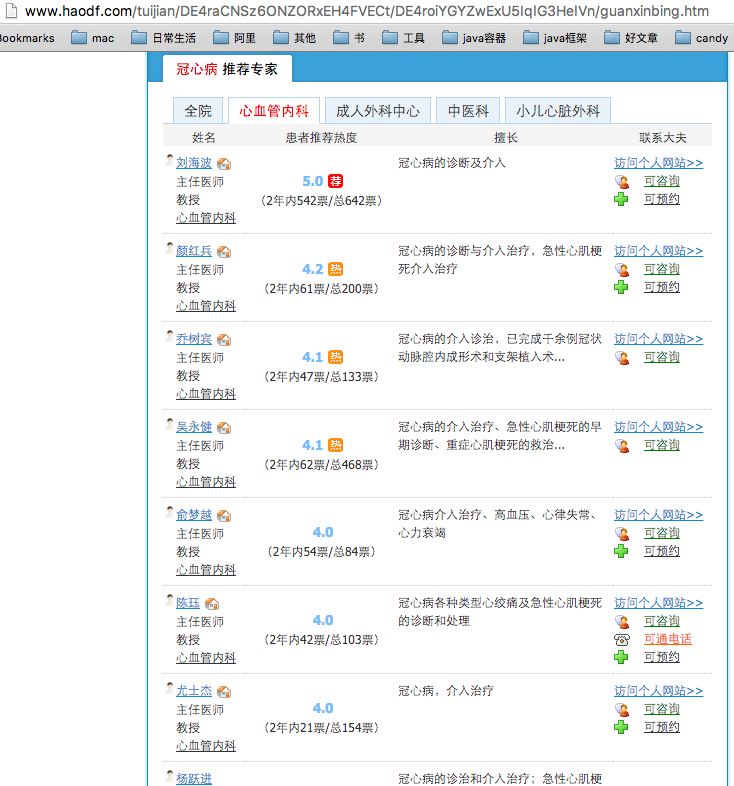
第五级:专家信息
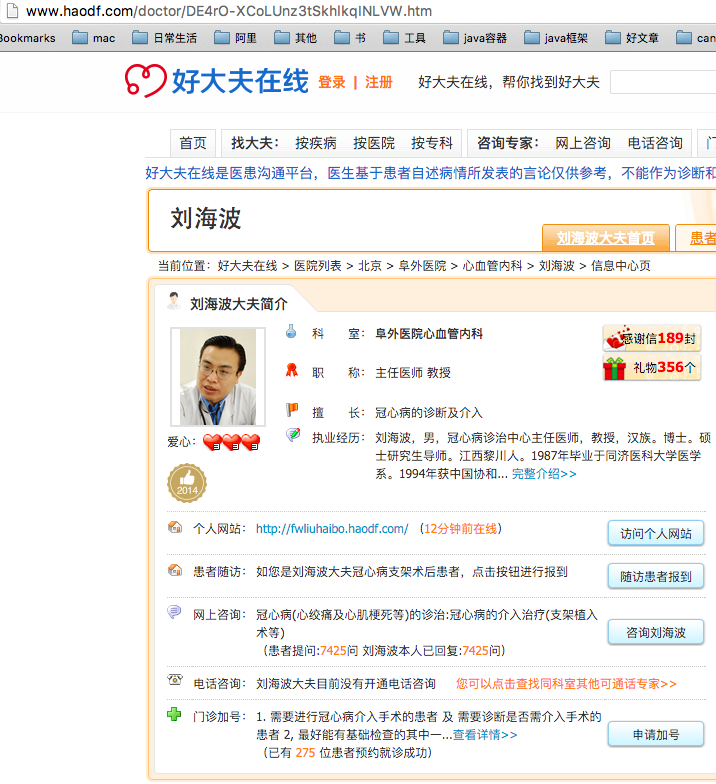
总结一下,就是最后要抓取的数据有:
科室 子科室 医院 科室介绍 专家 专家头像 职位 擅长 专家介绍
需求分析
确定爬取路径:
1、首先抓取http://www.haodf.com/keshi/list.htm页,提取科室和自科室;
2、抓取每个科室里面的好评科室;
3、提取每个好评科室里面的科室信息,然后抓取推荐专家;
4、提取医院信息,抓取每个推荐专家
5、专家详情页抓取专家、专家头像等信息
遇到的困难,以及解决方案
1、如何实现逐级抓取?
抓取的起点是http://www.haodf.com/keshi/list.htm,然后需要根据页面中得内容进行逐级抓取,scrapy提供了一种机制,来实现这样的需求,那就是解析完页面除了返回item数据之外,还可以返回一个Request对象,并且可以指定爬取完以后的回调函数。
比如:yield Request(department_url, callback=self.parse_more_department, meta = {‘item’: item})
department_url:接着要爬取的url地址
callback:爬取成功后的回调函数
2、如何将分散的信息汇总在一起?
数据分散在各个页面里,而我们最终的结果,要以我们定义好的item结构返回,那如何将不同页面的信息组装到item里呢?
比如第一级爬取到得科室,子科室,如何搜集,一般的解决方法就是使用meta来传递,
比如:yield Request(department_url, callback=self.parse_more_department, meta = {‘item’: item})
meta:这个meta信息会被传递到下一级爬取页面的response.meta里面;
下一级页面的获取方法是response.meta[‘item’]
3、抓到的页面内容和在浏览器中看到的不一样,提取不到预想的信息怎么办?
我一般会现在火狐浏览器里面打开我要爬取的页面,利用火狐的插件
来进行xpath的提取测试,这样做可以提高你的工作效率,可以快速写出正确的xpath语句,
但是在爬取过程中,发现原本认为可以提取的信息确提取不到,后来通过wget 网址,抓取内容,发现这个内容和我在浏览器里面看到的不一样。
后来通过定位,发现,有些页面内容是需要执行js才有的,也就是说,直接抓到页面回来还不行,还要让抓回来的页面在浏览器里面执行下才行。
通过调研发现要使用scrapy+PhantomJS可以解决这个问题,正好我以前用过PhantomJS,你可以把它理解成服务器端的浏览器,具体的安装我会专门写一篇文章。
调用很简单
driver = webdriver.PhantomJS()
driver.get(url)
driver.page_sourcepage_source就是相当于浏览器执行完之后页面
4、速度太快被好大夫封掉,不让爬怎么办?
当写完代码兴高采烈的跑程序时,跑一会发现很多的403,意味着完蛋了,好大夫把我屏蔽了,通过分析发现自己跑的太快了导致的,那怎么限速呢?这个很简单
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









