







文章目录
centos 换源
1、确保更换之前确保自己安装wget,若是没安装wget直接安装即可
yum list wget
yum -y install wget
2、首先备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
3、下载阿里云的yum源到/etc/yum.repos.d/
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
4、清除缓存
yum clean all
5、更新本地YUM缓存
yum makecache
安装c++编译器并且更新
安装
yum -y install gcc*
更新
1、安装CentOS的第三方软件源,如devtoolset:
sudo yum install -y centos-release-scl
安装devtoolset软件集,其中包含更新的GCC版本。例如,要安装devtoolset-9
sudo yum install -y devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
3、启用新版本的GCC
scl enable devtoolset-9 bash
4、永久更改GCC版本,
echo "source /opt/rh/devtoolset-9/enable" >> ~/.bash_profile
source ~/.bash_profile
编译:单文件以及多文件
单文件
有文件 demo.cpp
编译

执行

多个文件编译


编译选项
g++ 选项 源代码文件1 ...
常用选项:
-o : 指定输出文件的名,这个名称不能和源文件同名。默认为a.out
-g :对源代码进行调试
-On:在编译、链接中进行优化处理,生成的可执行程序效率更高
-c:只编译,不链接成为可执行文件,通常用于把源文件编译成静态库或动态库
-std=c++11 支持C++11标准
-I:(大写i)指定头文件所在目录
-L:指定链接库所在目录
-l:指定链接库名
优化选项

如果选择了优化选项:编译时间更长、目标程序不可调试、有效果,但是不可能显著提升程序的性能
静态库与动态库
实际开发的时候,通常把函数和类份文件编写,称之为库。
在其他的程序中,可以使用库中的函数和类。
一般来说,通用的函数和类不提供源代码文件(安全性、机密性),而是编译成二进制文件(分为静态库和动态库)。
静态库
1、制作静态库
g++ -c -o lib 库名.a 源代码文件清单
2、使用静态库
不规范的做法:g++ 选项 源代码文件名清单 静态库名
规划做法:g++ 选项 源代码文件名清单 -L库名所在目录 -l库名
3、静态库的概念
程序在编译时会把库文件的二进制代码链接到目标程序中,这种方式称为静态链接
如果多个程序中用到了同一静态库中的函数或类 ,就存在多份拷贝
4、静态库特点
- 静态库的链接是在编译时期完成的,执行的时候代码加载速度快
- 目标程序的可执行文件比较大,浪费空间
- 程序的更新和发布不方便。如果某一个静态库更新了,所有使用它的程序都需要重新编译
实操:

编译

制作库

使用库

动态库
1、制作动态库
g++ -fPIC -shared -o lib 库名.so 源代码文件清单
2、使用动态库
不规范的做法:g++ 选项 源代码文件名清单 动态库名
规划做法:g++ 选项 源代码文件名清单 -L库名所在目录 -l库名
运行可执行程序的时候需要提前设置LD_LIBRARY_PATH环境变量
3、动态库的概念
程序在编译时不会把库文件的二进制代码链接到目标程序中,而是在运行时候才被载入
如果多个程序中用到了同一静态库中的函数或类 ,那么在内存中只有一份,避免了空间的浪费
4、动态库特点
- 程序运行在运行的过程中,需要用到动态库的时候才把动态库的二进制代码载入内存
- 可以实现进程之间的代码共享,因此动态库也称为共享库
- 程序升级变得简单,不需要重新编译程序,只需要更新动态库就行了
不规范的使用


将动态库目录加入LD_LIBRARY_PATH环境变量


makefile
make是一个强大的实用工具,用于管理的编译和链接。make需要一个编译规则文件makefile,可实现自动化编译
增量编译
# 变量
O=book.cpp
# 指定编译的目标文件
all:book
# 编译book需要依赖book.cpp
book:book.cpp
g++ -o book book.cpp $(O)
# 用于清理book 使用make clean 触发
clean:
rm book
main函数的参数
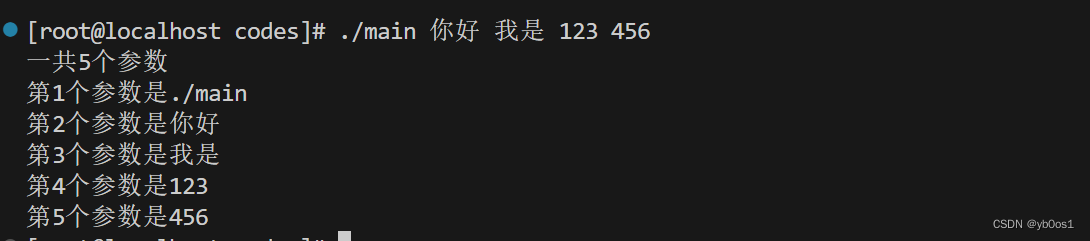
main函数有三个参数:arga、argv、envp
int main(int argc,char*argv[],char*envp[]){}
- argc:程序参数的个数
- argv:存放每个参数的值
- envp:环境变量,用的少 ,数组最后一个是0
#include<iostream>
using namespace std;
int main(int argc,char*argv[]){
cout<<"一共"<<argc<<"个参数"<<endl;
for(int i = 0;i < argc;++i){
cout<<"第"<<i+1<<"个参数是"<<argv[i]<<endl;
}
return 0;
};
#include<iostream>
using namespace std;
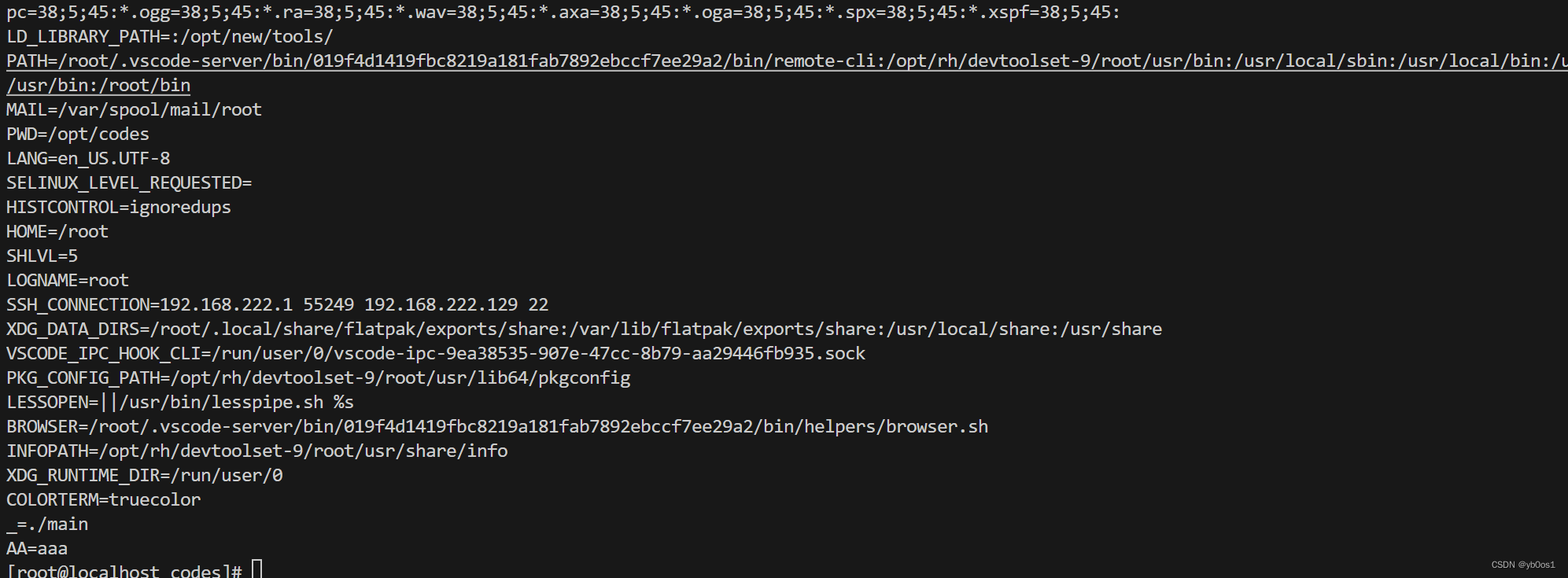
int main(int argc,char*argv[],char*envp[]){
for(int i = 0;envp[i]!=0 ;++i){
cout<<envp[i]<<endl;
}
setenv("AA","aaa",0);
cout<<"AA="<<getenv("AA")<<endl;
return 0;
};
gdb调试
基础
加上-g选项而且不能-O优化,才可以调试
gdb 文件
设置参数
| 命令 | 简写 | 说明 |
|---|---|---|
| set args | 设置程序运行的参数 | |
| break | b | 设置断点,b 20表示在20行设置断点,可以设置多个断点 |
| run | r | 开始运行程序,遇到断点才停止 |
| next | n | 执行当前行语句,如果该语句为函数调用,不会进入函数内部 |
| step | s | 执行当前行语句,如果该语句为函数调用,会进入函数内部。只是进入有源码的函数 |
| p | 显示变量或者表达式的值,也可以修改变量的值 | |
| continue | c | 继续运行程序,遇到下一个断点停止,没有断点一直执行 |
| set var | 设置变量的值, set var num=100 | |
| quit | q | 退出gdb |
调试core文件
如果程序在运行的过程中发生了内存泄漏,会被内核强行终止,提示“段错误(吐核)”,内存的状态将保存在 core 文件中,方便程序员进一步分析。
#include<iostream>
using namespace std;
int main(int argc,char*argv[]){
char*ptr = nullptr;
*ptr=3;
return 0;
};
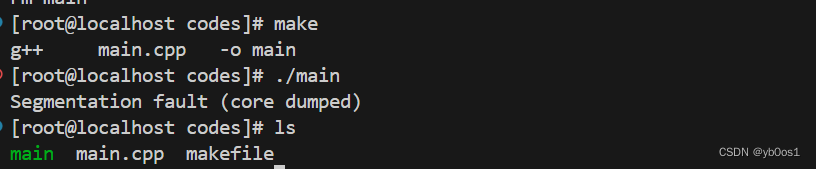
Linux缺省不会生成core文件,需要修改系统参数
调式core文件的步骤如下
- 使用
ulimit-a查看当前用户的资源限制参数 - 用
ulimit -c unlimited把core file size改为unlimited - 运行程序,产生core文件
- 使用
gdb main core文件名进行调试core文件 bt查看函数调用栈

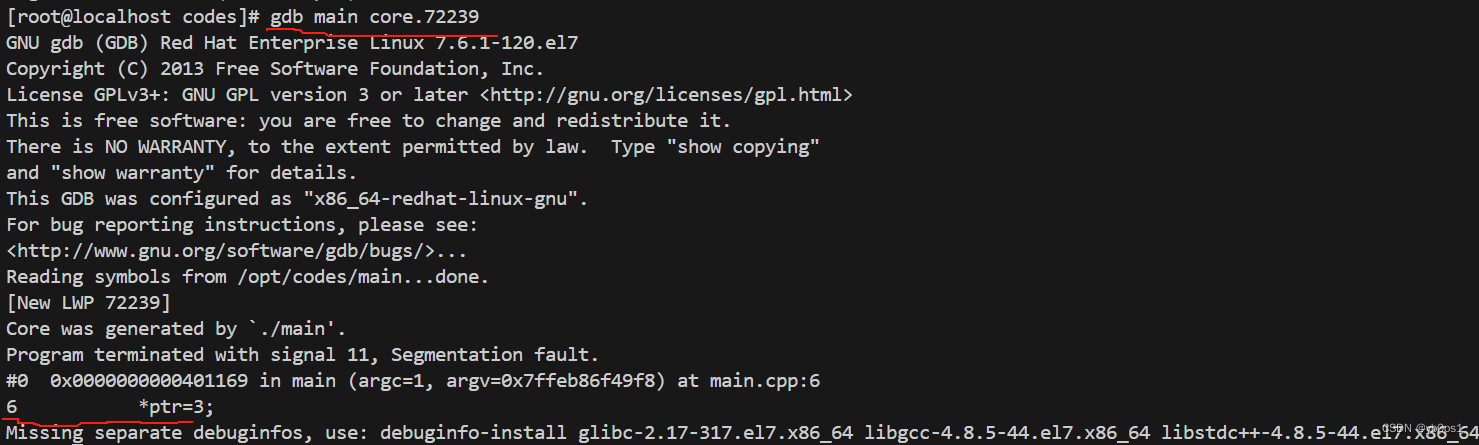
bt查看函数调用栈

调试正在运行中的程序
#include<iostream>
#include <unistd.h>
using namespace std;
void fun(){
for(int i = 0;i < 10000;++i){
sleep(1);
cout<<"i="<<i<<endl;
}
}
int main(int argc,char*argv[]){
fun();
return 0;
};
需要知道进程id
此时程序已经暂停
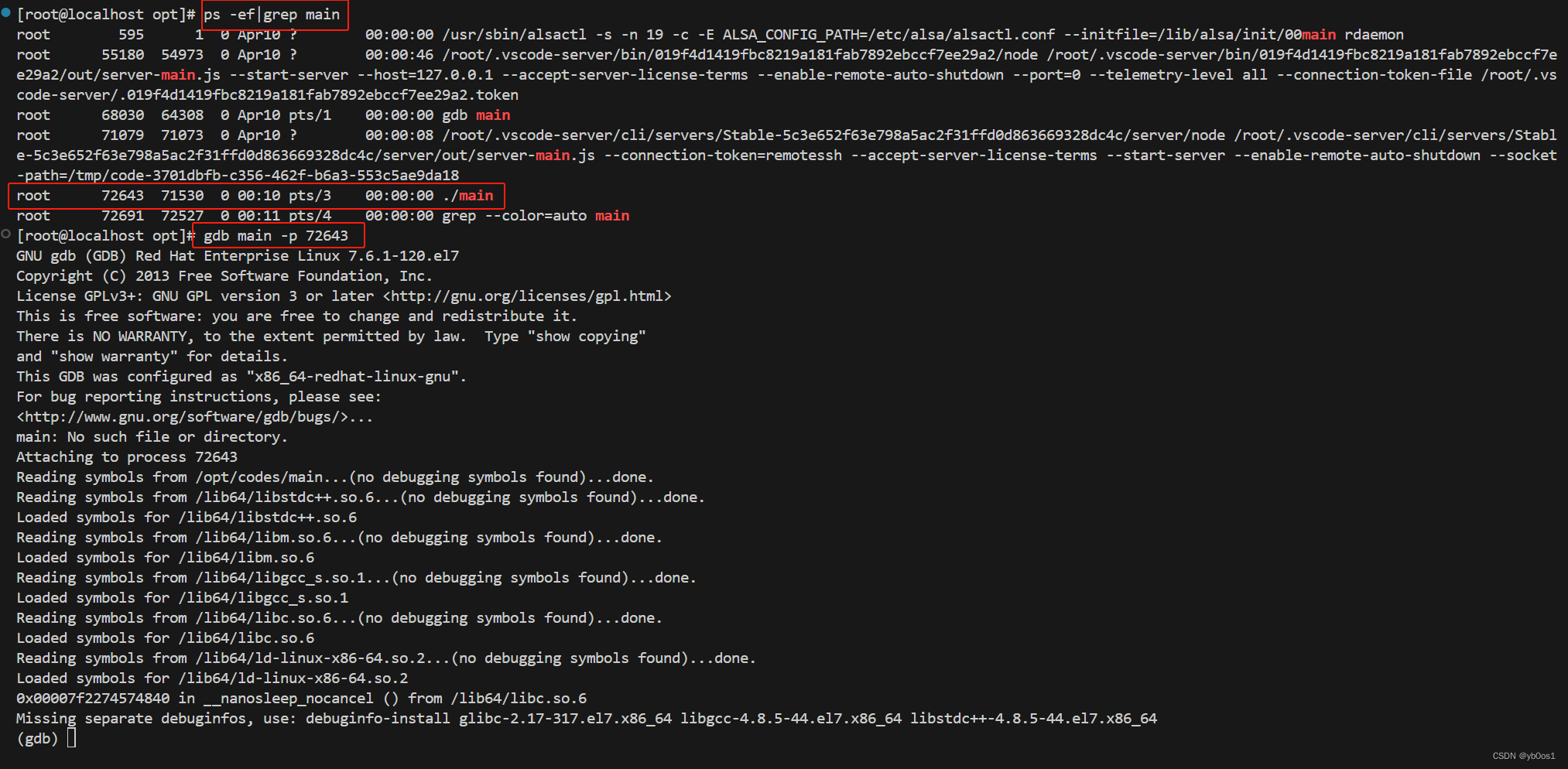
Linux时间操作
1970年1月1日组为UNIX的纪元时间,使用一个整数存放
time_t别名
time_t就是long类型的别名,在time.h文件中定义
typedef long time_t
time库函数
获取当前操作系统的时间
time.h中
time_t time(time_t*tloc);
//两种调用方法
time_t now = time(0);
time_t now;
time(&now);
tm结构体
time_t是一个长整数,不符合人类的使用习惯,需要转换成tm 结构体,tm 结构体在<time.h>中

localtime()库函数
localtime()函数用于把 time_t表示的时间转换为 tm 结构体表示的时间。
localtime()函数不是线程安全的,localtime_r()是线程安全的。
在time.h中

年要+1900
月份要+1
mktime库函数

gettimeofdat()库函数
用于获取 1970 年1月1日到现在的秒和当前秒中已逝去的微秒数,可以用于程序的计时。
sys/time.h

程序睡眠
如果需要把程序挂起一段时间,可以使用sleep()和 usleep()两个库函数
unistd.h
sleep单位是秒
usleep单位是微秒

Linux文件操作
简单的目录操作
获取当前工作目录
头文件unistd.h
char *getcwd(char *buf, size_t size);
char *get_current_dir_name(void);
void test(){
char path[256];//linux系统目录最大长度为255
getcwd(path,256);
std::cout<<"path="<<path<<std::endl;
char *path0=get_current_dir_name();//malloc分配内存 是对空间开辟的
std::cout<<"path0="<<path0<<std::endl;
free(path0);//注意释放内存
}
切换工作目录
包含头文件:<unistd.h>
int chdir(const char *path);
返回值:0-成功;其它-失败(目录不存在或没有权限
创建目录
头文件sys/stat.h
int mkdir(const char *pathname, mode_t mode);
/*
pathname-目录名。
mode-访问权限,如0755,不要省略前置的0。
返回值:0-成功;其它-失败(上级目录不存在或没有权限)。 /tmp/aaa /tmp/aaa/bbb
*/
删除目录
包含头文件: unistd.h
int rmdir(const char *path);
/*
path-目录名。
返回值:0-成功;其它-失败(目录不存在或没有权限)。
*/
获取存取权限access
access()用于判断当前用户对目录或文件的存取权限
含头文件:#include <unistd.h>
函数声明:
int access(const char *pathname, int mode);
参数说明:
pathname 目录或文件名。
mode 需要判断的存取权限。
在头文件<unistd.h>中的预定义如下:
#define R_OK 4 // 判断是否有读权限。
#define W_OK 2 // 判断是否有写权限。
#define X_OK 1 // 判断是否有执行权限。
#define F_OK 0 // 判断是否存在。
当pathname满足mode权限返回0,不满足返回-1,errno被设置。
在实际开发中,access()函数主要用于判断目录或文件是否存在
void fun(){
int flag = access("/opt/tmp/AA",F_OK);
std::cout<<errno<<"."<<strerror(errno)<<std::endl;
std::cout<<flag<<std::endl;
}
stat()库函数
stat结构体
struct stat结构体用于存放目录或文件的详细信息,如下:
struct stat
{
dev_t st_dev; // 文件的设备编号。
ino_t st_ino; // 文件的i-node。
mode_t st_mode; // 文件的类型和存取的权限。
nlink_t st_nlink; // 连到该文件的硬连接数目,刚建立的文件值为1。
uid_t st_uid; // 文件所有者的用户识别码。
gid_t st_gid; // 文件所有者的组识别码。
dev_t st_rdev; // 若此文件为设备文件,则为其设备编号。
off_t st_size; // 文件的大小,以字节计算。
size_t st_blksize; // I/O 文件系统的I/O 缓冲区大小。
size_t st_blocks; // 占用文件区块的个数。
time_t st_atime; // 文件最近一次被存取或被执行的时间,
// 在用mknod、 utime、read、write 与tructate 时改变。
time_t st_mtime; // 文件最后一次被修改的时间,
// 在用mknod、 utime 和write 时才会改变。
time_t st_ctime; // 最近一次被更改的时间,在文件所有者、组、 权限被更改时更新。
};
struct stat结构体的成员变量比较多,重点关注st_mode、st_size和st_mtime成员。
注意:st_mtime是一个整数表示的时间,需要程序员自己写代码转换格式。
st_mode成员的取值很多,用以下两个宏来判断:
S_ISREG(st_mode) // 是否为普通文件,如果是,返回真。
S_ISDIR(st_mode) // 是否为目录,如果是,返回真。
stat库函数
#include <sys/stat.h>
函数声明:int stat(const char *path, struct stat *buf);
stat()函数获取path参数指定目录或文件的详细信息,保存到buf结构体中。
返回值:0-成功,-1-失败,errno被设置。
void fun(){
struct stat st;
if((stat("/opt/codes/file.cpp",&st))!=0){
std::cout<<"错误:"<<strerror(errno)<<std::endl;
return;
}
if(S_ISREG(st.st_mode))std::cout<<"是一个文件,创建时间是"<<st.st_mtime<<std::endl;
else if(S_ISDIR(st.st_mode))std::cout<<"是一个目录,创建时间是"<<st.st_mtime<<std::endl;
}
修改目录或文件的时间utime
#include <sys/types.h>
#include <utime.h>
函数声明:
int utime(const char *filename, const struct utimbuf *times);
utime()函数用来修改参数filename的st_atime和st_mtime。如果参数times为空地址,则设置为当前时间。结构utimbuf 声明如下:
struct utimbuf
{
time_t actime;
time_t modtime;
};
返回值:0-成功,-1-失败,errno被设置。
重命名rename
rename()函数用于重命名目录或文件,相当于操作系统的mv命令。
包含头文件:
#include <stdio.h>
函数声明:
int rename(const char *oldpath, const char *newpath);
参数说明:
oldpath 原目录或文件名。
newpath 目标目录或文件名。
返回值:0-成功,-1-失败,errno被设置。
删除remove
remove()函数用于删除目录或文件,相当于操作系统的rm命令。
包含头文件:
#include <stdio.h>
函数声明:
int remove(const char *pathname);
参数说明:
pathname 待删除的目录或文件名。
返回值:0-成功,-1-失败,errno被设置。
获取目录中文件的列表
文件存放在目录中,在处理文件之前,必须先知道目录中有哪些文件,所以要获取目录中文件的列表。
dirent.h
步骤一:用opendir()函数打开目录。
DIR *opendir(const char *pathname);
成功-返回目录的地址,失败-返回空地址。
步骤二:用readdir()函数循环的读取目录。
struct dirent *readdir(DIR *dirp);
成功-返回struct dirent结构体的地址,失败-返回空地址。
步骤三:用closedir()关闭目录。
int closedir(DIR *dirp);
目录指针:
DIR *目录指针变量名;
每次调用readdir(),函数返回struct dirent的地址,存放了本次读取到的内容。
struct dirent
{
long d_ino; // inode number 索引节点号。
off_t d_off; // offset to this dirent 在目录文件中的偏移。
unsigned short d_reclen; // length of this d_name 文件名长度。
unsigned char d_type; // the type of d_name 文件类型。
char d_name [NAME_MAX+1]; // file name文件名,最长255字符。
};
重点关注结构体的d_name和d_type成员。
d_name-文件名或目录名。
d_type-文件的类型,有多种取值,最重要的是8和4,8-常规文件(A regular file);4-子目录(A directory),其它的暂时不关心。注意,d_name的数据类型是字符,不可直接显示。
void test(char *dir){
DIR *d;
if((d=opendir(dir))==nullptr)return;
struct dirent*stdinfo=nullptr;
while(true){
if((stdinfo=readdir(d))==nullptr)break;
std::cout<<"文件名="<<stdinfo->d_name<<",文件类型="<<int(stdinfo->d_type)<<std::endl;
}
closedir(d);
}
Linux系统错误
在C++程序中,如果调用了库函数,可以通过函数的返回值判断调用是否成功。其实,还有一个整型的全局变量errno,存放了函数调用过程中产生的错误代码。
如果调用库函数失败,可以通过errno的值来查找原因,这也是调试程序的一个重要方法。
errno在<errno.h>中声明。
配合 strerror()和perror()两个库函数,可以查看出错的详细信息。
strerror库函数
在string.h,用于获取错误代码对应的详细信息
char *strerror(int errnum); // 非线程安全。
int strerror_r(int errnum, char *buf, size_t buflen); // 线程安全。
gcc8.3.1一共有133个错误代码。
for(int i = 0;i < 200;++i){
std::cout<<strerror(i)<<std::endl;
}
int iret = mkdir("/opt/tmp",0755);
std::cout<<"iret="<<iret<<std::endl;
std::cout<<errno<<"."<<strerror(errno)<<std::endl;
perror()库函数
perror() 在<stdio.h>中声明,用于在控制台显示最近一次系统错误的详细信息,在实际开发中,服务程序在后台运行,通过控制台显示错误信息意义不大。(对调试程序略有帮助)
void perror(const char *s);
int iret = mkdir("/opt/tmp",0755);
std::cout<<"iret="<<iret<<std::endl;
std::cout<<errno<<"."<<strerror(errno)<<std::endl;
perror("最近的信息");
}
注意事项
1)调用库函数失败不一定会设置errno
并不是全部的库函数在调用失败时都会设置errno的值,以man手册为准(一般来说,不属于系统调用的函数不会设置errno,属于系统调用的函数才会设置errno)。
什么是系统调用?百度“库函数和系统调用的区别”。
2)errno不能作为调用库函数失败的标志
errno的值只有在库函数调用发生错误时才会被设置,当库函数调用成功时,errno的值不会被修改,不会主动的置为 0。
在实际开发中,判断函数执行是否成功还得靠函数的返回值,只有在返回值是失败的情况下,才需要关注errno的值。
int iret = mkdir("/opt/tmp",0755);
std::cout<<"iret="<<iret<<std::endl;
std::cout<<errno<<"."<<strerror(errno)<<std::endl;
iret = mkdir("/opt/tmp/aaa",0755);
std::cout<<"iret="<<iret<<std::endl;
std::cout<<errno<<"."<<strerror(errno)<<std::endl;
perror("最近的信息");
上面的代码 第二次创建已经成功了,但是errno还是错误代码没有回归到0(成功代码)

Linux的信号
基本概念
信号(signal)是软件中断,是进程之间相互传递消息的一种方法,用于通知进程发生了事件,但是,不能给进程传递任何数据。
信号产生的原因有很多。在shell中可以使用kill或者killall发送信号
kill -信号类型 进程编号
killall -信号类型 进程名
信号的类型
Linux有64种信号:
列出比较重要的:
| 信号名 | 信号值 | 默认处理动作 | 发出信号的原因 |
|---|---|---|---|
| SIGINT | 2 | A | 键盘中断CTRL+C |
| SIGKILL | 9 | AEF | 采用 kill -9 进程编号 强制杀死程序 |
| SIGSEGV | 11 | CEF | 无效的内存引用(数组越界、操作空指针和野指针等) |
| SIGALRM | 14 | A | 由闹钟alarm()函数发出的信号 |
| SIGTERM | 15 | A | 采用“采用“kill 进程编号”或“killall 程序名”通知程序”或“killall 程序名”通知程序 |
| SIGCHLD | 17 | B | 子进程结束信号 |
其余的不是特别重要。
- A 缺省的动作是终止进程。
- B 缺省的动作是忽略此信号,将该信号丢弃,不做处理。
- C 缺省的动作是终止进程并进行内核映像转储(core dump)。
- D 缺省的动作是停止进程,进入停止状态的程序还能重新继续,一般是在调试的过程中。
- E 信号不能被捕获。
- F 信号不能被忽略。
信号的处理
进程对信号处理的方法有三种
- 对该信号的处理采用系统的默认操作,大部分的信号的默认操作是终止进程
- 设置信号的处理函数,收到信号后,由该函数来处理
- 忽略某个信号,对该信号不做任何处理,就像未发生过一样
默认、自定义、忽略
设置程序对信号处理方式的函数:signal()
函数声明:sighandler_t signal(int signum, sighandler_t handler);
- 参数
signum表示信号的编号(信号的值)。 - 参数handler表示信号的处理方式,有三种情况:
1)SIG_DFL:恢复参数signum信号的处理方法为默认行为。
2)一个自定义的处理信号的函数,函数的形参是信号的编号。
3)SIG_IGN:忽略参数signum所指的信号。
#include<iostream>
#include<unistd.h>
#include<signal.h>
void handle(int signNum){
std::cout<<"收到信号:"<<signNum<<std::endl;
exit(0);//退出进程
}
int main(int argc,char*argv[]){
signal(15,handle);
while(true){
std::cout<<"运行中..."<<std::endl;
sleep(1);
}
return 0;
}


每五秒处理一下handle函数
#include<iostream>
#include<unistd.h>
#include<signal.h>
void handle(int signNum){
std::cout<<"收到信号:"<<signNum<<std::endl;
alarm(5);
}
int main(int argc,char*argv[]){
signal(14,handle);
alarm(5);
while(true){
std::cout<<"运行中..."<<std::endl;
sleep(1);
}
return 0;
}
第一个执行handle函数之后会把信号15设置为默认(终止进程)
#include<iostream>
#include<unistd.h>
#include<signal.h>
void handle(int signNum){
std::cout<<"收到信号:"<<signNum<<std::endl;
signal(15,SIG_DFL);
}
int main(int argc,char*argv[]){
signal(15,handle);
while(true){
std::cout<<"运行中..."<<std::endl;
sleep(1);
}
return 0;
}
信号有什么用
-
服务程序运行在后台,如果想让中止它,杀掉不是个好办法,因为进程被杀的时候,是突然死亡,没有安排善后工作。我们可以向服务程序发送一个信号,服务程序收到信号后,调用一个函数,在函数中编写善后的代码,程序就可以有计划的退出。
-
如果向服务程序发送0的信号,可以检测程序是否存活
善后工作
#include<iostream>
#include<unistd.h>
#include<signal.h>
void EXIT(int signNum){
std::cout<<"保存资源...\n释放资源...\n程序退出\n";
// 进程退出。
exit(0);
}
int main(int argc,char*argv[]){
// 忽略全部的信号,防止程序被信号异常中止
for(int i = 1;i <= 64;++i)signal(i,SIG_IGN);
// 如果收到2和15的信号(Ctrl+c和kill、killall),本程序将主动退出
signal(2,EXIT);
signal(15,EXIT);
while(true){
std::cout<<"工作中...\n";
sleep(1);
}
return 0;
}
服务程序正在运行:无反应
服务程序没运行:如下错误

发送信号
Linux操作系统提供了kill和killall命令向进程发送信号,在程序中,可以用kill()函数向其它进程发送信号。
函数声明:
int kill(pid_t pid, int sig);
kill()函数将参数sig指定的信号给参数pid 指定的进程。
参数pid 有几种情况:
1)pid>0 将信号传给**进程号为pid **的进程。
2)pid=0 将信号传给和当前进程相同进程组的所有进程,常用于父进程给子进程发送信号,注意,发送信号者进程也会收到自己发出的信号。
3)pid=-1 将信号广播传送给系统内所有的进程,例如系统关机时,会向所有的登录窗口广播关机信息。
sig:准备发送的信号代码
假如其值为0则没有任何信号送出,但是系统会执行错误检查,通常会利用sig值为零来检验某个进程是否仍在运行。
返回值说明: 成功执行时,返回0;失败返回-1,errno被设置。
进程终止
有8种方式可以终止紧张,
其中5种为正常终止:
- main()函数用
return返回 - 任意函数中
exit()函数 - 在任意函数中调用
_exit()或者_Exit()函数 - 最后一个线程从其启动例程(线程主函数)用
return返回; - 在最后一个线程中调用
pthread_exit()返回;
异常终止:
abort()函数中止- 接受一个信号
- 最后一个线程对取消请求做出响应
进程终止的状态
在main()函数中,return的返回值即终止状态,如果没有return语句或调用exit(),那么该进程的终止状态是0
shell中查看进程终止状态echo $?
正常终止进程的3个函数(exit()和_Exit()是由ISO C说明的,_exit()是由POSIX说明的)。
void exit(int status);
void _exit(int status);
void _Exit(int status);
status也是进程终止的状态
如果进程被异常终止,终止状态为非0
终止状态应用:服务程序的调度、日志和监控
资源释放问题
return:调用局部对象的析构函数。main函数中的还会调用全局对象的析构函数exit():不会调用局部对象的析构函数,会调用全局对象的析构函数,会执行清理工作_exit() _Exit():直接退出,不会执行任何清理工作
#include<iostream>
#include<string.h>
using std::string;using std::cout;using std::endl;
class Test{
public:
string name;
Test(string name):name(name){cout<<"构造函数\n";}
~Test(){cout<<name<<"析构函数\n";}
};
Test t1("全局对象");
int main(){
Test t2("局部对象");
return 0;
}

#include<iostream>
#include<string.h>
using std::string;using std::cout;using std::endl;
class Test{
public:
string name;
Test(string name):name(name){cout<<"构造函数\n";}
~Test(){cout<<name<<"析构函数\n";}
};
Test t1("全局对象");
int main(){
Test t2("局部对象");
exit(0);
}

#include<iostream>
#include<string.h>
#include <unistd.h>
using std::string;using std::cout;using std::endl;
class Test{
public:
string name;
Test(string name):name(name){cout<<"构造函数\n";}
~Test(){cout<<name<<"析构函数\n";}
};
Test t1("全局对象");
int main(){
Test t2("局部对象");
_exit(0);
}

进程终止函数
进程可以用atexit()函数登记终止函数(最多32个),这些函数将由exit()自动调用。
int atexit(void (*function)(void));
exit()调用终止函数的顺序与登记时相反。 (先入后出)
作用:进程退出前的收尾工作
#include<iostream>
#include <unistd.h>
using std::cout;using std::endl;
void fun1(){
cout<<"fun1\n";
}
void fun2(){
cout<<"fun2\n";
}
int main(){
atexit(fun1);
atexit(fun2);
exit(0);
}
调用可执行程序
Linux提供了system()函数和exec()函数族,在C++程序中,可以执行其它的程序(二进制文件、操作系统命令或Shell脚本)
system函数
system()函数提供了一种简单的执行程序的方法,把需要执行的程序和参数用一个字符串传给system()函数就行了
函数的声明:
int system(const char * string);
system()函数的返回值比较麻烦:
1)如果执行的程序不存在,system()函数返回非0;
2)如果执行程序成功,并且被执行的程序终止状态是0,system()函数返回0;
3)如果执行程序成功,并且被执行的程序终止状态不是0,system()函数返回非0。
执行终止状态为0
#include<iostream>
#include <stdlib.h>
using std::cout;
using std::endl;
int main(){
int res = system("/bin/ls /opt");
cout<<"res="<<res<<endl;
perror("system");
}

有错误
#include<iostream>
#include <stdlib.h>
using std::cout;
using std::endl;
int main(){
int res = system("/bin/lsss /opt");
cout<<"res="<<res<<endl;
perror("system");
}

exec函数族
exec函数族提供了另一种在进程中调用程序(二进制文件或Shell脚本)的方法
exec函数族的声明如下:
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg,...,char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],char *const envp[]);
注意:
1)如果执行程序失败则直接返回-1,失败原因存于errno中。
2)新进程的进程编号与原进程相同,但是,新进程取代了原进程的代码段、数据段和堆栈。
3)如果执行成功则函数不会返回,当在主程序中成功调用exec后,被调用的程序将取代调用者程序,也就是说,exec函数之后的代码都不会被执行
4)在实际开发中,最常用的是execl()和ex ecv(),其它的极少使用。
#include <iostream>
#include <string.h>
#include <unistd.h>
using namespace std;
int main(int argc,char *argv[])
{
int ret=execl("/bin/ls","/bin/ls","-lt","/tmp",0); // 最后一个参数0不能省略。
//下面的是不会运行的
//因为新进程的进程编号与原进程相同,但是,新进程取代了原进程的代码段、数据段和堆栈
cout << "ret=" << ret << endl;
perror("execl");
/*
char *args[10];
args[0]="/bin/ls";
args[1]="-lt";
args[2]="/tmp";
args[3]=0; // 这行代码不能省略。
int ret=execv("/bin/ls",args);
cout << "ret=" << ret << endl;
perror("execv");
*/
}
创建进程
Linux的0、1和2号进程
整个Linux系统全部的进程是一个树形结构
0号进程(系统进程)是所有进程的祖先 ,它创建了1号和2号进程
1号进程(systemd)负责执行内核的初始化工作和进行系统配置
2号进程(kthreadd)负责所有内核线程的调度和管理
pstree可以查看进程树
pstree -p 进程编号
进程标识
每个进程都有一个非负整数表示的唯一的进程ID。
虽然是唯一的ID,但是进程ID可以复用。
当一个进程终止后,其进程ID就成为了复用的候选者
Linux采用延迟复用算法,让新创建进程的ID不同于最近终止的进程所使用的ID,这样防止了新进程被误认为是使用同一ID的某个已终止的进程
pid_t getpid(void); 获取当前进程的ID
pid_t getppid(void); 获取父进程的ID
fork函数
一个现有的进程可以调用fork()函数创建一个新进程
pid_t fork(void);
fork创建的是子进程,子进程是父进程的副本,父进程和子进程都从调用fork()之后的代码开始执行(fork之后的代码父进程和子进程都会执行)
fork()函数被调用一次,但返回两次。两次返回的区别是子进程的返回值是0,而父进程的返回值则是子进程的进程ID,通过返回值可以区分子进程和父进程
子进程获得了父进程数据空间、堆和栈的副本
注意:
- 子进程拥有的是副本,不是和父进程共享;
- 但是子进程和主进程变量的地址是一样的,这里是虚拟地址而不是物理地址,系统做了处理只是看起来相同
- 地址一样:如果存在引用,那么一开始就是确定了地址,子进程和主进程要访问引用必须是一样的地址
fork之后,主进程和子进程执行顺序是不确定的
地址相同,子进程修改变量不会影响父进程
#include<iostream>
#include<unistd.h>
#include<string.h>
using namespace std;
int main(){
string name = "yb0os1";
int num = 5;
int&rnum = num;//引用指向地址不可变 所以子进程和父进程变量地址相同
//子进程返回0 父进程返回子进程的pid
pid_t pid = fork();
if (pid>0){
/* 父进程 */
sleep(1);
cout<<"父进程:"<<num<<"-"<<name<<endl;
cout<<"父进程:"<<&num<<"-"<<&name<<endl;
}else{
/* 子进程 */
name="yyy";
num = 120;
cout<<"子进程:"<<num<<"-"<<name<<endl;
cout<<"子进程:"<<&num<<"-"<<&name<<endl;
}
return 0;
}

fork的用法
- 父进程复制自己,然后,父进程和子进程分别执行不同的代码。这种用法在网络服务程序中很常见,父进程等待客户端的连接请求,当请求到达时,父进程调用fork(),让子进程处理些请求,而父进程则继续等待下一个连接请求
- 进程要执行另一个程序。这种用法在Shell中很常见,子进程从fork()返回后立即调用exec
exec新进程取代旧进程,这样对父进程就没有影响
system就是这样原理(父进程创建一个子进程)
#include<iostream>
#include<unistd.h>
using namespace std;
int main(){
if(fork()>0){
while(true){
cout<<"父进程..."<<endl;
sleep(1);
}
}else{
sleep(5);
execl("/bin/ls","/bin/ls","-lt","/opt",0);//0不可以省略
cout<<"子进程结束..."<<endl;
}
return 0;
}
共享文件
fork()的一个特性是在父进程中打开的文件描述符都会被复制到子进程中,父进程和子进程共享同一个文件偏移量,也就是说会写入两份,不会覆盖
如果父进程和子进程写同一描述符指向的文件,但又没有任何形式的同步,那么它们的输出可能会相互混合。
#include <iostream>
#include <fstream>
#include <unistd.h>
using namespace std;
int main()
{
ofstream fout;
fout.open("/tmp/tmp.txt"); // 打开文件。
fork();
for (int ii=0;ii<10000000;ii++) // 向文件中写入一千万行数据。
{
fout << "进程" << getpid() << "西施" << ii << "极漂亮" << "\n";
}
fout.close(); // 关闭文件。
}

vfork()
返回值和fork函数相同,但是两者语义不同
vfork函数创建一个进程,而该新进程的目的是exec一个新程序,它不复制父进程的地址空间,因为子进程会立即调用exec,于是也就不会使用父进程的地址空间。如果子进程使用了父进程的地址空间,可能会带来未知的结果。
另外一个区别:vfork()保证子进程先运行,在子进程调用**exec或exit()**之后父进程才恢复运行
僵尸进程
如果父进程比子进程先退出,那么子进程将被1号进程托管(这也是让程序在后台运行的方法)
#include<iostream>
#include<unistd.h>
using namespace std;
int main(){
if(fork()>0)return 0; //是主进程就退出
//子进程后台运行
for(int i = 0;i < 10;++i){
sleep(1);
cout<<"程序后台运行"<<endl;
}
return 0;
}
#include<iostream>
#include<unistd.h>
using namespace std;
int main(){
if(fork()>0){
sleep(10);
cout<<"主进程结束..."<<endl;
}else{
for(int i = 0;i < 100;++i){
sleep(1);
cout<<"子进程"<<endl;
}
}
return 0;
}
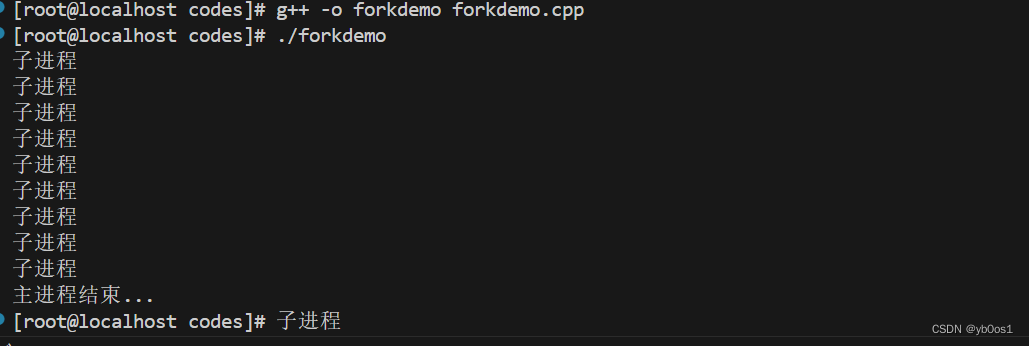

如果子进程比父进程先退出,而且父进程没有处理子进程退出的信息,那么子进程将变成僵尸进程
僵尸进程
#include<iostream>
#include<unistd.h>
using namespace std;
int main(){
if(fork()==0)return 0;
for(int i = 0;i < 100;++i){
sleep(1);
cout<<"父进程"<<endl;
}
return 0;
}

僵尸进程危害
内核为每个子进程保留了一个数据结构,包括进程编号、终止状态、使用CPU时间等。
父进程如果处理了子进程退出的信息,内核就会释放这个数据结构
父进程如果没有处理子进程退出的信息,内核就不会释放这个数据结构,子进程的进程编号将一直被占用
系统可用的进程编号是有限的,如果产生了大量的僵尸进程,将因为没有可用的进程编号而导致系统不能产生新的进程
避免僵尸进程
一、子进程退出的时候,内核会向父进程发头SIGCHLD信号,如果父进程用signal(SIGCHLD,SIG_IGN)通知内核,表示自己对子进程的退出不感兴趣,那么子进程退出后会立即释放数据结构
但是这样做父进程捕获不得子进程的退出信息
#include<iostream>
#include<unistd.h>
#include<signal.h>
using namespace std;
int main(){
signal(SIGCHLD,SIG_IGN);
if(fork()==0)return 0;
for(int i = 0;i < 100;++i){
sleep(1);
cout<<"父进程"<<endl;
}
return 0;
}

二、父进程通过wait()/waitpid函数等待子进程结束,在子进程退出之前父进程将被阻塞
pid_t wait(int *stat_loc);
pid_t waitpid(pid_t pid, int *stat_loc, int options);
pid_t wait3(int *status, int options, struct rusage *rusage);
pid_t wait4(pid_t pid, int *status, int options, struct rusage *rusage);
返回的是子进程的编号
父进程会一直等待,wait之后的代码无法执行,直到子进程退出之后,wait之后的代码才可以正常执行
#include<iostream>
#include<unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
int main(){
if(fork()>0){
int sts;
pid_t pid=wait(&sts);
cout << "已终止的子进程编号是:" << pid<< endl;
sleep(30);
if(WIFEXITED(sts)){
cout<<"子进程正常退出,退出状态是:"<<WEXITSTATUS(sts)<<endl;
}else{
cout<<"子进程是异常退出的,终止它的信号是:"<<WTERMSIG(sts)<<endl;
}
} else{
pid_t pid = getpid();
cout<<pid<<endl;
sleep(10);
return 0;
}
return 0;
}

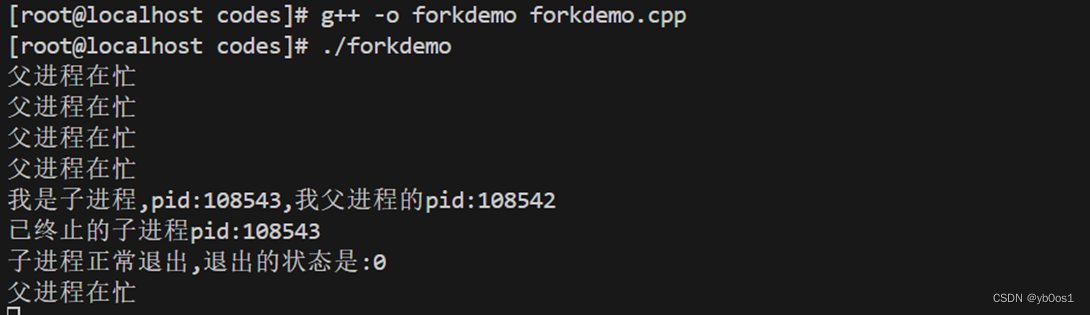
三、如果父进程很忙,可以捕获SIGCHLD信号,在信号处理函数中调用wait()/waitpid()
这样可以实现父进程代码正常运行,并且可以处理子进程的退出
#include<iostream>
#include<unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include<signal.h>
using namespace std;
void handle(int sig){//这个形参是必须要有的
int sts;
pid_t pid = wait(&sts);
cout<<"已终止的子进程pid:"<<pid<<endl;
if(WIFEXITED(sts)){
cout<<"子进程正常退出,退出的状态是:"<<WEXITSTATUS(sts)<<endl;
}else{
cout<<"子进程异常退出,终止的信号是:"<<WTERMSIG(sts)<<endl;
}
}
int main(){
signal(SIGCHLD,handle);
if(fork()>0){
while(true){
sleep(1);
cout<<"父进程在忙"<<endl;
}
}else{
sleep(5);
cout<<"我是子进程,pid:"<<getpid()<<",我父进程的pid:"<<getppid()<<endl;
return 0;
}
return 0;
}
多进程与信号
在多进程的服务程序中,如果子进程收到退出信号,子进程自行退出;如果父进程收到退出信号,则应该先向全部的子进程发送退出信号,然后自己再退出
子自己退,父管理子
#include <iostream>
#include <unistd.h>
#include <signal.h>
using namespace std;
void childEXIT(int sig);
void fatherEXIT(int sig);
int main(){
// 忽略全部的信号,不希望被打扰。
for (int ii=1;ii<=64;ii++) signal(ii,SIG_IGN);
// 设置信号,在shell状态下可用 "kill 进程号" 或 "Ctrl+c" 正常终止些进程
// 但请不要用 "kill -9 +进程号" 强行终止 SIGTERM 15 SIGINT 2
signal(SIGTERM,fatherEXIT);
signal(SIGINT,fatherEXIT);
while(true){
if(fork()>0){
sleep(3);
continue;
}else{
signal(SIGTERM,childEXIT);
signal(SIGINT,SIG_IGN);//子进程后台运行 一般没办法触发ctrl+c
while(true){
cout<<"子进程"<<getpid()<<"正在运行"<<endl;
sleep(3);
}
}
}
return 0;
}
void childEXIT(int sig){
// 以下代码是为了防止信号处理函数在执行的过程中再次被信号中断 一般子进程不会收到两次中断信号 但是加上也可以
signal(SIGTERM,SIG_IGN);
signal(SIGINT,SIG_IGN);
cout << "子进程" << getpid() << "退出,sig=" << sig << endl;
// 在这里增加释放资源的代码(只释放子进程的资源)
exit(0);
}
void fatherEXIT(int sig){
// 以下代码是为了防止信号处理函数在执行的过程中再次被信号中断 一般子进程不会收到两次中断信号 但是加上也可以
signal(SIGTERM,SIG_IGN);
signal(SIGINT,SIG_IGN);
cout<<"父进程退出 sig="<<sig<<endl;
kill(0,SIGTERM);//也会把中断信号发给自己 所以需要上面的代码
// 在这里增加释放资源的代码(全局的资源)
exit(0);
}


共享内存
在多线程中,多线程共享内存空间,如果多个线程想要访问同一块内存,定义全局变量就行
在多进程中,每个进程的地址空间是独立的,不共享的。如果多个进程想要访问同一块内存空间,不能使用全局变量,只能使用共享内存。
概念
共享内存(Shared Memory)允许多个进程(不要求进程之间有血缘关系)访问同一个内存空间,是多个进程之间共享和传递数据最高效的方式。
进程可以将共享内存连接到它们自己的地址空间中,如果某个进程修改了共享内存中的数据,其它的进程读到的数据也会改变。
共享内存没有提供锁机制,也就是说,在某一个进程对共享内存进行读/写的时候,不会阻止其它进程对它的读/写。如果要对共享内存的读/写加锁,可以使用信号量。
Linux中提供了一组函数用于操作共享内存。
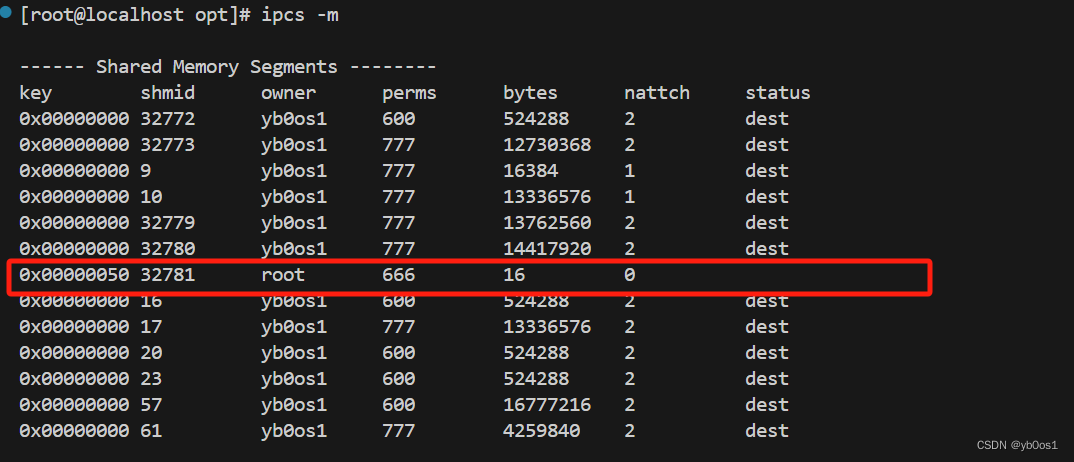
ipcs -m可以查看共享内存段
ipcrm -m 共享内存id 可以手工删除共享内存
shmget函数(创建/获取)
用于创建/获取共享内存
函数原型:
int shmget(key_t key, size_t size, int shmflg);
key:共享内存的键值,是一个无符号整数(typedef unsigned int key_t),一般采用十六进制,不同共享空间的key不相同size:共享内存的大小,以字节为单位(sizeof计算也可以)shmflg:共享内存的访问控制权限,与文件的权限一样,例如0666|IPC_CREAT。0666(八进制)表示全部用户对它可读写,IPC_CREAT表示如果不存在就创建- 返回值:成功返回共享内存的id,失败返回-1(系统内存不足、没有权限)
注意:共享内存不可是STL容器,只能是C++内置数据类型
#include<iostream>
#include<sys/shm.h>
using namespace std;
struct Person{
int age;
char name[20];
};
int main(){
int shmid = shmget(0x0050,sizeof(Person),0666|IPC_CREAT);
if(shmid==-1) {cout<<"shmget(0x5005) failed.\n"; return -1;}
cout<<"创建成功:"<<shmid<<"\n";
return 0;
}
shmat函数(连接)
该函数用于把共享内存连接到当前进程的地址空间
void *shmat(int shmid, const void *shmaddr, int shmflg);
- shmid:由shmget返回的共享内存的标识
- shmaddr:指定共享内存连接到当前进程中的地址位置,通常填0(让系统来选择共享内存的地址)
- shmflg:标志位,通常填0
- 调用成功时返回共享内存起始地址,失败返回(void*)-1
shmdt函数(分离)
该函数用于将共享内存从当前进程中分离,相当于shmat()函数的反操作
int shmdt(const void *shmaddr);
- shmaddr:shmat函数返回的地址
- 返回值:成功返回0,失败返回-1
#include<iostream>
#include<sys/shm.h>
using namespace std;
struct Person{//只允许是c++内置数据类型 不允许是STL容器
int age;
char name[20];
};
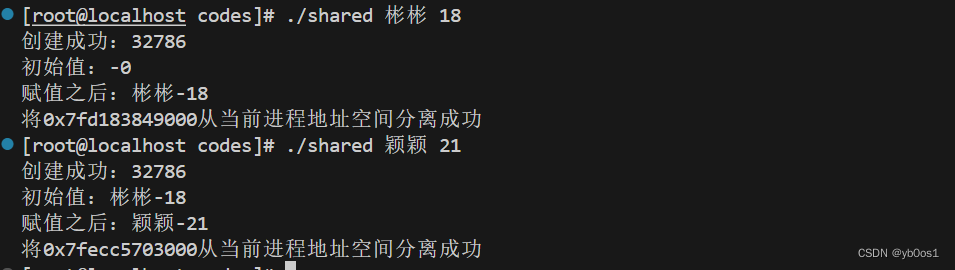
int main(int argc,char *argv[]){
if(argc!=3){
cout<<"输入不符合 请按以下形式: ./demo name age"<<endl;
return -1;
}
//创建or获取共享内存
int shmid = shmget(0x0050,sizeof(Person),0666|IPC_CREAT);
if(shmid==-1) {cout<<"shmget(0x5005) failed.\n"; return -1;}
cout<<"shmid="<<shmid<<"\n";
//连接到当前进程地址空间
Person*ptr = (Person*)shmat(shmid,0,0);//shmat返回的是void* 所以需要强制转化一下
cout<<"初始值:"<<ptr->name<<"-"<<ptr->age<<endl;
strcpy(ptr->name,argv[1]);
ptr->age = atoi(argv[2]);
cout<<"赋值之后:"<<ptr->name<<"-"<<ptr->age<<endl;
//从当前进程地址空间分离
int isDel = shmdt(ptr);
if(isDel!=-1)cout<<"将"<<ptr<<"从当前进程地址空间分离成功"<<endl;
return 0;
}
shmctl函数(删除)
该函数用于操作共享内存,最常用的操作是删除共享内存
int shmctl(int shmid, int command, struct shmid_ds *buf);
- shmid:shmget函数返回的共享内存的id
- command:操作共享内存的指令,删除填 IPC_RMID
- buf:操作共享内存的数据结构的地址,如果要删除共享内存填0
- 调用成功时返回0,失败时返回-1
注意:用root创建的共享内存,不管创建的权限是什么,普通用户无法删除
#include<iostream>
#include<sys/shm.h>
using namespace std;
struct Person{//只允许是c++内置数据类型 不允许是STL容器
int age;
char name[20];
};
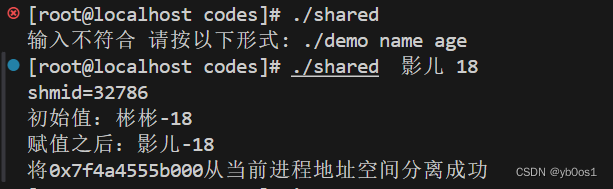
int main(int argc,char *argv[]){
if(argc!=3){
cout<<"输入不符合 请按以下形式: ./demo name age"<<endl;
return -1;
}
//创建or获取共享内存
int shmid = shmget(0x0050,sizeof(Person),0666|IPC_CREAT);
if(shmid==-1) {cout<<"shmget(0x5005) failed.\n"; return -1;}
cout<<"shmid="<<shmid<<"\n";
//连接到当前进程地址空间
Person*ptr = (Person*)shmat(shmid,0,0);//shmat返回的是void* 所以需要强制转化一下
if(ptr==(void*)-1){
cout<<"连接失败"<<endl;
return -1;
}
cout<<"初始值:"<<ptr->name<<"-"<<ptr->age<<endl;
strcpy(ptr->name,argv[1]);
ptr->age = atoi(argv[2]);
cout<<"赋值之后:"<<ptr->name<<"-"<<ptr->age<<endl;
//从当前进程地址空间分离
int isDel = shmdt(ptr);
if(isDel!=-1)cout<<"将"<<ptr<<"从当前进程地址空间分离成功"<<endl;
//删除共享内存
if(shmctl(shmid,IPC_RMID,0)==-1){
cout<<"删除失败"<<endl;
return -1;
}
return 0;
}
如果结构体使用了STL呢?
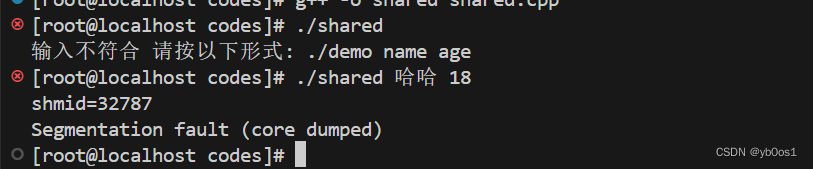
会出现段错误,为什么?
STL容器动态的分配堆区内存,堆区内存不属于共享内存
循环队列、信号量、生产/消费者模型的源代码
循环队列and普通使用
_public.h
#include<iostream>
#include<cstring>
template<typename T,int MaxLength>
class Squeue{
private:
bool is_inited;//是否已经初始化
int head;//头
int tail;//尾
T data[MaxLength];
int length;//实际长度
Squeue(const Squeue&)=delete;//禁用拷贝构造函数
Squeue operator=(const Squeue&)=delete;//禁用拷贝赋值函数
public:
Squeue(){
init();
}
void init(){
if(!is_inited){
head=0;
tail = MaxLength-1;
is_inited = true;
length=0;
memset(data,0,sizeof(data));
}
}
bool full(){
return length == MaxLength;
}
bool push(T m){
if(!full()){
tail = (tail+1)%MaxLength;
data[tail]=m;
++length;
return true;
}
std::cout<<"push failed!\n";
return false;
}
int size(){return length;}
bool empty(){return length==0;}
T&front(){return data[head];}//如果加上判断是否为空,当为空的时候没有返回
bool pop(){
if(!empty()){
head=(head+1)%MaxLength;
--length;
return true;
}
std::cout<<"pop failed!\n";
return false;
}
void print(){
for(int i=0;i<length;++i)
std::cout<<"data["<<(head+i)%MaxLength<<"]="<<data[(head+i)%MaxLength]<<"\n";
}
};
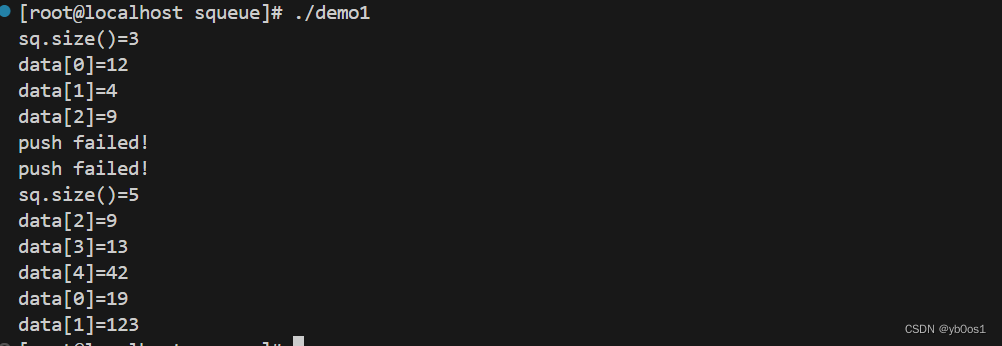
demo1.cpp
#include"_public.h"
using namespace std;
int main(){
Squeue<int,5>sq;
sq.push(12);sq.push(4);sq.push(9);
cout<<"sq.size()="<<sq.size()<<"\n";
sq.print();
sq.pop();sq.pop();
sq.push(13);sq.push(42);sq.push(19);sq.push(123);sq.push(2);sq.push(10);
cout<<"sq.size()="<<sq.size()<<"\n";
sq.print();
return 0;
}
循环队列and共享内存
_public.h
#include<iostream>
#include<cstring>
template<typename T,int MaxLength>
class Squeue{
private:
bool is_inited;//是否已经初始化
int head;//头
int tail;//尾
T data[MaxLength];
int length;//实际长度
Squeue(const Squeue&)=delete;//禁用拷贝构造函数
Squeue operator=(const Squeue&)=delete;//禁用拷贝赋值函数
public:
Squeue(){
init();
}
void init(){
if(!is_inited){
head=0;
tail = MaxLength-1;
is_inited = true;
length=0;
memset(data,0,sizeof(data));
}
}
bool full(){
return length == MaxLength;
}
bool push(T m){
if(!full()){
tail = (tail+1)%MaxLength;
data[tail]=m;
++length;
return true;
}
std::cout<<"push failed!\n";
return false;
}
int size(){return length;}
bool empty(){return length==0;}
T&front(){return data[head];}
bool pop(){
if(!empty()){
head=(head+1)%MaxLength;
--length;
return true;
}
std::cout<<"pop failed!\n";
return false;
}
void print(){
for(int i=0;i<length;++i)
std::cout<<"data["<<(head+i)%MaxLength<<"]="<<data[(head+i)%MaxLength]<<"\n";
}
};
demo2.cpp
#include"_public.h"
using namespace std;
int main(){
int shmid = shmget(0x0A5E,sizeof(Squeue<int,6>),0640|IPC_CREAT);
if(shmid==-1){
cout<<"shmget failed\n";
return -1;
}
Squeue<int,6>*QQ = (Squeue<int,6>*)shmat(shmid,0,0);
QQ->init();//不会自动调用构造函数 所以要init
if(QQ==(void*)-1){
cout<<"shmat failed!\n";
return -1;
}
QQ->push(12);
QQ->push(23);
QQ->push(99);
QQ->push(16);
cout<<"队列的长度:"<<QQ->size()<<endl;
QQ->print();
cout<<"队头元素:"<<QQ->front()<<endl;QQ->pop();
cout<<"队头元素:"<<QQ->front()<<endl;QQ->pop();
QQ->push(61);
QQ->push(78);
QQ->push(8);
QQ->push(6);
QQ->push(112);
QQ->push(65);
cout<<"队列的长度:"<<QQ->size()<<endl;
QQ->print();
cout<<QQ->empty()<<endl;
shmdt(QQ);
return 0;
}
信号量and共享内存
信号量可以实现进程同步,本质是一个非负数的计数器,用于给共享内存资源建立一个标识,表示该共享资源被占用情况
两种操作
- P操作(wait):将信号量值-1,如果信号量的值为0,将阻塞等待,直到信号量的值大于0
- V操作(post):将信号量值+1,任何时候都不会阻塞
应用
- 如果约定信号量的取值只有0或者1(0-资源不可用,1-资源可用),可以实现互斥锁
- 如果约定信号量的取值表示可用资源的数量,可以实现生产/消费者模型
_public.h
#ifndef _PUBLIC
#define _PUBLIC
#include<iostream>
#include<cstring>
#include <unistd.h>
#include<sys/shm.h>
#include<sys/sem.h>
#include<sys/types.h>
#include<sys/ipc.h>
template<typename T,int MaxLength>
class Squeue{
private:
bool is_inited;//是否已经初始化
int head;//头
int tail;//尾
T data[MaxLength];
int length;//实际长度
Squeue(const Squeue&)=delete;//禁用拷贝构造函数
Squeue operator=(const Squeue&)=delete;//禁用拷贝赋值函数
public:
Squeue(){
init();
}
void init(){
if(!is_inited){
head=0;
tail = MaxLength-1;
is_inited = true;
length=0;
memset(data,0,sizeof(data));
}
}
bool full(){
return length == MaxLength;
}
bool push(T m){
if(!full()){
tail = (tail+1)%MaxLength;
data[tail]=m;
++length;
return true;
}
std::cout<<"push failed!\n";
return false;
}
int size(){return length;}
bool empty(){return (length==0);}
T& front(){
return data[head];
}
bool pop(){
if(!empty()){
head=(head+1)%MaxLength;
--length;
return true;
}
std::cout<<"pop failed!\n";
return false;
}
void print(){
for(int i=0;i<length;++i)
std::cout<<"data["<<(head+i)%MaxLength<<"]="<<data[(head+i)%MaxLength]<<"\n";
}
};
class csemp{
private:
union semun{
int val;
struct semid_ds *buf;
unsigned short *arry;
};
int semid;//信号量id(描述符) 未初始化为-1 初始化之后为返回的id
/*
sem_flg设置为SEM_UNDO,操作系统将跟踪进程对信号量的修改情况,
在全部修改信号量的进程(正常或异常)终止后,操作系统将把信号量恢复为初始值。
sem_flg设置为0,操作系统不会把信号量恢复为初始值
1、如果用于互斥锁,sem_flg设置为SEM_UNDO,也就是全部进程终止后,操作系统将锁设置为解锁状态
2、如果用于生产/消费者模型,sem_flg设置为0,
*/
short sem_flg;
csemp(const csemp&)=delete;
csemp& operator=(const csemp&)=delete;
public:
csemp():semid(-1){}
/*
初始化:
如果信号量已经存在,获取
如果信号量不存在,创建,并且初始化为value
用于互斥锁:value=1,sem_flg=SEM_UNDO
用于生产/消费者模型:value=0,SEM_UNDO=0
key:信号量的标识符(唯一)
value:值
sem_flg_y:
*/
bool init(key_t key,unsigned short value=1,short sem_flg_y=SEM_UNDO);
bool wait(short value=-1);//P操作 -1 如果信号量的值是0,将阻塞等待,直到信号量的值大于0
bool post(short value=1);//V操作 +1
int getValue();//获取信号量的值,成功返回信号量 失败返回-1
bool destroy();//销毁信号量
~csemp()=default;
};
#endif
_public.cpp
#include"_public.h"
// 如果信号量已存在,获取信号量;如果信号量不存在,则创建它并初始化为value。
// 如果用于互斥锁,value填1,sem_flg填SEM_UNDO。default
// 如果用于生产消费者模型,value填0,sem_flg填0。
bool csemp::init(key_t key,unsigned short value,short sem_flg_y){
if(semid != -1)return false;//已经初始化
sem_flg = sem_flg_y;
// 信号量的初始化不能直接用semget(key,1,0666|IPC_CREAT)
// 因为信号量创建后,初始值是0,如果用于互斥锁,需要把它的初始值设置为1,
// 而获取信号量则不需要设置初始值,所以,创建信号量和获取信号量的流程不同。
// 信号量的初始化分三个步骤:
// 1)获取信号量,如果成功,函数返回。
// 2)如果失败,则创建信号量。
// 3) 设置信号量的初始值。
//获取信号量
if((semid = semget(key,1,0640)) == -1){
//信号量不存在
if(errno == ENOENT){
//创建信号量:用IPC_EXCL标志确保只有一个进程创建并初始化信号量,其它进程只能获取
if((semid=semget(key,1,0640|IPC_CREAT|IPC_EXCL))==-1){
//创建信号量失败,也就是已经存在信号量 再次获取信号量
/*
为什么上面已经判断信号量不存在这里还可能存在?
多进程,存在多个进程同时进入获取的信号量不存在,但是只有一个创建,创建之后就存在了
*/
if(errno==EEXIST){
if((semid=semget(key,1,0640))==-1){//获取失败
perror("init 1 semget()");
return false;
}
return true;
}else{// 如果是其它错误,返回失败
perror("init 2 semget()");
return false;
}
}
// 信号量创建成功后,还需要把它初始化成value
union semun sem_union;
sem_union.val = value;
if(semctl(semid,0,SETVAL,sem_union)<0){
perror("init semctl");
return false;
}
}else{//其他错误(不是信号量不存在的错误)
perror("init 3 semget");
return false;
}
}
return true;//获取成功直接返回true
}
// 信号量的P操作(把信号量的值减value),如果信号量的值是0,将阻塞等待,直到信号量的值大于0
bool csemp::wait(short value){
if(semid==-1)return false;//未初始化 不可操作
struct sembuf sem_b={0,value,sem_flg};//和以下等价
/*
sem_b.sem_num = 0;//信号量编码 0代表第一个信号
sem_b.sem_op = value; //p操作的value必须小于0
sem_b.sem_flg = sem_flg;
*/
if(semop(semid,&sem_b,1)==-1){//semop进行PV操作 是P还是V看v sembuf的value
perror("P semop()");
return false;
}
return true;
}
// 信号量的V操作(把信号量的值加value)。
bool csemp::post(short value){
if(semid==-1)return false;
struct sembuf sem_b={0,value,sem_flg};//和以下等价
/*
sem_b.sem_num = 0;//信号量编码 0代表第一个信号
sem_b.sem_op = value; //p操作的value必须小于0
sem_b.sem_flg = sem_flg;
*/
if(semop(semid,&sem_b,1)==-1){
perror("V semop()");
return false;
}
return true;
}
int csemp::getValue(){
return semctl(semid,0,GETVAL);
}
bool csemp::destroy(){
if(semid==-1)return false;
if(semctl(semid,0,IPC_RMID)==-1){
perror("destroy semctl()");
return false;
}
return true;
}
demo3.cpp
#include"_public.h"
using namespace std;
struct stgirl{
int id; // 编号。
char name[51]; // 姓名,注意,不能用string。
};
int main(int argc,char*argv[]){
if(argc!=3){
cout<<"using ./demo id name\n";
return -1;
}
int shmid = shmget(0x0500,sizeof(stgirl),0640|IPC_CREAT);
if(shmid==-1){
cout << "shmget(0x5005) failed.\n";
return -1;
}
stgirl*gl = (stgirl*)shmat(shmid,0,0);
if(gl==(void*)-1){
cout<<"shmat() failed\n";
return -1;
}
csemp mutex;
if(mutex.init(0x0500)==-1){
cout<<"csemp init failed\n";
return -1;
}
// 查看信号量 :ipcs -s // 删除信号量 :ipcrm sem 信号量id
// 查看共享内存:ipcs -m // 删除共享内存:ipcrm -m 共享内存id
cout<<"lock...\n";
mutex.wait();
cout<<"old::id="<<gl->id<<",name="<<gl->name<<endl;
gl->id = atoi(argv[1]);
strcpy(gl->name,argv[2]);
cout<<"new::id="<<gl->id<<",name="<<gl->name<<endl;
sleep(10);
mutex.post();
cout<<"unlock...\n";
shmdt(gl);
// mutex.destroy();
// if(shmctl(shmid,IPC_RMID,0)==-1){
// cout << "shmctl failed\n";
// return -1;
// }
return 0;
}
生产消费者模型(重难点)
生产者
//生产者
#include"_public.h"
using namespace std;
using Elem = Person;
int main(){
// 初始化共享内存
int shmid = shmget(0x0555,sizeof(Squeue<Elem,5>),0640|IPC_CREAT);
if(shmid==-1){
cout<<"shmget failed!\n";
return -1;
}
// 把共享内存连接到当前进程的地址空间
Squeue<Elem,5>*QQ = (Squeue<Elem,5>*)shmat(shmid,0,0);
if(QQ==(void*)-1){
cout<<"shmat failed!\n";
return -1;
}
QQ->init();// 初始化循环队列
Elem e; // 创建一个数据元素
csemp mutex;mutex.init(0x0501);// 用于给共享内存加锁
csemp cond;cond.init(0x0502,0,0);// 信号量的值用于表示队列中数据元素的个数
mutex.wait();//上锁
e.age=18;e.sex='M';strcpy(e.name,"彬彬");QQ->push(e);
e.age=28;e.sex='W';strcpy(e.name,"西施");QQ->push(e);
e.age=24;e.sex='W';strcpy(e.name,"貂蝉");QQ->push(e);
mutex.post();//解锁
cond.post(3);//实参是3,表示生产了3个数据
shmdt(QQ);// // 把共享内存从当前进程中分离
return 0;
}
消费者
//消费者
#include"_public.h"
using namespace std;
using Elem = Person;
int main(){
// 获取共享内存
int shmid = shmget(0x0555,sizeof(Squeue<Elem,5>),0640|IPC_CREAT);
if(shmid==-1){
cout<<"shmget failed!\n";
return -1;
}
// 把共享内存连接到当前进程的地址空间
Squeue<Elem,5>*QQ = (Squeue<Elem,5>*)shmat(shmid,0,0);
if(QQ==(void*)-1){
cout<<"shmat failed!\n";
return -1;
}
QQ->init();// 初始化循环队列
Elem e; // 创建一个数据元素
csemp mutex;mutex.init(0x0501);// 用于给共享内存加锁
csemp cond;cond.init(0x0502,0,0);// 信号量的值用于表示队列中数据元素的个数
while(true){
mutex.wait();//加锁
while(QQ->empty()){
mutex.post();//解锁
cond.wait();// 等待生产者的唤醒信号 QQ是空就是代表cond的信号量为0 为0P操作则等待
mutex.wait();
}
// 数据出队
e = QQ->front();QQ->pop();
mutex.post(); // 解锁
cout <<"name="<< e.name<<",age=" << e.age << ",sex=" << ((e.sex=='M')?"男":"女")<<endl;
sleep(1);
}
shmdt(QQ);
}
_public.h
#ifndef _PUBLIC
#define _PUBLIC
#include<iostream>
#include<cstring>
#include <unistd.h>
#include<sys/shm.h>
#include<sys/sem.h>
#include<sys/types.h>
#include<sys/ipc.h>
struct Person{
int age;
char sex;
char name[51];
};
template<typename T,int MaxLength>
class Squeue{
private:
bool is_inited;//是否已经初始化
int head;//头
int tail;//尾
T data[MaxLength];
int length;//实际长度
Squeue(const Squeue&)=delete;//禁用拷贝构造函数
Squeue operator=(const Squeue&)=delete;//禁用拷贝赋值函数
public:
Squeue(){
init();
}
void init(){
if(!is_inited){
head=0;
tail = MaxLength-1;
is_inited = true;
length=0;
memset(data,0,sizeof(data));
}
}
bool full(){
return length == MaxLength;
}
bool push(T m){
if(!full()){
tail = (tail+1)%MaxLength;
data[tail]=m;
++length;
return true;
}
std::cout<<"push failed!\n";
return false;
}
int size(){return length;}
bool empty(){return (length==0);}
T& front(){
return data[head];
}
bool pop(){
if(!empty()){
head=(head+1)%MaxLength;
--length;
return true;
}
std::cout<<"pop failed!\n";
return false;
}
void print(){
for(int i=0;i<length;++i)
std::cout<<"data["<<(head+i)%MaxLength<<"]="<<data[(head+i)%MaxLength]<<"\n";
}
};
class csemp{
private:
union semun{
int val;
struct semid_ds *buf;
unsigned short *arry;
};
int semid;//信号量id(描述符) 未初始化为-1 初始化之后为返回的id
/*
sem_flg设置为SEM_UNDO,操作系统将跟踪进程对信号量的修改情况,
在全部修改信号量的进程(正常或异常)终止后,操作系统将把信号量恢复为初始值。
sem_flg设置为0,操作系统不会把信号量恢复为初始值
1、如果用于互斥锁,sem_flg设置为SEM_UNDO,也就是全部进程终止后,操作系统将锁设置为解锁状态
2、如果用于生产/消费者模型,sem_flg设置为0,
*/
short sem_flg;
csemp(const csemp&)=delete;
csemp& operator=(const csemp&)=delete;
public:
csemp():semid(-1){}
/*
初始化:
如果信号量已经存在,获取
如果信号量不存在,创建,并且初始化为value
用于互斥锁:value=1,sem_flg=SEM_UNDO
用于生产/消费者模型:value=0,SEM_UNDO=0
key:信号量的标识符(唯一)
value:值
sem_flg_y:
*/
bool init(key_t key,unsigned short value=1,short sem_flg_y=SEM_UNDO);
bool wait(short value=-1);//P操作 -1 如果信号量的值是0,将阻塞等待,直到信号量的值大于0
bool post(short value=1);//V操作 +1
int getValue();//获取信号量的值,成功返回信号量 失败返回-1
bool destroy();//销毁信号量
~csemp()=default;
};
#endif
_public.cpp
#include"_public.h"
// 如果信号量已存在,获取信号量;如果信号量不存在,则创建它并初始化为value。
// 如果用于互斥锁,value填1,sem_flg填SEM_UNDO。default
// 如果用于生产消费者模型,value填0,sem_flg填0。
bool csemp::init(key_t key,unsigned short value,short sem_flg_y){
if(semid != -1)return false;//已经初始化
sem_flg = sem_flg_y;
// 信号量的初始化不能直接用semget(key,1,0666|IPC_CREAT)
// 因为信号量创建后,初始值是0,如果用于互斥锁,需要把它的初始值设置为1,
// 而获取信号量则不需要设置初始值,所以,创建信号量和获取信号量的流程不同。
// 信号量的初始化分三个步骤:
// 1)获取信号量,如果成功,函数返回。
// 2)如果失败,则创建信号量。
// 3) 设置信号量的初始值。
//获取信号量
if((semid = semget(key,1,0640)) == -1){
//信号量不存在
if(errno == ENOENT){
//创建信号量:用IPC_EXCL标志确保只有一个进程创建并初始化信号量,其它进程只能获取
if((semid=semget(key,1,0640|IPC_CREAT|IPC_EXCL))==-1){
//创建信号量失败,也就是已经存在信号量 再次获取信号量
/*
为什么上面已经判断信号量不存在这里还可能存在?
上面两个操作不是原子操作
多进程,存在多个进程同时进入获取的信号量不存在,但是只有一个创建,创建之后就存在了
*/
if(errno==EEXIST){
if((semid=semget(key,1,0640))==-1){//获取失败
perror("init 1 semget()");
return false;
}
return true;
}else{// 如果是其它错误,返回失败
perror("init 2 semget()");
return false;
}
}
// 信号量创建成功后,还需要把它初始化成value
union semun sem_union;
sem_union.val = value;
if(semctl(semid,0,SETVAL,sem_union)<0){
perror("init semctl");
return false;
}
}else{//其他错误(不是信号量不存在的错误)
perror("init 3 semget");
return false;
}
}
return true;//获取成功直接返回true
}
// 信号量的P操作(把信号量的值减value),如果信号量的值是0,将阻塞等待,直到信号量的值大于0
bool csemp::wait(short value){
if(semid==-1)return false;//未初始化 不可操作
struct sembuf sem_b={0,value,sem_flg};//和以下等价
/*
sem_b.sem_num = 0;//信号量编码 0代表第一个信号
sem_b.sem_op = value; //p操作的value必须小于0
sem_b.sem_flg = sem_flg;
*/
if(semop(semid,&sem_b,1)==-1){//semop进行PV操作 是P还是V看v sembuf的value
perror("P semop()");
return false;
}
return true;
}
// 信号量的V操作(把信号量的值加value)。
bool csemp::post(short value){
if(semid==-1)return false;
struct sembuf sem_b={0,value,sem_flg};//和以下等价
/*
sem_b.sem_num = 0;//信号量编码 0代表第一个信号
sem_b.sem_op = value; //p操作的value必须小于0
sem_b.sem_flg = sem_flg;
*/
if(semop(semid,&sem_b,1)==-1){
perror("V semop()");
return false;
}
return true;
}
int csemp::getValue(){
return semctl(semid,0,GETVAL);
}
bool csemp::destroy(){
if(semid==-1)return false;
if(semctl(semid,0,IPC_RMID)==-1){
perror("destroy semctl()");
return false;
}
return true;
}
线程
后续更新分p
后续补充
















 2254
2254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









