







 本文介绍了如何使用Python爬取Bilibili视频。通过分析网页链接,找到视频序号参数next_offset,并处理反爬虫策略,获取headers信息。利用requests库获取视频数据,实现视频下载。并提供了一个简单的下载器示例。
本文介绍了如何使用Python爬取Bilibili视频。通过分析网页链接,找到视频序号参数next_offset,并处理反爬虫策略,获取headers信息。利用requests库获取视频数据,实现视频下载。并提供了一个简单的下载器示例。
B 站视频网址:
https://vc.bilibili.com/p/eden/rank#/?tab=全部 
通过 F12 打开开发者模式,然后在 Networking -> Name 字段下找到这个链接:
http://api.vc.bilibili.com/board/v1/ranking/top?page_size=10&next_offset=&tag=%E4%BB%8A%E6%97%A5%E7%83%AD%E9%97%A8&platform=pc 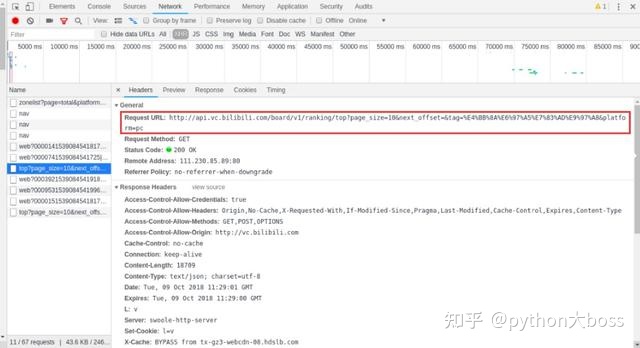 next_offset 会一直变化,我们可以猜测,这个可能就是获取下一个视频序号,我们只需要把这部分参数取出来,把 next_offset 写成变量值,用 JSON 的格式返回到目标网页即可。
next_offset 会一直变化,我们可以猜测,这个可能就是获取下一个视频序号,我们只需要把这部分参数取出来,把 next_offset 写成变量值,用 JSON 的格式返回到目标网页即可。
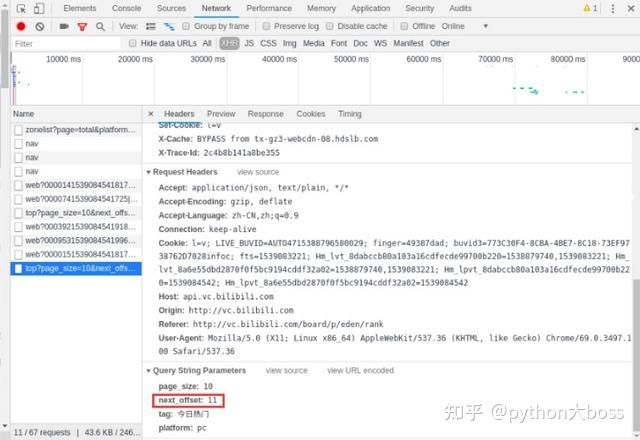 我们通过上面的尝试写了段代码,发现 B 站在一定程度上做了反爬虫操作,所以我们需要先获取 headers 信息,否则下载下来的视频是空的,然后定义 params 参数存储 JSON 数据,然后通过 requests.get 去获取其参数值信息,用 JSON 的格式返回到目标网页即可&
我们通过上面的尝试写了段代码,发现 B 站在一定程度上做了反爬虫操作,所以我们需要先获取 headers 信息,否则下载下来的视频是空的,然后定义 params 参数存储 JSON 数据,然后通过 requests.get 去获取其参数值信息,用 JSON 的格式返回到目标网页即可&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3707
3707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









