







 系列文章天池NLP赛事-新闻文本分类(一) —— 赛题理解天池NLP赛事-新闻文本分类(二) —— 数据读取和数据分析天池NLP赛事-新闻文本分类(三)——基于机器学习的文本分类天池NLP赛事-新闻文本分类(四)——基于深度学习的文本分类1-FastText目录四、基于深度学习的文本分类1-FastText4.1 文本表示方法——FastText4.2 基于FastText的文本分类4.3 如何使用验证集调参四、基于深度学习的文本分类1-FastText4.1 文本表示方法——FastTe.
系列文章天池NLP赛事-新闻文本分类(一) —— 赛题理解天池NLP赛事-新闻文本分类(二) —— 数据读取和数据分析天池NLP赛事-新闻文本分类(三)——基于机器学习的文本分类天池NLP赛事-新闻文本分类(四)——基于深度学习的文本分类1-FastText目录四、基于深度学习的文本分类1-FastText4.1 文本表示方法——FastText4.2 基于FastText的文本分类4.3 如何使用验证集调参四、基于深度学习的文本分类1-FastText4.1 文本表示方法——FastTe.
系列文章
天池NLP赛事-新闻文本分类(一) —— 赛题理解
天池NLP赛事-新闻文本分类(二) —— 数据读取和数据分析
天池NLP赛事-新闻文本分类(三)——基于机器学习的文本分类
天池NLP赛事-新闻文本分类(四)——基于深度学习的文本分类1-FastText
四、基于深度学习的文本分类1-FastText
4.1 文本表示方法——FastText
上一章中,我们介绍了几种文本表示方法:One-hot,Bag of Words,N-gram,TF-IDF
上述表示方法的缺陷:转换得到的向量维度很高,需要较长的训练时间;没有考虑单词与单词之间的关系,只是进行了统计。
与这些表示方法不同,深度学习也可以用于文本表示,还可以将其映射到一个低维空间。其中比较典型的例子有:FastText、Word2Vec和Bert。在本章我们将介绍FastText,将在后面的内容介绍Word2Vec和Bert。
FastText
可以参考:https://blog.csdn.net/feilong_csdn/article/details/88655927
FastText是一种典型的深度学习词向量的表示方法,它非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。
所以FastText是一个三层的神经网络,输入层、隐含层和输出层。
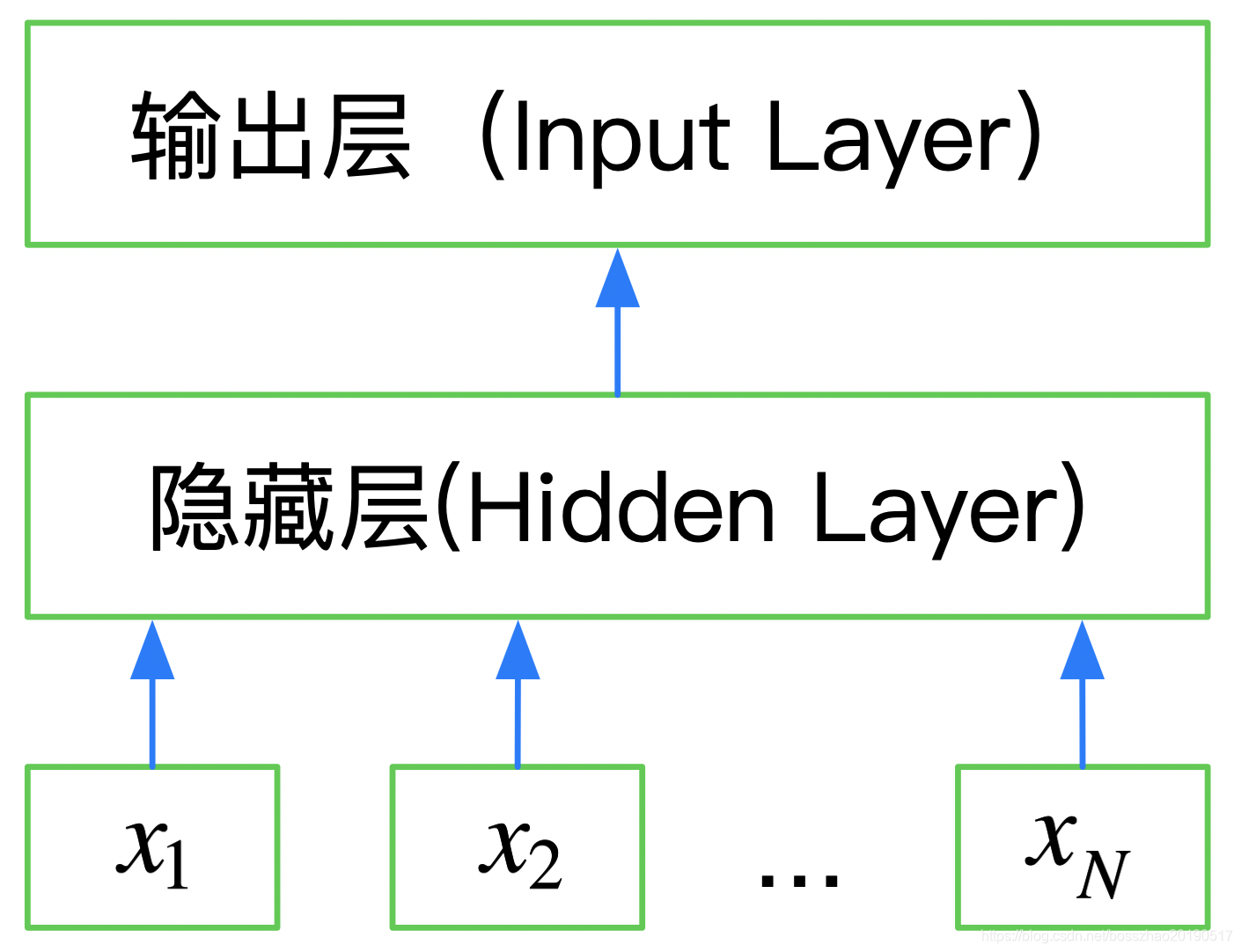
下图是使用keras实现的FastText网络结构:
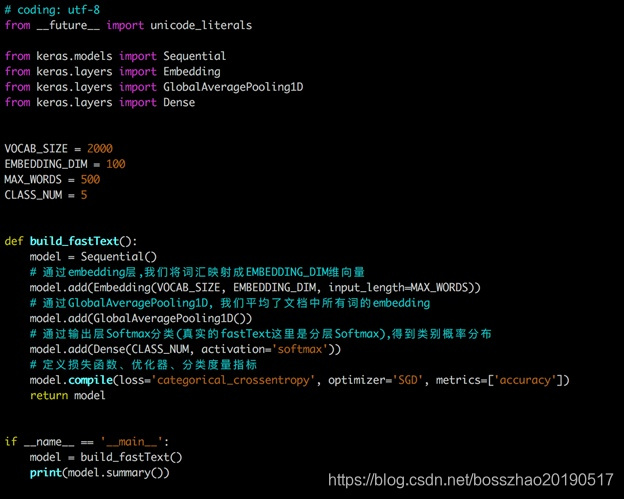
FastText在文本分类任务上,是优于TF-IDF的:
- FastText用单词的Embedding叠加获得的文档向量,将相似的句子分为一类
- FastText学习到的Embedding空间维度比较低,可以快速进行训练
4.2 基于FastText的文本分类
pip安装
pip install fasttext
Note:这里安装的时候,这个小错误没有管用着也没什么问题
import pandas as pd
from sklearn.metrics import f1_score
# 转换为FastText需要的格式
train_df = pd.read_csv('../input/train_set.csv', sep='\t', nrows=15000)
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text'< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









