







初学者入门Python基础六
`
文章目录
前言
本篇内容分享的是Python基础中的字符串相关的知识点,字符串的驻留机制、查询、大小写转换、劈分等操作会以具体的demo进行演示。
提示:以下是本篇文章正文内容,下面案例可供参考
一、字符串的驻留机制
驻留机制的几种情况:
1)字符串的长度为0或 时
2)符合标识符的字符串
3)字符串只在编译时进行驻留,而非运行时
4)【-5,256】之间的整数数字
sys中的intern方法强制2个字符串指向同一个对象
pycharm对字符串进行了优化处理
字符串驻留机制的优缺点:
1)当需要值相同的字符串时,可以直接从字符串池里拿出来,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的
2)在需要进行字符串拼接时建议使用str类型和join方法,而非+,因为join()方法在计算出所有字符中的长度,然后在拷贝,只New一次对象,效率要比+效率高
'''字符串的驻留机制'''
a = 'python'
b = "python"
c = '''python'''
print(a,id(a))
print(b,id(b))
print(c,id(c))
print(c,id(c))

二、字符串的基本操作
2.1字符串的查询

s = 'hello,hello'
print(s.index('lo')) #3
print(s.find('lo')) #3
print(s.rindex('lo')) #9
print(s.rfind(('lo'))) #9
#print(s.index('k')) #不存在报错
#print(s.rindex('k') #不存在报错
print(s.find('k')) #不存在 -1
print(s.rfind('k')) #不存在 -1

2.2 字符串的大小写转换
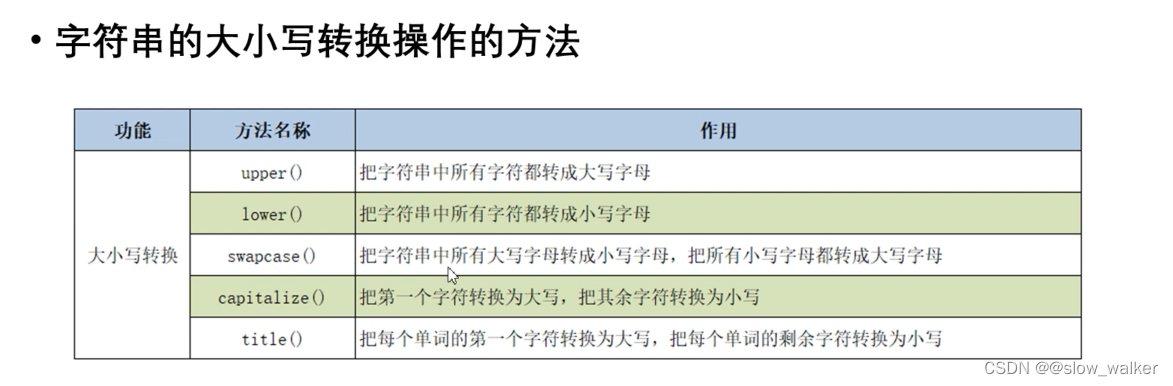
'''字符串中的大小写转换'''
s = 'hello,python'
s2 = s.upper()
print(s,id(s))
print(s2,id(s2)) #转成大写之后会产生一个新的字符串对象
print(s.lower(),id(s.lower())) #转换之后会产生一个新的字符串对象
print(s,id(s))
s3 = 'Hello,Python'
print(s3.swapcase()) #大写变小写 小写变大写
print(s3.capitalize()) #把第一个字符转换为大写,其余字符为小写
print(s3.title()) #把第一个单词的第一个字符转换成大写,把每个单词剩余的转换为小写

2.3 字符串对齐

s = 'hello,python'
#居中对齐
print(s.center(20,'*'))
#左对齐
print(s.ljust(20,'*'))
print(s.ljust(10))
print(s.ljust(20))
#右对齐
print(s.rjust(20,'*'))
print(s.rjust(10))
print(s.rjust((20)))
#右对齐 使用0 进行填充
print(s.zfill(20))
print(s.zfill(10))

2.4 字符串劈分
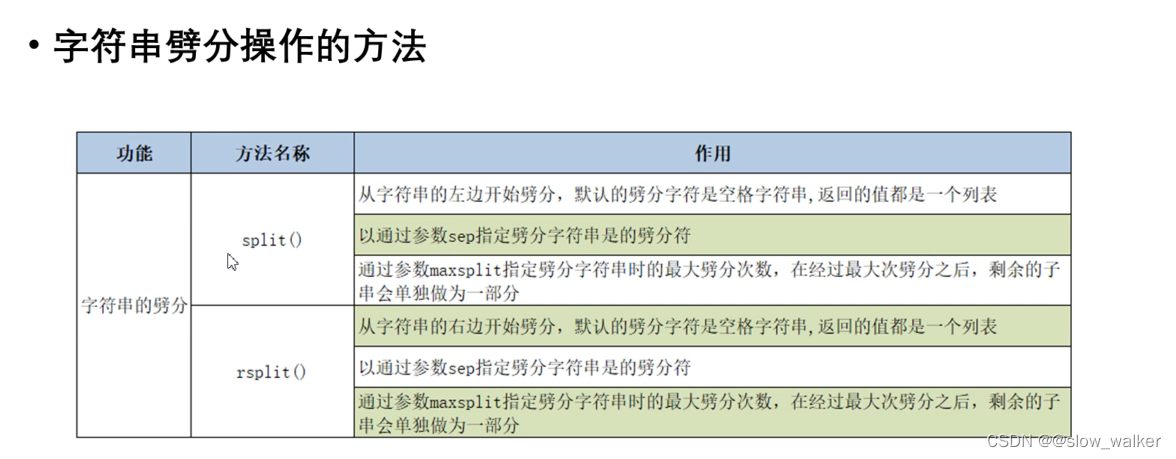
split 劈分 从左侧开始返回时列表
s = 'hello world python'
lst = s.split()
print(lst)
s1 = 'hello|world|python'
print(s1.split(sep= '|'))
print(s1.split(sep='|',maxsplit=1))
print('--------------------rsplit----------------------')
#从右侧开始进行劈分
print(s.rsplit()) #默认以空格进行分割
print(s1.rsplit('|'))
print(s1.rsplit(sep='|',maxsplit=1))

2.5 字符串的判断
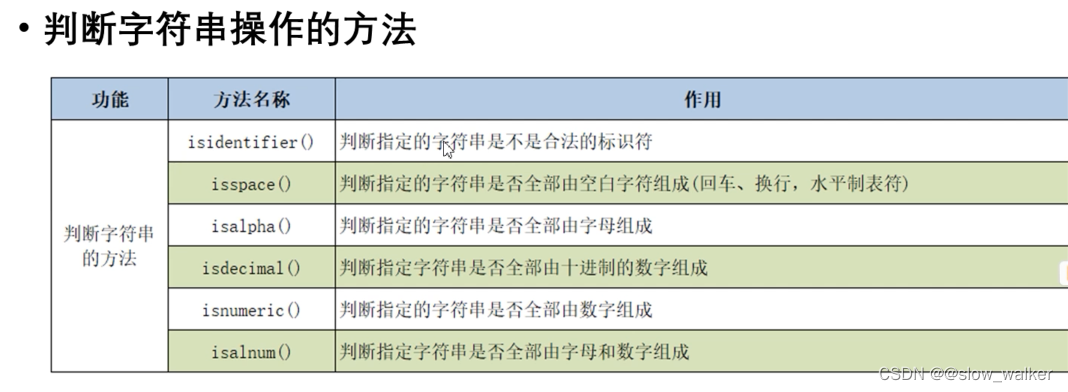
s = 'hello,python'
print('1.',s.isidentifier()) #False
print('2.','hello'.isidentifier()) #True
print('3.','张三_'.isidentifier()) #True
print('4.','张三_123'.isidentifier()) #True
print('5','\t'.isspace()) #True
print('6.','abc'.isalpha()) #True
print('7','张三'.isalpha()) #True
print('8','张三1'.isalpha()) #False
print('9','123'.isdecimal()) #True
print('10','123四'.isdecimal()) #False
print('11','123'.isnumeric()) #True
print('12','123四'.isnumeric()) #True
print('13','abc1'.isalnum()) #True
print('14','张三123'.isalnum()) #True
print('15','张三123!%'.isalnum()) #False

2.6 == 和 is的区别
'''== 与 is 的区别
== 比较的值
is 比较的Id
'''
a = b = 'hello'
c = 'hello'
print(a == b)
print(a == c)
print(a is b)
print(a is c)
print(id(a))
print(id(b))
print(id(c))

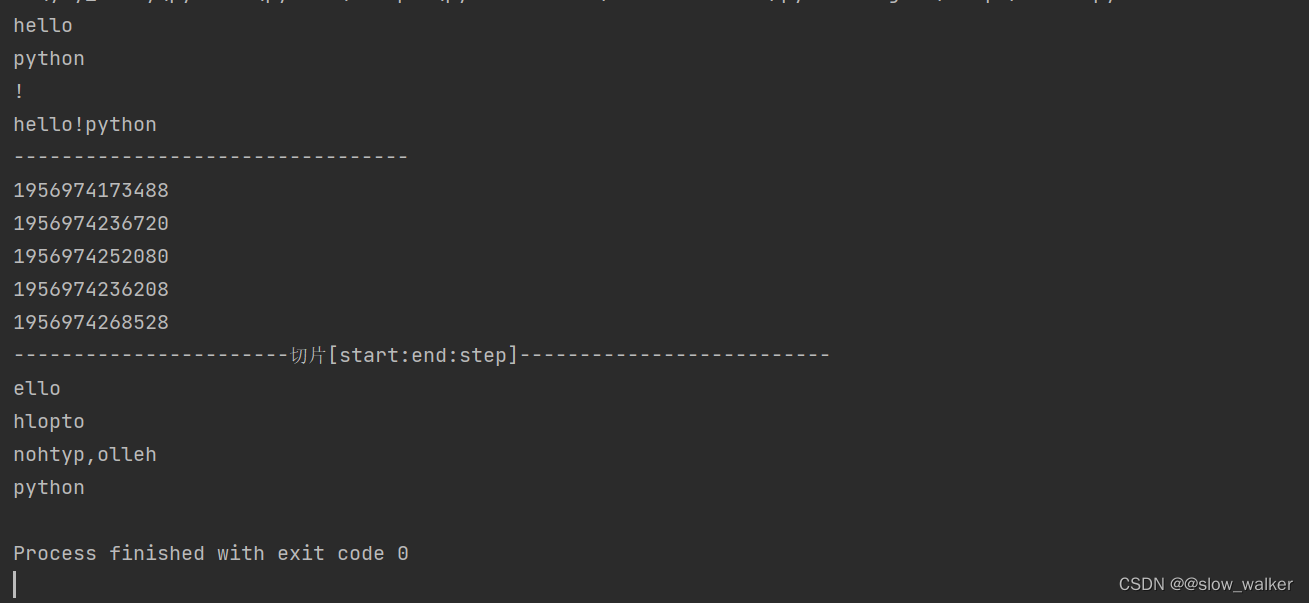
2.7字符串的切片操作
'''字符串的切片操作'''
s = 'hello,python'
s1 = s[:5] #没有指定起始位置 从0开始
s2 = s[6:] #没有指定结束位置 到结束最后一个字符
s3 = '!'
new_s = s1 + s3 + s2
print(s1)
print(s2)
print(s3)
print(new_s)
print('---------------------------------')
print(id(s))
print(id(s1))
print(id(s2))
print(id(s3))
print(id(new_s))
print('-----------------------切片[start:end:step]--------------------------')
print(s[1:5:1]) #从1开始到5(不包含5) 步长为1
print(s[::2]) #默认从0开始没有写结束默认到字符串末尾 步长为2 两个相连元素之间隔2
print(s[::-1]) #默认从字符串的最后一个开始 到字符串第一个结束因为步长为负数
print(s[-6::1]) #从-6开始到字符串最后一个结束 步长为1
2.8字符串的格式化
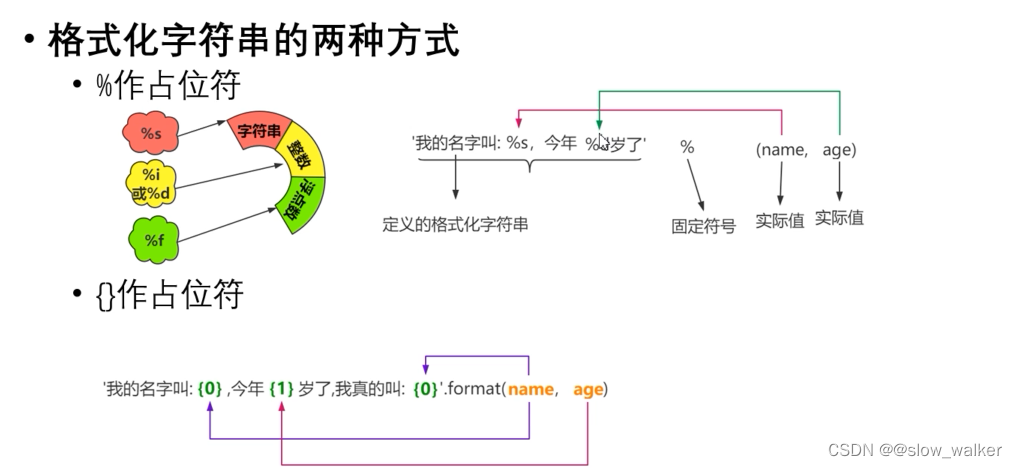
'''格式化字符串'''
#(1)使用%占位符
name = '张三'
age = 20
print('我叫%s,今年%d岁' % (name,age))
#(2) {}
print('我叫{0},今年{1}岁'.format (name,age))
#(3)f-string
print(f'我加{name},今年{age}岁')
print('----------------------------------------------')
print('%10d' % 99) #10表示的宽度
print('hellohello')
print('%.3f' % 3.1415926) #保留三位小数
#同时表示宽度和精度
print('%4.3f' % 3.1415926)
print('----------------------------------------------')
print('{0:.3}'.format((3.1415926))) #.3一共是三位数
print('{0:.3f}'.format((3.1415926))) #.3f一共是三位小数
print('{:4.3f}'.format((3.1415926))) #同时设置宽度和精度 ,宽度是4 小数是3位
2.9 字符串的编码转换
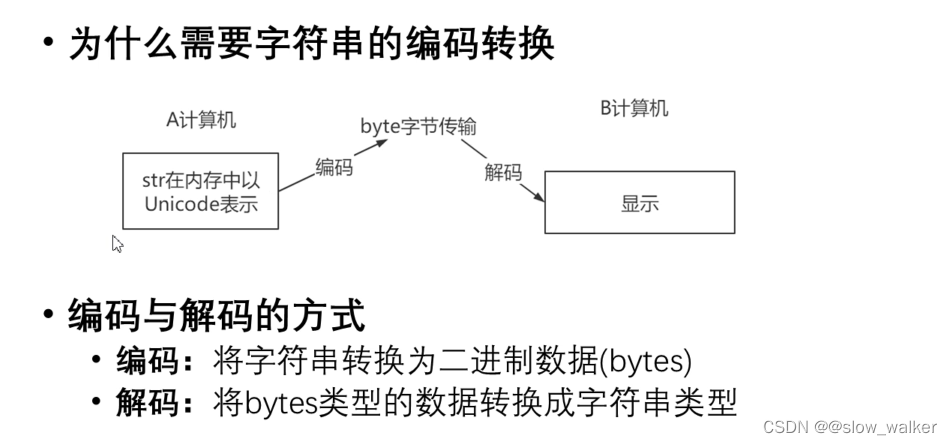
'''---------------------字符串的编码转换--------------------------'''
#编码
s = '天涯共此时'
print(s.encode(encoding='GBK')) #在GBK这种编码格式中 一个中文占两个字节
print(s.encode(encoding='UTF-8')) #在UTF-8 编码格式中 一个中文占三个字节
#解码
#编码和解码方式要一致
#byte代表就是一个二进制数据(字节类型的数据)
byte = s.encode(encoding='GBK') #编码
print(byte.decode(encoding = 'GBK')) #解码
byte = s.encode(encoding='UTF-8') #编码
print(byte.decode(encoding='UTF-8')) #解码

以上就是本次Python的基础分享字符串的操作















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











