









深度学习方法采用多个处理层来学习数据的层次表示,并在许多领域中产生了最先进的结果。最近,在自然语言处理(NLP)的背景下,各种模型设计和方法蓬勃发展。本文总结了已经用于大量NLP任务的重要深度学习相关模型和方法,并回顾其演变过程。我们还给出了对各种模型的总结、比较和对比,以及对NLP深度学习的过去、现在和未来的透彻理解。
I. 绪论
自然语言处理(NLP)是一种理论驱动的计算技术,用于人类语言的自动分析和表示。NLP研究从纸带穿孔和批处理的时代演变而来,当时句子分析可能需要长达7分钟。到谷歌及类似应用的时代,数百万个网页可以不到一秒就处理完成了[1]。NLP使计算机能够在各个层面执行各种与自然语言相关的任务,从句法分析和词性(POS)标注到机器翻译和对话系统。
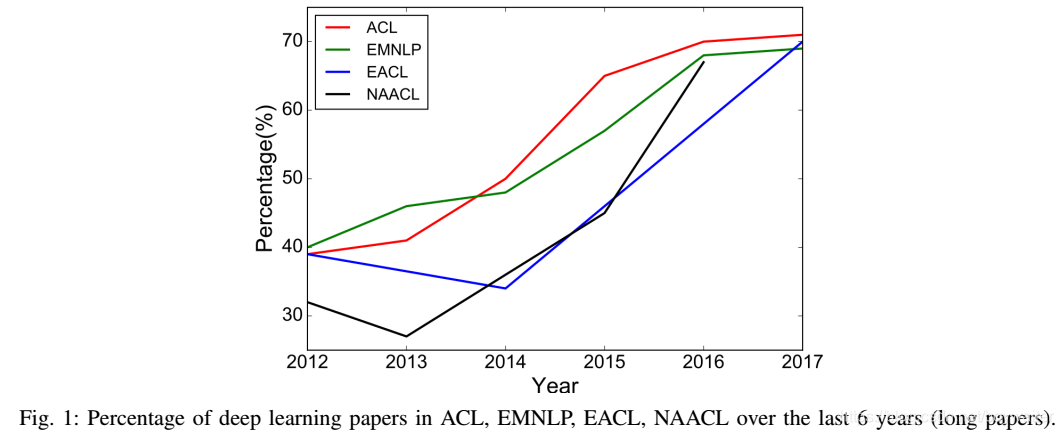
深度学习架构和算法已经在计算机视觉和模式识别等领域取得了令人瞩目的进步。沿着这一趋势,最近NLP研究越来越关注使用新的深度学习方法(见图1)。几十年来,针对NLP问题的机器学习方法,一直基于在非常高维度和稀疏特征上训练的浅模型(例如,SVM和逻辑回归)。过去几年中,基于稠密向量表示的神经网络已经在各种NLP任务上产生了优异的结果。这种趋势是由词嵌入[2,3]和深度学习方法[4]的成功引发的。深度学习可实现多层自动特征表示学习。相比之下,传统的基于机器学习的NLP系统在很大程度上依赖于人工特征。这种人工特征非常耗时且通常不完备。
Collobert等[5]证明了一个简单的深度学习框架可以在很多NLP任务中表现优于大多数最先进的方法,例如命名实体识别(NER),语义角色标记(SRL)和词性标注。从那时起,已经提出了许多基于复杂深度学习算法来解决困难的NLP任务。我们回顾了应用于自然语言任务的主要深度学习相关模型和方法,例如卷积神经网络(CNN),循环神经网络(RNN)和递归神经网络。我们还讨论了记忆增强策略,注意力机制以及无监督模型,强化学习方法以及最近的深度生成模型如何用于语言相关任务。
据我们所知,本文是第一个全面涵盖当今NLP研究中最流行的深度学习方法的工作。Goldberg [6]的工作仅以教学方式介绍了将神经网络应用于NLP的基本原则。我们相信本文将为读者提供有关该领域当前实践的更全面的概念。论文的结构如下:第II节介绍了分布式表示的概念,是复杂深度学习模型的基础;接下来,第III,IV和V节讨论流行模型,如卷积,循环和递归神经网络,以及它们在各种NLP任务中的使用;接下来,第VI节列出了NLP中强化学习的最新应用以及无监督句子表示学习的新发展;然后,第VII节阐述了深度学习模型与内存模块结合的最新趋势;最后,第VIII部分总结了一系列深度学习方法在主要NLP问题的标准数据集上的表现。
II. 分布式表示
统计NLP(代表人物Christopher Manning,著有同名教材)曾经建模复杂自然语言任务的主要选择。然而,它初期经常在学习语言模型的联合概率函数时遭遇”维度灾难“。这是学习词在低维空间中的分布式表示的动机[7]。
分布式表示(distributed representation):分布式(distributed)描述的是把信息分布式地存储在向量的各个维度中,与之相对的是局部表示(local representation),如词的on-hot表示(one-hot representation),在高维向量中 只有一个维度描述了词的语义。一般来说,通过矩阵降维或神经网络降维可以将语义分散存储到向量的各个维度中,因此,这类方法得到的低维向量一般都可以称作分布式表示。
作者:spring_willow
来源:CSDN
原文:https://blog.csdn.net/spring_willow/article/details/81452162
A.词嵌入
分布式向量或词嵌入(图2)基本上遵循分布式假设,根据该假设,具有相似含义的词倾向于在类似的上下文中出现。因此,这些向量试图表示词的邻居这一特征。分布式向量的主要优点是它们表示词之间的相似性。可以使用余弦相似度等度量方法来测量向量之间的相似性。词嵌入通常用作深度学习模型中的第一个数据处理层。通常,通过优化大规模未标注语料库中的辅助目标来预训练词嵌入,例如基于其上下文预测词[8,3] (也就是说,通过基于上下文预测词来训练词嵌入,认为如果预测词的任务效果好,则词嵌入训练的效果也好),其中所学习的词向量可以表示通用的句法和语义信息。因此,已经证明这些嵌入在表示上下文相似性和类比方面是有效的,并且由于其较小的维度,在计算核心NLP任务时是快速且有效的。
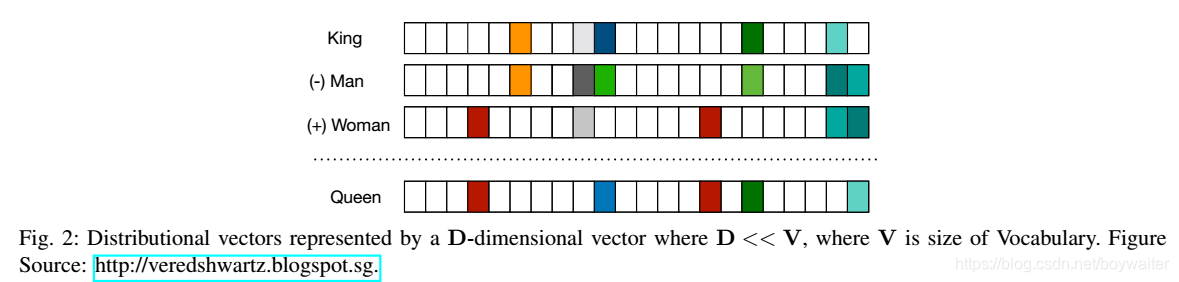
多年来,创建这种嵌入模型一直是浅层神经网络,并且不需要深层网络来创建良好的嵌入。然而,基于深度学习的NLP模型总是使用这些嵌入来表示词、短语甚至句子。这实际上是传统的基于词数的模型和基于深度学习的模型之间的主要区别。词嵌入一直是各种NLP任务中最先进结果的原因[9,10,11,12]。
例如,Glorot等[13]在情感分类中使用嵌入和叠加去噪自动编码器进行域自适应,Hermann和Blunsom [14]提出了组合分类自动编码器来学习句子的组合性。在最近文献中的广泛使用表明它们在执行NLP任务的任何深度学习模型中的有效性和重要性。
分布式表示(嵌入)主要通过上下文来学习。在20世纪90年代,一些研究发展[15]标志着分布语义研究的基础。[16,17]提供了这些早期趋势的更详细的总结。后来的发展是对这些早期工作的改编,由此创建了主题模型,如LDA(latent Dirichlet allocation)[18]和语言模型(language models, LMs)[7]。这些工作奠定了表示学习的基础。
2003年,Bengio等[7]提出了一种神经语言模型,可以学习词的分布式表示(图3)。作者认为,一旦利用词序列的联合概率将词表示编译成句子表示,就得到了指数数量的语义相邻句子。进而,这有助于泛化,因为如果已经看到具有相似词(相似是指词表示在低维空间中相邻)的词序列,则未见的句子现在可以得到更高的置信度。
[19]是首个展示预训练词嵌入实用性的工作。作者提出了一种神经网络架构,构成了许多当前方法的基础。该工作还开创了将词嵌入作为NLP任务的有用工具。然而,词嵌入的广泛推广可以说归功于[3],他们提出了连续词袋模型(continuous bag-of-words, CBOW)和skip-gram模型来有效地构建高质量的分布式向量表示。推动其广泛使用的是所表现出向量组合性这样的意外副作用,即,两个词向量的和向量是这两个词的语义合成,例如“man”+“royal”=“king”。Gittens等[20]最近给出了这种情况的理论依据,指出仅在某些假设成立时才能看到组合性,例如,假设词需要在嵌入空间中均匀分布。
Pennington等[21]提出另一种著名的词嵌入方法,它基本上是一种“基于计数”的模型。这里,通过对计数进行归一化并对它们进行对数平滑来预处理词共现计数矩阵。然后对该矩阵进行分解以获得较低维度的表示,这通过最小化“重建损失”来完成。
下面,我们提供Mikolov等人提出的word2vec方法的简要描述[3]。
B. word2vec
词嵌入由Mikolov等人革命化[8,3],提出了CBOW和skip-gram模型。给定围绕目标词的大小为k的窗口中的上下文词,CBOW计算目标词的条件概率。另一方面,与CBOW模型完全相反,skip-gram模型通过预测给定中心目标词的周围上下文词。假设上下文词对称地位于前后两个方向上窗口大小相等的距离内。在无监督情况,词嵌入维度由预测的精确度决定。随着嵌入维数的增加,预测的精确度也会增加,直到它在某个点收敛,则认为该点是最佳的嵌入维度,因为它在不影响精确度的情况下是最短的。
让我们考虑CBOW模型的简化版本,其中在上下文中仅考虑一个词。这基本上复制了一个二元语言模型(bigram)。这部分内容的详细解释见https://blog.csdn.net/boywaiter/article/details/83409636
如图4所示,CBOW模型是一个简单的全连接神经网络,有一个隐藏层。输入层采用上下文词的one-hot向量作为输入,具有 V V V个神经元,而隐藏层具有 N N N个神经元。输出层是词汇表中所有词的softmax。这些层分别通过权重矩阵 W ∈ R V × N \textbf{W}\in \mathcal{R}^{V×N} W∈RV×N和 W ′ ∈ R H × V \textbf{W}'\in \mathcal{R}^{H\times V} W′∈RH×V连接。来自词汇表的每个词最终表示为两个学习向量 v c \textbf{v}_c vc和 v w \textbf{v}_w vw,分别对应于作为上下文和作为目标词的表示。因此,词汇表中的第 k k k个词将具有
v c = W ( k , . ) a n d v w = W ( . , k ) ′ \textbf{v}_c=\textbf{W}_{(k,.)}\ and \ \textbf{v}_w=\textbf{W}'_{(.,k)} vc=W(k,.) and vw=W(.,k)′
总的来说,对于任何词 w i w_i wi以及给定的上下文词 c c c作为输入,
P ( w i c ) = y i = e u i ∑ j = 1 V e u j P(\frac{w_i}{c})=y_i=\frac{e^{\textbf{u}_i}}{\sum_{j=1}^{V}e^{\textbf{u}_j}} P(cwi)=yi=∑j=1Veujeui
参数 θ = { W , W ′ } \theta=\{\textbf{W},\textbf{W}'\} θ={W,W′}是以log似然作为目标函数,并计算梯度如下学习得到的
l ( θ ) = ∑ w ∈ V o c a b u l a r y log ( P ( w c ) ) l(\theta)=\sum_{w\in Vocabulary}\log(P(\frac{w}{c})) l(θ)=w∈Vocabulary∑log(P(cw))
∂ l ( θ ) ∂ W ′ = W ( 1 − P ( w c ) ) \frac{\partial{l(\theta)}}{\partial \textbf{W}'}=\textbf{W}(1-P(\frac{w}{c})) ∂W′∂l(θ)=W(1−P(cw))
在通用CBOW模型中,所有上下文词的one-hot向量同时输入,即
h = W T ( x 1 + … + x c ) \textbf{h}=\textbf{W}^\textrm{T}(\textbf{x}_1+\ldots +\textbf{x}_c) h=WT(x1+…+xc)
单个词嵌入的一个不足是它们无法表示短语Mikolov等[3],其中两个或多个词的组合(例如,像“hot potato”[烫手山芋]这样的习语或是象“Boston Global”[波士顿环球报]这样的命名实体)不代表单个词的含义的组合。Mikolov等探讨该问题的解决方案[3],基于词共现来识别这些短语,并单独训练短语嵌入。最近的方法已经探索了直接从未标注数据中学习n-gram嵌入[23]。
另一个不足来自于仅基于周围词的小窗口学习嵌入,有些词,例如 g o o d good good的和 b a d bad bad,共享几乎相同的嵌入[24],如果用于情感分析这样的任务[25]则有问题。有时这些嵌入会将语义上相似但具有相反情感的词聚类到一起。这使得情绪分析任务的下游模型无法识别导致性能变差的这一原因。Tang等[26]通过提出情感特定词嵌入(sentiment specific word embedding,SSWE)来解决这个问题。作者在学习嵌入时将损失函数中有监督情感标签纳入损失函数。
词嵌入的普遍警告是其高度依赖于使用它的应用程序。Labutov和Lipson[27]提出了任务特定嵌入,它重新训练词嵌入以使它们在当前任务空间中对齐。这非常重要,因为从头开始的训练嵌入需要大量的时间和资源。Mikolov等[8]试图通过提出负面采样( n e g a t i v e negative negative s a m p l i n g sampling sampling)来解决这个问题,负面采样只是在训练word2vec模型时基于频率的负面词采样。
传统的词嵌入算法为每个词分配不同的向量。这使他们无法解释多义词。在最近的一项工作中,Upadhyay等[28]提供了一种解决这一缺陷的创新方法。作者利用多语言并行数据来学习多义词嵌入。例如,英语词bank,当翻译成法语时,提供两个不同的词:banc和banque,分别代表财务和地理含义。这种多语种分布信息帮助他们解决了一词多义问题。表I提供了现有框架的目录,这些框架经常用于创建嵌入,并进一步结合到深度学习模型中。
C.字符嵌入
词嵌入能够表示语法和语义信息,但对于诸如词性标注和NER之类的任务,词内形态和形状信息也非常有用。一般来说,在字符层面建立自然语言理解系统已引起一定的研究关注[29,30,31,32]。某些NLP任务中报告了形态丰富语言的更好结果。Santos和Guimaraes [31]应用了字符级表示,以及针对NER任务的词嵌入,在葡萄牙语和西班牙语语料库中实现了最先进的结果。Kim等[29]显示仅使用字符嵌入构建神经语言模型的积极结果。Ma等[33]利用几个嵌入,包括字符trigram,并结合原型和分层信息,用于在NER任务中学习预训练的标签嵌入。
具有大词汇量的语言的普遍现象是未知词问题或未登录词(out-of-vocabulary,OOV)问题。字符嵌入可以处理这个问题,因为词不过是字母的组合。某些语言的文本不是由词而是由字符构成,而且词的语义含义映射为其构成字符(如中文),字符级别的构建系统是避免分词的自然选择[34]。因此,在这类语言中采用深度学习应用程序的工作往往倾向于在字符嵌入而不是词向量[35]。例如,Peng等[36]证明偏旁部首(radical)级的处理可以大大提高情感分类的表现。特别是,作者提出了两种类型的中文基于偏旁部首的分层嵌入,它不仅包括偏旁部首和字符层面的语义,还包含情感信息。Bojanowski等[37]还试图通过在形态丰富的语言中使用字符级信息来改进词的表示。他们将词表示为字符袋(bag-of-character)n-gram,接近于skip-gram方法。因此,他们的工作具有skip-gram模型的有效性,同时解决了一些持久的词嵌入问题。该方法也很快,可以快速地在大型语料库上进行训练。该方法通常被称做 F a s t T e x t FastText FastText,在速度,可伸缩性和有效性方面比以前的方法更突出。
除了字符嵌入之外,还提出了用于OOV处理的不同方法。Herbelot和Baroni [38]通过将未知词初始化为上下文词的总和,以及提高学习率精炼这些词,实时处理OOV。但是,他们的方法尚未在典型的NLP任务上进行测试。Pinter等[39]提供了一种有趣的方法来训练基于字符的模型来重建预训练的嵌入。这使他们能够学习到从字符嵌入到词嵌入的组合映射,从而解决OOV问题。
尽管分布式向量越来越受欢迎,但最近关于其长期相关性的讨论已经出现。例如,Lucy和Gauthier[40]最近试图评估词向量表示概念含义必要方面的能力。作者发现了对词背后概念的感知理解的严重不足,这些不足无法仅从分布式语义中推断出来。缓解这些不足的可能方向将是基础学习(grounded learning,类似于儿童学习语言的学习方式,在丰富的语言环境中学,无需标注),这在该研究领域中越来越受欢迎。
III. CNN
随着词嵌入的普及及其在分布式空间中表示词的能力,需要一种有效的特征函数,可以从构成句子的词或n-gram中提取更高级别的特征。这些抽象特征将用于许多NLP任务,例如情感分析、摘要、机器翻译和问答(QA)。CNNs因其在计算机视觉任务中的有效性而被证明是用于这些任务自然选择[41,42,43]。
使用CNN进行句子建模追溯到Collobert和Weston [19]。这项工作使用多任务学习来输出NLP任务的多个预测,例如词性标注、块(chunk)、命名实体标签、语义角色、语义相似的词和语言模型。查找表用于将每个单词转换为用户定义维度的向量。因此,通过将查找表应用于每个词(图5),输入序列 { s 1 , s 2 , … , s n } \{s_1, s_2,\ldots ,s_n\} {s1,s2,…,sn}的 n n n个单词被转换成一系列向量 { w s 1 , w s 2 , … , w s n } \{\textbf{w}_{s_1}, \textbf{w}_{s_2}, \ldots , \textbf{w}_{s_n}\} {ws1,ws2,…,wsn}。
这可以被认为是最早的词嵌入方法,其权重是在网络训练中学习的。在[5]中,Collobert扩展了他的工作,提出了一个基于CNN的通用框架来解决大量的NLP任务。这两项工作都引发了CNN在NLP研究人员中的大规模普及(截止2018年10月27日,google scholar引用分别2752和3625)。鉴于CNN已经展示了其在计算机视觉任务中的成功,人们更容易相信其(在NLP任务中的)表现。
CNN具有从输入句子中提取显著n-gram特征的能力,为下游任务创建句子的富含信息的潜在语义表示。该应用由Collobert等[5],Kalchbrenner等[44],Kim[45]开创,这使得后续文献中基于CNN的网络大量增加。下面,我们描述一个简单的基于CNN的句子建模网络的工作。
A. 基本CNN
1)句子建模:如图6所示。
原始文本中句子参差不齐,需要进行预处理。按照预定义的两个参数进行预处理。这两个参数分别是max_len和max_features。max_len规定了每个句子的最大程度,或者句子中可以包含的word的最大个数。max_features表示只保留最常见的前max_features个词。
经过预处理之后,输入是一个(None, max_len)的张量,第1维表示句子数目,None表示可以接受任何数目,第2维是每个句子中包含的word的最大个数,这些word都属于前max_features个最常见的词。
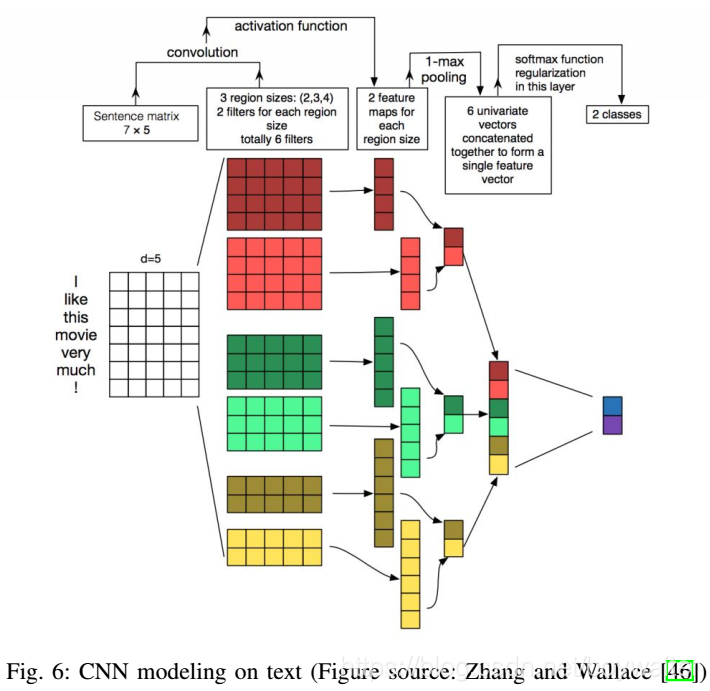
- Embedding层
– Embedding层的主要参数是Embedding(input_dim, out_dim, input_length)。其中input_dim=max_features,out_dim表示每个word嵌入的维度,input_length=max_len。
– Embedding层的输出是(None, input_length, out_dim)的张量。
– 例如,图中input_length=7,out_dim=5 - 卷积层
– Conv1D(filters, kernal_size,activatation),其中filters代表filter的个数,kernal_size代表核的大小,activatation是激活函数。
– 例如,图中有三个Conv1D层,filters都是2, kernal_size自上而下分别是4,3,2, activatation没有明说,可以是tanh或relu等。每个Conv1D两个filter,一共6个filter。
– 输入是Embedding层的输出
– 输出是(None, input_length-kernel_size+1, filters)
– 例如,自上而下input_length-kernel_size+1分别是7-4+1=4,7-3+1=5,7-2+1=6 - max-pooling层,在input_length-kernel_size+1维中取最大值,输出(None,1,filters)即(None,filters)。
– 例如,自上而下共输出3个(None,2)
– 再将它们组合到一起,输出(None, 6) - softmax层Dense(classes,activation=‘softmax’)是一个分类器,将输入分为指定数目classes的类别
– 例如,图中classes=2,可能是情感分析任务的positive和negative。
注意:公式(6)中 k T \textbf{k}^\textrm{T} kT应为 k \textbf{k} k,因为点积operation的两个operand应该shape相同。另外还有个typo,"The filter k k k is applied…“应为"The filter k \textbf{k} k is applied…”
2)Window方法:基本CNN可以将整个句子建模为句子表示(由词嵌入构成),但很多NLP任务,如NER、POS tagging,SRL(semantic role labeling),需要基于word的预测。Window方法用于解决这些任务,它假定一个word的标注只依赖于其周围的word。
对上述模型的修改:卷积层的输入不再是整个句子的表示,而是固定大小的以待标注词为中心的窗口内的子句的表示。
结合CRF可以提升效果,因为CRF可以表示相邻标注之间的依赖信息。
结合TDNN(time-delay neural network)。Window方法中的CNN只考虑待标注词所在窗口,而TDNN额外同时考虑所有窗口。
B. 应用
Kim[45]将上述框架用于句子分类任务,效果显著。缺点是CNN所固有的,无法在模型中包含长距离依赖。
Kalchbrenner等[44]提出DCNN(Dynamic CNN),还提出一种dynamic k-max pooling策略,可以从序列中选择最活跃的k个特征,而且只保留k个特征的顺序而忽略其位置信息。通过该策略与DCNN的结合,可以使得较小kernel_size的filter也可以覆盖输入句子的较大范围,可以累积整个句子中的重要信息。而基本CNN的较高卷积层特征的覆盖范围是由最底层卷积层的kernel_size决定的。
针对情感分析任务,Ruder等[51]将句子表示与aspect向量(对应于不同情感的句子内容的表示)连接起来(concatenation)。
CNN方法通常在长文本上表现好于短文本[23]。Wang等[52]提出用CNN学习短文本的表示。因为短文本上下文较少,需要结合外部知识[53]。
Denil等[54]将DCNN用于将构成句子的词的含义映射为从中提取摘要的文档的含义。DCNN在句子和文档两个层次学习卷积filter,将低层的词汇特征合成为高层的语义概念。
CNN用于语义匹配[55]和信息检索[56]。CNN将查询和文档投影到同一语义空间中,计算cosine相似度。CNN根据词序列中的时间上下文窗口提取查询和文档中的上下文结构,在词的n-gram层次上表示上下文特征。卷积层和最大池化层可以发现显著的词n-gram,聚合起来构成完整的句子向量。
在QA领域,Yih等[57]提出通过计算查询和知识库中实体的语义近似度来确定知识库中的哪些事实可以用来回答某个问题。Dong[58]提出MCCNN(multi-column CNN)来从多个方面分析和理解问题并创建其表示,利用MCCNN从构成回答类型的多个方面及问题的上下文来提取信息。Severyn and Moschitti [59]用CNN建模问题和回答句子的优化表示,在嵌入中加入额外的问题和回答对中匹配的词的关系信息。
如果句子中包含多个重要事实,则最大池化会丢失信息。为此,Chen等[60]提出DMCNN(Dynamic multi-pooling CNN)。
CNN固有的局部连接性、权重共享和池化带来某种程度的不变性。语音识别也需要这种不变性。Abdel-Hamid等[61]利用混合CNN-HMM模型为频率轴上的频移提供不变性。由于说话者的不同,经常会出现语音信号的变化。采用有限权重共享减少了池化参数,计算复杂度降低。Palaz等[60]深入分析了以原始语音作为输入的基于CNN的语音识别系统。
机器翻译需要保留序列信息和长期依赖,从结构上看CNN并不适合。Tu等[61]通过结合翻译对的语义近似度和原文译文各自上下文解决了这一问题。尽管没有解决序列保留问题,但评测结果很好。
总的来说,CNN擅于从上下文窗口中发现语义线索,但包含大量训练参数,需要大量训练数据。另一个弱点是不能建模长距离上下文信息,无法在表示中保留序列信息[43, 61]。
IV. RNN
RNN [64]处理序列信息,“循环”表示在序列的每个实例上执行相同的任务,输出取决于先前的计算和结果。通常,通过将序列中的符号一个接一个送入循环单元,产生固定大小的序列的向量表示。在某种程度上,RNN对先前的计算有“记忆”并在当前处理中使用该信息。该模式自然适用于许多NLP任务(因为自然语言是序列),如语言建模[2,65,66],机器翻译[67,68,69],语音识别[70,71,72,73],图像字幕[74]。
A. RNN的特点
- RNN序列处理的特点,使其适于表示语言的序列性
- RNN可以建模变长文本[75, 76]
- 对于需要建模整个句子的NLP任务,例如机器翻译[77],RNN可以先将句子摘要为一个定长向量,再将其映射为变长的目标序列
- RNN还支持时间分布式联合处理。大多数像词性标注这样的序列标记[32]都属于这个领域。更具体的例子包括多标签文本分类[78],多模情感分析[79,80,81]和主观性检测[82]。
这并不意味RNN优于其他模型,在语言建模上,CNN也有着很有竞争力的表现[83]。CNN和RNN在建模句子时目标不同。
- RNN试图创建一个任意长句子与无限长上下文的组合,CNN则试图提取最重要的n-gram。虽然CNN被证明可以有效表示n-gram特征,这在某些句子分类任务中是近似充分的,但只有局部的词序敏感性,而通常忽略长期依赖性。
Yin等[84]提供了RNN和CNN之间性能比较。经过在多个NLP任务,包括情感分类,QA和词性标注,得出的结论是没有明显的赢家:每个网络的性能取决于任务本身所需的全局语义。
B. RNN模型
1)简单RNN:Fig.9 是一个通用RNN按时间的展开图,可以接受整个序列作为输入。
- x t \textbf{x}_t xt: t t t时刻的输入
- h t \textbf{h}_t ht: t t t时刻的隐藏状态
- o t \textbf{o}_t ot: t t t时刻的输出
-
h
t
=
f
(
Ux
t
+
Vh
t
−
1
)
\textbf{h}_t= f(\textbf{Ux}_t +\textbf{Vh}_{t-1})
ht=f(Uxt+Vht−1),即当前时刻的隐藏状态是由当前时刻的输入和上一时刻的隐藏状态计算得到的。
f
f
f是非线性函数,如tanh或ReLU。
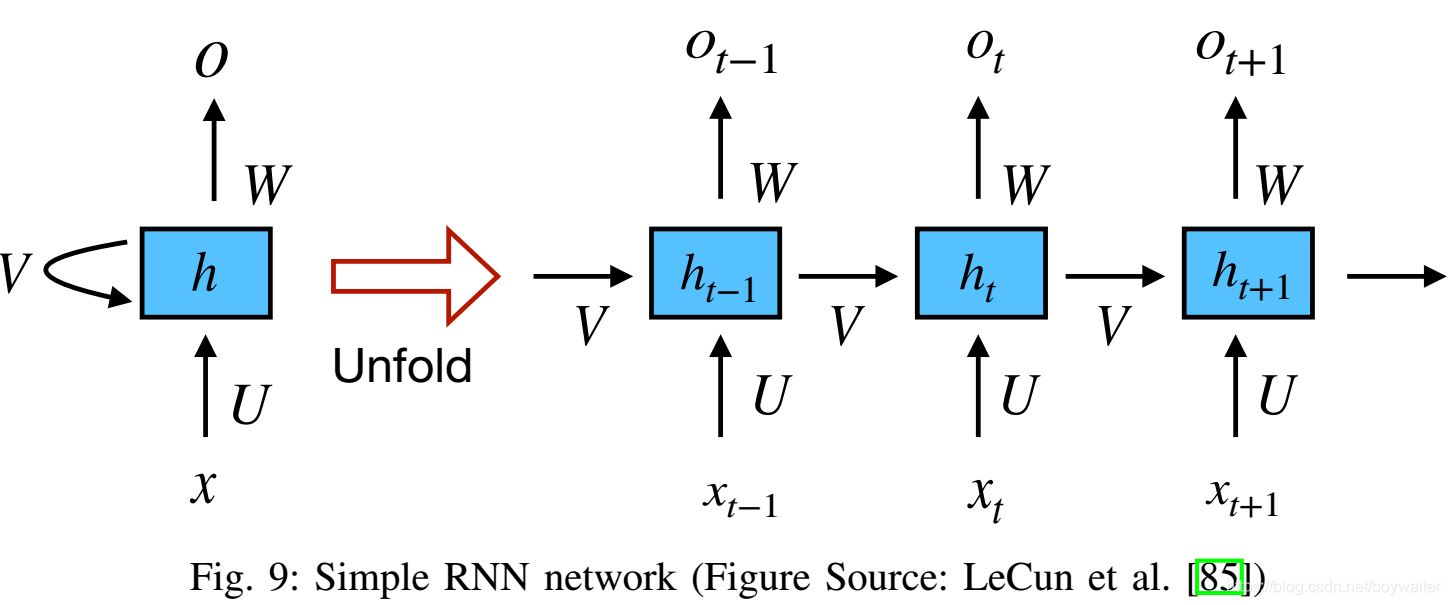
- h t = σ ( Wh t ) \textbf{h}_t= \sigma(\textbf{Wh}_t) ht=σ(Wht),即输出是由当前时刻的隐藏状态计算得到, σ \sigma σ表示输出也可能涉及非线性。
- U, V, W \textbf{U, V, W} U, V, W是各时刻共享的权重矩阵。
- 隐藏状态可以看做RNN的存储,记忆了其他时间步中的信息。
在NLP任务中,
x
t
\textbf{x}_t
xt通常是one-hot编码或嵌入,有时也可以是文本内容的抽象表示。
简单RNN常常会遇到“梯度消失”的问题,使得模型难以训练和调参。为此,提出变种LSTM(Long short-term memory)和GRU(Gated recurrent units),以及新的网络结构ResNet (Residual networks,残差网络)。
2)LSTM:LSTM (Fig. 10)[86, 87]在简单RNN上加入了“遗忘”门(forget gates),可以解决梯度消失和梯度爆炸问题。
与普通(vanilla)RNN不同,LSTM允许误差反向传播无限多个时间步。包含三个门,输入、遗忘和输出(图中分别用i、f和o表示)。
RNN使用隐藏状态作为记忆,当前记忆是当前输入与之前记忆的组合。更早之前的记忆会随时间步进逐渐减弱消失(原因是,f为tanh,则与隐藏状态h相乘的权重矩阵V的元素值可以看做介于[-1,1]之间,f为relu,则看做是0或1。随着时间步进,矩阵V不断连乘,元素值逐渐减小),因此误差关于更早隐藏状态的参数的梯度逐渐缩小,称为梯度消失。梯度消失,则对这些参数不再更新。对于需要长期依赖的应用场景,RNN性能不佳。
LSTM和GRU引入“门”,用于控制信息流。遗忘门用于遗忘某些过去的记忆,输入门引入新的信息,输出门控制哪些需要放入记忆以备将来使用。LSTM的门使用sigmoid激活函数,输出值介于[0,1]。
更详细的解释可以参见
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
(中文翻译参见 https://www.jianshu.com/p/9dc9f41f0b29)
和 https://cloud.tencent.com/developer/article/1358208
和 https://zybuluo.com/hanbingtao/note/581764
隐藏状态是结合了三个门计算得到的:
x
=
[
h
t
−
1
x
t
]
\textbf{x}=\left [\begin{matrix} \textbf{h}_{t-1}\\ \textbf{x}_t\end{matrix}\right]
x=[ht−1xt]
f t = σ ( W f ⋅ x + b f ) f_t=\sigma (\textbf{W}_f\cdot \textbf{x}+\textbf{b}_f) ft=σ(Wf⋅x+bf)
i t = σ ( W i ⋅ x + b i ) i_t=\sigma (\textbf{W}_i\cdot \textbf{x}+\textbf{b}_i) it=σ(Wi⋅x+bi)
C ~ t = tanh ( W c ⋅ x + b c ) \tilde{C}_t= \tanh(\textbf{W}_c\cdot \textbf{x}+\textbf{b}_c) C~t=tanh(Wc⋅x+bc)
o t = σ ( W o ⋅ x + b o ) o_t=\sigma (\textbf{W}_o\cdot \textbf{x}+\textbf{b}_o) ot=σ(Wo⋅x+bo)
C t = f t ⊙ C t − 1 + i t ⊙ C ~ t C_t=f_t\odot C_{t-1}+i_t\odot\tilde{C}_t Ct=ft⊙Ct−1+it⊙C~t
h t = o t ⊙ tanh ( C t ) h_t=o_t\odot \tanh(C_t) ht=ot⊙tanh(Ct)
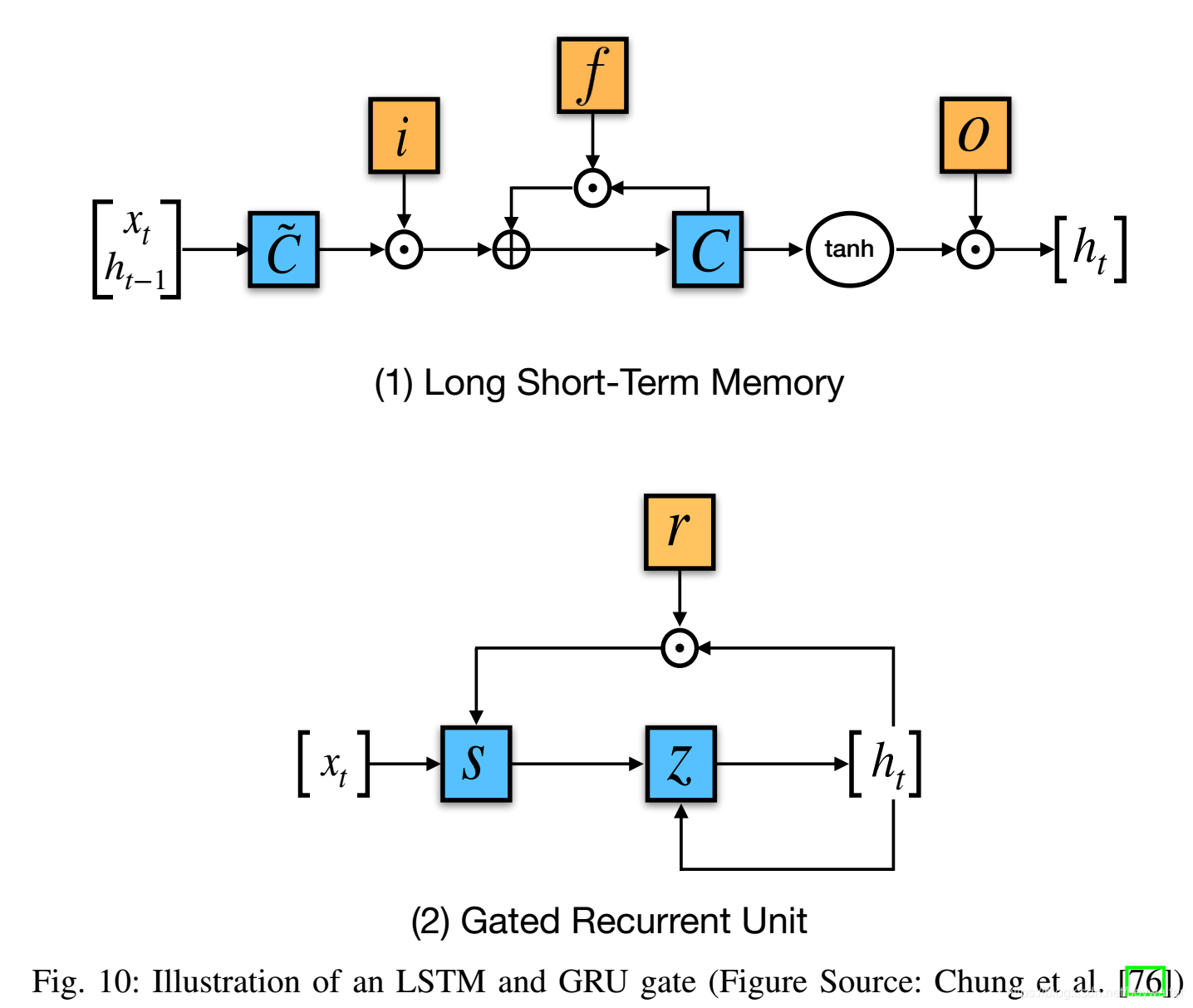
3)GRU:GRU[77](Fig. 10)结构上没有LSTM复杂,但性能上差不多。GRU包括两个门,重置门(reset gate)和更新门(update),类似于无记忆的LSTM。完全暴露隐藏状态信息,不加控制。
z
=
σ
(
U
z
⋅
x
t
+
W
z
⋅
h
t
−
1
)
\textbf{z}=\sigma(\textbf{U}_z\cdot \textbf{x}_t+\textbf{W}_z\cdot \textbf{h}_{t-1})
z=σ(Uz⋅xt+Wz⋅ht−1)
r = σ ( U r ⋅ x t + W r ⋅ h t − 1 ) \textbf{r}=\sigma(\textbf{U}_r\cdot \textbf{x}_t+\textbf{W}_r\cdot \textbf{h}_{t-1}) r=σ(Ur⋅xt+Wr⋅ht−1)
s t = tanh ( U z ⋅ x t + W s ⋅ ( h t − 1 ⊙ r ) ) \textbf{s}_t=\tanh(\textbf{U}_z\cdot \textbf{x}_t+\textbf{W}_s\cdot (\textbf{h}_{t-1}\odot\textbf{r})) st=tanh(Uz⋅xt+Ws⋅(ht−1⊙r))
h t = ( 1 − z ) ⊙ s t + z ⊙ h t − 1 \textbf{h}_t=(1-\textbf{z})\odot\textbf{s}_t+\textbf{z}\odot \textbf{h}_{t-1} ht=(1−z)⊙st+z⊙ht−1
问题是如何选择适合的带门的RNN(gated RNN),答案是启发式的。Chung等[76]对比评价上述RNN,结论是带门的比简单的(使用tanh作为激活函数)好,但LSTM和GRU差别不大。
应用
1)用于词一级分类的RNN:RNN在词一级分类领域占有重要地位。在许多任务中都是最先进的。Lample等[88]使用双向LSTM进行NER。网络表示围绕目标词的任意长的上下文信息(突破固定窗口大小的限制),产生两个固定大小的向量,在其上是一个全连接层,最后用CRF层进行实体标记。
与基于计数统计的传统方法相比,RNN在语言建模方面也有相当大的改进。Graves [89]在这一领域开创了先河,说明了RNN在建模带有远距离上下文结构的复杂序列的有效性。他还提出了深度RNN,使用多层隐藏状态来增强建模。这项工作开创了RNN在NLP之外的任务的使用。后来,Sundermeyer等[90]比较了根据前面词预测词时,将前馈神经网络替换为RNN而获得的增益。他们提出了神经网络架构中的典型层次结构,其中前馈神经网络相对于传统的基于计数的语言模型得到了相当大的改进,而前馈神经网络又被RNN取代,后来被LSTM取代。他们提到的一个重点是他们的结论适用于各种其他任务,如统计机器翻译[91]。
2)句子级别分类的RNN:Wang等[25]提出用LSTM编码整个推文(tweets),其隐藏状态用于预测不同情感。事实证明,这种简单的策略比Kalchbrenner等人提出的更复杂的DCNN结构[44]更有竞争力,后者旨在赋予CNN模型表示长期依赖的能力。在研究否定短语的特殊情况下,作者还表明LSTM门的动态性可以表示词not的逆转效应。
与CNN类似,RNN的隐藏状态也可用于文本之间的语义匹配。在对话系统中,Lowe等[92]建议用Dual-LSTM匹配消息和候选响应,Dual-LSTM将两者都编码为固定大小的向量,然后将其内积作为对候选响应进行排序的基础。
3)用于生成语言的RNN:NLP中的一项具有挑战性的任务是生成自然语言,这是RNN的另一种自然应用。根据文本或视觉数据,深度LSTM在诸如机器翻译,图像字幕等任务中生成合理的任务特定文本。在这种情况下,RNN被称为解码器。
在[69]中,作者提出了一种通用的深度LSTM编码器 - 解码器框架,将一个序列映射到另一个序列。一个LSTM用于将“源”序列编码为固定大小的向量,可以是原始语言的文本(机器翻译),要回答的问题(QA)或要回复的消息(对话系统) 。该向量作为另一个称为解码器的LSTM的初始状态。在推理期间,解码器一个接一个地生成符号,同时用最后生成的符号更新其隐藏状态。集束搜索通常用于近似最佳序列。
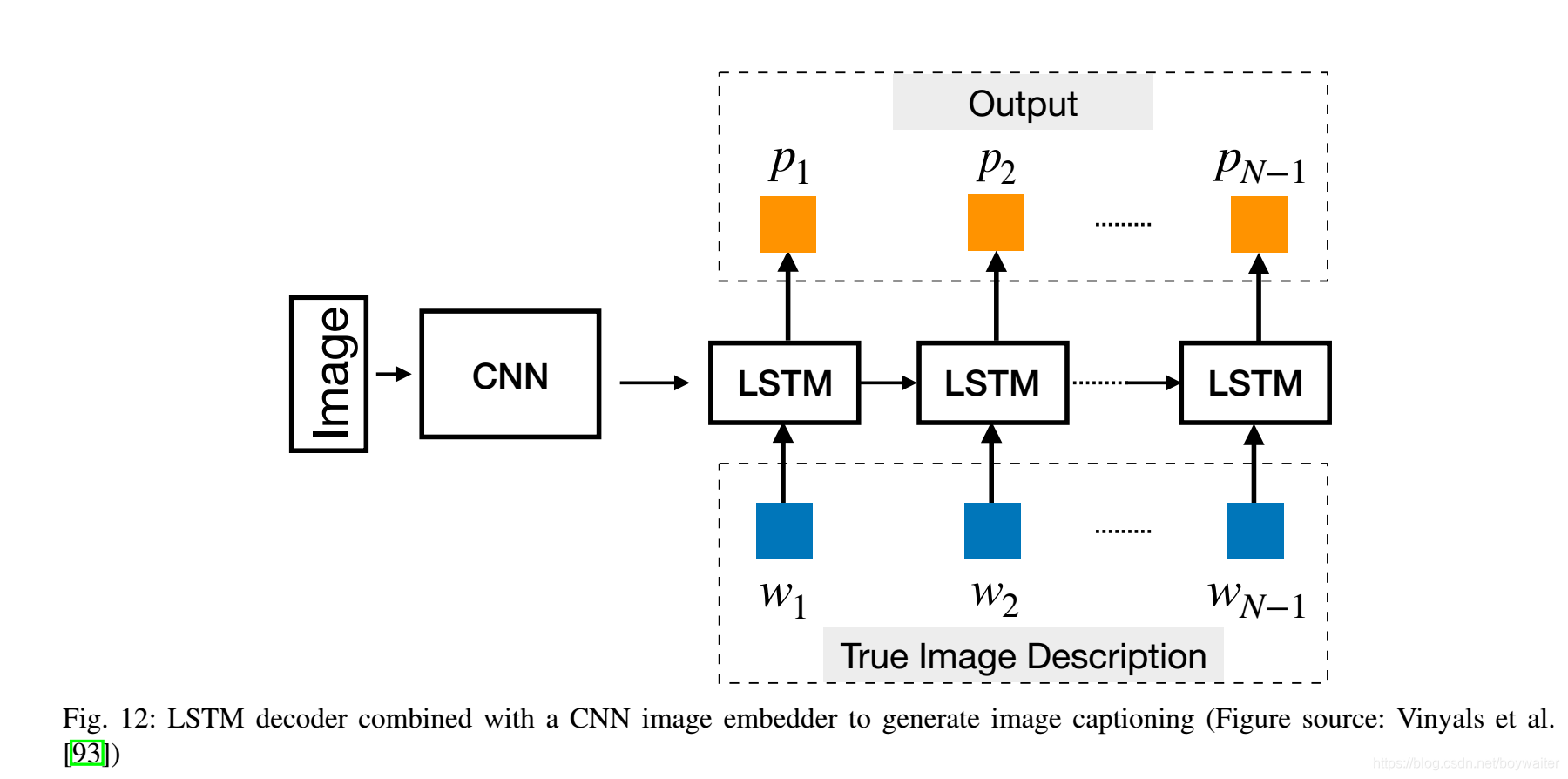
Sutskever等[69]以端到端的方式在机器翻译任务上试验4层LSTM,显示出有竞争力的结果。在[94]中,采用相同的编码器 - 解码器框架来建模人类对话。在超过1亿个消息响应对上训练时,LSTM解码器能够在开放域中生成非常有趣的响应。在附加信号上调节LSTM解码器以实现某些效果也是常见的。在[95]中,作者提出在一个恒定的个人向量上调节解码器,该向量表示单个说话者的个人信息。在上述情况中,主要基于文本输入的语义向量表示生成语言。类似的框架也已成功用于基于图像的语言生成,其中视觉特征用于调节LSTM解码器(图12)。
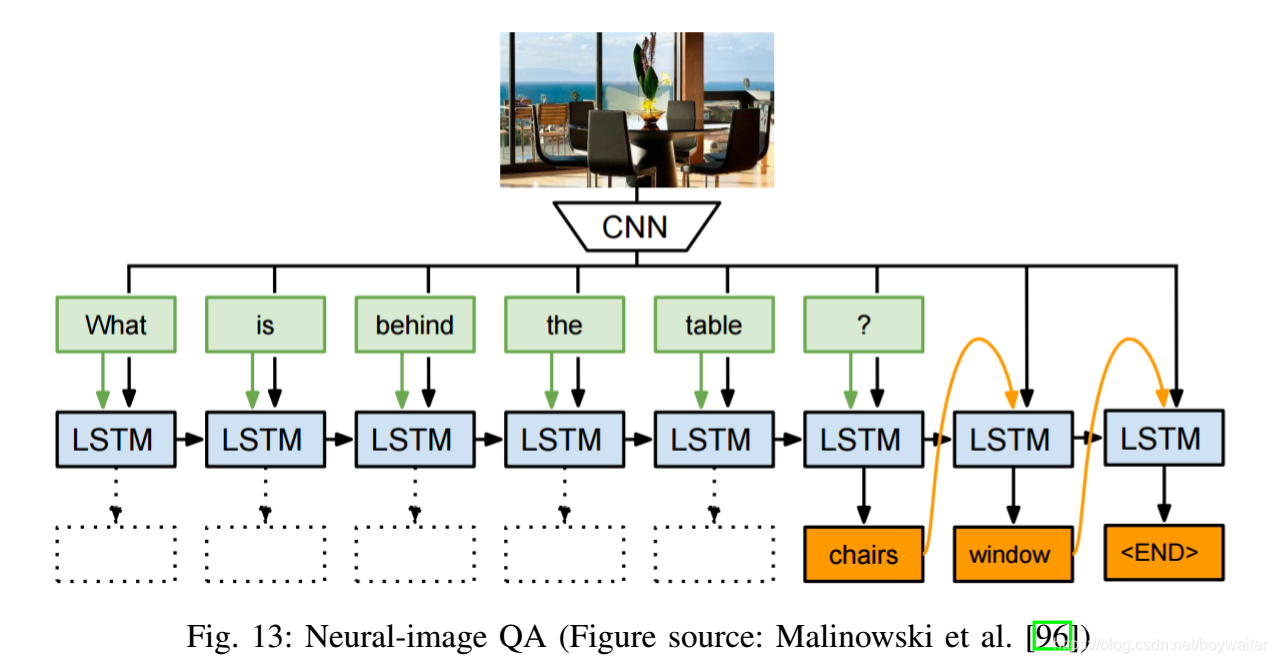
Visual QA是另一项需要基于文本和视觉线索生成语言的任务。Malinowski等[96]第一个提出端到端深度学习解决方案,他们将答案预测为根据CNN建模的输入图像和LSTM建模的文本来调节的一组词(图13)。
Kumar等[97]通过精心设计的称为DMN(动态存储网络)的网络来解决这个问题,该网络有四个子模块。想法是反复访问输入文本和图像,以形成在每次迭代中改进的信息集。注意力网络用于细粒度地聚焦于输入的文本短语。
注意力机制
传统编码器 - 解码器框架面临的一个潜在问题是编码器有时被迫编码可能与任务不完全相关的信息。如果输入很长或者信息很丰富并且不可能进行选择性编码,也会出现问题。
例如,文本摘要的任务可以被转换为序列-到-序列学习问题,其中输入是原始文本,输出是压缩版本。直观地说,期望固定大小的向量编码很长文本中的所有信息是不现实的。在机器翻译中也报道了类似的问题[98]。
在诸如文本摘要和机器翻译之类的任务中,输入文本和输出文本之间存在某些对齐,这意味着每个标记生成步骤与输入文本的某个部分高度相关。这种直觉激发了注意力机制。该机制试图通过允许解码器返回去参考输入序列来缓解上述问题。具体地说,在解码期间,除了最后隐藏状态和生成的符号之外,解码器还根据一个“上下文”向量来调节,该向量基于输入的隐藏状态序列计算得到的。
Bahdanau等[98]首先将注意机制应用于机器翻译,提高了性能,特别是对于长序列。在他们的工作中,根据解码器的最后隐藏状态,利用多层感知器,确定输入隐藏状态序列上的注意力信号。通过在每个解码步骤期间,可视化输入序列上的注意力信号,可以看出源语言和目标语言之间的清晰对齐(图14)。

Rush等[99]将类似的方法应用于摘要任务。其中摘要中的每个输出词都通过注意力机制根据输入句来调节。作者进行了生成式摘要,与抽取式摘要相反,它不是非常传统的,但可以扩展到大规模数据,语言输入最少。
在图像字幕中,Xu等[100]在每个解码步骤期间,根据输入图像的不同部分调节LSTM解码器。注意力信号由前一个隐藏状态和CNN特征确定。在[101]中,作者通过线性化分析树将语法分析问题转换为序列-到-序列学习任务。事实证明,注意力机制在这项工作中更具数据效率。更进一步的参考输入序列,是在特定条件下,将输入的词或子序列直接复制到输出序列[102],这在诸如对话生成和文本摘要的任务中是有用的。在解码期间的每个时间步骤选择复制或生成[103]。
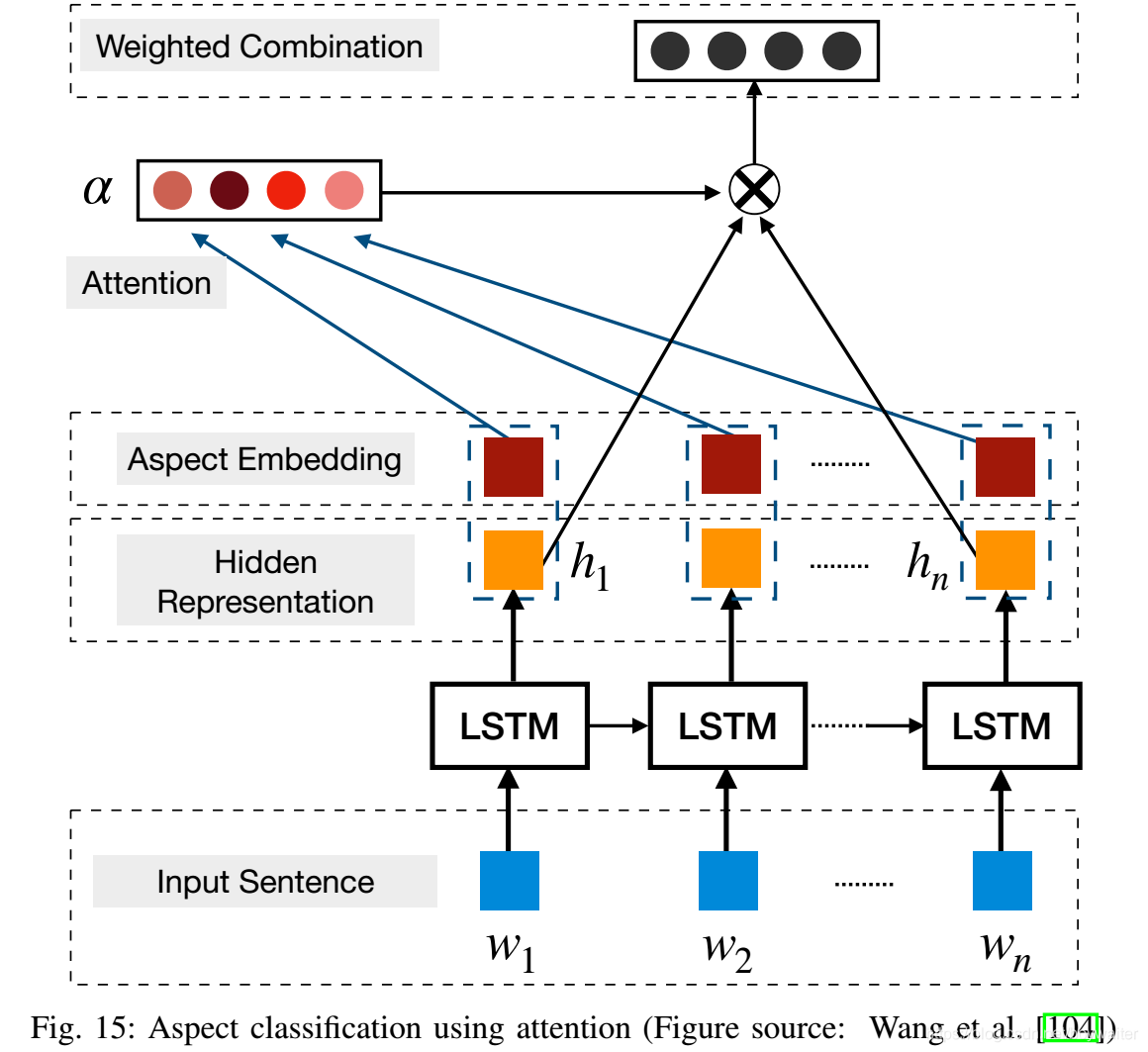
在基于aspect的情感分析中,Wang等[104]提出了一种基于注意力的解决方案,他们利用aspect嵌入为分类过程提供额外支持(图15)。注意力模块关注于句子的选择区域,它会影响要分类的aspect。这可以在图16中看到,其中,对于(a)中的aspect “service”,注意力模块动态地关注短语“fastest delivery times”,对于(b)中的aspect “food”,识别出句子中的多个关键点,包括“tasteless”和“too sweet”。最近,Ma等[105]在LSTM中增加了层次注意力机制,包含目标层面注意力和句子层面注意力,以利用常识知识进行基于aspect的情感分析。

另一方面,Tang等[106]采用基于存储网络(也称为MemNet [107])的解决方案,该解决方案采用多跳注意。记忆上的多个注意力计算层可以改善对记忆中的大多数信息区域的查找,并进而辅助分类。他们的工作是这个领域的最先进技术。
鉴于注意力模块的直观适用性,NLP研究人员仍在积极研究它们,并将其用于越来越多的应用。
V. 递归神经网络
递归神经网络代表了建模序列的自然方式。然而,可以说,语言呈现出自然的递归结构,其中词和子短语以层次结构组合成短语。这种结构可以表示为成分句法分析树。因此,树形结构模型可以更好地利用句子结构的这种句法解释[4]。具体地,在递归神经网络中,句法分析树中的每个非终端节点的表示由其所有子节点的表示确定。
A.基本模型
本节描述递归神经网络的基本结构。如图17和18所示(好像没什么区别啊),网络
g
g
g定义了关于短语或词(
b
,
c
b, c
b,c或
a
,
p
1
a, p_1
a,p1)的表示的合成函数,以计算更高层次的短语(
p
1
p_1
p1或
p
2
p_2
p2)的表示。所有节点的表示采用相同的形式。
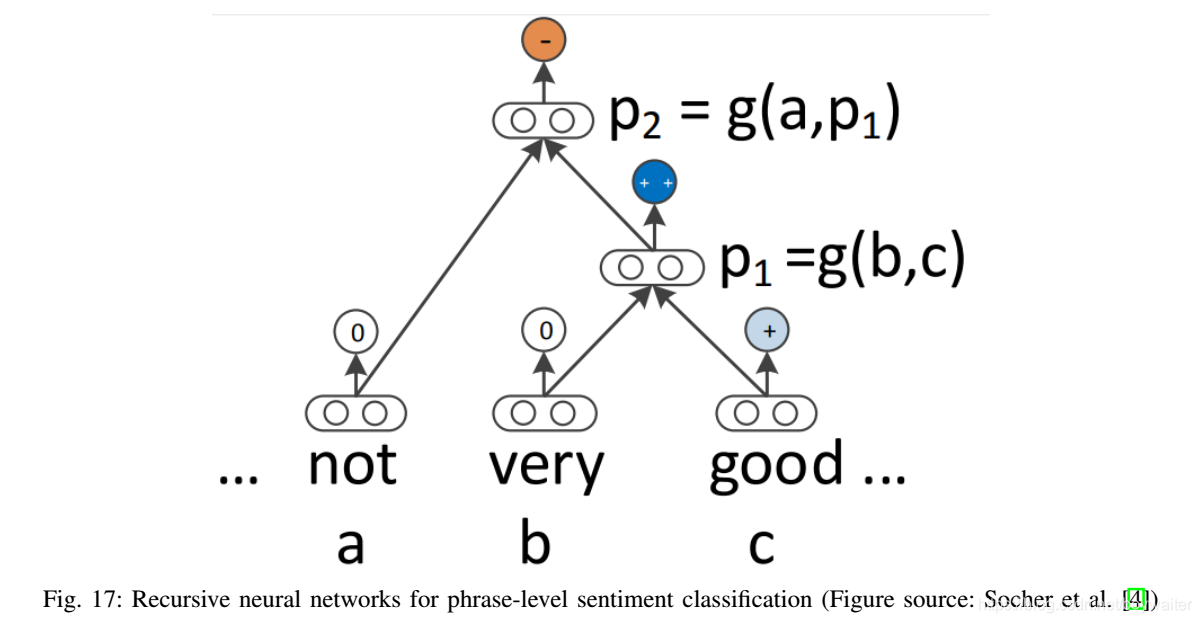
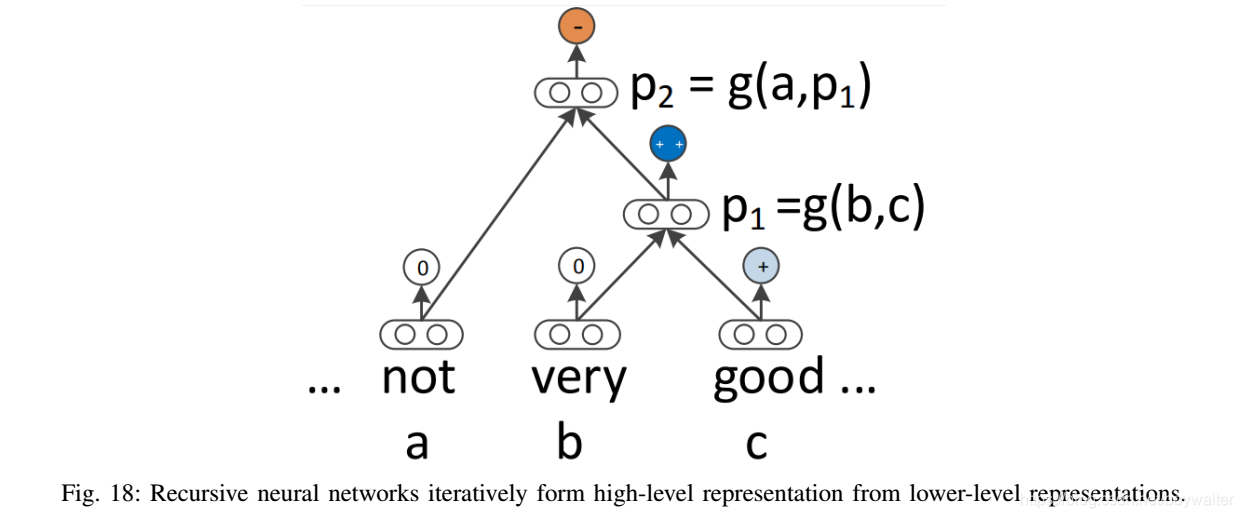
在[4]中,作者描述了该模型的多种变体。在其最简单的形式中,
g
g
g定义为:
p
1
=
tanh
(
W
[
b
c
]
)
,
p
2
=
tanh
(
W
[
a
p
1
]
)
,
p_1=\tanh(\textbf{W}\left [\begin{matrix}b\\c\end{matrix}\right]), p_2=\tanh(\textbf{W}\left [\begin{matrix}a\\p_1\end{matrix}\right]),
p1=tanh(W[bc]),p2=tanh(W[ap1]),
其中每个节点表示为一个
D
D
D-维向量,
W
∈
R
D
×
2
D
\textbf{W}\in \mathcal{R}^{D\times 2D}
W∈RD×2D。
另一个变体是MV-RNN[108]。想法是将每个词和短语既表示为矩阵也表示为向量。当两个成分组合时,其中一个成分的矩阵乘以另一个成分的向量:
p
1
=
tanh
(
W
[
C
b
B
c
]
)
,
P
2
=
tanh
(
W
M
[
B
C
]
)
,
p_1=\tanh(\textbf{W}\left [\begin{matrix}C_b\\B_c\end{matrix}\right]), P_2=\tanh(\textbf{W}_M\left [\begin{matrix}B\\C\end{matrix}\right]),
p1=tanh(W[CbBc]),P2=tanh(WM[BC]),
其中
b
,
c
,
p
1
∈
R
D
,
B
,
C
,
P
1
∈
R
D
×
D
,
W
M
∈
R
D
×
2
D
b,c,p_1\in \mathcal{R}^D, B,C,P_1\in \mathcal{R}^{D\times D}, \textbf{W}_M\in \mathcal{R}^{D\times 2D}
b,c,p1∈RD,B,C,P1∈RD×D,WM∈RD×2D。与基本模型相比,MV-RNN用矩阵作为合成函数的参数,参数对应于成分。
RNTN(递归神经张量网络)的提出是为了在输入向量之间引入更多的交互,而不会像MV-RNN那样使参数的数量特别大。RNTN的定义是:
p
1
=
tanh
(
[
b
c
]
T
V
[
1
:
D
]
[
b
c
]
+
W
[
b
c
]
)
,
p_1=\tanh(\left [\begin{matrix}b\\c\end{matrix}\right]^\textrm{T}V^{[1:D]}\left [\begin{matrix}b\\c\end{matrix}\right]+\textbf{W}\left [\begin{matrix}b\\c\end{matrix}\right]),
p1=tanh([bc]TV[1:D][bc]+W[bc]),
其中
t
e
x
t
b
f
V
∈
R
2
D
×
2
D
×
D
textbf{V}\in \mathcal{R}^{2D\times 2D\times D}
textbfV∈R2D×2D×D是定义多个双线性形式的张量。
B. 应用
递归神经网络的一个自然应用是句法分析[10]。在短语表示上定义评分函数以计算该短语的合理性。集束搜索通常用于搜索最佳树。该模型采用max-margin objective(最大边际目标)[109]进行训练。
基于递归神经网络和句法分析树,Socher等[4]提出了一个短语级情感分析框架(图19),为树中每个节点分配一个情感标签。
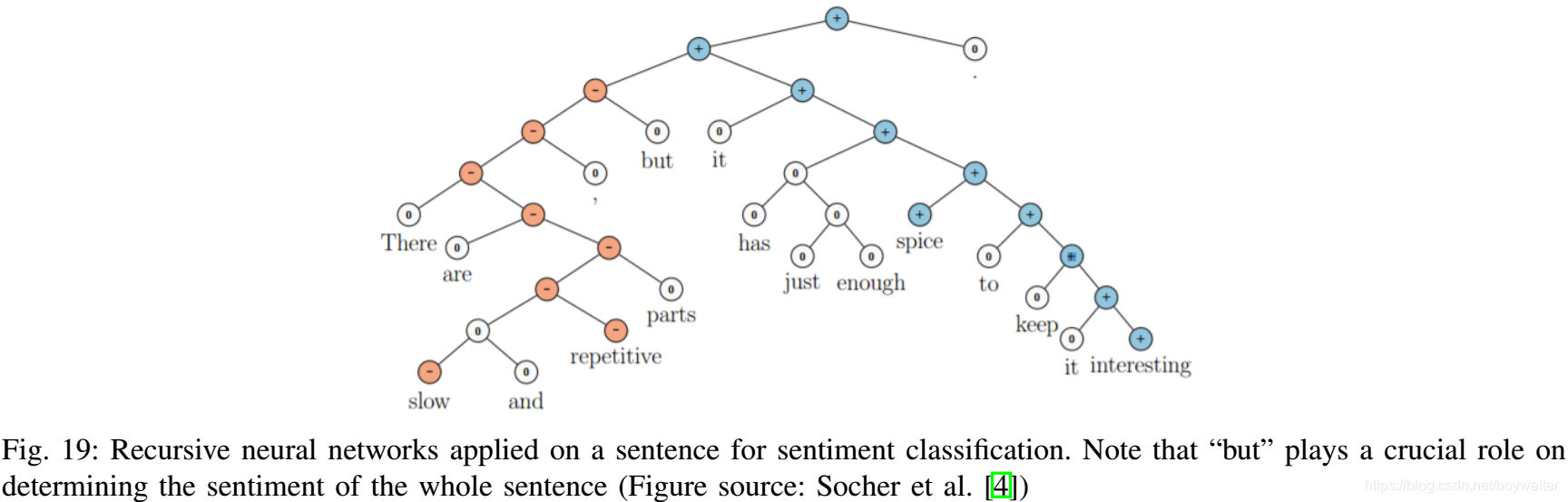
Socher等[108]通过为包括两个项的最小成分构建单个合成语义,分类句子中的名义之间的语义关系,如因-果关系或主题-消息分类。Bowman等[110]提出用递归神经网络对句子之间的逻辑关系进行分类。两个句子的表示被送入另一个神经网络以进行关系分类。递归单元的基本版本和张量版本在文本蕴涵数据集中都具有竞争性。
为了避免梯度消失问题,也将LSTM单元用于树结构[111]。因为观察到情感分析和句子相关性测试的明显改善,在线性LSTM模型上显示出句子表示的改进。
VI. 深度增强模型和深度无监督学习
A.序列生成中使用强化学习
强化学习(reinforcement learning)是一种训练代理(agent)在获得奖励(reward)之前执行离散行动(action)的方法。在NLP中,有关语言生成的任务有时可以被视为强化学习问题。
在其原始形式中,给定当前隐藏状态和之前符号的情况下,RNN语言生成器一般通过最大化事实序列中每个符号的似然来训练。该训练方案被称为“教师强制”,在每个生成(损失评估)步骤中为生成器提供真实符号序列。在测试时,真实符号由模型本身生成的符号替换。训练和推理之间的差异,称为“暴露偏差”[112,113],随着生成的序列快速累积误差。
当训练自回归语言生成模型时,词级最大似然策略的另一个问题是训练目标与测试度量不同。目前尚不清楚如何使用词一级的训练策略优化用于评估这些任务(机器翻译,对话系统等)的基于n-gram重叠的指标(BLEU,ROUGE)。根据经验,用词级最大似然训练的对话系统也倾向于产生dull和短视的反应[114],而文本摘要倾向于产生不连贯或重复的摘要[103]。
强化学习提供了在一定程度上解决上述问题的前景。为了直接优化不可微的评估指标,Ranzato等[113]应用REINFORCE算法[115]来训练基于RNN的模型,用于若干序列生成任务(例如,文本摘要,机器翻译和图像字幕),比之前的监督学习方法有改进。在这样的框架中,生成模型(RNN)被视为代理,其与外部环境(在每个时间步骤看到的输入词和上下文向量)相互作用。此代理的参数定义了一个策略,其执行导致代理选择一个动作,该动作指的是在每个时间步骤预测序列中的下一个词。在采取行动后,代理更新其内部状态(RNN的隐藏单元)。一旦代理到达序列的末尾,它就会获得奖励。此奖励可以是针对特定任务定制的任何开发人员定义的度量标准。例如,Li等[114]根据是否易于回答,信息流和语义连贯性,为生成的句子定义了3个奖励。
强化学习有两个众所周知的缺点。为了使强化学习易于处理,需要仔细处理状态和动作空间[116,117],它们最终可能限制模型的表达能力和学习能力。其次,训练奖励函数的需要使得这些模型难以在运行时进行设计和测量[118,119]。
序列级监督的另一种方法是使用对抗训练技术[120],其中语言生成器的训练目标是欺骗判别器,判别器用以区分生成序列和真实序列。生成器 G G G和判别器 D D D在最小-最大游戏(min-max game)中联合训练,理想的目标是,使得 G G G无法区分生成序列与真实序列。这种方法可以被视为GAN(生成对抗网络)[120]的变体,其中 G G G和 D D D根据某些刺激调节(例如,图像标题任务中的源图像)。在实践中,上述方案可以在具有策略梯度的强化学习范式下实现。对于对话系统,判别器类似于人类图灵测试人员,他们区分人类和机器生成的对话[121]。
B.无监督的句子表示学习
与词嵌入类似,句子的分布式表示也可以用无监督的方式学习。这种无监督学习的结果是“句子编码器”,它将任意句子映射到可以表示其语义和句法属性的固定大小的向量。通常必须为学习过程定义一个辅助任务。
类似于用于学习词嵌入的skip-gram模型[8],提出了用于学习句子表示的是skip-thought模型[122],其辅助任务是基于给定句子预测两个相邻句子(之前和之后) 。seq2seq模型用于此学习任务。一个LSTM将句子编码为向量(分布式表示)。另外两个LSTM解码这种表示以生成目标序列。使用标准的seq2seq训练过程。训练完成之后,编码器可以被视为通用特征提取器(同时也学习了词嵌入)。
Kiros等[122]在一系列句子分类任务上验证了学到的句子编码器的质量,用基于静态特征向量的简单线性模型显示了其竞争力。然而,句子编码器也可以在监督学习任务中作为分类器的一部分进行微调。Dai和Le[123]研究了使用解码器重建编码的句子本身,它类似于自编码器[124]。
在训练LSTM编码器时,语言建模也可以用作辅助任务,其中监督信号来自下一个符号的预测。Dai和Le [123]进行了一组实验,用各种任务中学到的参数初始化LSTM模型。实验表明,对大型无监督语料库中的句子编码器进行预训练比仅预训练词嵌入产生更好的准确性。此外,预测下一个符号是比重建句子本身更糟糕的辅助目标,因为LSTM隐藏状态只负责一个相当短期的目标。
C.深度生成模型
最近在生成逼真图像方面的成功推动了一系列将深度生成模型应用于文本数据的努力。这类研究的前景是发现自然语言的丰富结构,同时从潜在的编码空间生成逼真的句子。在本节中,我们回顾最近通过变分自编码器(VAE)[125]和生成式对抗网络(GAN)实现这一目标的研究[120]。
标准句子自编码器,如上一节所述,不会对潜在空间施加任何约束,因此,当从任意潜在表示生成真实句子时它们会失败[126]。这些句子的表示通常可能占据隐藏空间中的一个小区域,隐藏空间中的大多数区域不一定映射到现实句子[127]。它们不能用于为句子分配概率或对新句子抽样[126]。
VAE对隐藏编码空间强加了先验分布,从而可以从模型中提取适当的样本。它通过用学到的后验识别模型替换确定性编码器函数来修改自编码器架构。该模型由编码器和生成器网络组成,编码器和生成器网络分别将数据样本编码为潜在表示并从潜在空间生成样本。通过在生成模型下最大化观察数据的对数似然的变分下界来训练它。
Bowman等[126]提出了一种基于RNN的变分自编码器生成模型,该模型结合了整个句子的分布式潜在表示(图20)。与简单RNN语言模型不同,该模型使用明确的全局句子表示。来自这些句子表示的先验的样本产生了多样且格式良好的句子。
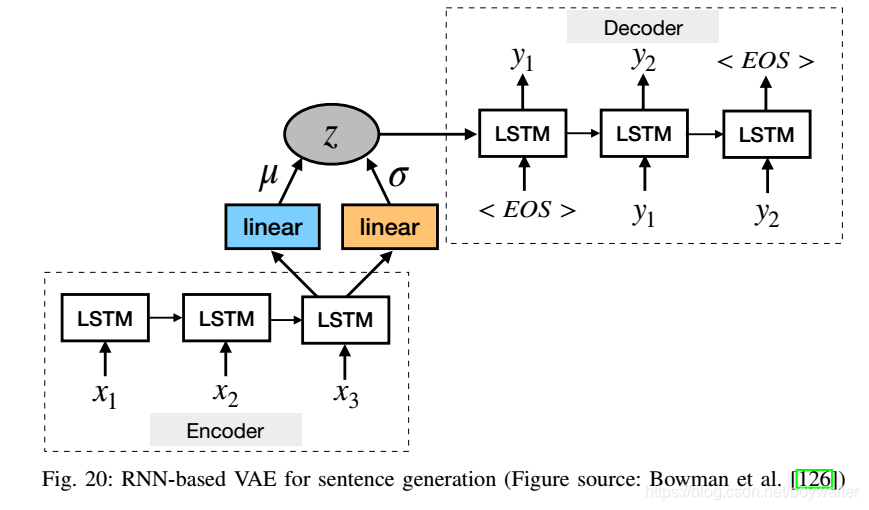
Hu等[128]提出生成句子,其属性通过学习具有指定语义的disentangled潜在表示来控制。作者用一组结构化变量增强了VAE中的潜在编码,每个变量都针对句子的一个显著且独立的语义特征。该模型包含VAE和属性判别器,其中VAE组件训练生成器重建真实句子以生成似是而非的文本,而判别器迫使生成器产生与结构化编码一致的属性。Hu等[128]展示了,当在大量无监督句子和少量标注句子上训练时,该模型能够根据英语的两个主要属性——时态和sentiment——产生合理的句子。
GAN是另一类由两个竞争网络组成的生成模型。生成神经网络将潜在表示解码为数据实例,同时教导判别网络以区分真实数据分布的实例和由生成器产生的合成实例。GAN没有明确地表示真实的数据分布 p ( x ) p(x) p(x)。
Zhang等[127]提出了一个框架,利用LSTM和CNN进行对抗性训练,以生成真实的文本。潜在编码 z z z在每个时间步骤被送入LSTM生成器。CNN充当二元句子分类器,区分真实数据和生成的样本。将GAN应用于文本的一个问题是来自判别器的梯度不能通过离散变量适当地反向传播。在[127]中,通过在词嵌入空间中每次“软”进行词预测来解决该问题。Yu等[129]建议通过将生成器建模为随机策略来绕过这个问题。奖励信号来自在完整序列上判断的GAN判别器,并利用蒙特卡罗搜索传递回中间状态 - 动作步骤。
对深层生成模型的评估一直很具挑战性。对于文本,可以从一组固定的语法创建oracle训练数据,然后根据生成的样本是否(或何种程度)与预定语法一致来评估生成模型[130]。另一种策略是在大量未见的测试数据上评估样本的BLEU分数。生成与未见的真实数据类似的句子的能力被认为是质量的衡量标准[129]。
VII. 记忆增强网络
注意机制存储编码器的一系列隐藏向量,允许解码器在每个符号的生成期间访问该向量。这里,编码器的隐藏向量可以看作模型的“内部记忆”的条目。最近,人们对将神经网络与某种形式的记忆耦合的兴趣激增,模型可以与之交互。
在[107]中,作者提出了QA任务的记忆网络。在综合QA中,为模型提供了一系列陈述(记忆条目)作为问题的潜在支持事实。该模型学会根据问题和先前检索的记忆一次从记忆中检索一个条目。在大规模的实际QA中,(主语,关系,宾语)三元组形式的大量常识知识被用作记忆。Sukhbaatar等[131]扩展了这项工作并提出了端到端记忆网络,其中通过注意机制以“软”方式检索记忆条目,从而实现端到端训练。从记忆中检索信息的多轮(跳)被证明对于良好的性能是必不可少的,并且该模型能够检索和推理几个支持事实以回答特定问题(图21)。Sukhbaatar等[131]还展示了该模型用于语言建模的特殊用法,其中句子中的每个词都被视为记忆条目。通过多跳,该模型产生的结果与深度LSTM模型相当。
此外,动态记忆网络(DMN)[97]通过采用神经网络模型用于输入表示,注意和应答机制,改进了先前基于记忆的模型。由此产生的模型适用于各种NLP任务(QA,词性标注和情感分析),因为每个任务都可以转换为<memory,question,answer>三元组格式。Xiong等[141]将相同的模型应用于视觉QA并证明记忆模块适用于视觉信号。
VIII.不同模型在不同NLP任务中的表现
我们在表II-VII中总结了,近年来在7个主要NLP主题上,标准数据集上开发的一系列深度学习方法的表现。我们的目标是向读者展示领域中使用的常见数据集以及使用不同模型的最新结果。
A. 词性标注
WSJ-PTB(Penn Treebank数据集的华尔街日报部分)语料库包含117万个符号,并已广泛用于开发和评估词性标注系统。Gimenez和Marquez [132]在七个词窗口中使用基于手动定义的特征的one-against-all(在深度模型广泛使用之前,SVM确实是万夫莫敌)SVM,其中一些基本的n-gram模式根据评估形成二元特征,例如:“前一个词是the”, “前两个标签是DT NN”等。词性标注问题的一个特征是相邻标签之间的强依赖性。通过简单的从左到右标记方案,此方法仅通过特征工程建模相邻标记之间的依赖关系。为了减少特征工程,Collobert等[5]使用多层感知器,且仅依靠词窗口内的词嵌入。[5]还证明了结合CRF是有效的。Santos和Zadrozny [32]将词嵌入与字符嵌入连接起来,以更好地利用形态线索。在[32]中,作者没有考虑CRF,但由于确定词的标注是根据上下文窗口来决定,因此可以看出依赖性是隐式建模的。Huang等[133]将词嵌入和手动设计的词一级特征连接起来,并采用双向LSTM来模拟任意长的上下文。一系列ablation分析(例如,通过只使用双向LSTM,只使用CRF,两个都使用,来分析每个因素是否有效果)表明,双向性和CRF都提高了性能。Andor等[134]展示了一种基于转换(transition-based)的方法,通过简单的前馈神经网络产生有竞争力的结果。当把DMN [97]应用于序列标记任务时,通过将每个RNN隐藏状态视为记忆条目,可以多次访问上下文,每次聚焦于上下文的不同部分。
B.句法分析
有两种类型的句法分析:依存分析,它将各个词用它们之间的关系连接起来,成分分析,它迭代地将文本分成子短语。基于转换的方法是一种流行的选择,因为它们关于句子长度是线性的。句法分析器做出一系列决定,从缓冲区顺序读取词,并将它们逐步组合成句法结构[135]。在每个时间步骤,根据包含可用树节点的栈,包含未读词的缓冲区和所获得的依存弧集合来做出决定。Chen和Manning[135]用一个隐藏层的神经网络建模了每个时间步的决策。输入层包含某些词的嵌入,词性标注和依存弧标签,分别来自栈,缓冲区和一依存弧标签集合。
Tu等[63]采用具有两个隐藏层的更深层模型扩展了Chen和Manning[135]的工作。但是,Tu等[63],Chen和Manning[135]都依赖于从分析器状态中选择手动特征,而且只考虑了有限数量的最近符号。Dyer等[137]提出了堆栈-LSTM来建模任意长的历史。堆栈的结束指针可以改变位置,因为栈中的树节点可以压栈和出栈。Zhou等[138]综合集束搜索和对比学习,以便更好地进行优化。
基于转换的模型也适用于成分分析。Zhu等[140] (NEUNLP的工作)根据特征做出每个转换动作,这些特征包括堆栈和缓冲区顶部几个词的词性标注和成分标签。通过用标签的线性序列唯一地表示分析树,Vinyals等[101]将seq2seq学习方法应用于此问题。
C.命名实体识别
CoNLL 2003是NER的标准英语数据集,主要有四种类型的命名实体:人员(person),位置(location),组织(organization)和其他实体(miscellaneous entities)。词典对NER非常有用。Collobert等[5]首先通过地名词典功能增强的神经结构获得了具有竞争力的结果。Chiu和Nichols [143]将词典特征、字符嵌入和词嵌入连接起来,作为双向LSTM的输入。另一方面,Lample等[88]只依靠字符和词嵌入,以及大型无监督语料库上预训练的嵌入,在不使用任何词典的情况下取得了有竞争力的结果。与词性标注类似,CRF也提高了NER的性能,如[88]中的比较所示。总的来说,对于与结构化预测相关的NLP问题,带有CRF的双向LSTM都是强模型。
Passos等[142]提出修改skip-gram模型,以更好地利用相关词典信息学习实体类型相关的词嵌入。Luo等[144]联合优化实体和将实体链接到知识库。Strubell等[145]建议使用扩张的卷积,该卷积通过每次跳过某些输入,在更宽的有效输入宽度上定义,以便更好地进行并行化和上下文建模。该模型训练速度明显加快,同时保持准确性。
D.语义角色标记
语义角色标记(SRL)旨在发现句子中每个谓词的谓词-参数结构。对于每个目标动词(谓词),句子中所有可以作为动词的语义角色的成分都被识别出来。典型的语义参数包括Agent,Patient,Instrument等,以及诸如Locative,Temporal,Manner,Cause等的修饰语(adjunct)[147]。表V显示了CoNLL 2005和2012数据集上不同模型的性能。
传统的SRL系统由几个阶段组成:生成一个分析树,识别哪个分析树节点代表给定动词的参数,最后对这些节点进行分类以确定相应的SRL标签。每个分类过程通常需要提取大量特征并将其输入统计模型[5]。
给出一个谓词,Tackstrom等[146]通过一系列基于分析树的特征,对实现了成分跨度及其作为谓词的可能角色。他们提出了一种可以进行有效推理的动态规划算法。Collobert等[5]通过分析以附加查找表形式提供的信息来增强卷积神经网络,获得了同样好的结果。Zhou和Xu [147]提出使用双向LSTM来模拟任意长的上下文,这证明在没有任何分析树信息的情况下是成功的。He等[148]通过引入高速连接[154],更先进的正则化和多个专家的集合,进一步扩展了这项工作。
E.情感分类
斯坦福情感树库(SST)数据集包含从电影评论网站烂番茄(Rotten Tomatoes)中获取的句子。SST由Pang和Lee [155]提出,随后由Socher等[4]扩展。标注模式启发了一个新的情感分析数据集,称为CMU-MOSI,在多模设定中研究情感[156]。[4]和[111]都是依赖于成分分析树的递归网络。其差异表明LSTM相对于简单RNN对句子建模更有效。另一方面,tree-LSTM比线性双向LSTM表现更好,这意味着树结构可以更好地表示自然句子的句法属性。Yu等[150]提出用情感词典改进预训练的词嵌入,观察到基于[111]的改进结果。
Kim [45]和Kalchbrenner等[44]都使用了卷积层。模型[45]类似于图6中的模型,而Kalchbrenner等[44]通过将k-max池化层与卷积层交织,以分层方式构建模型。
F.机器翻译
基于短语的SMT框架[164]将翻译模型分解为源语句和目标语句中匹配短语的翻译概率。Cho等[77]提出用RNN编码器 - 解码器学习源短语到相应目标短语的翻译概率。这种为短语对评分的方案改善了翻译性能。另一方面,Sutskever等[69]为4层LSTM seq2seq模型的SMT系统生成的前1000个最佳候选翻译重新评分。完全取消传统的SMT系统,Wu等[151]训练了一个深层LSTM网络,其中包含8个编码器和8个解码器层,以及残差连接和注意力连接。然后,Wu等[151]通过使用强化学习直接优化BLEU分数来改进模型,但是发现这种方法对BLEU分数的改善并没有反映在翻译质量的人类评价中。最近,Gehring等[152]提出了一种基于CNN的seq2seq机器翻译学习模型。输入中每个词的表示由注意力机制并行风格的CNN计算得到。解码器状态也由CNN用已经生成的词确定。Vaswani等[153]提出了一种基于自我注意力的模型,并完全取消了卷积和循环。
G. 问答
QA问题有多种形式。有些依靠大型知识库来回答开放式域问题,而其他人则根据几个句子或段落(阅读理解)回答问题。对于前者,我们列出(参见表VIII)对[157]中介绍的大规模QA数据集上进行的几个实验,其中14M常识知识三元组被视为知识库。每个问题都可以通过单关系查询来回答。对于后者,我们使用(参见表VIII) b A b I bAbI bAbI的合成数据集,要求模型在多个相关事实上推理以产生正确答案。该数据集包含20个合成任务,用于测试模型检索相关事实和在这些事实上进行推理的能力。每项任务都侧重于不同的技能,例如基本共引(basic coreference)和大小推理(size reasoning)。
学习回答单关系查询的核心问题是在数据库中找到单个支撑事实。Fader等[157]提出通过学习一个词典来解决这个问题,该词典基于问题解释数据集,将自然语言模式映射到数据库概念(实体,关系,问题模式)。Bordes等[158]将问题和知识库三元组作为稠密向量嵌入,并根据内积对其进行评分。
Weston等[107]采用类似的方法,通过将知识库视为长期记忆,记忆网络的框架中解决问题。在 b A b I bAbI bAbI数据集上,Sukhbaatar等[131]通过令训练过程与实际支撑事实无关,改进了原始记忆网络模型[107],而Kumar等[97]使用神经序列模型(GRU)代替[131]和[107]中的神经词袋模型来嵌入记忆。
H.对话系统
已经开发了两种类型的对话系统:基于生成的模型和基于检索的模型。
在表IX中,Twitter对话三元组数据集通常用于评估基于生成的对话系统,包含3轮Twitter对话实例。常用的评估指标是BLEU [165],尽管人们普遍认为大多数自动评估指标对于对话评估并不完全可靠,并且通常需要额外的人工评估。Ritter等[159]采用基于短语的统计机器翻译(SMT)框架将消息“翻译”为其适当的响应。Sordoni等[160]重新排序SMT用上下文敏感的RNN编码器 - 解码器框架产生的1000个最佳响应,观察到了实质性收益。Li等[161]报告了用最大互信息训练目标替换传统最大对数似然训练目标的结果,以努力产生有趣和多样化的响应,这两者都在4层LSTM编码器 - 解码器框架上进行测试。
响应检索任务被定义为从候选响应库中选择最佳响应。这种模型可以通过recall 1@k度量来评估,其中真实响应与k-1个随机响应混合。Ubuntu对话数据集是通过从在线聊天室中抓取多轮Ubuntu故障排除对话来构建的[92]。Lowe等[92]使用LSTM对消息和响应进行编码,然后使用两个句子嵌入的内积来对候选进行排名。
Zhou等[163]提出通过在句子级CNN嵌入之上使用LSTM编码器来更好地利用人类对话的多轮性质,类似于[166]。Dodge等[162]将问题转移到记忆网络的框架中,其中过去的对话被视为记忆,最新的话语被视为要回答的“问题”。作者表明,使用简单的神经词汇嵌入句子可以产生有竞争力的结果。
IX. 结论
深度学习提供了一种利用大量计算和数据,而利用很少量手工工程的方法[85]。通过分布式表示,多种深度模型已成为NLP问题的最先进方法。监督学习是近期NLP深度学习研究中最受欢迎的实践。然而,在许多现实世界的场景中,我们只有未标记的数据,这些数据需要先进的无监督或半监督方法。如果在测试模型时某些特定类别缺少标记数据或出现新类别,则应采用零样本学习(zero-shot learning)等策略。这些学习方案仍处于发展阶段,但我们期望基于深度学习的NLP研究能够朝着更好地利用未标记数据的方向发展。我们预计这种趋势会随着更多更好的模型设计而继续。我们期望看到更多采用强化学习方法的NLP应用,例如对话系统。我们还期望看到更多关于多模态学习的研究[167],因为在现实世界中,语言通常基于其他信号(或与之相关)。
最后,我们期望看到更多深度学习模型,其内部记忆(从数据中学到的自下而上的知识)通过外部记忆(从知识库中继承的自上而下的知识)得到丰富。耦合符号(coupling symbolic)和次符号(sub-symbolic)AI将是从自然语言处理到自然语言理解的道路上前进的关键。事实上,依靠机器学习很有可能根据过去的经验做出“好的猜测”,因为次符号方法编码相关性,他们的决策过程是概率性的。然而,自然语言理解需要的远不止于此。用诺姆乔姆斯基的话来说,“你不会通过获取大量数据,将它们扔进计算机并对它们进行统计分析来获得科学中的发现:这不是你理解事物的方式,你必须有理论上的见解”。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









