







原始论文:https://www.ijcai.org/Proceedings/2020/0526.pdf
相关博客
【自然语言处理】【文本风格迁移】基于向量分解的非并行语料文本风格迁移
【自然语言处理】【文本风格迁移】基于风格实例的文本风格迁移
一、简介
- 风格迁移的目标是,保持句子语义内容不变的情况下,赋予句子不同的风格。由于缺乏大规模并行语料,近期主要的研究工作是集中在无监督迁移上的。
- 文学理论和机器学习研究均表明内容和风格一定程度上是耦合的,这导致了内容保持和风格准确两者间的矛盾。
- 目前主要有两种无监督风格迁移的范式
- 一种是基于分解的范式。这种方法显式地从内容中分离风格,然后合并一个新的风格表示。但是,由于分解的难度,指定目标风格中通常会带一些不期望的内容。因此,该方法通常会获得一个高风格迁移准确率,但是很难保持全部的源内容。
- 另一种范式是基于注意力结构来保证所有单词级别的源信息。不同于分解方法,该方法会强迫模型专注在风格独立的单词上。但是,这样的方法倾向于过度强调内容保持,导致风格准确性不理想。
- 语言学研究表明,风格的综合表征能够通过多个实例中的广泛比较来更好的观察到。受这个观点的启发,论文提出了一种称为 StyIns \text{StyIns} StyIns的风格实例支持方法,从而减轻上面的矛盾。
二、方法概述
2.1 问题形式化
假设具有 M M M个数据集 { D i } i = 1 M \{D_i\}_{i=1}^M {Di}i=1M,在 D i D_i Di中的句子共享相同风格 s i s_i si。给定一个具有源风格 s i s_i si的任意句子 x x x,风格迁移的目标是将 x x x改写为具有风格 s j s_j sj的新句子 y y y,并保持其主要内容。
2.2 概述
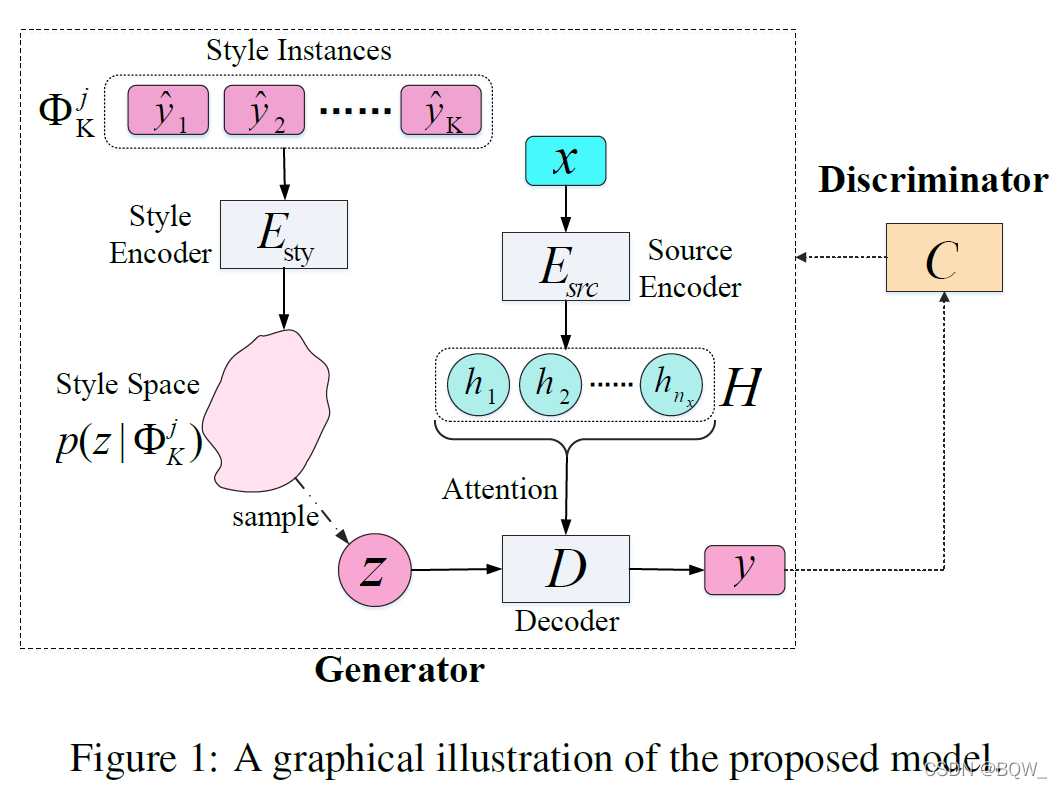
该方法的核心思路:使用一些具有某个风格的句子来获得表示该风格的向量,这些具有相同风格的句子称为风格实例。
设存在一个句子集合
Φ
K
j
=
{
y
^
}
k
=
1
K
⊂
D
j
\Phi_{K}^j=\{\hat{y}\}_{k=1}^K\sub D_j
ΦKj={y^}k=1K⊂Dj,也就是这些句子共享风格
s
j
s_j
sj,称这些句子为风格实例。利用这些风格实例来构造一个隐变量
z
z
z,来表示风格这个复杂的概念。假设同一个风格的句子间条件独立,可以推断出一个风格迁移的参数化表达式
p
(
y
∣
x
,
Φ
K
j
)
=
∫
p
(
y
,
z
∣
x
,
Φ
K
j
)
d
z
=
∫
p
(
y
∣
x
,
z
)
∗
p
(
z
∣
Φ
K
j
)
d
z
=
E
z
∼
p
(
z
∣
Φ
K
j
)
[
p
(
y
∣
x
,
z
)
]
(1)
\begin{align} p(y|x,\Phi_K^j)&=\int p(y,z|x,\Phi_K^j)dz \\ &=\int p(y|x,z)*p(z|\Phi_K^j)dz \\ &=\mathbb{E}_{z\sim p(z|\Phi_K^j)}[p(y|x,z)] \end{align} \tag{1}
p(y∣x,ΦKj)=∫p(y,z∣x,ΦKj)dz=∫p(y∣x,z)∗p(z∣ΦKj)dz=Ez∼p(z∣ΦKj)[p(y∣x,z)](1)
等式(1)中
p
(
y
∣
x
,
Φ
K
j
)
p(y|x,\Phi_K^j)
p(y∣x,ΦKj)表示给定风格实例
Φ
K
j
\Phi_K^j
ΦKj和待风格迁移样本
x
x
x,输出风格迁移后样本
y
y
y的概率。
根据等式(1)的指导,使用一个称为源编码器的双向 LSTM \text{LSTM} LSTM编码器,称为 E s r c ( x ) E_{src}(x) Esrc(x)。源编码器 E s r c ( x ) E_{src}(x) Esrc(x)负责将句子 x x x编码为隐藏状态 H H H。使用一个记为 E s t y ( Φ K j ) E_{sty}(\Phi_K^j) Esty(ΦKj)的风格编码器,负责基于风格实例建模分布 p ( z ∣ Φ K j ) p(z|\Phi_K^j) p(z∣ΦKj)。使用一个称为 D ( H , z ) D(H,z) D(H,z)的解码器,其会基于 H H H和 z z z解码出风格迁移后的句子 y y y,其中 z z z是从 p ( z ∣ Φ K j ) p(z|\Phi_K^j) p(z∣ΦKj)中采样得到的。三个组件 E s r c ( x ) E_{src}(x) Esrc(x)、 E s t y ( Φ K j ) E_{sty}(\Phi_K^j) Esty(ΦKj)和 D ( H , z ) D(H,z) D(H,z)共同构成了整个文本风格迁移生成器 G ( x , Φ K j ) G(x,\Phi_K^j) G(x,ΦKj)。
总结: E s r c ( x ) E_{src}(x) Esrc(x)编码原始句子, E s t y ( Φ K j ) E_{sty}(\Phi_K^j) Esty(ΦKj)编码风格实例, D ( H , z ) D(H,z) D(H,z)解码风格迁移后句子。
四、隐风格空间学习
E s r c ( x ) E_{src}(x) Esrc(x)是一个双向LSTM, D ( H , z ) D(H,z) D(H,z)是一个基于注意力机制的LSTM解码器。因此,主要的问题是如何确定 E s t y ( Φ K j ) E_{sty}(\Phi_K^j) Esty(ΦKj)。
风格编码器 E s t y ( Φ K j ) E_{sty}(\Phi_K^j) Esty(ΦKj)使用风格实例作为输入,构建出一个隐风格空间,最终输出风格表示 z z z,该表示用于指导后续解码器的风格生成。先前的工作采用变分自编码器来构建隐空间。但是,变分自编码器会假设句子独立并将其分配到一个各向独立的高斯隐空间中。这种假设并不合理,维度独立的高斯分布表达能力不足,且相同风格的句子并不独立,而是共享一个全局的风格空间。
4.1 Generative Flow
简单来说,使用变分自编码器对句子进行编码并不是最优的,因此这里使用Generative Flow。
为了解决变分自编码器的问题,论文使用一种构建复杂分布的强力技术
generative flow, GF
\text{generative flow, GF}
generative flow, GF。简单来说,
GF
\text{GF}
GF通过应用一系列参数化映射函数
f
t
f_t
ft,将简单初始化隐变量
z
0
z_0
z0转换为复杂变量
z
T
z_T
zT:
z
t
=
f
t
(
z
t
−
1
,
c
)
,
z
0
∼
p
(
z
0
∣
c
)
,
t
∈
{
1
,
2
,
…
,
T
}
(2)
z_t=f_t(z_{t-1},c),z_0\sim p(z_0|c),t\in\{1,2,\dots,T\} \tag{2}
zt=ft(zt−1,c),z0∼p(z0∣c),t∈{1,2,…,T}(2)
其中,
c
c
c是给定的条件,
T
T
T是参数化映射函数的数量。
GF
\text{GF}
GF要求每个函数
f
t
f_t
ft都是可逆的、且可以计算雅克比行列式。经过转换后的最终分布的概率密度为
l
o
g
p
(
z
T
∣
c
)
=
l
o
g
p
(
z
0
∣
c
)
−
∑
t
=
1
T
l
o
g
d
e
t
∣
d
z
t
d
z
t
−
1
∣
(3)
log\;p(z_T|c)=log\;p(z_0|c)-\sum_{t=1}^Tlog\;det\Big|\frac{d_{z_t}}{d_{z_{t-1}}}\Big| \tag{3}
logp(zT∣c)=logp(z0∣c)−t=1∑Tlogdet∣
∣dzt−1dzt∣
∣(3)
目前,已经有许多
f
t
f_t
ft被提出。这里选择一个简单但有效的方法
IAF(Inverse Autoregressive Flow)
\text{IAF(Inverse Autoregressive Flow)}
IAF(Inverse Autoregressive Flow)。具体来说,有
[
m
t
,
o
t
]
←
g
t
(
z
t
−
1
,
c
)
,
σ
t
=
sigmoid
(
o
t
)
z
t
=
σ
t
⊙
z
t
−
1
+
(
1
−
σ
t
)
⊙
m
t
\begin{align} [m_t,o_t]\leftarrow g_t(z_{t-1},c),\sigma_t=\text{sigmoid}(o_t) \tag{4}\\ z_t=\sigma_t\odot z_{t-1}+(1-\sigma_t)\odot m_t \tag{5} \end{align}
[mt,ot]←gt(zt−1,c),σt=sigmoid(ot)zt=σt⊙zt−1+(1−σt)⊙mt(4)(5)
其中,
⊙
\odot
⊙是element-wise乘法,
g
t
g_t
gt是自回归网络。
注: g t g_t gt来自论文《Made: Masked autoencoder for distribution estimation》
这里介绍了如何将隐向量 z 0 z_0 z0转换为复杂隐变量 z T z_T zT,下面介绍 z 0 z_0 z0是怎么来的。
4.2 风格实例支持的隐空间
为了构建更具表达能力的隐空间,这里抛弃平均场假设,通过利用
K
K
K个风格实例
Φ
K
j
=
{
y
^
k
}
k
=
1
K
\Phi_K^j=\{\hat{y}_k\}_{k=1}^K
ΦKj={y^k}k=1K来构建隐空间,而不是单个实例。具体来说,将每个风格实例
y
^
k
\hat{y}_k
y^k输入至一个双向
LSTM
\text{LSTM}
LSTM,并获得向量表示为
v
k
v_k
vk。假设初始隐状态为
z
0
z_0
z0,且服从各向同性高斯分布
z
0
∼
p
(
z
0
∣
Φ
K
j
)
=
N
(
u
0
,
σ
0
2
I
)
u
0
≈
1
K
∑
k
=
1
K
v
k
,
σ
0
2
≈
1
K
−
1
∑
k
=
1
K
(
v
k
−
u
0
)
2
c
=
M
L
P
(
u
0
)
\begin{align} &z_0\sim p(z_0|\Phi_K^j)=\mathcal{N}(u_0,\sigma_0^2I) \tag{6}\\ &u_0\approx \frac{1}{K}\sum_{k=1}^K v_k,\sigma_0^2\approx\frac{1}{K-1}\sum_{k=1}^K(v_k-u_0)^2 \tag{7}\\ &c=MLP(u_0) \tag{8} \end{align}
z0∼p(z0∣ΦKj)=N(u0,σ02I)u0≈K1k=1∑Kvk,σ02≈K−11k=1∑K(vk−u0)2c=MLP(u0)(6)(7)(8)
其中,
z
0
z_0
z0的均值使用极大似然估计近似,方差使用无偏估计;
c
c
c是
Φ
K
j
\Phi_K^j
ΦKj的全局表示,其主要是使用
MLP
\text{MLP}
MLP进行计算,在公式(4)会使用
c
c
c。
4.3 风格编码器
随着上面两个模块的引入,就可以得到风格编码器 E s t y ( Φ K j ) E_{sty}(\Phi_K^j) Esty(ΦKj)的输出 z z z。具体来说,使用等式 ( 6 ) (6) (6)来采样 z 0 z_0 z0,并使用等式 ( 2 ) (2) (2)进行映射。将采样得到的 z z z与词向量进行拼接,再输入至解码器的每个时间步上。
五、无监督训练
给定源句子 x x x以及源风格 s i s_i si和目标风格 s j s_j sj,并给定两个风格实例集合 Φ K i \Phi_K^i ΦKi和 Φ K j \Phi_K^j ΦKj,使用下面的损失函数进行优化:
5.1 Reconstruction Loss
该损失函数已被不同的模型所使用,其需要模型基于源风格信号来重构给定的句子
L
r
e
c
o
n
=
−
l
o
g
p
G
(
x
∣
x
,
Φ
K
i
)
(9)
\mathcal{L}_{recon}=-log\;p_G(x|x,\Phi_K^i) \tag{9}
Lrecon=−logpG(x∣x,ΦKi)(9)
使用 x x x和与 x x x相同风格的风格实例 Φ K i \Phi_K^i ΦKi来重构 x x x。
5.2 Cycle Consistency Loss
该损失函数最先被用在图像风格迁移中,被用来增强内容保持,之后被应用在文本上。这里用不同风格的实例来实现源句子的两个方向转换
L
c
y
c
l
e
=
−
l
o
g
p
G
(
x
∣
y
,
Φ
K
i
)
,
y
←
G
(
x
,
Φ
K
j
)
(10)
\mathcal{L}_{cycle}=-log\;p_G(x|y,\Phi_K^i),y\leftarrow G(x,\Phi_K^j) \tag{10}
Lcycle=−logpG(x∣y,ΦKi),y←G(x,ΦKj)(10)
在每次迭代中,会提供不同的采样实例来帮助
StyIns
\text{StyIns}
StyIns更好的概况风格属性。
使用迁移后句子y和风格实例 Φ K i \Phi_K^i ΦKi来反向生成 x x x。
5.3 Adversarial Style Loss
由于没有任何并行语料,这里使用对抗训练来构建监督信号。具体来说,使用具有
M
+
1
M+1
M+1个类别的分类器作为判别器
C
C
C,用于分类输入句子的风格。生成器的目标是欺骗判别器
L
s
t
y
l
e
=
−
l
o
g
p
C
(
j
∣
y
)
(11)
\mathcal{L}_{style}=-log\;p_C(j|y) \tag{11}
Lstyle=−logpC(j∣y)(11)
其中,
p
C
(
j
∣
y
)
p_C(j|y)
pC(j∣y)表示判别器认为
y
y
y属于风格
j
j
j的概率,
L
s
t
y
l
e
\mathcal{L}_{style}
Lstyle用于更新生成器的参数。
判别器被交替优化
L
C
=
−
[
l
o
g
p
C
(
i
∣
x
)
+
l
o
g
p
C
(
i
∣
x
^
)
+
l
o
g
p
C
(
M
+
1
∣
y
)
]
(12)
\mathcal{L}_C=-[log\;p_C(i|x)+log\;p_C(i|\hat{x})+log\;p_C(M+1|y)] \tag{12}
LC=−[logpC(i∣x)+logpC(i∣x^)+logpC(M+1∣y)](12)
其中,
x
^
←
G
(
x
,
Φ
K
i
)
\hat{x}\leftarrow G(x,\Phi_K^i)
x^←G(x,ΦKi),
L
C
\mathcal{L}_C
LC用于更新判别器的参数。
损失函数 L s t y l e \mathcal{L}_{style} Lstyle是用于更新生成器的,使生成器能够更新的生成指定风格的句子;损失函数 L C \mathcal{L}_C LC是用于更新判别器,使判别器能够更加准确的判断句子的风格。二者交替进行训练。
六、半监督训练
前面介绍的方法主要是基于没有并行风格语料的情况。但是,当 x x x拥有并行语料 y ∗ ∉ Φ K i y^\ast \notin\Phi_K^i y∗∈/ΦKi,则可以通过最小化
− l o g p ( y ∗ ∣ x , Φ K j ) -log\;p(y^\ast|x,\Phi_K^j) −logp(y∗∣x,ΦKj)创建监督信号,从而辅助模型更好的完成风格迁移。
这里先推导一下 − l o g p ( y ∗ ∣ x , Φ K j ) -log\;p(y^\ast|x,\Phi_K^j) −logp(y∗∣x,ΦKj)的上界,
−
l
o
g
p
(
y
∗
∣
x
,
Φ
K
j
)
≤
E
q
(
z
∣
y
∗
,
Φ
K
j
)
[
l
o
g
p
(
y
∗
∣
z
,
x
)
]
−
K
L
[
q
(
z
∣
y
∗
,
Φ
K
j
)
∣
∣
p
(
z
∣
Φ
K
j
)
]
(12)
-log\;p(y^*|x,\Phi_K^j)\leq \mathbb{E}_{q(z|y^*,\Phi_K^j)}[log\;p(y^*|z,x)] - KL[q(z|y^*,\Phi_K^j)||p(z|\Phi_K^j)] \tag{12}
−logp(y∗∣x,ΦKj)≤Eq(z∣y∗,ΦKj)[logp(y∗∣z,x)]−KL[q(z∣y∗,ΦKj)∣∣p(z∣ΦKj)](12)
基于最小化这个上界,可以得到最终监督的Loss
L
s
u
p
e
r
=
−
α
∗
E
q
(
z
∣
y
∗
,
Φ
K
j
)
[
l
o
g
p
(
y
∗
∣
z
,
x
)
+
l
o
g
p
(
z
∣
Φ
K
j
)
−
l
o
g
q
(
z
∣
y
∗
,
Φ
K
j
)
]
+
β
∗
E
q
(
z
∣
Φ
K
j
)
[
−
l
o
g
p
(
y
∗
∣
z
,
x
)
]
\mathcal{L}_{super}=-\alpha*\mathbb{E}_{q(z|y^*,\Phi_K^j)}[log\;p(y^*|z,x) + log\; p(z|\Phi_K^j)-log\;q(z|y^*,\Phi_K^j)]+\beta*\mathbb{E}_{q(z|\Phi_K^j)}[-log\;p(y^*|z,x)]
Lsuper=−α∗Eq(z∣y∗,ΦKj)[logp(y∗∣z,x)+logp(z∣ΦKj)−logq(z∣y∗,ΦKj)]+β∗Eq(z∣ΦKj)[−logp(y∗∣z,x)]
其中,
α
\alpha
α和
β
\beta
β是超参数。
通过优化 L s u p e r \mathcal{L}_{super} Lsuper,同时最小化了 − l o g p ( y ∗ ∣ x , Φ K j ) -log\;p(y^\ast|x,\Phi_K^j) −logp(y∗∣x,ΦKj)的上边界和下边界。
七、整体训练流程
for 迭代数 do
采样源风格 s i s_i si和目标风格 s j s_j sj
从 D i D_i Di中采样风格实例 Φ K i \Phi_{K}^i ΦKi,从 D j D_j Dj中采样风格实例 Φ K j \Phi_{K}^j ΦKj
从 D i D_i Di中采样实例 x x x,其中 x ∉ Φ K i x\notin \Phi_K^i x∈/ΦKi
累加 L r e c o n \mathcal{L}_{recon} Lrecon、 L c y c l e \mathcal{L}_{cycle} Lcycle、 L s t y l e \mathcal{L}_{style} Lstyle
if y ∗ y^\ast y∗存在 do
累加 L s u p e r \mathcal{L}_{super} Lsuper
更新生成器 G G G的参数
for 判别器更新的step do
使用 L C \mathcal{L}_{C} LC更新生成器 C C C的参数
end for
end for


















 3376
3376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











