







Abstract
小样本学习对于生成从少数例子中泛化的模型至关重要。在这项工作中,我们发现度量缩放和度量任务条件对于提高少样本算法的性能很重要。我们的分析表明,简单的度量缩放完全改变了小样本算法参数更新的性质【不明白?】。度量缩放为 mini-Imagenet 5-way 5-shot 分类任务的某些度量提供了高达 14% 的准确度改进。我们进一步提出了一种简单有效的方法来调节任务样本集上的学习器,从而学习依赖于任务 (task-dependent) 的度量空间【如何学得度量空间?】。此外,我们提出并实证测试了一种基于辅助任务协同训练的实用端到端优化程序,以学习依赖于任务的度量空间。由此产生的基于任务相关的缩放度量的少样本学习模型在 mini-Imagenet 上达到了最先进的水平。我们在基于 CIFAR100 的本文中介绍的另一个小样本数据集上确认了这些结果。
我们的代码可在 https://github.co /ElementAI/TADAM 上公开获得。
1 Introduction
人类可以学会从几个例子中识别新的类别,即使是从一个[2]。 小样本学习最近引起了极大的关注 [33, 28, 29, 24, 17, 16],因为它旨在产生可以从少量标记数据中泛化的模型。 在少样本设置中,我们的目标是学习一个模型,该模型从一组支持示例(样本集)中提取信息,以预测查询集中实例的标签。 最近,这个问题已被重新定义为元学习框架 [22],即模型经过训练,以便给定样本集或任务,为该特定任务生成分类器【有点抽象???】。 因此,模型在训练阶段暴露于不同的任务(或情景),并在一组不重叠的新任务上进行评估 [33] 。
最近的两种方法在少样本学习领域引起了极大的关注:匹配网络 [33] 和原型网络 [28]。 在这两种方法中,样本集和查询集都嵌入了一个神经网络,并且在嵌入空间中给定一个度量的情况下使用最近邻分类。 从那时起,学习最适合小样本学习的度量的问题就引起了该领域的兴趣 [33, 28, 29, 17, 16]。 在少样本学习的背景下学习度量空间通常意味着确定合适的相似性度量(例如余弦或欧几里德)、将原始输入映射到相似性空间的特征提取器(例如图像的卷积堆栈或文本的 LSTM 堆栈)、损失函数来驱动参数更新,以及一个训练方案(通常是情景的)。 尽管已经探索了此列表中的各个组件【什么表?】,但它们之间的关系并未受到相当多的关注。
【将组件联系起来,或许就有了提升,因果推断也是发现各个部分的联系~】
在目前的工作中,我们的目标是缩小这一差距。 我们表明,将已识别组件之间的相互作用考虑之内,可以显着改善少样本泛化。 特别是,我们表明,可以利用相似性度量和成本函数之间的非平凡交互(non-trivial interaction)【这是个啥?】来提高给定的通过缩放的相似性度量的性能。使用这种机制,我们缩小了余弦相似性和欧几里得距离之间超过 10% 的性能差距报告在 [28] 。 更重要的是,我们扩展了度量空间的概念,通过在特定任务上调节特征提取器使其任务相关。 然而,学习这样的空间通常比学习静态空间更具挑战性。 我们找到了一种解决方案,可以利用条件特征提取器和基于辅助协同训练的训练程序【这是啥嘛?】之间的交互来完成更简单的任务。 我们提出的基于任务相关的缩放度量的少样本学习架构在两个具有挑战性的少样本图像分类数据集上实现了卓越的性能。它比基线显示了高达 8.5% 的绝对精度提高(Snell 等人 [28]),并且 在 5-shot、5-way mini-Imagenet 分类任务上比最先进的 [17] 高 4.8%,达到 76.7% 的准确率,这是该数据集上报告的最佳准确率。
1.1 Background

1.2 Summary of contributions
Metric Scaling:
据我们所知,这是第一个研究(i)提出度量缩放来提高少镜头算法的性能,(ii)数学分析其对目标函数更新的影响,(iii)实证证明其对少镜头性能的积极影响。
Task Conditioning:
我们使用任务编码网络来提取基于任务的样本集的任务表示。这用于通过FILM[19]影响特征提取器的行为。
Auxiliary task co-training:
我们表明,在传统的监督分类任务上协同训练特征提取,降低了训练复杂性,并提供了更好的泛化。
1.3 Related work
在文献中可以找到三种主要的解决少镜头分类问题的方法。
第一种是元学习方法。即:learning a model that, given a task (set of labeled data), produces a classifier that generalizes across all tasks[31, 25].
Matching Networks [33],MAML [6], “Optimization as a model” ,Meta-learning with memory-augmented neural networks,adaResNet 。许多最近的方法都专注于学习一个在情节特征空间(the episodic feature space)上的度量。Prototypical networks [28] ,relation network,SNAIL[16] 。研究还表明,这些方法受益于利用未标记和模拟数据[23,34]
第二种方法旨在最大化来自不同类[10]的示例之间的距离。文献10 是孪生网络。对比损失函数的应用;triplet loss 的应用,The attentive recurrent comparators的应用。
第三种方法依赖于对不同类别的先验分布的贝叶斯建模。还有依赖分层贝叶斯模型的。
至于任务条件,[3, 18, 19] 提出了用于风格转移和视觉推理的条件批量归一化。不同的是,我们修改了条件方案以使其适应小样本学习,引入 γ0,β0 先验和辅助协同训练。在小样本学习情境中,任务条件的概念可以追溯到[33],尽管是以隐式形式存在的,因为没有任务嵌入的概念。在我们的工作中,我们明确地引入了一个任务表示(见图1),它是作为任务类中心(任务原型)的平均值计算的。这比[33]中的单个样本级LSTM/注意模型简单得多。[33] 中的条件被用作固定特征提取器的输出的后处理。我们建议通过预测特征提取器自己的批量归一化参数来调节特征提取器,从而使特征提取器行为任务动态化,而无需对支持集进行繁琐的微调。为了训练任务条件化的体系结构,我们采用常规的 64 路分类任务进行多任务训练。尽管辅助协同训练通常对学习有益,但“对于多任务学习何时起作用以及是否存在有助于确定其成功的数据特征知之甚少”[20]。 我们表明,在少样本学习的背景下,将任务调节和辅助协同训练相结合是有益的
在模型蒸馏的背景下,Hinton等人对softmax中的标度和温度调整进行了讨论。我们提出在少镜头学习场景中使用它,并提供新的理论和实证结果量化缩放参数的影响。
2 Model Description
2.1 Metric Scaling
Snell等人 [28] 使用1.1节中详细描述的方法,发现欧几里德距离优于Vinyals等人[33]使用的余弦距离。我们假设这种改进可以直接归因于度量的不同尺度与 softmax 的相互作用。此外,已知输出的维度对输出尺度有直接影响【不明白?】,即使对于欧几里德距离 [32]。因此,我们建议通过可学习的温度 α 来缩放距离度量
 以使模型能够学习每个相似性度量的最佳方式,从而提高所有度量的性能。为了进一步理解α的作用,我们分析了分类(class-wise)交叉熵损失函数:
以使模型能够学习每个相似性度量的最佳方式,从而提高所有度量的性能。为了进一步理解α的作用,我们分析了分类(class-wise)交叉熵损失函数:

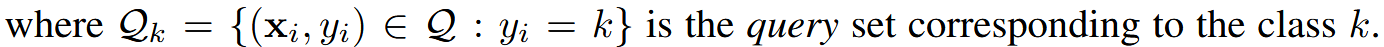
 其用于更新参数φ的梯度由下式给出:
其用于更新参数φ的梯度由下式给出:

 乍一看,α 对导数表达式的影响是双重的:(i)整体缩放,以及(ii)调节 RHS 【RHS是啥?赋值右侧】括号内第二项中权重的锐度。下面我们探讨 α → 0 和 α →∞ 范围内的 α 归一化【啥叫α归一化?】梯度 【 注:The effect of α-related gradient scaling is trivial】:
乍一看,α 对导数表达式的影响是双重的:(i)整体缩放,以及(ii)调节 RHS 【RHS是啥?赋值右侧】括号内第二项中权重的锐度。下面我们探讨 α → 0 和 α →∞ 范围内的 α 归一化【啥叫α归一化?】梯度 【 注:The effect of α-related gradient scaling is trivial】:

对方程 (3),很明显,对于小的 α 值,第一项最小化了查询样本与其对应原型之间的嵌入距离。 第二项最大化样本与非所属类别的原型之间的嵌入距离【最小化最大化距离是怎么看出来的?】。 对于较大的 α 值(方程(4)),第一项与方程 (3) 相同; 而第二项最大化样本与最接近的错误分配原型 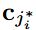 (如果有)的距离。 如果
(如果有)的距离。 如果 = k (没误差), 点 xi 的导数贡献为零【为什么为零?】。这相当于只从最难的例子中学习导致关联错误(association errors)【不明白?】。因此, α 的两种不同机制有利于最小化样本分布的重叠(minimizing the overlap of the sample distributions) 和按样本校正聚类分配(correcting cluster assignments sample-wise) 【这两个是啥意思?】。
= k (没误差), 点 xi 的导数贡献为零【为什么为零?】。这相当于只从最难的例子中学习导致关联错误(association errors)【不明白?】。因此, α 的两种不同机制有利于最小化样本分布的重叠(minimizing the overlap of the sample distributions) 和按样本校正聚类分配(correcting cluster assignments sample-wise) 【这两个是啥意思?】。
大 α 机制与解决少样本分类错误更直接相关。 同时,这种机制产生的更新策略有一个缺点。 随着优化的进行和分类精度的提高,错误分类的样本数量平均减少,这导致平均有效批量(batch)大小减少(更多的样本产生零导数)。 因此,我们的假设是对于数据集、度量和任务的给定组合,缩放参数 α 有一个最佳值。 第 3.4 节凭经验证明 α 的最优值确实存在,它可以是例如 在验证集上进行交叉验证。
2.2 Task conditioning (通篇不懂。。。)
到目前为止,我们假设特征提取器fφ(·)是任务独立的。动态任务条件下的特征提取器应该更适合于在给定的样本集类表示和查询样本之间找到正确的关联,这是由Vinyals等人[33]用双向LSTM作为固定特征提取器的后处理隐式完成的。不同的是,我们显式地定义了一个动态特征提取器fφ(x,Γ),其中Γ是一组从任务表示中预测的参数,以便在给定任务样本集S的情况下优化fφ(x,Γ)的性能。这与 FILM 调节层 [19] 和条件批标准化 [3, 18] 有关,形式为 h 【见图】,其中 γ 和 β 是应用于层 hl 的缩放和移位向量。+1 = γ h + β
 具体来说,我们建议使用类原型的均值作为任务表示 c【见下图】,用任务嵌入网络 (TEN) 对其进行编码,并对于特征提取器中的每个卷积层,预测层级元素级尺度和移位向量 γ,β (参见补充材料第 S1 节中的图 1 和图 2)。
具体来说,我们建议使用类原型的均值作为任务表示 c【见下图】,用任务嵌入网络 (TEN) 对其进行编码,并对于特征提取器中的每个卷积层,预测层级元素级尺度和移位向量 γ,β (参见补充材料第 S1 节中的图 1 和图 2)。
 任务表示定义为任务类中心的平均值(i)降低了TEN输入的维数,(ii)取代了昂贵的RNN/CNN/注意力 建模。另一方面,它是一种对任务进行聚类的有效方法。在任务表示空间中,具有大量公共相似类的任务将倾向于更靠近集群(具有大量相似类的任务将倾向于在任务表示空间中聚集得更近)。
任务表示定义为任务类中心的平均值(i)降低了TEN输入的维数,(ii)取代了昂贵的RNN/CNN/注意力 建模。另一方面,它是一种对任务进行聚类的有效方法。在任务表示空间中,具有大量公共相似类的任务将倾向于更靠近集群(具有大量相似类的任务将倾向于在任务表示空间中聚集得更近)。
我们的TEN的实现(参见补充材料,第S1节的更多细节)使用两个独立的完全连接的残差网络来生成向量γ,β。根据[18]中的术语,γ参数是在delta范围内学习的,即预测偏离统一(预测与统一的偏差)(predicting deviation from unity)。
能够成功训练 TEN 的最关键组成部分是添加标量 L2 惩罚后乘法器 γ0 和 β0 (the scalar L2 penalized post-multipliers γ0 and β0)。 他们通过编码一个先验信念来限制 γ(和 β)的影响,即对于给定的层,γ(和 β)的所有分量应该同时接近零,除非任务调节为该层提供了显着的信息增益。数学上,这可以表示为:
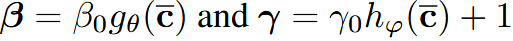
 预测因子 predictor ?
预测因子 predictor ?
2.3 Architecture
总体提出的少镜头分类架构如图1所示(见补充部分,第S1节有更多细节)。我们采用resnet - 12[8]作为主干特征提取器。它有4个深度为3的块,带有3x3的滤波器和快捷连接(shortcut connections)。2x2 max-pool应用于每个块的末尾。卷积层深度从 64 个过滤器开始,在每个最大池后加倍。 请注意,此架构在精神上与 [1] 和 [17] 中使用的架构相似,但我们在主干 ResNet 之前或之后不使用任何投影层。 在第一次通过样本集时,TEN 根据任务表示预测特征提取器中每个卷积层的 γ 和 β 参数值。 接下来,样本集和查询集由以刚刚生成的 γ 和 β 值为条件的特征提取器进行处理。 两个输出都被输入到一个相似性度量中,以找到类原型和查询实例之间的关联。 相似性度量的输出由标量 α 缩放,并输入到 softmax 层。
2.4 Auxiliary task co-training
通过在卷积和批处理规范块之后插入任务条件层,TEN(章节2.2)为体系结构引入了额外的复杂性。我们经验地观察到,同时优化卷积滤波器和TEN是非常具有挑战性的。我们通过使用额外的 logit 头(mini-Imagenet 案例中的正常的 64 路分类)进行辅助协同训练来解决该问题。 辅助任务以在episodes 中退火的概率进行采样。 我们使用 0.9 【见下图】形式的指数衰减计划对其进行退火,其中 T 是训练episodes 的总数,t 是 episode 索引。
 初始辅助任务选择概率被交叉验证为 0.9,衰减步数选择为 20。我们观察到辅助任务协同训练的显著积极影响(请参阅第 3.4 节)。对特征提取器进行简单的预训练并没有观察到相同的积极效果。 我们将此归因于通过反向传播辅助任务梯度和主任务梯度实现的正则化效果
初始辅助任务选择概率被交叉验证为 0.9,衰减步数选择为 20。我们观察到辅助任务协同训练的显著积极影响(请参阅第 3.4 节)。对特征提取器进行简单的预训练并没有观察到相同的积极效果。 我们将此归因于通过反向传播辅助任务梯度和主任务梯度实现的正则化效果
值得注意的是,带有辅助分类任务的少样本联合训练与课程学习(curriculum learning)有关 [24]。 辅助分类问题可以被视为更简单课程的一部分,帮助学习者在处理更难的小样本分类任务之前获得必要的最低技能水平。 有效地提取特征(即任务表示)形成了有效地根据给定任务的表示重新调整特征的“先决条件”
3 Experimental Results
3.1 Experimental Results
3.2 On the similarity metric
3.3 TEN importance across layers
3.4 Ablation study
4 Conclusions and Future Work
我们提出、分析并凭经验验证了小样本学习领域的一些改进。
我们表明,与未缩放的对应物(unscaled counterpart)不同,缩放余弦相似度与欧几里德距离相当。事实上,基于我们的结果,我们认为缩放因子是任何依赖于相似性度量和交叉熵损失函数的少镜头学习算法的必要标准组成部分。在为小样本学习寻找新的更有效的相似性度量(similarity measures)时,这一点尤为重要。
此外,我们的理论分析表明,当使用softmax和分类交叉熵时,简单缩放相似度度量会导致完全不同的参数更新机制。我们还发现在 softmax 的两个渐近机制之间实现了最佳性能。这就提出了显式设计损失函数和适合小样本学习的最优α计划的研究问题。我们进一步提出任务表示条件作为一种提高特征提取器在少镜头分类任务上的性能的方法。在这种情况下,设计更强大的任务表示,例如,基于类嵌入的高阶统计,看起来是未来工作的一个非常有前途的场所。
在两个独立的具有挑战性的数据集上的实验结果表明,该方法较已有的结果有了显著的改进,达到了少镜头图像分类的最高水平。















 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









