







结合之前学习的知识,现在可以进行猫狗大战的实现了。数据集是采用猫狗大战kaggle竞赛提供的25000张图片。下面一步步来实现。
使用的是tensorflow 2.1 下的keras 2.3.1版本。
一、初步实现
首先导入需要用到的库
import os,shutil
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras import optimizers
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator
(一)选取训练集、测试集、验证集
接下来把要用到的图片另存一个文件夹放好,找到图片前缀有dog和cat的文件夹,分别取猫狗图片各2000张,1000张用于训练、其余1000张分别用于测试与验证。
下面是实现代码
# 存放数据集的目录,图片名字根据猫狗种类已进行了命名
original_dir = 'E:\python\dogs-vs-cats\dogs-vs-cats\\train'
# 存放需要用到的数据集的目录
base_dir = 'E:\python\dogs-vs-cats\dogs-vs-cats\\small'
# 创建这个文件夹
os.mkdir(base_dir)
# 在创建好的文件夹中建立训练集、测试集、验证集目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
# 在训练、验证、测试目录下按猫狗再进行分类
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# 猫狗各取2000张图片
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dir, fname)
dat = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dat) #将图片进行复制
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dir, fname)
dat = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dat)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dir, fname)
dat = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dat)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dir, fname)
dat = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dat)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dir, fname)
dat = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dat)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dir, fname)
dat = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dat)
在建立好我们需要的文件夹后,这段代码可以去除,只留下下面一段就行了
base_dir = 'E:\python\dogs-vs-cats\dogs-vs-cats\\small'
train_dir = os.path.join(base_dir, 'train')
test_dir = os.path.join(base_dir, 'test')
validation_dir = os.path.join(base_dir, 'validation')
(二)构建神经网络模型
下面我们要建立一个简易的CNN网络模型。
首先同样是调用keras内置的Sequential模型,接着一步步添加卷积、池化层与全连接层等,代码如下
model = models.Sequential() #构建Sequential模型
#添加一层卷积层,输入图片的大小定义为150*150,颜色模式为RGB,激活函数为‘relu’,采用32个卷积核大小为3*3进行卷积
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
#经过卷积,输出图片尺寸:150-3+1=148*148,输出训练参数数量:32*3*3*3+32=896
model.add(layers.MaxPool2D((2, 2)))
#经过池化,输出图片尺寸:148/2=74*74
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
#经过卷积,输出图片尺寸:74-3+1=72*72,输出训练参数数量:64*3*3*32+64=18496
model.add(layers.MaxPool2D((2, 2)))
#经过池化,输出图片尺寸:72/2=36*36
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
#经过卷积,输出图片尺寸:36-3+1=34*34,输出训练参数数量:128*3*3*64+128=73856
model.add(layers.MaxPool2D((2, 2)))
#经过池化,输出图片尺寸:34/2=17*17
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
#经过卷积,输出图片尺寸:17-3+1=15*15,输出训练参数数量:128*3*3*128+128=147584
model.add(layers.MaxPool2D((2, 2)))
#经过池化,输出图片尺寸:15/2=7*7
#添加Dropout层
model.add(layers.Dropout(0.5))
#多维转为一维:7*7*128=6272
model.add(layers.Flatten())
#该全连接层计算输入向量和权重向量之间的点积,再加上一个偏置,参数数量:6272*512+512=3211776
model.add(layers.Dense(512, activation='relu'))
#计算方法同上,参数数量:512*1+1=513
model.add(layers.Dense(1, activation='sigmoid'))
#对模型进行配置,acc表示对模型的评价,我们暂且称它为准确率,值为0到1
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
(三)数据预处理
接下来就是对数据进行预处理了,我们使用ImageDataGenerator来读取并处理函数,再使用fit_generator填充数据,最后保存模型。
#因为CNN更喜欢处理小的输入值,所以我们将图像缩小255倍,即进行归一化,将[0, 255]区间的像素值减小到[0, 1]区间中,
train_datagen = ImageDataGenerator( rescale=1./255,
rotation_range=40,
width_shift_range=0.2, #宽度平移
height_shift_range=0.2, #高度平移
shear_range=0.2, #修剪
zoom_range=0.2, #缩放
horizontal_flip=True,) #添加新像素
#为了防止过拟合现象,我们采用增大数据的方式。即对原有的图片进行多次随机变换操作来使得模型不会两次见到同一张图片。
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
directory=train_dir, #训练集目录
target_size=(150, 150),
batch_size=20, #每次更新的样本数
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
directory=validation_dir,#验证集目录
target_size=(150, 150),
batch_size=20,
class_mode='binary')
#用fit_generator向模型中填充数据
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30, #即迭代次数,迭代次数越高模型精确度越高,但耗费时间更长,且可能出现过拟合情况
validation_data=validation_generator,
validation_steps=50)
#保存模型
model.save('cats_and_dogs_small_1.h5')
需要注意的是在上面调整生成器参数时,batch_size是每次更新的样本数,steps_per_epoch是我们在每次迭代中需要执行多少次生成器来生产数据,由于我们训练集共有2000个样本数据,所以两个值的乘积不能大于2000,否则会因为样本数不足而报错。同样的验证数据的生成器两个值乘积不得大于1000。
(四)绘制损失曲线和精度曲线
接下来我们利用图像直观感受训练过程中loss(损失值)和acc(精确度)的变化,可以利用keras内置的history函数进行,代码如下
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
#绘制精确度曲线
epochs = range( len(acc) )
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
#绘制损失值曲线
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
结果如下



训练集和验证集上的准确率是在70%左右。同样的,训练集和验证集上的loss均在0.55左右,未出现大幅度的过拟合。当然,看图的情况应该还可以通过增加迭代次数提高精确度,但最终大概也就在75%左右,那么有没有什么办法能够较大的提升精确度呢?
二、优化模型
这里采用的是用预训练神经网络。我们的数据样本相对较少,而网络上有基于大数据集图片分类的预先训练好的网络,例如ImageNet。由于ImageNet的数据量无比之大(1.4 million 已经标注的图片,1000个不同的类别),那么我们用ImageNet预先训练好的网络来对我们的猫狗进行提取特征,可以很好的提升猫狗大战的准确率。这也叫迁移学习。
这里选用的是VGG16的结构,得益于它在ImageNet中良好的表现,并且简单实用。VGG16神经网络结构如下所示

或者下面这样
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
我们要做的是特征提取,也就是我们只要它在全连接层前的部分,后面把这些特征送入我们自己的分类器,我们需要做的就是定义全连接层,定义新的分类器。我们将卷积层的模型称之为基线卷积。下面是实现代码
import os
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras import optimizers
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
base_dir = 'E:\python\dogs-vs-cats\dogs-vs-cats\\small'
train_dir = os.path.join(base_dir, 'train')
test_dir = os.path.join(base_dir, 'test')
validation_dir = os.path.join(base_dir, 'validation')
#调用VGG16卷积神经网络
conv_base = VGG16(weights='imagenet',
include_top=False, #提取特征,放弃全连接层
input_shape=(150, 150, 3))
conv_base.summary()
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
conv_base.trainable = False#使用冻结的卷积基训练模型,即提取的特征不能改变
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
directory=train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
directory=validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50,
verbose=2)
model.save('cats_and_dogs_small_3.h5')
#显示训练中loss和acc的曲线
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range( len(acc) )
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
和一开始的区别就是我们使用了预训练神经网络,当然,精确度也有了很大的提高,结果如下
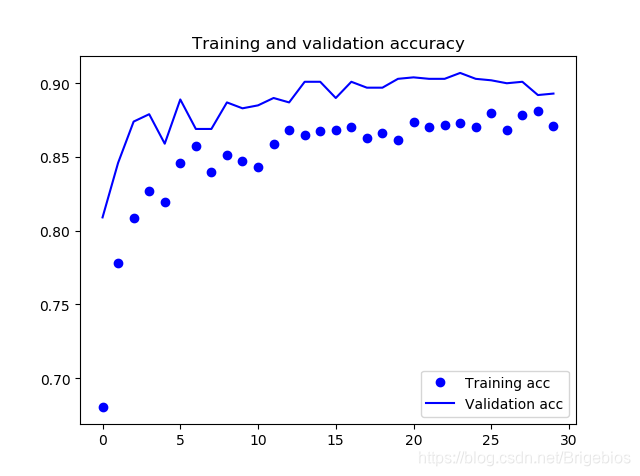
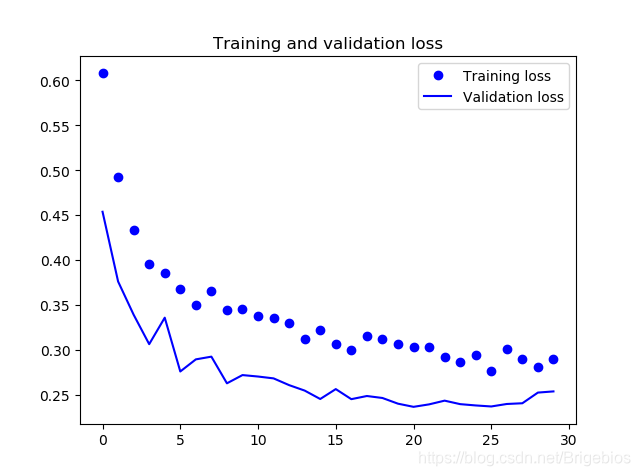

可以看到,验证集精确度大概能保持90%左右,损失值在25%左右。
当然,我们还可以选择不冻结卷积基,针对我们要解决的问题对模型进行细微调整,还能更进一步提高精确度,这也是另一种重用预训练模型的一种方式,称为微调。在此就不展示了。
三、数据测试
最后用训练好的模型再进行测试,看看预测情况,由于是个二分类问题,直接通过观察预测值大小,采用了一个简单的if语句来进行判断,代码如下
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing import image
import numpy as np
#加载模型
model = load_model("cats_and_dogs_small_3.h5")
model.summary()
#图像预处理
file_path='E:\python\dogs-vs-cats\dogs-vs-cats\\test1\\1.jpg'
img = image.load_img(file_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)
img_tensor=np.expand_dims(img_tensor,axis=0)
img_tensor/=255.
#预测
prediction=model.predict(img_tensor)
if prediction>0.5:
print('类别:狗', ' 概率:',prediction[0][0] )
else:
print('类别:猫', ' 概率:',1-prediction[0][0] )
结果如下

单张图片经测试准确率能够到100%,接下来试试批量处理。
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing import image
import numpy as np
import os
#加载模型h5文件
model = load_model("cats_and_dogs_small_3.h5")
model.summary()
i=j=0
file_path='E:\python\dogs-vs-cats\dogs-vs-cats\\test2'
for fd in os.listdir(file_path):
fd = os.path.join(file_path, fd)
img = image.load_img(fd, target_size=(150, 150))
img_tensor = image.img_to_array(img)
img_tensor=np.expand_dims(img_tensor,axis=0)
img_tensor/=255.
prediction=model.predict(img_tensor)
if prediction>0.5:
i=i+1
else:
j=j+1
print("狗的图片有%d张"%(i))
print("猫的图片有%d张"%(j))
结果如下
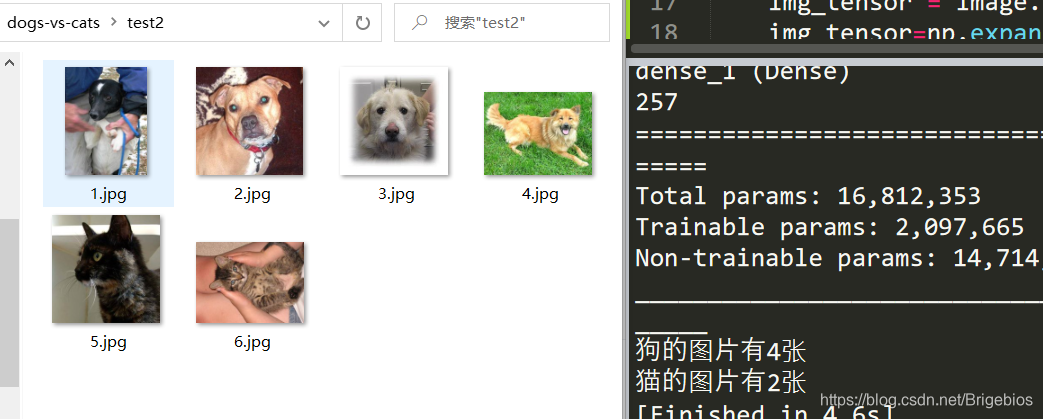
至此就使用keras实现了一次猫狗识别的代码,总的来说收获很多,也了解到了构建神经网络是个怎样的过程。一开始也由于不清楚导致走了不少弯路 ,比如如何调整batch_size和卷积层参数之类的,或者如何加快迭代速度,提高运算效率的问题。每调整一次数据运行就要花半个小时左右,最后使用VGG16模型进行迁移学习更是花了3、4个小时,实在苦不堪言。当然,完成这项任务自己也算正式迈入深度学习的大门了,接下来还会进一步努力提高自己。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









