







今天要做的是使用一个基于pytorch环境下的Faster-Rcnn网络实现对视力表字符的检测任务。
使用平台:pycharm;环境:torch1.5.0、cuda10.2
一、制作数据集
从头实现一个目标检测任务第一步就是制作数据集。首先在网上下载了视力表字符的图片,而后对几个字符进行加噪、上下采样处理并贴到一面墙的图片上,具体实现过程采用OpenCV库,实现方法很简单,在此不多加展示,结果如下所示:
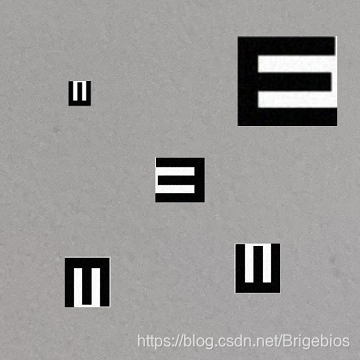
如此制作了10张样本图片后,通过数据增强的方法,采用旋转、偏移等操作扩大我们的数据集,生成了大小为150的数据集,具体方法也很简单,在此不多加展示。结果如下所示:

在制作好需要的图片后,接下来要对这些图片进行标注。这里使用的是图片标注工具LabelImg,具体安装使用方法网上也有。

如上图进行标注后生成了xml文件将我们标注的信息记录了下来,

之后我们的训练就要根据这些信息来进行。至此,数据集的制作就完成了,接下来是训练过程的演示。
二、训练模型
这里参考的是该篇博客构建的Faster-Rcnn网络:
https://blog.csdn.net/weixin_44791964/article/details/105739918
在B站也有相应的视频,步骤很详细。
首先第一步是根据我们的数据集生成一个索引文件。
import os
import random
random.seed(0)
xmlfilepath=r'faster-rcnn-pytorch-master/VOCdevkit/VOC2007/Annotations' #标注信息文件存放位置
saveBasePath=r"faster-rcnn-pytorch-master/VOCdevkit/VOC2007/ImageSets/Main" #索引文件存放位置
#----------------------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# train_percent不需要修改
#----------------------------------------------------------------------#
trainval_percent=1
train_percent=1
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
其实内容就是我们每一张图片的名字的集合。
建立好索引文件后,我们根据这一文件可以将图片的标注信息与图片地址整合后再建立一个文件,代码如下
import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["left", "right", "down", "up"]
def convert_annotation(year, image_id, list_file):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id), encoding='utf-8')
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = 0
if obj.find('difficult')!=None:
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for year, image_set in sets:
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set), encoding='utf-8').read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w', encoding='utf-8')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))#图片存放位置
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
此时会生成对应的2007_train.txt,每一行对应其图片位置及真实框的位置。如下所示:

至此就万事俱备了,接下来正式开始训练,代码如下:
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from nets.frcnn import FasterRCNN
from trainer import FasterRCNNTrainer
from utils.dataloader import FRCNNDataset, frcnn_dataset_collate
from utils.utils import LossHistory, weights_init
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def fit_ont_epoch(net,epoch,epoch_size,epoch_size_val,gen,genval,Epoch,cuda):
total_loss = 0
rpn_loc_loss = 0
rpn_cls_loss = 0
roi_loc_loss = 0
roi_cls_loss = 0
val_toal_loss = 0
with tqdm(total=epoch_size,desc=f'Epoch {epoch + 1}/{Epoch}',postfix=dict,mininterval=0.3) as pbar:
for iteration, batch in enumerate(gen):
if iteration >= epoch_size:
break
imgs, boxes, labels = batch[0], batch[1], batch[2]
with torch.no_grad():
if cuda:
imgs = torch.from_numpy(imgs).type(torch.FloatTensor).cuda()
else:
imgs = torch.from_numpy(imgs).type(torch.FloatTensor)
losses = train_util.train_step(imgs, boxes, labels, 1)
rpn_loc, rpn_cls, roi_loc, roi_cls, total = losses
total_loss += total.item()
rpn_loc_loss += rpn_loc.item()
rpn_cls_loss += rpn_cls.item()
roi_loc_loss += roi_loc.item()
roi_cls_loss += roi_cls.item()
pbar.set_postfix(**{'total' : total_loss / (iteration + 1),
'rpn_loc' : rpn_loc_loss / (iteration + 1),
'rpn_cls' : rpn_cls_loss / (iteration + 1),
'roi_loc' : roi_loc_loss / (iteration + 1),
'roi_cls' : roi_cls_loss / (iteration + 1),
'lr' : get_lr(optimizer)})
pbar.update(1)
print('Start Validation')
with tqdm(total=epoch_size_val, desc=f'Epoch {epoch + 1}/{Epoch}',postfix=dict,mininterval=0.3) as pbar:
for iteration, batch in enumerate(genval):
if iteration >= epoch_size_val:
break
imgs,boxes,labels = batch[0], batch[1], batch[2]
with torch.no_grad():
if cuda:
imgs = torch.from_numpy(imgs).type(torch.FloatTensor).cuda()
else:
imgs = torch.from_numpy(imgs).type(torch.FloatTensor)
train_util.optimizer.zero_grad()
losses = train_util.forward(imgs, boxes, labels, 1)
_, _, _, _, val_total = losses
val_toal_loss += val_total.item()
pbar.set_postfix(**{'total_loss': val_toal_loss / (iteration + 1)})
pbar.update(1)
loss_history.append_loss(total_loss/(epoch_size+1), val_toal_loss/(epoch_size_val+1))
print('Finish Validation')
print('Epoch:'+ str(epoch+1) + '/' + str(Epoch))
print('Total Loss: %.4f || Val Loss: %.4f ' % (total_loss/(epoch_size+1),val_toal_loss/(epoch_size_val+1)))
print('Saving state, iter:', str(epoch+1))
torch.save(model.state_dict(), 'logs/Epoch%d-Total_Loss%.4f-Val_Loss%.4f.pth'%((epoch+1),total_loss/(epoch_size+1),val_toal_loss/(epoch_size_val+1)))
if __name__ == "__main__":
#-------------------------------#
# 是否使用Cuda
# 没有GPU可以设置成False
#-------------------------------#
Cuda = True
#----------------------------------------------------#
# 训练所需要区分的类的个数。
#----------------------------------------------------#
NUM_CLASSES = 4
#-------------------------------------------------------------------------------------#
# input_shape是输入图片的大小,默认为800,800,3,随着输入图片的增大,占用显存会增大
#-------------------------------------------------------------------------------------#
input_shape = [800,800,3]
#----------------------------------------------------#
# 使用到的主干特征提取网络
# vgg或者resnet50
#----------------------------------------------------#
backbone = "resnet50"
model = FasterRCNN(NUM_CLASSES,backbone=backbone)
weights_init(model)
model_path = 'model_data/voc_weights_resnet.pth'
print('Loading weights into state dict...')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location=device)
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
print('Finished!')
net = model.train()
if Cuda:
net = torch.nn.DataParallel(model)
cudnn.benchmark = True
net = net.cuda()
loss_history = LossHistory("logs/")
annotation_path = '2007_train.txt'
#----------------------------------------------------------------------#
# 验证集的划分在train.py代码里面进行
# 2007_test.txt和2007_val.txt里面没有内容是正常的。训练不会使用到。
# 当前划分方式下,验证集和训练集的比例为1:9
#----------------------------------------------------------------------#
val_split = 0.1
with open(annotation_path,encoding='utf-8') as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val
#------------------------------------------------------#
# 主干特征提取网络特征通用,冻结训练可以加快训练速度
# 也可以在训练初期防止权值被破坏。
# Init_Epoch为起始世代
# Freeze_Epoch为冻结训练的世代
# Epoch总训练世代
# 提示OOM或者显存不足请调小Batch_size
#------------------------------------------------------#
if True:
lr = 1e-4
Batch_size = 2
Init_Epoch = 0
Freeze_Epoch = 50
optimizer = optim.Adam(net.parameters(), lr, weight_decay=5e-4)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.95)
train_dataset = FRCNNDataset(lines[:num_train], (input_shape[0], input_shape[1]), is_train=True)
val_dataset = FRCNNDataset(lines[num_train:], (input_shape[0], input_shape[1]), is_train=False)
gen = DataLoader(train_dataset, shuffle=True, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=frcnn_dataset_collate)
gen_val = DataLoader(val_dataset, shuffle=True, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=frcnn_dataset_collate)
epoch_size = num_train // Batch_size
epoch_size_val = num_val // Batch_size
if epoch_size == 0 or epoch_size_val == 0:
raise ValueError("数据集过小,无法进行训练,请扩充数据集。")
# ------------------------------------#
# 冻结一定部分训练
# ------------------------------------#
for param in model.extractor.parameters():
param.requires_grad = False
# ------------------------------------#
# 冻结bn层
# ------------------------------------#
model.freeze_bn()
train_util = FasterRCNNTrainer(model, optimizer)
for epoch in range(Init_Epoch,Freeze_Epoch):
fit_ont_epoch(net,epoch,epoch_size,epoch_size_val,gen,gen_val,Freeze_Epoch,Cuda)
lr_scheduler.step()
if True:
lr = 1e-5
Batch_size = 2
Freeze_Epoch = 50
Unfreeze_Epoch = 100
optimizer = optim.Adam(net.parameters(), lr, weight_decay=5e-4)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.95)
train_dataset = FRCNNDataset(lines[:num_train], (input_shape[0], input_shape[1]), is_train=True)
val_dataset = FRCNNDataset(lines[num_train:], (input_shape[0], input_shape[1]), is_train=False)
gen = DataLoader(train_dataset, shuffle=True, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=frcnn_dataset_collate)
gen_val = DataLoader(val_dataset, shuffle=True, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=frcnn_dataset_collate)
epoch_size = num_train // Batch_size
epoch_size_val = num_val // Batch_size
if epoch_size == 0 or epoch_size_val == 0:
raise ValueError("数据集过小,无法进行训练,请扩充数据集。")
#------------------------------------#
# 解冻后训练
#------------------------------------#
for param in model.extractor.parameters():
param.requires_grad = True
# ------------------------------------#
# 冻结bn层
# ------------------------------------#
model.freeze_bn()
train_util = FasterRCNNTrainer(model,optimizer)
for epoch in range(Freeze_Epoch,Unfreeze_Epoch):
fit_ont_epoch(net,epoch,epoch_size,epoch_size_val,gen,gen_val,Unfreeze_Epoch,Cuda)
lr_scheduler.step()
训练过程如下:

三、预测图片
训练后在logs文件夹中生成了每一次迭代后训练成的模型,我们取最后一个生成的Epoch100-Total_Loss0.4427-Val_Loss0.3494.pth模型,并将其导入用于预测图片,代码如下:
import colorsys
import copy
import os
import time
import numpy as np
import torch
from PIL import Image, ImageDraw, ImageFont
from nets.frcnn import FasterRCNN
from utils.utils import DecodeBox, get_new_img_size
class FRCNN(object):
_defaults = {
"model_path" : 'logs/Epoch100-Total_Loss0.4427-Val_Loss0.3494.pth',#使用我们训练好的模型
"classes_path" : 'model_data/voc_classes.txt', #此处的voc_classes.tet内容对应我们之前的4个分类
"confidence" : 0.5,
"iou" : 0.3,
"backbone" : "resnet50",
"cuda" : True,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
#---------------------------------------------------#
# 初始化faster RCNN
#---------------------------------------------------#
def __init__(self, **kwargs):
self.__dict__.update(self._defaults)
self.class_names = self._get_class()
self.generate()
self.mean = torch.Tensor([0, 0, 0, 0]).repeat(self.num_classes+1)[None]
self.std = torch.Tensor([0.1, 0.1, 0.2, 0.2]).repeat(self.num_classes+1)[None]
if self.cuda:
self.mean = self.mean.cuda()
self.std = self.std.cuda()
self.decodebox = DecodeBox(self.std, self.mean, self.num_classes)
#---------------------------------------------------#
# 获得所有的分类
#---------------------------------------------------#
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
#---------------------------------------------------#
# 载入模型
#---------------------------------------------------#
def generate(self):
#-------------------------------#
# 计算总的类的数量
#-------------------------------#
self.num_classes = len(self.class_names)
#-------------------------------#
# 载入模型与权值
#-------------------------------#
self.model = FasterRCNN(self.num_classes,"predict",backbone=self.backbone).eval()
print('Loading weights into state dict...')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
state_dict = torch.load(self.model_path, map_location=device)
self.model.load_state_dict(state_dict)
if self.cuda:
# self.model = nn.DataParallel(self.model)
self.model = self.model.cuda()
print('{} model, anchors, and classes loaded.'.format(self.model_path))
# 画框设置不同的颜色
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
#---------------------------------------------------#
# 检测图片
#---------------------------------------------------#
def detect_image(self, image):
#-------------------------------------#
# 转换成RGB图片,可以用于灰度图预测。
#-------------------------------------#
image = image.convert("RGB")
image_shape = np.array(np.shape(image)[0:2])
old_width, old_height = image_shape[1], image_shape[0]
old_image = copy.deepcopy(image)
#---------------------------------------------------------#
# 给原图像进行resize,resize到短边为600的大小上
#---------------------------------------------------------#
width,height = get_new_img_size(old_width, old_height)
image = image.resize([width,height], Image.BICUBIC)
#-----------------------------------------------------------#
# 图片预处理,归一化。
#-----------------------------------------------------------#
photo = np.transpose(np.array(image,dtype = np.float32)/255, (2, 0, 1))
with torch.no_grad():
images = torch.from_numpy(np.asarray([photo]))
if self.cuda:
images = images.cuda()
roi_cls_locs, roi_scores, rois, _ = self.model(images)
#-------------------------------------------------------------#
# 利用classifier的预测结果对建议框进行解码,获得预测框
#-------------------------------------------------------------#
outputs = self.decodebox.forward(roi_cls_locs[0], roi_scores[0], rois, height = height, width = width, nms_iou = self.iou, score_thresh = self.confidence)
#---------------------------------------------------------#
# 如果没有检测出物体,返回原图
#---------------------------------------------------------#
if len(outputs)==0:
return old_image
outputs = np.array(outputs)
bbox = outputs[:,:4]
label = outputs[:, 4]
conf = outputs[:, 5]
bbox[:, 0::2] = (bbox[:, 0::2]) / width * old_width
bbox[:, 1::2] = (bbox[:, 1::2]) / height * old_height
font = ImageFont.truetype(font='model_data/simhei.ttf',size=np.floor(3e-2 * np.shape(image)[1] + 0.5).astype('int32'))
thickness = max((np.shape(old_image)[0] + np.shape(old_image)[1]) // old_width * 2, 1)
image = old_image
for i, c in enumerate(label):
predicted_class = self.class_names[int(c)]
score = conf[i]
left, top, right, bottom = bbox[i]
top = top - 5
left = left - 5
bottom = bottom + 5
right = right + 5
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(np.shape(image)[0], np.floor(bottom + 0.5).astype('int32'))
right = min(np.shape(image)[1], np.floor(right + 0.5).astype('int32'))
# 画框框
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
print(label, top, left, bottom, right)
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[int(c)])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[int(c)])
draw.text(text_origin, str(label,'UTF-8'), fill=(0, 0, 0), font=font)
del draw
return image
def get_FPS(self, image, test_interval):
#-------------------------------------#
# 转换成RGB图片,可以用于灰度图预测。
#-------------------------------------#
image = image.convert("RGB")
image_shape = np.array(np.shape(image)[0:2])
old_width, old_height = image_shape[1], image_shape[0]
#---------------------------------------------------------#
# 给原图像进行resize,resize到短边为600的大小上
#---------------------------------------------------------#
width,height = get_new_img_size(old_width, old_height)
image = image.resize([width,height], Image.BICUBIC)
#-----------------------------------------------------------#
# 图片预处理,归一化。
#-----------------------------------------------------------#
photo = np.transpose(np.array(image,dtype = np.float32)/255, (2, 0, 1))
with torch.no_grad():
images = torch.from_numpy(np.asarray([photo]))
if self.cuda:
images = images.cuda()
roi_cls_locs, roi_scores, rois, _ = self.model(images)
#-------------------------------------------------------------#
# 利用classifier的预测结果对建议框进行解码,获得预测框
#-------------------------------------------------------------#
outputs = self.decodebox.forward(roi_cls_locs[0], roi_scores[0], rois, height = height, width = width, nms_iou = self.iou, score_thresh = self.confidence)
#---------------------------------------------------------#
# 如果没有检测出物体,返回原图
#---------------------------------------------------------#
if len(outputs)>0:
outputs = np.array(outputs)
bbox = outputs[:,:4]
label = outputs[:, 4]
conf = outputs[:, 5]
bbox[:, 0::2] = (bbox[:, 0::2]) / width * old_width
bbox[:, 1::2] = (bbox[:, 1::2]) / height * old_height
t1 = time.time()
for _ in range(test_interval):
with torch.no_grad():
roi_cls_locs, roi_scores, rois, _ = self.model(images)
#-------------------------------------------------------------#
# 利用classifier的预测结果对建议框进行解码,获得预测框
#-------------------------------------------------------------#
outputs = self.decodebox.forward(roi_cls_locs[0], roi_scores[0], rois, height = height, width = width, nms_iou = self.iou, score_thresh = self.confidence)
#---------------------------------------------------------#
# 如果没有检测出物体,返回原图
#---------------------------------------------------------#
if len(outputs)>0:
outputs = np.array(outputs)
bbox = outputs[:,:4]
label = outputs[:, 4]
conf = outputs[:, 5]
bbox[:, 0::2] = (bbox[:, 0::2]) / width * old_width
bbox[:, 1::2] = (bbox[:, 1::2]) / height * old_height
t2 = time.time()
tact_time = (t2 - t1) / test_interval
return tact_time
最后一步,输入图片看看预测结果:
import time
import cv2
import numpy as np
from PIL import Image
from frcnn import FRCNN
if __name__ == "__main__":
frcnn = FRCNN()
#-------------------------------------------------------------------------#
# mode用于指定测试的模式:
# 'predict'表示单张图片预测
# 'video'表示视频检测
# 'fps'表示测试fps
#-------------------------------------------------------------------------#
mode = "predict"
#-------------------------------------------------------------------------#
# video_path用于指定视频的路径,当video_path=0时表示检测摄像头
# video_save_path表示视频保存的路径,当video_save_path=""时表示不保存
# video_fps用于保存的视频的fps
# video_path、video_save_path和video_fps仅在mode='video'时有效
# 保存视频时需要ctrl+c退出才会完成完整的保存步骤,不可直接结束程序。
#-------------------------------------------------------------------------#
video_path = 0
video_save_path = ""
video_fps = 25.0
if mode == "predict":
'''
1、该代码无法直接进行批量预测,如果想要批量预测,可以利用os.listdir()遍历文件夹,利用Image.open打开图片文件进行预测。
具体流程可以参考get_dr_txt.py,在get_dr_txt.py即实现了遍历还实现了目标信息的保存。
2、如果想要进行检测完的图片的保存,利用r_image.save("img.jpg")即可保存,直接在predict.py里进行修改即可。
3、如果想要获得预测框的坐标,可以进入frcnn.detect_image函数,在绘图部分读取top,left,bottom,right这四个值。
4、如果想要利用预测框截取下目标,可以进入frcnn.detect_image函数,在绘图部分利用获取到的top,left,bottom,right这四个值
在原图上利用矩阵的方式进行截取。
5、如果想要在预测图上写额外的字,比如检测到的特定目标的数量,可以进入frcnn.detect_image函数,在绘图部分对predicted_class进行判断,
比如判断if predicted_class == 'car': 即可判断当前目标是否为车,然后记录数量即可。利用draw.text即可写字。
'''
while True:
img = input('Input image filename:')
try:
image = Image.open(img)
except:
print('Open Error! Try again!')
continue
else:
r_image = frcnn.detect_image(image)
r_image.show()
elif mode == "video":
capture=cv2.VideoCapture(video_path)
if video_save_path!="":
fourcc = cv2.VideoWriter_fourcc(*'XVID')
size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))
out = cv2.VideoWriter(video_save_path, fourcc, video_fps, size)
fps = 0.0
while(True):
t1 = time.time()
# 读取某一帧
ref,frame=capture.read()
# 格式转变,BGRtoRGB
frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
# 转变成Image
frame = Image.fromarray(np.uint8(frame))
# 进行检测
frame = np.array(frcnn.detect_image(frame))
# RGBtoBGR满足opencv显示格式
frame = cv2.cvtColor(frame,cv2.COLOR_RGB2BGR)
fps = ( fps + (1./(time.time()-t1)) ) / 2
print("fps= %.2f"%(fps))
frame = cv2.putText(frame, "fps= %.2f"%(fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow("video",frame)
c= cv2.waitKey(1) & 0xff
if video_save_path!="":
out.write(frame)
if c==27:
capture.release()
break
capture.release()
out.release()
cv2.destroyAllWindows()
elif mode == "fps":
test_interval = 100
img = Image.open('img/street.jpg')
tact_time = frcnn.get_FPS(img, test_interval)
print(str(tact_time) + ' seconds, ' + str(1/tact_time) + 'FPS, @batch_size 1')
else:
raise AssertionError("Please specify the correct mode: 'predict', 'video' or 'fps'.")
接下来从网络上随便找一张视力表图片输入后预测结果如下:
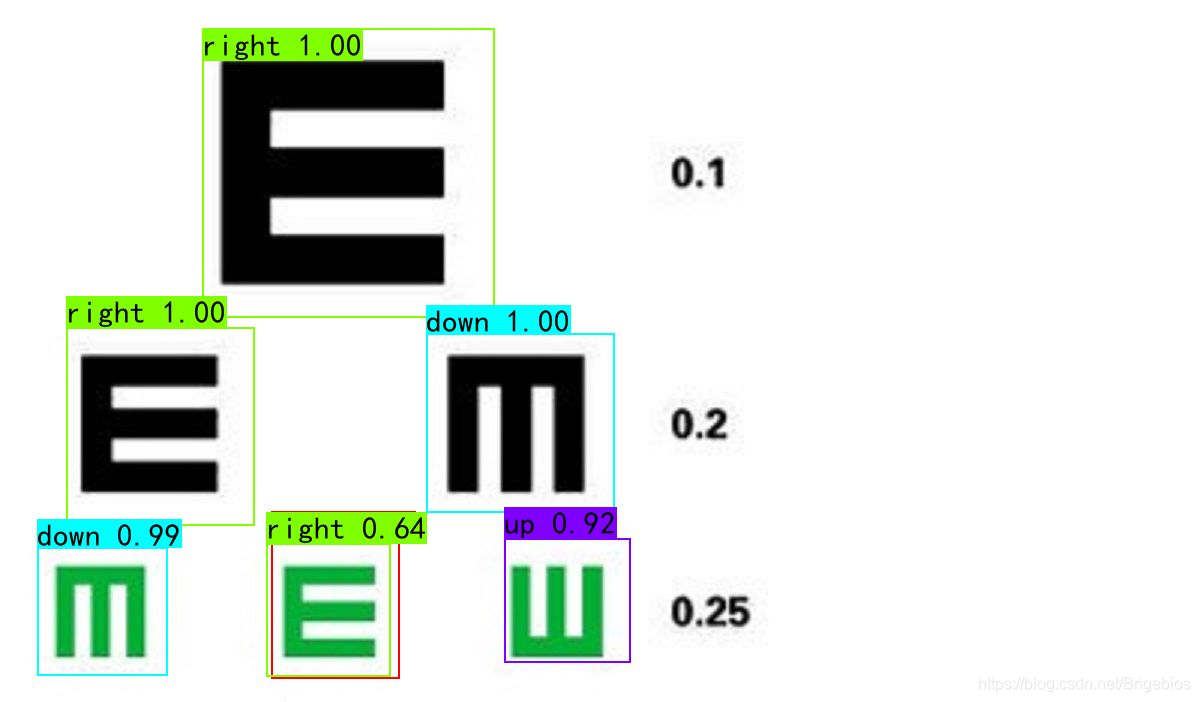
效果还可以,但还是存在一定误差,应该是在制作数据集时存在纰漏或者数据集还不够大的原因。但总而言之也算完成了对视力表字符识别的任务。
接下来对模型进行评估。
四、模型评估
主要使用mAP目标检测精度来评估我们的模型好坏,评估过程可参考视频https://www.bilibili.com/video/BV1zE411u7Vw
具体mAP计算过程可参考:https://www.bilibili.com/video/BV1zE411u7Vw
计算后的mAP图如下所示
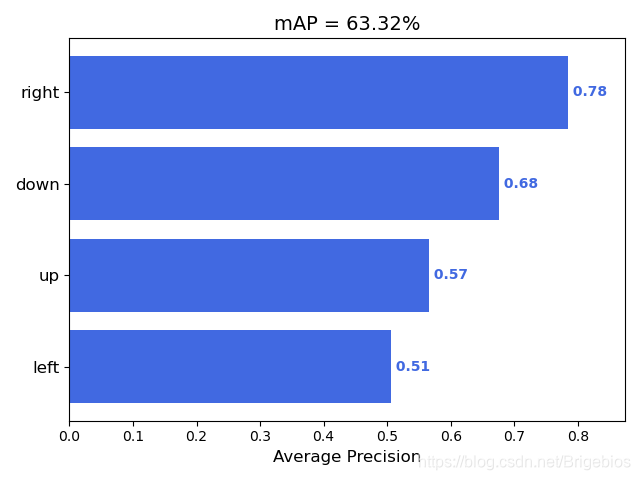
可以看到在检测left方向的字符精度较低,经反复测试结果也是如此,可以推断是在制作数据集时出现了纰漏,或者左字符样本不够丰富导致的。
至此,从制作数据集到评估模型,目标检测任务的总体过程就实施了一遍,期间也遇到过许多bug,但最终顺利解决了,收获还是挺大的。














 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









