




本方主要从以下几面方面来研究fs文件系统
1、文件系统的注册
2、文件系统的mount
3、文件的访问
一、 fat文件系统的注册
static struct file_system_type vfat_fs_type = {
.owner = THIS_MODULE,
.name = "vfat",
.mount = vfat_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV | FS_ALLOW_IDMAP,
};
MODULE_ALIAS_FS("vfat");
static int __init init_vfat_fs(void)
{
return register_filesystem(&vfat_fs_type);
}
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
if (fs->parameters &&
!fs_validate_description(fs->name, fs->parameters))
return -EINVAL;
BUG_ON(strchr(fs->name, '.'));
if (fs->next)
return -EBUSY;
write_lock(&file_systems_lock);
p = find_filesystem(fs->name, strlen(fs->name));
//从已经注册的全局变量中依次轮循进行字符串比较
if (*p) //不为空则证明已经注册过
res = -EBUSY;
else //为空则直接用结构体变量填充
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
static struct file_system_type **find_filesystem(const char *name, unsigned len)
{
struct file_system_type **p;
//从全局变量file_systems查找,注意file_systems默认值是NULL,返回的是指针地址,用以接收需要注册的结构体数据
for (p = &file_systems; *p; p = &(*p)->next)
if (strncmp((*p)->name, name, len) == 0 &&
!(*p)->name[len])
break;
return p;
}
以上可知,文件系统注册是比较简单的单链表操作
文件系统的挂载
挂载需要上层主动调用mount命令,通过系统调用到内核进行挂载。以fat文件格式为例看挂载流程
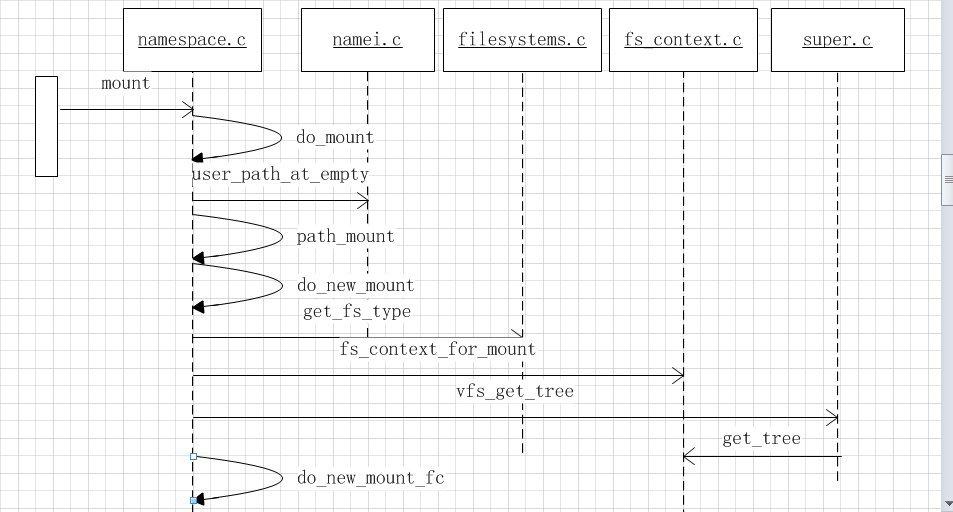
long do_mount(const char *dev_name, const char __user *dir_name,
const char *type_page, unsigned long flags, void *data_page)
{
struct path path;
int ret;
ret = user_path_at(AT_FDCWD, dir_name, LOOKUP_FOLLOW, &path);
//用当前线程task成员path填充path结构体
if (ret)
return ret;
ret = path_mount(dev_name, &path, type_page, flags, data_page);
path_put(&path);
return ret;
}
static int do_new_mount(struct path *path, const char *fstype, int sb_flags,
int mnt_flags, const char *name, void *data)
{
struct file_system_type *type;
struct fs_context *fc;
const char *subtype = NULL;
int err = 0;
if (!fstype)
return -EINVAL;
type = get_fs_type(fstype);//根据字符串从全局链表上获取注册的文件数据
if (!type)
return -ENODEV;
if (type->fs_flags & FS_HAS_SUBTYPE) {
subtype = strchr(fstype, '.');
if (subtype) {
subtype++;
if (!*subtype) {
put_filesystem(type);
return -EINVAL;
}
}
}
fc = fs_context_for_mount(type, sb_flags);//分配fs_context结构体,比较重要
put_filesystem(type);
if (IS_ERR(fc))
return PTR_ERR(fc);
if (subtype)
err = vfs_parse_fs_string(fc, "subtype",
subtype, strlen(subtype));
if (!err && name)
err = vfs_parse_fs_string(fc, "source", name, strlen(name));
if (!err)
err = parse_monolithic_mount_data(fc, data);
if (!err && !mount_capable(fc))
err = -EPERM;
if (!err)
err = vfs_get_tree(fc);//回调函数到具体的文件系统里面,创建超级块
if (!err)
err = do_new_mount_fc(fc, path, mnt_flags);//创建挂载点
put_fs_context(fc);
return err;
}
fs_context_for_mount
->alloc_fs_context
static struct fs_context *alloc_fs_context(struct file_system_type *fs_type,
struct dentry *reference,
unsigned int sb_flags,
unsigned int sb_flags_mask,
enum fs_context_purpose purpose)
{
int (*init_fs_context)(struct fs_context *);
struct fs_context *fc;
int ret = -ENOMEM;
fc = kzalloc(sizeof(struct fs_context), GFP_KERNEL_ACCOUNT);
if (!fc)
return ERR_PTR(-ENOMEM);
fc->purpose = purpose;
fc->sb_flags = sb_flags;
fc->sb_flags_mask = sb_flags_mask;
fc->fs_type = get_filesystem(fs_type);//注册的文件系统填充,后续会被使用
fc->cred = get_current_cred();
fc->net_ns = get_net(current->nsproxy->net_ns);
fc->log.prefix = fs_type->name;
mutex_init(&fc->uapi_mutex);
switch (purpose) {
case FS_CONTEXT_FOR_MOUNT:
fc->user_ns = get_user_ns(fc->cred->user_ns);
break;
case FS_CONTEXT_FOR_SUBMOUNT:
fc->user_ns = get_user_ns(reference->d_sb->s_user_ns);
break;
case FS_CONTEXT_FOR_RECONFIGURE:
atomic_inc(&reference->d_sb->s_active);
fc->user_ns = get_user_ns(reference->d_sb->s_user_ns);
fc->root = dget(reference);
break;
}
/* TODO: Make all filesystems support this unconditionally */
init_fs_context = fc->fs_type->init_fs_context;
//函数指向文件结构体的init_fs_context成员函数
if (!init_fs_context)
init_fs_context = legacy_init_fs_context;
//如果文件格式没有定义此函数则使用默认函数。对于fat
文件格式来说是没有定义的,ext4有定义
ret = init_fs_context(fc);
if (ret < 0)
goto err_fc;
fc->need_free = true;
return fc;
}
static int legacy_init_fs_context(struct fs_context *fc)
{
fc->fs_private = kzalloc(sizeof(struct legacy_fs_context), GFP_KERNEL_ACCOUNT);
if (!fc->fs_private)
return -ENOMEM;
fc->ops = &legacy_fs_context_ops;
//设置其默认的回调函数,后续这个ops会被使用到
return 0;
}
vfs_get_tree
->fc->ops->get_tree //这里就会使用到上述的legacy_fs_context_ops
const struct fs_context_operations legacy_fs_context_ops = {
.free = legacy_fs_context_free,
.dup = legacy_fs_context_dup,
.parse_param = legacy_parse_param,
.parse_monolithic = legacy_parse_monolithic,
.get_tree = legacy_get_tree,
.reconfigure = legacy_reconfigure,
};
static int legacy_get_tree(struct fs_context *fc)
{
struct legacy_fs_context *ctx = fc->fs_private;
struct super_block *sb;
struct dentry *root;
root = fc->fs_type->mount(fc->fs_type, fc->sb_flags,
fc->source, ctx->legacy_data);
//调用文件系统的mount函数,如果没有定义init_fs_context这个回调函数则mount函数一定要存在不然直接crash.反之则不一定需要mount
if (IS_ERR(root))
return PTR_ERR(root);
sb = root->d_sb;
BUG_ON(!sb);
fc->root = root; //保存root
return 0;
}
接下来就是调用 fat文件系统提供的mount函数了,看下大体流程
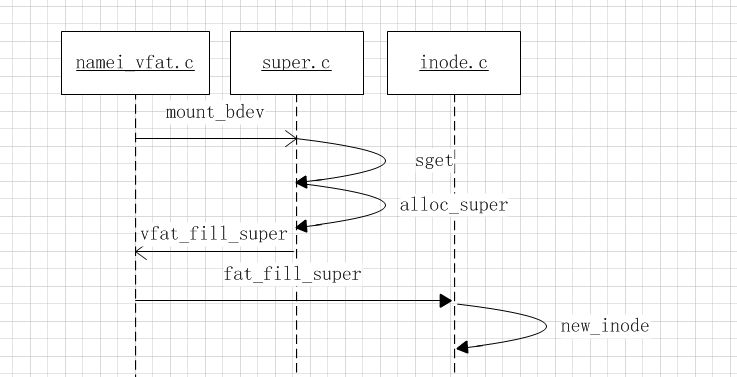
上述的流程核心就是创建super_block,并各种初始化填充里面的数据成员,另外一个就是生成root inode。函数比较复杂这里不作深入研究,只看大体的流程。在这里还没有走到对inode节点文件操作回调赋值。
do_new_mount_fc创建一个新的挂载点,这里就详细研究了
3、文件的访问
分成两部分:
一、目录的创建
二、文件打开
目录创建由用户调用命令mkdir通过系统调用到驱动,大体流程如下
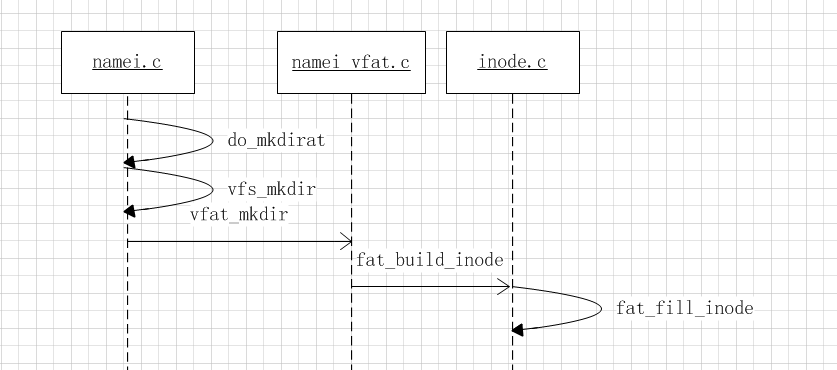
mkdir核心内容是创建一个inode并加入到链表,这个inode节点会被赋值对文件和目录操作的回调函数,这里只看下核心代码
int fat_fill_inode(struct inode *inode, struct msdos_dir_entry *de)
{
struct msdos_sb_info *sbi = MSDOS_SB(inode->i_sb);
int error;
MSDOS_I(inode)->i_pos = 0;
inode->i_uid = sbi->options.fs_uid;
inode->i_gid = sbi->options.fs_gid;
inode_inc_iversion(inode);
inode->i_generation = get_random_u32();
if ((de->attr & ATTR_DIR) && !IS_FREE(de->name)) {
inode->i_generation &= ~1;
inode->i_mode = fat_make_mode(sbi, de->attr, S_IRWXUGO);
inode->i_op = sbi->dir_ops;
inode->i_fop = &fat_dir_operations;
//目录的操作回调函数
MSDOS_I(inode)->i_start = fat_get_start(sbi, de);
MSDOS_I(inode)->i_logstart = MSDOS_I(inode)->i_start;
error = fat_calc_dir_size(inode);
if (error < 0)
return error;
MSDOS_I(inode)->mmu_private = inode->i_size;
set_nlink(inode, fat_subdirs(inode));
error = fat_validate_dir(inode);
if (error < 0)
return error;
} else { /* not a directory */
inode->i_generation |= 1;
inode->i_mode = fat_make_mode(sbi, de->attr,
((sbi->options.showexec && !is_exec(de->name + 8))
? S_IRUGO|S_IWUGO : S_IRWXUGO));
MSDOS_I(inode)->i_start = fat_get_start(sbi, de);
MSDOS_I(inode)->i_logstart = MSDOS_I(inode)->i_start;
inode->i_size = le32_to_cpu(de->size);
inode->i_op = &fat_file_inode_operations;
inode->i_fop = &fat_file_operations;
//文件的操作回调函数
inode->i_mapping->a_ops = &fat_aops;
MSDOS_I(inode)->mmu_private = inode->i_size;
}
if (de->attr & ATTR_SYS) {
if (sbi->options.sys_immutable)
inode->i_flags |= S_IMMUTABLE;
}
fat_save_attrs(inode, de->attr);
inode->i_blocks = ((inode->i_size + (sbi->cluster_size - 1))
& ~((loff_t)sbi->cluster_size - 1)) >> 9;
fat_time_fat2unix(sbi, &inode->i_mtime, de->time, de->date, 0);
inode->i_ctime = inode->i_mtime;
if (sbi->options.isvfat) {
fat_time_fat2unix(sbi, &inode->i_atime, 0, de->adate, 0);
fat_time_fat2unix(sbi, &MSDOS_I(inode)->i_crtime, de->ctime,
de->cdate, de->ctime_cs);
} else
inode->i_atime = fat_truncate_atime(sbi, &inode->i_mtime);
return 0;
}
这个是对目录的操作,文件操作也会走到上面的这个函数拿到inode节点并赋值回调函数
文件打开的的基本流程如下:
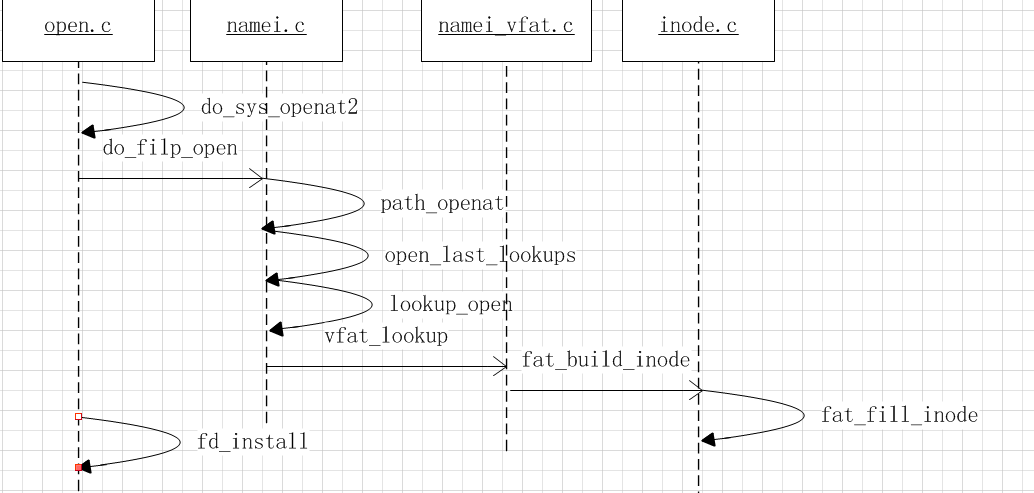
基本操作也是拿到inode,后续通过inode进行操作。如果有实现open回调函数则调用。但是fat好像并没有实现这个回调
f->f_op = fops_get(inode->i_fop);
if (WARN_ON(!f->f_op)) {
error = -ENODEV;
goto cleanup_all;
}
error = security_file_open(f);
if (error)
goto cleanup_all;
error = break_lease(file_inode(f), f->f_flags);
if (error)
goto cleanup_all;
/* normally all 3 are set; ->open() can clear them if needed */
f->f_mode |= FMODE_LSEEK | FMODE_PREAD | FMODE_PWRITE;
if (!open)
open = f->f_op->open;
if (open) {
error = open(inode, f);
if (error)
goto cleanup_all;
}
最后打开文件成功后将文件保存在fdtable数组里面


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











