








IEEE Transactions on Image Processing(TIP), 2017
paper_list_weather_classification
文章目录
1 Background and Motivation
天气是我们生活中不可或缺的一部分,即时和密集地收集天气信息是一个具有巨大社会影响的科学主题。
图像包含很多信息以了解天气,在进行天气分析时候,图像具有数量大和生成成本低等特殊优势
基于图像的天气识别有许多应用
- 包括太阳能系统在内的智能电网可以根据天气识别结果分配电力
- 驾驶助手根据天气情况做出即时响应
- ourtdoor robot
与其他计算机视觉的识别任务不太相同, weather recognition needs to understand complex phenomena of lighting and reflection on object surface and of the scene
基于图像处理的天气识别和场景识别不能完全等价,因为天气识别需要分析各种气象条件下场景的变化(Regional Cue 如 Fig.1,同样是草,在不同的天气环境下草也不太一样),而不是场景结构本身。

本文,作者提出了利用 coexistence clue 来进行天气识别, 例如,蓝天和大街上的投影一起出现,就很有可能是 sunny day 了(天空和街道的并发线索),又如 Fig.2,街道部分被照亮,部分有建筑的阴影,就很有可能是 sunny day 了(街道和建筑的并发线索)

从 Fig.2 可以看出,region pairs with high visual concurrency do not necessarily hold stable spatial/structural relationship,因此如何锁定合适的区域,如何发掘更多的 coexistence clue 成为关键!
因此,作者设计了region selection and concurrency model (RSCM) 来解决上诉的关键问题
2 Advantages / Contributions
- 贡献了自己的多标签,单标签数据集,效果很好,在公共数据集上表现也不错(感觉数据集并没有那么好)
- 提出的数据集 help discover regional properties and concurrency
3 Related work
- driving assistance
- adding weather priors
- estimate illumination from outdoor images
4 Method

先粗略的分割找有鉴别性的区域
然后,区域组合来进行天气识别
4.1 Pre-process: Coarse Segmentation
co-segmentation,从一组图片中提取相似的公共部分,which works in an unsupervised manner to segment an image into different regions.
Fig.8(b) 是初略分割的结果,可以看出,比较粗超,不足以区分出 semantic classes,

为了尽量避免 mistake,作者先用 K-means 对图像进行聚类(根据 HoG 和 GIST 特征),聚类结果如 Fig.7 所示,

然后再对聚在一起的一类图片进行 co-segmentation,结果如 Fig.9 所示

4.2 Regional Feature Extraction
采用的是论文 《Instance-aware semantic segmentation via Multi-task Network Cascades》(CVPR-2016) 中的方法,本文中简称 CFM 方法
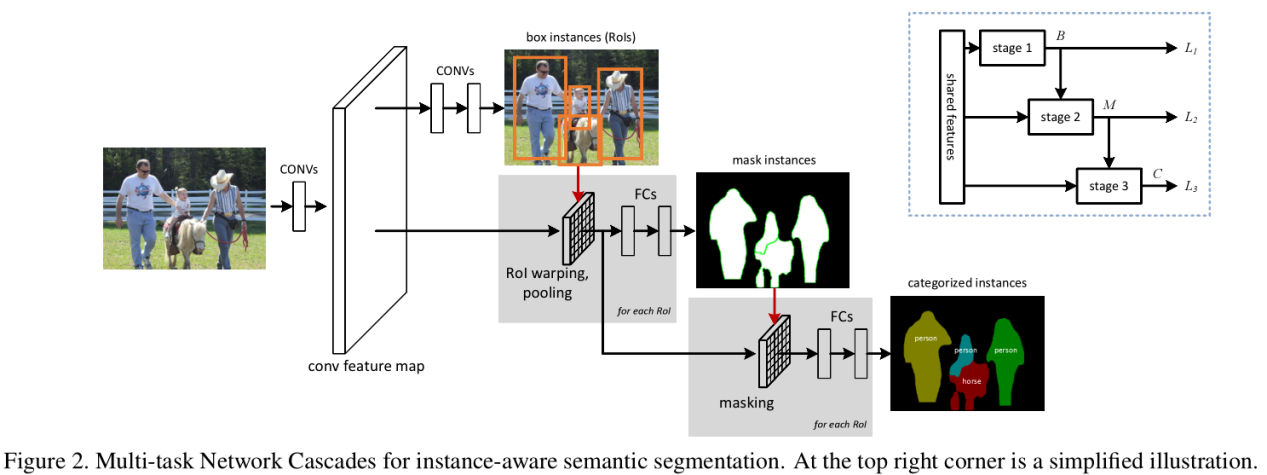
整体效果如 Fig.10 所示,对 cluster 的 region 进行 RoI pooling,然后 mask

提取到的区域特征公式 f f f 表示如下
f = G ( Θ ; I , R ) f = G(\Theta; I,R) f=G(Θ;I,R)
其中, G ( Θ ; : ) G(\Theta;:) G(Θ;:) 表示 CNN 网络, I I I 是输入图片, R R R 是 region of image I I I
4.3 Region Selection and Concurrency

面临两个难题,一个 cluster 可能有许多 region,怎么选?选出来的区域怎么 concurrency 才能更好的进行天气识别?
作者设计 region selection and concurrency model (RSCM) 来解决上面两个问题
4.3.1 Region Selection
R i , j , k R_{i,j,k} Ri,j,k 表示 k t h k^{th} kth image group (k-means聚类后的结果)中 j t h j^{th} jth cluster 的 i t h i^{th} ith region,为了简单的描述,我们去掉 k k k!
比如 Fig.11 中,class 1(cluster)中,有两个 region(两片绿色区域)
region R i , j R_{i,j} Ri,j 的特征描述为 f i , j f_{i,j} fi,j, j t h j^{th} jth cluster 的 region 数量为 n j n_j nj,二值 v i , j v_{i,j} vi,j 来描述 region 是否被选中,当 n j = 0 n_j = 0 nj=0 时,我们定义 v 0 , j = 1 v_{0,j} = 1 v0,j=1, f 0 , j = 0 → f_{0,j} = \overrightarrow{0} f0,j=0,也即,选中空 region,其特征为 0
被选择出来的特征可以表示为
F j = v j T f j F_j = v_j^Tf_j Fj=vjTfj
其中, v j = [ v 0 , j . . . v n j , j ] v_j = \begin{bmatrix} v_{0,j} \\ ...\\ v_{n_j,j} \end{bmatrix} vj=⎣⎡v0,j...vnj,j⎦⎤, v i , j ∈ 0 , 1 , ∣ ∣ v j ∣ ∣ 1 = 1 v_{i,j} \in {0,1}, ||v_j||_1 = 1 vi,j∈0,1,∣∣vj∣∣1=1(一个 cluster 中仅一个 region 被选中), f j = [ f 0 , j . . . f n j , j ] f_j = \begin{bmatrix} f_{0,j} \\ ...\\ f_{n_j,j} \end{bmatrix} fj=⎣⎡f0,j...fnj,j⎦⎤
各 vector 的维度如下,
- v j ∈ R n j + 1 v_j \in \mathbb{R}^{n_j + 1} vj∈Rnj+1(包括了 v 0 , j v_{0,j} v0,j)
- f j ∈ R ( n j + 1 ) × D f_j \in \mathbb{R}^{(n_j + 1) \times D} fj∈R(nj+1)×D
- F j ∈ R D F_j \in \mathbb{R}^ D Fj∈RD,cluster j 中选出某个 region 的 D 维特征
实验中 D 被设计为了 4096
区域选择的得分方程(scoring function)表达如下
E s ( W s ; V , F ) = t r a c e ( W s F T ) E_s(W^s;V,F) = trace(W^sF^T) Es(Ws;V,F)=trace(WsFT)
It outputs high score to encourage the selection of discriminative regions.
其中
-
W s = [ W 1 s . . . W M s ] W_s = \begin{bmatrix} W_1^s \\ ...\\ W_M^s \end{bmatrix} Ws=⎣⎡W1s...WMs⎦⎤(权重 ),
-
V = [ v 1 . . . v M ] V = \begin{bmatrix} v_1 \\ ...\\ v_M \end{bmatrix} V=⎣⎡v1...vM⎦⎤(所有 cluster 的所有 region 被选中的情况),
-
F = [ F 1 . . . F M ] F = \begin{bmatrix} F_1 \\ ...\\ F_M \end{bmatrix} F=⎣⎡F1...FM⎦⎤(所有 cluster 的所有 region 的特征)
W s ∈ R M × D W^s \in \mathbb{R}^ {M \times D} Ws∈RM×D, F ∈ R M × D F \in \mathbb{R}^ {M \times D} F∈RM×D, M M M 是 cluster 数量
4.3.2 Region Concurrency
用孪生网络(Siamese architecture),以不同 cluster 的两个 region 作为输入,用 CFM 提取特征
来自 j t h j^{th} jth 和 k t h k^{th} kth cluster 的不同 region 的 Concurrency 计算方式如下:
s j , k = − ∣ ∣ F j − F k ∣ ∣ 2 s_{j,k} = -||F_j-F_k||_2 sj,k=−∣∣Fj−Fk∣∣2
值越大,concurrency 越高
计算出不同 region 的 concurrency 后,乘以一个权重就可以得到得分方程
E c ( W c ; V , F ) = ∑ j = 1 M − 1 ∑ k > j M ( W c ∘ S ) j , k ( 公 式 7 ) E_c(W^c;V,F) = \sum_{j=1}^{M-1}\sum_{k>j}^{M}(W^c \circ S)_{j,k}(公式7) Ec(Wc;V,F)=j=1∑M−1k>j∑M(Wc∘S)j,k(公式7)
A higher score of Eq. (7) means the regions have higher concurrency.
其中
- W c , S ∈ R M × M W^c,S \in \mathbb{R}^ {M \times M} Wc,S∈RM×M,对称矩阵, S S S 描述不同 cluster 计算出来的 concurrency,
- ∘ \circ ∘ 是 Hadamard product,也即 element-wise multiply
- concurrency matrix S S S 是对称的,也即 s j , k = s k , j s_{j,k} = s_{k,j} sj,k=sk,j
4.3.3 Joint Model for Weather Recognition
J ( W s , W c ; V , F ) = E s ( W s ; V , F ) + E c ( W c ; V , F ) ( 公 式 8 ) J(W^s,W^c;V,F) = E_s(W^s;V,F) + E_c(W^c;V,F)(公式8) J(Ws,Wc;V,F)=Es(Ws;V,F)+Ec(Wc;V,F)(公式8)
A higher score means that an image has higher confidence to have label y = 1.
训练集 ( F , y ) ∈ T (F,y) \in T (F,y)∈T, F F F 是 regional features, y y y 是 weather label,参数 W c , W s , Θ W^c, W^s, \Theta Wc,Ws,Θ 的 learning phase 如下
1)Inference of V V V
隐变量 V
V ∗ = a r g m a x V J ( W s , W c ; V , F ) ( 公 式 9 ) V^* = \underset{V}{argmax} J(W^s,W^c;V,F)(公式9) V∗=VargmaxJ(Ws,Wc;V,F)(公式9)
穷举所有 region 来寻找 V 显然是不太可取的( C n 2 C_n^2 Cn2 复杂度),作者采用 iterated conditional modes (ICM) 算法,迭代来求解 V ∗ V^* V∗

比如,每次迭代中,只改变 v i , j v_{i,j} vi,j,其他 v v v 不变,看 J J J 的变化来,来确定 v i , j v_{i,j} vi,j 的值
Fig.12 展示了一些天气学出来的 region pairs


2)Learning of W s W^s Ws and W c W^c Wc
用的 latent SVM,来优化(梯度下降),如公式 10 和 11 所示


3)Learning of Θ \Theta Θ
损失函数如公式 12 所示

用 SGD 来更新
实验中 η \eta η 被设置为了 2
上述的 v v v、 W s W c W^sW^c WsWc、 Θ \Theta Θ 交替优化,流程如下所示

5 Experiments
先用 ICM 算法根据公式 9 计算出隐变量 V ∗ V* V∗,然后根据公式 8 求解
- 二分类的时候,J>0,y = 1;J≤0,y = -1
- 多分类的时候,采用 one-vs-all 策略,当前类 y=1,其他类别 y=-1,有多个 RSCM(类比多分类 SVM),预测的时候取最高的 RSCM 得分(得分要 scale 成概率)
- attribute recognition 时,也是 one-vs-all 策略,多个 RSCM 都输出结果(高于某个阈值的话)
5.1 Datasets

- MWD,multi-class weather dataset,contains 65,000 images from 6 common categories,(训练测试55开,跑10次,给出 mean ± std)
- Weather Class Annotation,Fig.5(a)
- Weather Attribute Annotation,Fig.5(b)
- 《Two-class weather classification》Dataset,10,000 张,sunny and cloudy

5.2 Experiments on Our Weather Classification Dataset
1)Sensitivities to Region Generation

探讨 co-segmentation 算法产生的 region 数量对 RSCM 的影响,region 数量越多,速度越慢,M = 15 效果反而变差,可能是形成许多信息量不够的 tiny region
2)Component Analysis

探讨 selection 和 concurrency 模块的重要性,两个模块都很重要
3)Strategies of Utilizing Regions

用整个图的效果不如用 region 的好
4)Comparisons with Other Methods

5.3 Experiments on Our Weather Attribute Dataset


5.4 Study on Weather Classification and Attribute Recognition

用 weather classification 任务训练得到的模型去测试 attribue recognition 任务,确实不太行
Fig.13 展示了用分类模型训练 RSCM 的结果,可以看出分类数据集也包含了 useful information

用分类和 attribute 数据集一起训练 RSCM 模型,效果最好

反过来,用 attribute 数据集训练出来的模型去测试分类数据集,acc 能达到 96.4,👍👍👍
5.5 Experiments on Two-class Weather Dataset

未来展望
region clusters aware of the weather condition during training
6 Conclusion(own)
- 天气识别和场景识别也不能完全等价,因为天气识别需要分析各种气象条件下场景的变化,而不是场景结构本身。
- weather classification and attribute recognition
- traditional bag-of-feature strategy considering brightness, contrast, sharpness, saturation and hue in sunny and rainy days
- co-segmentation
- ICM
- 《Instance-aware semantic segmentation via Multi-task Network Cascades》(CVPR-2016),CFM 方法
- 实验对比还蛮周全的,整图 vs region,classification 测 attribute















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









