







文章目录
深拷贝和浅拷贝
浅拷贝就是只拷贝对象第一层 若第一层中有可变类型引用 那么其中的可变类型若发生改变 则拷贝对象也会发生改变 例如
a = [1, 2, [1,2]]
b = copy.copy(a) # 这里无论是 copy 还是列表生成式 for循环 切片 最终拷贝的 都是浅拷贝 其根本原理是 列表里面装的不是元素的真实值 而是这个元素的引用地址
因为 [1,2]是可变类型 且在b里面存的是 该列表的引用地址 所以 当列表里面改了 a也会跟着改变
深拷贝就是一层一层拷贝 直到复制到没有可变类型为止
a = [1,2]
b = [1,2,a]
c = copy.deepcopy(b)
这里相当于会将a的里面的内容逐层拷贝然后放到一个新的内存地址中去
可迭代对象、迭代器、生成器
可迭代对象 (Iterable):
迭代对象是可以返回一个迭代器的任何对象。它定义了一个 _iter_() 方法,该方法返回一个迭代器对象。当使用 for 循环遍历一个迭代对象时,Python 会自动调用其 _iter_() 方法来获取一个迭代器,并调用该迭代器的_next_() 方法逐个获取元素,直到没有元素可迭代为止。
也就是能直接作于 for循环 的对象 有以下两类:
1.集合数据类型: list、tuple、str、set、dict
2.迭代器、生成器、或包含yield的生成器函数
迭代器 (Iterator):
迭代器属于可迭代对象
迭代器是一个对象,它定义了一个 _next_() 方法,每次调用该方法返回序列中的下一个元素,如果没有元素可迭代,则抛出 StopIteration 异常。
迭代器还定义了一个 _iter_() 方法,该方法返回迭代器本身。这意味着迭代器也是可迭代对象,因此可以在 for 循环中使用。
简单迭代器代码
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器a,b
def __iter__(self):
return self # for循环 调用iter()方法 这个方法又去调用其本身的__iter__方法 返回一个迭代器 因为本身就是迭代器 所以返回本身即可
def __next__(self):# 同上
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 100000: # 退出循环的条件
raise StopIteration();
return self.a # 返回下一个值
生成器(generator):
生成器属于迭代器
生成器是一种特殊的迭代器,它可以动态地生成值。生成器可以通过函数中的 yield 语句来实现。当函数执行到 yield 语句时,函数会返回一个值,并暂停执行,保存函数的状态。当下一次调用生成器时,函数会从之前保存的状态继续执行,直到下一个 yield 语句。
生成器有两类:
第一类
只要func里面有yeild关键词的就是生成器函数
生成器函数:还是使用 def 定义函数,但是,使用yield而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次从它离开的地方继续执行。
def foo(num):
print("starting...")
while num<10:
num=num+1
yield num
for n in foo(0): # for循环会不断调用next()方法 让yield中单的地方继续运行
print(n)
第二类:
生成器表达式:类似于列表推导,只不过是把一对大括号[]变换为一对小括号()。但是,生成器表达式是按需产生一个生成器结果对象,要想拿到每一个元素,就需要循环遍历。
# 一个列表
xiaoke=[2,3,4,5]
# 生成器generator,类似于list,但是是把[]改为()
gen=(a for a in xiaoke)
for i in gen:
print(i)
#结果是:
2
3
4
5
for 循环的对象都是可迭代对象 但是它需要得到一个迭代器 后续通过next()方法调用迭代器获取对象的下一个值
所以它会调用python内置函数iter()方法
如果这个可迭代对象是list、dict这种容器对象 那么iter()能返回一个迭代器
如果这个可迭代对象就是一个迭代器 那么iter()会调用 迭代器自身的__iter__方法 且后续的迭代 调用的next()方法也是去调用迭代器本身的__next__()方法
所以一个迭代器 需要有__iter__ 方法 这个方法返回其本身 __next__方法
而可迭代对象 list、tuple、dict这些 它只有__iter__方法 会返回一个迭代器 (不是其本身了) 没有__next__方法
总结:
Python中的迭代对象是一个可以返回一个迭代器的任何对象;迭代器是一个具有 _next_() 方法的对象,用于遍历序列中的元素;生成器是一种特殊的迭代器,它使用 yield 语句来动态地生成值。迭代器和生成器都是可迭代对象,因此可以在 for 循环中使用。相比于迭代器,生成器更为灵活和方便,因为它们可以动态地生成值。
- 生成器继承迭代器,迭代器继承可迭代对象,可迭代对象继承ABCMeta抽象基类
- 可迭代对象特性,可以使用for循环遍历,但是不能使用next()方法
- 迭代器特性,也是可迭代对象,自然可以使用for循环遍历,也可以使用next()方法获取下一个值
- 生成器特性,既是可迭代对象,也是迭代器,可以使用for和next(),生成器还有send()、throw()和close()方法
with open
with语句的底层,其实是很通用的结构,允许使用上下文管理器(context manager)。
上下文管理器实际是指一种支持__enter__和__exit__这两个方法的对象
enter 方法是不带参数的,它会在进入with语句块时被调用,即将其返回值绑定到as关键字之后的变量上;
exit 方法则带有3个参数:异常类型、异常对象和异常回溯。在离开方法时这个函数会被调用(带有通过参数提供的,可以引发的异常)。如果__exit__返回的是false,那么所有的异常都将不被处理;
class OperateTest(object):
def open(self):
print("此处打开文件了!")
def close(self):
print("此处关闭文件了!")
def operate(self, txt_file):
print("文件处理中!%s" % txt_file)
def __enter__(self):
self.open()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.close()
with OperateTest() as fp:
fp.operate("text_file")
yeild 和 yeild from
yeild from 后面如果是一个迭代对象(list,dict,str这种),则它可以将这个迭代对象的值一个个的yeild出来并返回给调用者,并执行完
yeild from 后面如果是一个生成器函数,则每次只能获取生成器函数yeild出来的值,并将该值给调用者,遇到return才会执行完
# 子生成器
def average_gen():
total = 0
count = 0
average = 0
while True:
new_num = yield average
count += 1
total += new_num
average = total/count
# 委托生成器
def proxy_gen():
while True:
yield from average_gen() # 遇到average_gen生成器函数里面的yeild返回的值就会往外抛数据
# ,遇到外面执行next()或send()再将数据往里面传
# 调用方
def main():
calc_average = proxy_gen()
next(calc_average) # 预激下生成器
print(calc_average.send(10)) # 打印:10.0
print(calc_average.send(20)) # 打印:15.0
print(calc_average.send(30)) # 打印:20.0
if __name__ == '__main__':
main()
闭包、装饰器
闭包
闭包的特点:
1.外部函数中定义了一个内部函数
2.外部函数有返回值
3.返回的值是:内部函数名
4.内部函数还引用外部函数的变量值
一般情况下,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
- 带参数的闭包
#带参数的闭包
def func2(a,b):#两个入参a,b
c=100 #外部函数参数
def inner_func2():#内部函数
d=3 #内部函数的参数
sum=a+b+c+d #引用外部函数的参数
print(sum)
return inner_func2 #返回内部函数名
f=func2(1,6)#f接收func2返回的inner_func2
f() #等价于调用inner_func2
nonlocal 变量名 #内部函数可修改外部函数的不可变变量
global 变量名 #内部函数可修改全局的不可变变量
装饰器是闭包的一种用途
装饰器
- 装饰器函数
如果装饰器不需要带参数则 第一层就不需要
#带参数的装饰器
def outer(q):#第一层,负责接收装饰器的参数
def decorate(func):#第二层,负责接收被装饰函数
def inner_func(*args,**kwargs):#第三层,负责接收被装饰函数的参数
func(*args,**kwargs)
print('铺地板{}块'.format(q))
return inner_func#返出来第三层
return decorate#返出来第二层
@outer(q=10)#装饰器带参数q=10
def house(time):
print('我是毛坯房,{}开始装修'.format(time))
@outer(q=100)#装饰器带参数q=100
def street():
print('新修的道路名字叫深南大道')
house('2019-12-21')
street()
- 类装饰器
带参数的装饰器 同理需要三层 一层负责接收装饰器的参数 一层负责接收被装饰的函数 一层负责接收被装饰函数的参数
class BaiyuDecorator:
def __init__(self, arg1, arg2): # 相当于装饰器函数中的第一层 用来接收装饰器的参数
print('执行类Decorator的__init__()方法')
self.arg1 = arg1
self.arg2 = arg2
def __call__(self, func): # 相当于第二层 用来接收被装饰的函数
print('执行类Decorator的__call__()方法')
def baiyu_warp(*args): # 相当于第三层 用来接收 被装饰函数的参数
print('执行wrap()')
print('装饰器参数:', self.arg1, self.arg2)
print('执行' + func.__name__ + '()')
func(*args)
print(func.__name__ + '()执行完毕')
return baiyu_warp
@BaiyuDecorator('参数1', '参数2') # 1、执行到这里的时候会将 类装饰器的__init__方法走一遍
def example(a1, a2, a3): # 2、执行到这里 会将类装饰器的 __call__方法走一遍
print('传入example()的参数:', a1, a2, a3)
if __name__ == '__main__':
print('准备调用example()')
example('Baiyu', 'Happy', 'Coder') # 3、运行这里的时候 先运行装饰器 __call__方法里面的 baiyu_warp 装饰器
print('测试代码执行完毕')
如果类装饰器 不需要带参数 则只需要两层即可
- 不带参数的装饰器
class BaiyuDecorator:
def __init__(self, func): # 该装饰器不需要带参数 因此原来第一层直接用来装被装饰函数
self.func = func
print(".执行类的__init__方法")
def __call__(self, *args, **kwargs): # 原来第二层用来装被装饰函数的参数
print('进入__call__函数')
t1 = time.time()
self.func(*args, **kwargs)
print("执行时间为:", time.time() - t1)
@BaiyuDecorator
def baiyu(): # 运行到这里才会去运行 类装饰器的__init__方法 且将该方法的地址传参过去
print("我是攻城狮白玉")
time.sleep(2)
if __name__ == '__main__':
# print(blog)
pass
print('1111')
baiyu()
python垃圾回收机制
python中,主要通过引用技术进行垃圾回收;通过“标记-清除” 解决容器(list,dict,set,tuple)对象可能产生循环引用问题; 通过“分代回收”以空间换时间的方法提高垃圾回收效率
引用计数
typedef struct_object {
int ob_refcnt;
struct_typeobject *ob_type;
} PyObject;
在Python中每一个对象的核心就是一个结构体PyObject,它的内部有一个引用计数器(ob_refcnt)。程序在运行的过程中会实时的更新ob_refcnt的值,来反映引用当前对象的名称数量。当某对象的引用计数值为0,那么它的内存就会被立即释放掉。
以下情况是导致引用计数加一的情况:
- 对象被创建,例如a=2
- 对象被引用,b=a
- 对象被作为参数传入到一个函数中
- 对象作为一个元素存储在容器中
下面的情况则会导致引用计数减一:
- 对象别名被显示销毁 del
- 对象别名被赋予新的对象
- 一个对象离开他的作用域
- 对象所在的容器被销毁或者是从这个容器中删除对象
引用技术的优点:
如高效、实现逻辑简单、具备实时性,一旦一个对象的引用计数归零,内存就直接释放了。不用像其他机制等到特定时机。将垃圾回收随机分配到运行的阶段,处理回收内存的时间分摊到了平时,正常程序的运行比较平稳
引用技术的缺点:
- 逻辑简单,但实现有些麻烦。每个对象需要分配单独的空间来统计引用计数,这无形中加大的空间的负担,并且需要对引用计数进行维护,在维护的时候很容易会出错。
- 在一些场景下,可能会比较慢。正常来说垃圾回收会比较平稳运行,但是当需要释放一个大的对象时,比如字典,需要对引用的所有对象循环嵌套调用,从而可能会花费比较长的时间。
- 循环引用。这将是引用计数的致命伤,引用计数对此是无解的,因此必须要使用其它的垃圾回收算法对其进行补充。
也就是说,Python 的垃圾回收机制,很大一部分是为了处理可能产生的循环引用,是对引用计数的补充。
标记清除
标记清除是为了解决循环引用的问题,解决容器对象(只有容器对应才会产生循环引用的问题)循环引用的问题。
主要分为两部:
- 标记
标记阶段,遍历所有的对象,如果是可达的(reachable),也就是还有对象引用它,那么就标记该对象为可达 - 清除
清除阶段,再次遍历对象,如果发现某个对象没有标记为可达,则就将其回收
针对循环引用这个问题,比如有两个对象互相引用了对方,当外界没有对他们有任何引用,也就是说他们各自的引用计数都只有1的时候,如果可以识别出这个循环引用,把它们属于循环的计数减掉的话,就可以看到他们的真实引用计数了。基于这样一种考虑,有一种方法(根据分代回收的机制遍历对象),比如从对象A出发,沿着引用寻找到对象B,把对象B的引用计数减去1;然后沿着B对A的引用回到A,把A的引用计数减1,这样就可以把这层循环引用关系给去掉了。
不过这么做还有一个考虑不周的地方。假如A对B的引用是单向的, 在到达B之前我不知道B是否也引用了A,这样子先给B减1的话就会使得B称为不可达的对象了。为了解决这个问题,python中常常把内存块一分为二,将一部分用于保存真的引用计数,另一部分拿来做为一个引用计数的副本,在这个副本上做一些实验。比如在副本中维护两张链表,一张里面放不可被回收的对象合集,另一张里面放被标记为可以被回收(计数经过上面所说的操作减为0)的对象,然后再到后者中找一些被前者表中一些对象直接或间接单向引用的对象,把这些移动到前面的表里面。这样就可以让不应该被回收的对象不会被回收,应该被回收的对象都被回收了。
标记清除的具体流程参考以下链接python垃圾回收机制
注意:垃圾回收机制的阶段,会暂停整个应用程序,等待标记清除结束后才会恢复应用程序的运行。
分代回收
在循环引用对象的回收中,整个应用程序会被暂停,为了减少应用程序暂停的时间,Python 通过“分代回收”(Generational Collection)以空间换时间的方法提高垃圾回收效率。
分代回收是基于这样的一个统计事实,对于程序,存在一定比例的内存块的生存周期比较短;而剩下的内存块,生存周期会比较长,甚至会从程序开始一直持续到程序结束。生存期较短对象的比例通常在 80%~90% 之间,这种思想简单点说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集。这样在执行标记-清除算法时可以有效减小遍历的对象数,从而提高垃圾回收的速度。
思考
在标记-清除中,如果 对象a、b互相引用对方且c引用了a,执行del a和del b后,会发生什么?
a=[1,2]
b=[3,4]
c=a
a.append(b)
b.append(a)
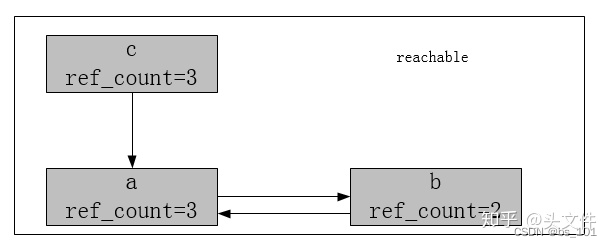
del a
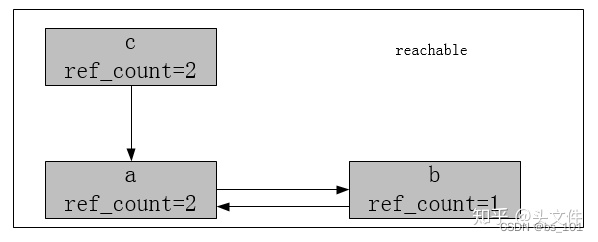
del b
当执行gc扫描时
第一步 标记:
a引用b,将b的ref_count减1到0,b引用a,将a的ref_count减1到1,将b放在unreachable下
第二部 再循环:
因为a是可达的,所以会递归地将从a节点出发可以达到的所有节点标记为reachable下,(又会将b从unreachable中取回放入到reachable中,至此c,a,b都不会被清除)
上述内容参考这篇文章
元类
1、什么是元类
在python中一切皆是对象,所有的对象都是实例化或者说调用类得到的(调用类的过程称为类的实例化)
一切皆为对象,那么类的本质也是一个对象,既然所有的对象都是调用类得到的,那么类必然也是调用了另一个类得到的,这个类就称之为元类;
2、类的创建过程
既然类也是另一个类(元类)创建的对象,那么这个过程是如何的
1、先拿到一个类名:“OldboyTeacher”
2、然后拿到类的父类:(object,)
3、再运行类体代码,将产生的名字放到名称空间中{…}
4、调用元类(传入类的三大要素:类名、基类、类的名称空间)得到一个元类的对象,然后将元类的对象赋值给变量名OldboyTeacher,oldboyTeacher就是我们用class自定义的那个类
class Mymeta(type): # 只有继承了type类的类才是自定义的元类
pass
class OldboyTeacher(object, metaclass=Mymeta):
school = 'oldboy'
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print('%s says welcome to the oldboy to learn Python' % self.name)
# 1、先拿到一个类名:"OldboyTeacher"
# 2、然后拿到类的父类:(object,)
# 3、再运行类体代码,将产生的名字放到名称空间中{...}
# 4、调用元类(传入类的三大要素:类名、基类、类的名称空间)得到一个元类的对象,然后将元类的对象赋值给变量名OldboyTeacher,oldboyTeacher就是我们用class自定义的那个类
上面的class 的写法,跟下面这种写法效果一致
OldboyTeacher = Mymeta("OldboyTeacher",(object,),{...})
单例
1.用元类实现单例
方式一:定制元类实现单例模式
import settings
class Mymeta(type):
def __init__(self,name,bases,dic): #定义类Mysql时就触发
# 事先先从配置文件中取配置来造一个Mysql的实例出来
# self.__instance = object.__new__(self) # 产生对象
#self.__init__(self.__instance, settings.HOST, settings.PORT) # 初始化对象
# 上述两步可以合成下面一步
self.__instance=super().__call__(*args,**kwargs)
super().__init__(name,bases,dic)
def __call__(self, *args, **kwargs): #Mysql(...)时触发
if args or kwargs: # args或kwargs内有值
# 类Mysql创建对象,因为Mysql类本身也是一个对象,那么对象调用自己本身就会执行
# 父类的__call__方法,父类的call方法会调用自己的 __new__和__init__方法
obj=object.__new__(self)
self.__init__(obj,*args,**kwargs)
return obj
return self.__instance
class Mysql(metaclass=Mymeta):
def __init__(self,host,port):
self.host=host
self.port=port
obj1=Mysql() # 没有传值则默认从配置文件中读配置来实例化,所有的实例应该指向一个内存地址
obj2=Mysql()
obj3=Mysql()
print(obj1 is obj2 is obj3)
obj4=Mysql('1.1.1.4',3307)
2.用装饰器实现
方式二:定义一个装饰器实现单例模式
import settings
def singleton(cls): #cls=Mysql
_instance=cls(settings.HOST,settings.PORT)
def wrapper(*args,**kwargs):
if args or kwargs:
obj=cls(*args,**kwargs)
return obj
return _instance
return wrapper
@singleton # Mysql=singleton(Mysql)
class Mysql:
def __init__(self,host,port):
self.host=host
self.port=port
obj1=Mysql()
obj2=Mysql()
obj3=Mysql()
print(obj1 is obj2 is obj3) #True
obj4=Mysql('1.1.1.3',3307)
obj5=Mysql('1.1.1.4',3308)
print(obj3 is obj4) #False
3.用__new__方法实现
class Mysql:
__instance=None
def __init__(self,host,port):
self.host=host
self.port=port
def __new__(cls, *args, **kwargs):
if cls.__instance:
return cls.__instance
# python3中调用父类的__new__方法,不需要传*args,**kwargs参数
cls.__instance = object.__new__(cls)
return cls.__instance
obj1=Mysql('1.1.1.2',3306)
obj2=Mysql('1.1.1.3',3307)
print(obj1 is obj2) #True
















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









