







王树森关于强化学习的视频课程讲的非常好,这篇文章算是我对课程的一份笔记,便于之后回顾。
视频时长有限,难免其中有些点没有讲透彻,或者前后知识点的关联没有说明。因此这份笔记并不是完全照搬原视频的章节顺序和内容,而是根据自己的理解做了调整,容易和重复的部分我会精简,困难和含糊的地方会多做解释,并会结合其它课程和资料进行补充。
文章目录
基本概念
强化学习中的概念很多,之后所有的数学推导都是基于这些概念的,一开始一定要区分清楚。
环境、状态、动作这些最基础的定义就不赘述了。

折扣回报
U
t
U_t
Ut依赖于未来的每一个动作和状态,所以它的随机性来源于策略函数
π
\pi
π和状态转移函数
p
p
p。

动作价值函数
Q
π
Q_\pi
Qπ,是
U
t
U_t
Ut的期望,相当于未来所有状态和动作的随机性都被消除了,
Q
π
Q_\pi
Qπ只依赖于当前状态
s
t
s_t
st和动作
a
t
a_t
at,且与策略函数
π
\pi
π有关。
Q
π
Q_\pi
Qπ的含义为:给定策略函数
π
\pi
π,
Q
π
Q_\pi
Qπ能给状态
s
t
s_t
st下所有动作打分。

如果将
Q
π
Q_\pi
Qπ关于
π
\pi
π求最大化,可以进一步消除
π
\pi
π,即在所有可能的策略函数
π
\pi
π中,选择最好的也就是使
Q
π
Q_\pi
Qπ最大的那个
π
\pi
π,这样就得到了最优价值函数
Q
∗
Q^*
Q∗。
Q
∗
Q^*
Q∗与
π
\pi
π无关,它可以给状态
s
t
s_t
st下所有动作打分,所以
Q
∗
Q^*
Q∗可以指导Agent的决策。

如果将
Q
π
Q_\pi
Qπ对随机变量
A
A
A求期望,就得到了状态价值函数
V
V
V。
V
π
V_\pi
Vπ和动作
A
A
A无关,给定策略函数
π
\pi
π,
V
π
V_\pi
Vπ可以用来评价状态
s
t
s_t
st的好坏,即为当前局势打分。
动作 A A A的概率密度函数是 π \pi π,如果 A A A是离散变量,这个期望就是求连加,如果 A A A是连续变量,就是求积分。连续动作空间的强化学习是另一个方向,在最后几节会提到,在那之前我们都默认动作是离散的。

V
π
V_\pi
Vπ再对
S
S
S求期望,可以消除状态的影响,评价策略函数
π
\pi
π的好坏。

强化学习的任务就是学习策略函数
π
\pi
π或者最优价值函数
Q
∗
Q^*
Q∗,如果有
π
\pi
π函数,那么就可以通过随机采样选取动作。如果有
Q
∗
Q^*
Q∗函数,那就选择价值最大的那个动作,这两者都可以指导Agent运动。
前者叫做策略学习(Policy-Based),后者叫做价值学习(Value-Based)。

价值学习(Value-Based)
DQN原理
DQN是一种价值学习方法,用一个神经网络来近似
Q
∗
Q^*
Q∗函数,目标是获得最多的回报,
W
W
W是神经网络的参数。

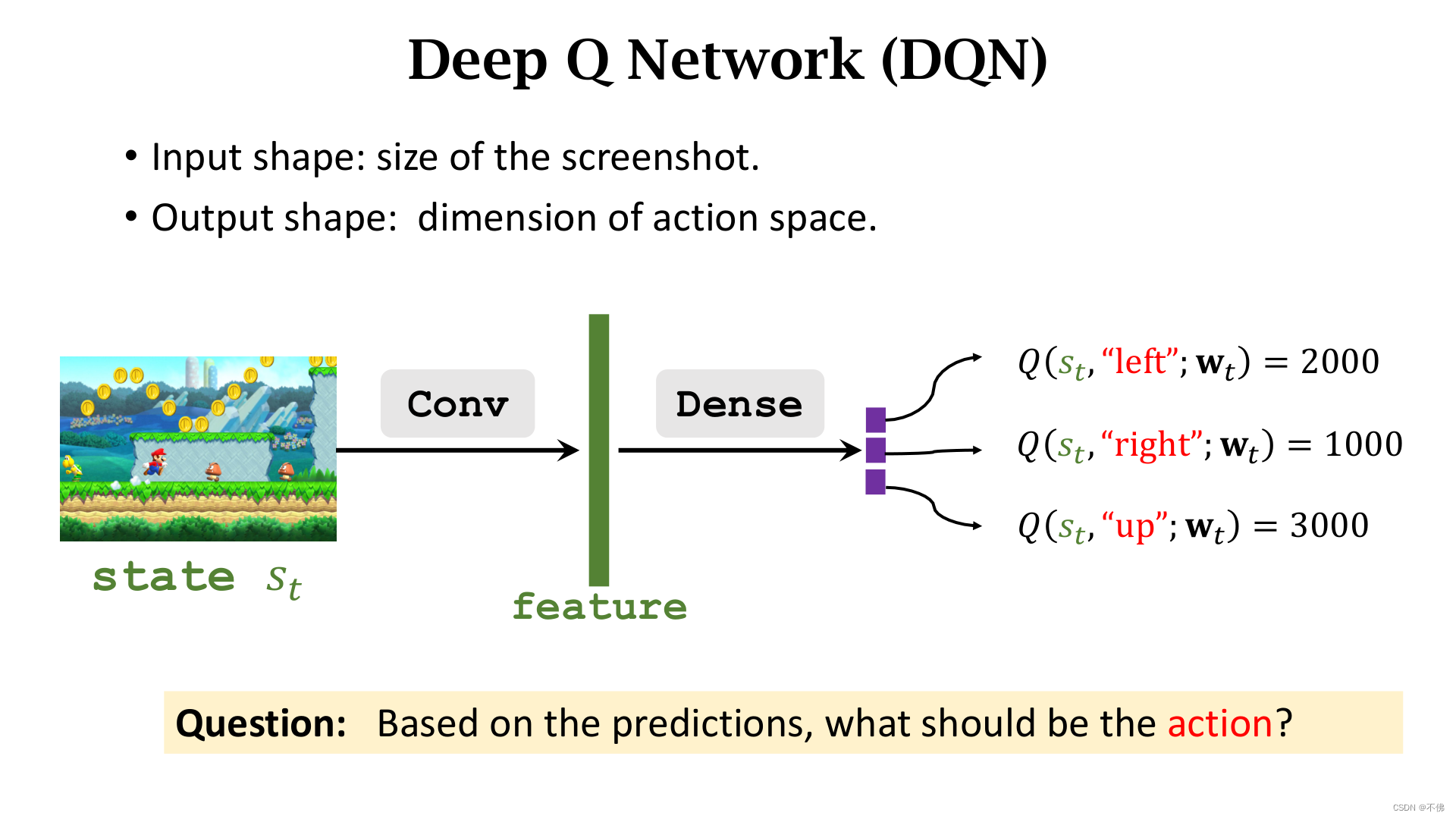
对超级玛丽游戏,DQN的网络结构可以如下图,输入状态
s
t
s_t
st,输出各个动作的价值,选择最大价值的动作。
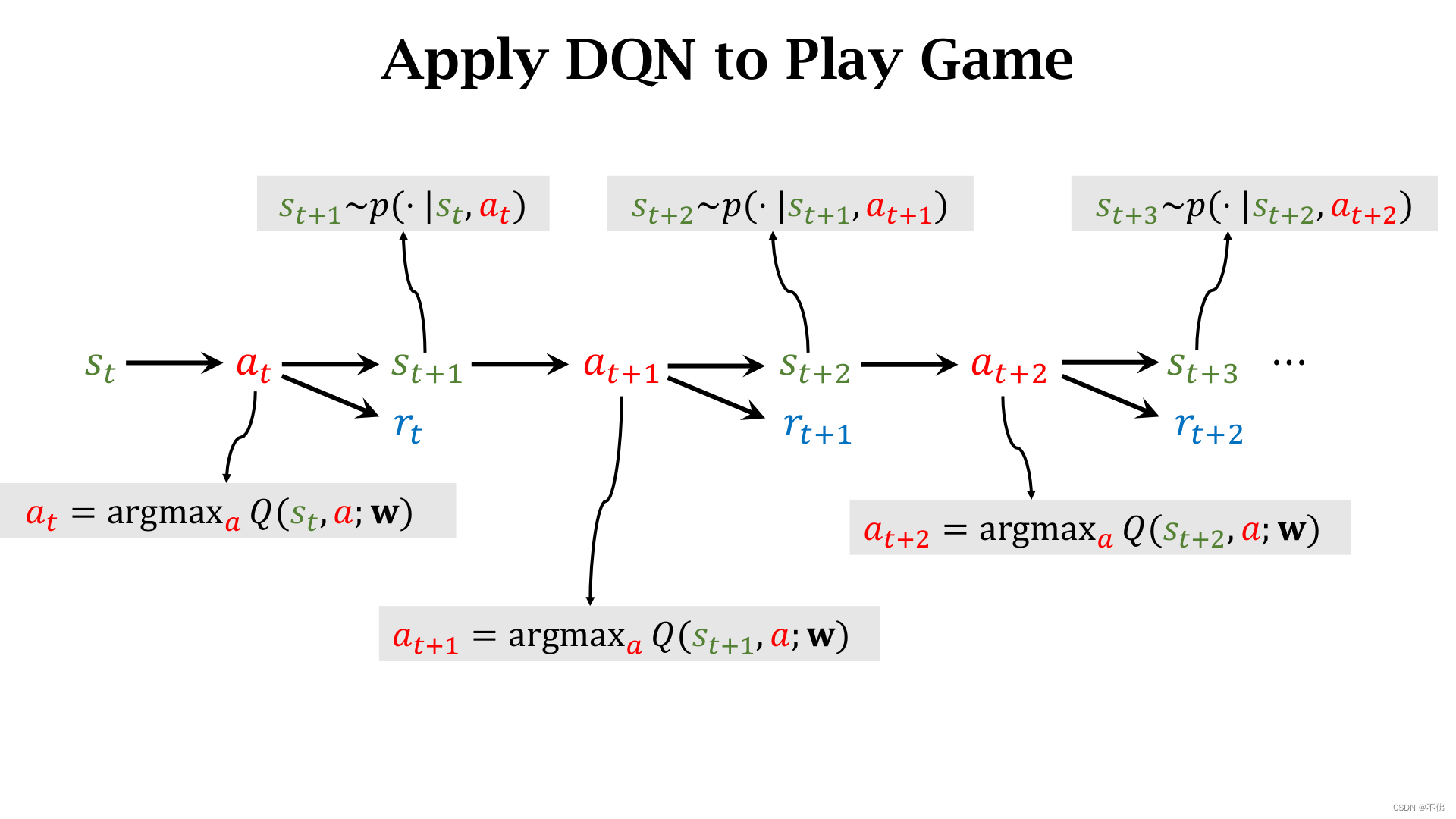
这里需要注意一下,下面两个图讲的是DQN的使用流程,在训练时并不是一直选择最大价值的动作,而是需要随机探索不同动作的。
重复以下步骤就可以玩游戏了
Temporal Difference (TD)算法
训练DQN,或者说学习 Q ∗ Q^* Q∗最常用的是TD(时序差分)算法,下面用一个例子来帮助理解TD算法。
假设要从NYC去Atlanta,模型
Q
Q
Q预测需要花费1000分钟,而我们走完这段路,发现实际用了860分钟,那么则很容易就可以定义损失LOSS,用梯度下降法更新模型
Q
Q
Q的参数。

可如果我们只走了一段路程,还没有到达终点,那么模型能不能只根据我们已经走了的这段路程进行学习呢?答案是可以的,这就是TD算法解决的问题。
例如我们走到途中的一站DC时,实际花费了300分钟,而模型估计到达Atlanta还需要600分钟,那么原来估计的1000分钟就被更新为900分钟,这个900就被称为TD target,它比1000分钟更可靠,因为其中包含了一部分真实观测值300。所以可以把TD target作为目标去更新模型原来的估计1000,1000和900的差值就称为TD error。


也可以这样理解TD算法,模型估计NYC到DC的时间其实是1000-600=400,而实际观测时间是300,我们自然可以更新这一段估计。

DQN+TD算法
根据折扣回报的定义,可得到以下式子:

等式两边做期望,对
U
t
U_t
Ut的期望用神经网络
Q
Q
Q的输出来近似,对
R
t
R_t
Rt的期望用当前时刻奖励
r
t
r_t
rt来近似。

对照TD算法,式子左侧就是模型在
t
t
t时刻的估计,式子右侧是模型在得到真实奖励
r
t
r_t
rt后,在
t
+
1
t+1
t+1时刻的估计,也就是TD target。

这样就可以用TD算法来更新模型参数了,那么这里
t
+
1
t+1
t+1时刻的动作
a
t
+
1
a_{t+1}
at+1是怎么选的呢?其实就是
Q
Q
Q函数对动作
a
a
a求最大化,选择让
Q
Q
Q函数输出最大的那个动作。

DQN使用TD算法训练步骤:

策略学习(Policy-Based)
策略学习原理
策略学习就是想办法近似策略函数
π
\pi
π。

如果状态是有限的,我们可以列一个表直接学习
π
\pi
π函数:
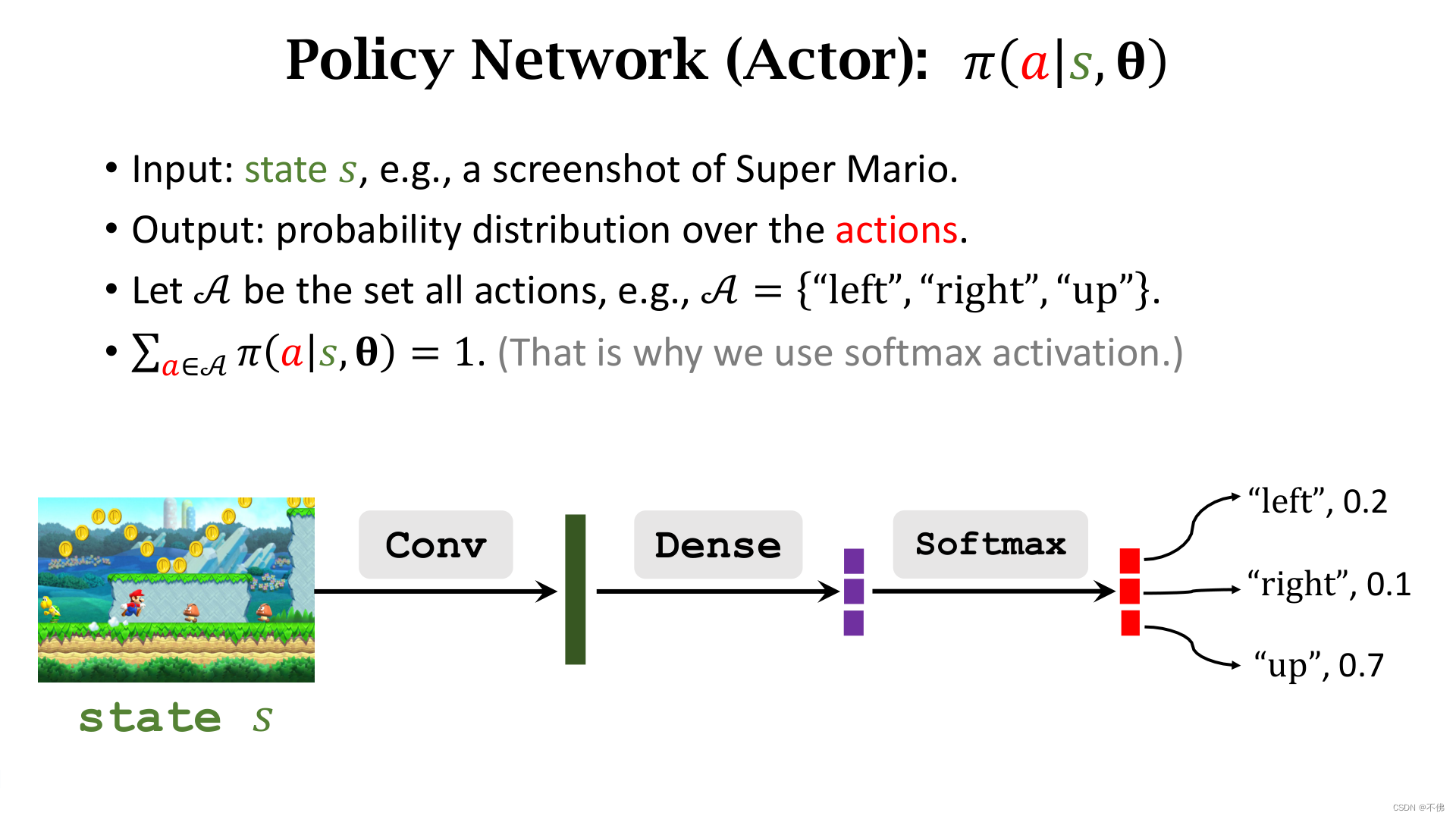
但很多情况下状态是无限的,比如超级玛丽游戏,这时候我们就要找一个函数来做函数近似,一般选择用神经网络来做近似,这个神经网络就被称为policy network。
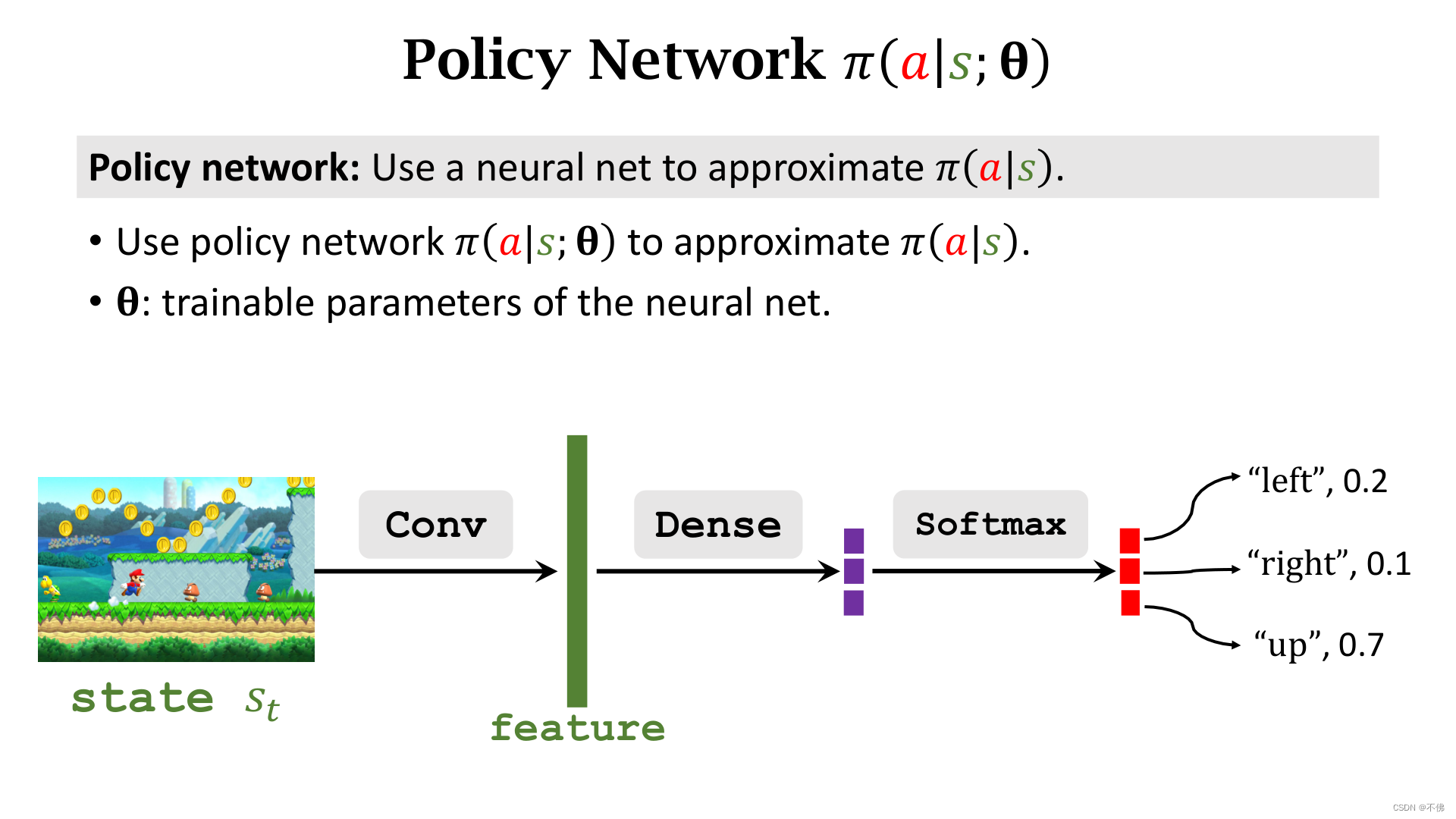
回顾一下状态价值函数的定义,是
Q
π
Q_\pi
Qπ对动作
A
A
A的期望, 这里我们只讨论离散动作,它就可以写成一系列连加的形式:

我们用神经网络近似
π
\pi
π函数,参数为
θ
\theta
θ,那么状态价值函数
V
π
V_\pi
Vπ也被近似。

给定状态
s
s
s,如果策略网络
π
\pi
π越好,
V
V
V的值越大。因此我们可以把策略学习的目标函数设为
V
V
V关于状态
S
S
S的期望
J
(
θ
)
J(\theta)
J(θ),它就是对策略的评价。接下来的目标就是改进
θ
\theta
θ来增大
J
J
J,如果可以求得
V
V
V对
θ
\theta
θ的梯度(Polocy gradient),就可以用随机梯度上升的方式学习
θ
\theta
θ。这里
V
V
V对
θ
\theta
θ的梯度,可以看成是
J
J
J对
θ
\theta
θ的随机梯度,随机性来自于
S
S
S。

Polocy Gradient
接下来的重点是如何求Polocy Gradient,根据以下推导可以得到Polocy Gradient的第一种形式。这里我们假设
Q
π
Q_\pi
Qπ与
θ
\theta
θ无关,以下两个推导都进行了简化,但不影响结果。
如果动作
A
A
A是离散的,可以按照这个式子算出梯度,但实际上我们一般不这么算,而是采用第二种形式。

第二种形式是将式子右侧凑成一个期望,然后用蒙特卡洛近似来算这个梯度。

我们得到了Polocy Gradient的两种形式:

对第一种形式,我们可以对每个动作分别计算然后求和,如果动作空间过大,计算量就会很大,如果动作是连续的,那就没办法求了。

对连续动作,可以用第二种形式,因为我们把式子右侧凑成了关于函数
g
g
g的期望,所以
g
g
g就是策略梯度的无偏估计。我们根据概率密度函数
π
\pi
π随机采样一个动作
a
^
\hat a
a^,计算相应的
g
g
g值,就可以用来近似策略梯度了。这种用采样近似期望的方式就是蒙特卡洛近似,其实就是期望的点估计。第二种形式的算法对离散动作也是适用的。

策略学习总结
策略学习算法步骤:

这里还有一个问题我们一直没有考虑,就是这个
Q
π
Q_\pi
Qπ的值怎么算?
第一种方法是REINFORCE。因为
Q
π
Q_\pi
Qπ的定义是回报
U
t
U_t
Ut的期望,所以我们可以玩完一局游戏后,把真实观测到的
u
t
u_t
ut作为
q
t
q_t
qt的近似。

第二种方法是再用一个神经网络来近似
Q
π
Q_\pi
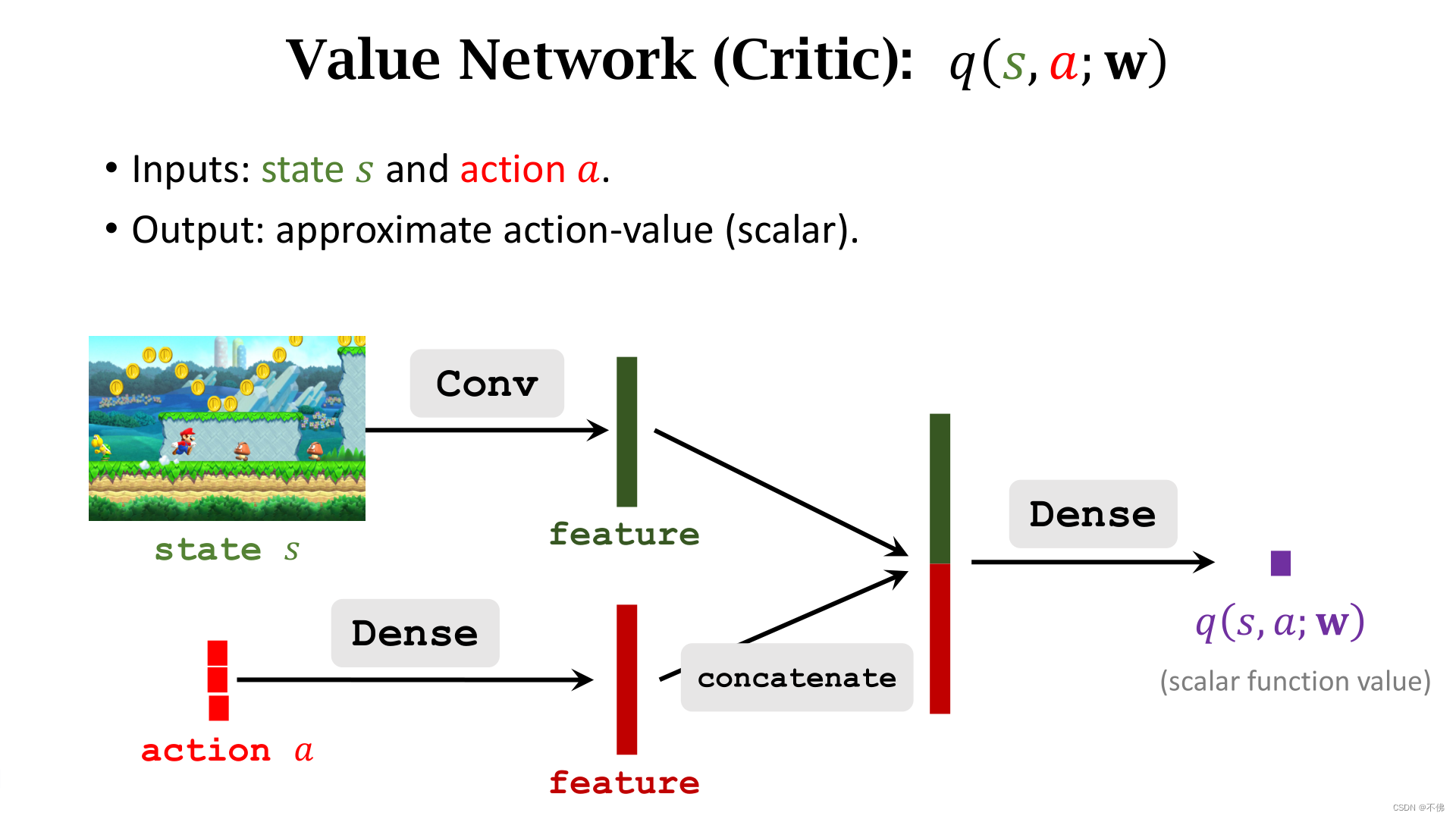
Qπ,这就有了两个网络,一个负责动作,一个负责评价,这就是Actor-Critic算法。

Actor-Critic
Actor-Critic方法是价值学习和策略学习的结合。
我们用策略网络来近似
π
\pi
π函数,负责做动作,称为Actor。用价值网络近似
Q
π
Q_\pi
Qπ,负责给动作打分,称为Critic。
如果细心的话就会发现,这里的价值网络学的是
Q
π
Q_\pi
Qπ,而不是之前在DQN中学习的
Q
∗
Q^*
Q∗。这是Sarsa算法和Q-Learning算法的区别。
这里补充一下莫烦老师对于为什么要有 Actor 和 Critic的看法:
我们有了像 Q-learning 这么伟大的算法, 为什么还要瞎折腾出一个 Actor-Critic? 原来 Actor-Critic 的 Actor 的前生是 Policy Gradients , 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪. 那为什么不直接用 Policy Gradients 呢? 原来 Actor Critic 中的 Critic 的前生是 Q-learning 或者其他的 以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率。
总之,Actor-Critic结合了价值学习能单步更新的优点和策略学习能处理连续动作的优点。

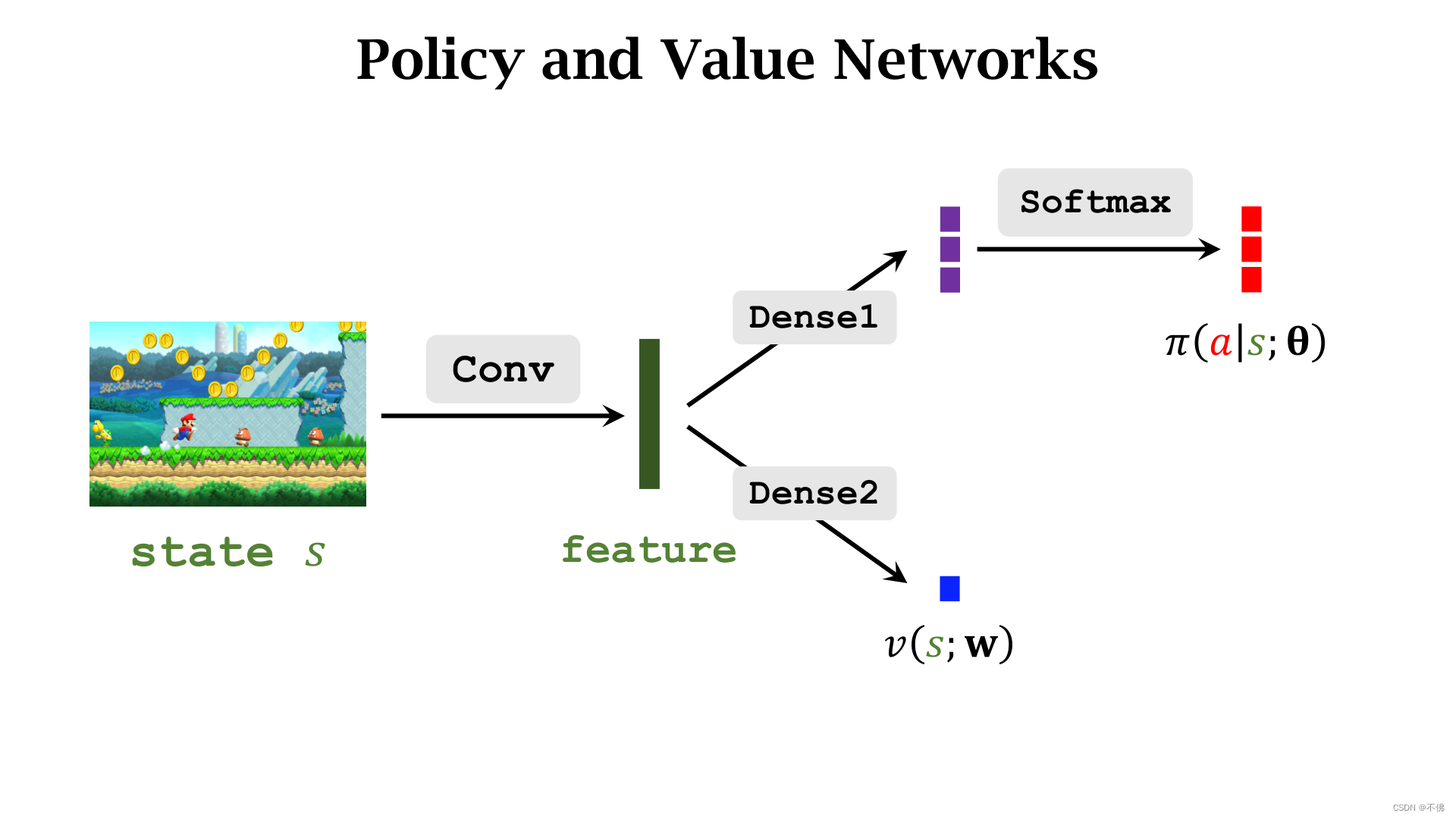
策略网络和价值网络结构大致如下:
训练策略网络
π
\pi
π是为了让
V
V
V值增大,这里对动作的评分是由价值网络
q
q
q作出的。
训练价值网络
q
q
q是为了让评分更精准,
q
q
q是根据从环境中真实获得的奖励来学习的。

总体训练步骤

详细说明:用TD算法更新价值网络
q
q
q,用策略梯度更新策略网络
π
\pi
π。


回过头来看的时候,我在这里产生了个呆呆的疑问:视频里强调采样的下一个时刻的动作只是用来计算
q
t
+
1
q_{t+1}
qt+1,并没有真正执行。那这更新的策略和实际的行动策略就不是一个了,那不是Off-policy吗?可是这里学习价值函数用的是Sarsa,不应该是On-policy的方法吗?
我觉得原因出在:这里的动作价值函数 q q q并没有决定行动策略,它只是个打分的辅助函数,最终是使用策略函数 π \pi π来指导Agent运动,我把这一点跟价值学习混淆了。而 π \pi π函数用策略梯度更新,只跟当前时刻采样的动作有关,这是真实的动作,并没有用到下一时刻的假想动作,因此AC算法是On-policy的。之后介绍的A2C也是On-policy的,所以PPO算法对它进行了改进。
这段话如果没看懂也没关系,往后看就能明白啦。

在实际实现中,最后一步常用
δ
t
\delta_t
δt代替
q
t
q_t
qt,这其实是使用了Baseline,任何接近
q
t
q_t
qt的值都可以作为Baseline,使用Baseline不会影响策略梯度的期望,但能降低方差,加快收敛,往往效果更好。关于Baseline的内容这里做个了解就行,之后会专门细讲。

在训练结束之后,只使用策略网络
π
\pi
π指导Agent运动,价值网络
q
q
q不再使用。

Sarsa vs Q-Learning
Sarsa和Q-Learning使用的都是TD算法,也都有表格版本(适用于有限的动作和状态)和DQN版本。区别就在于一个是学习动作价值函数 Q π Q_\pi Qπ,一个是学习最优动作价值函数 Q ∗ Q^* Q∗。Sarsa用在Critic,Q-Learning用在DQN。


视频中并没有给出这两者的更多对比,我看了些其它资料,大概总结如下:
- Sarsa和Q-Learning的本质区别来自于对于Q值的更新方式不同,Sarsa使用下一步的实际动作来作为更新,而Q-Learning选取下一步Q值最大的动作作为更新,但并没有真正采取这个动作。
- 根据是否允许行为策略不同于目标策略 ,强化学习方法可以分为异策略(Off-policy)和同策略 (On-policy)。Q-Learning的Target Policy是绝对的 g r e e d y greedy greedy策略,但在学习探索过程中决定Agent行动的Behavior Policy的却和Sarsa同是 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略,即以 ϵ \epsilon ϵ的概率进行随机探索。Q-Learning行动的策略和改进的策略不是同一个,因此它是Off-policy的,Sarsa则是On-policy的。
- 因为Q-Learning一直追求最大价值,虽然随机探索会遭遇危险,但它不在乎,所以最终策略表现得贪婪勇敢,而Sarsa则表现得比较稳健。
我觉得可以这样理解:Q-Learning是一个有理想信念的人,为了实现中华民族伟大复兴和共产主义,为了所有程序员不必996,都有一头茂密的秀发,它愿意为之不断战斗流血牺牲,虽然会遭遇危险,但不会停下奔向理想的脚步。而Sarsa只是个普通人,没有那么崇高的理想,只能考虑每一步的收获和代价,一边抱怨着996一边加班写技术博客,在生活的压力下,拼尽全力成为一个普通人。
不说了,已经在哭了。
价值学习技巧
根据前边讲的DQN和TD算法,可以开始训练一个Agent了,但效果一般不太好。下面介绍一些训练的高级技巧,可以提升效果加快收敛。
Multi-Step TD Target
可以使用多步的奖励来定义TD Target,效果更好,单步的TD Target可以看作多步的特例。

思路和实现都很简单,没什么可讲的,就贴一下Sarsa和Q-Learning的区别。


Experience Replay
之前我们使用完一条transition之后,这条经验就被丢弃了,这是一种浪费。第二个问题是我们总是顺序使用相邻的transition进行训练,实验表明这种相邻经验的相关性对训练是有害的。因此我们选择经验回放的方式进行训练。
注意:经验回放不适用于On-policy方法,旧策略采样得到的动作不能用于新策略的更新。


将一系列transition存入一个Replay Buffer,这个序列是有限的,长度为n,当序列满了之后再加入新的transition会删除最早的那条transition,n为超参数,一般设的很大。


在训练中,我们从这个Replay Buffer中随机抽取一条或多条transition进行梯度下降,这是SGD(随机梯度下降)和Mini-Batch GD(小批量梯度下降)的区别。

Prioritized Experience Replay
Experience Replay有许多改进,优先经验回放是其中的一种。它的思路是每个transition重要性应该不同,对比较少出现的transition,应该加大学习力度。我们用TD Error
δ
t
\delta_t
δt来衡量transition的重要性,因为对比较少见的transition,预测值和真实值的差距会更大。

优先经验回放就是用重要性抽样代替均匀抽样,有2种方式,一种就是将抽样概率直接正比于
δ
t
\delta_t
δt,第二种是将抽样概率反比于
δ
t
\delta_t
δt的排序。总之,
δ
t
\delta_t
δt越大,抽样概率越大。
使用重要性抽样后会导致一条transition被多次学习,应当相应调整学习率。
β
\beta
β是个超参数,抽样概率越大,学习率越小。

每次选择一条transition进行训练的时候,更新它的
δ
t
\delta_t
δt。对最新收集到还没进行训练的transition,把它的
δ
t
\delta_t
δt设成最大,拥有最高的优先级。

总结:
δ
t
\delta_t
δt越大,抽样概率越大,学习率越小。

Target Network & Double DQN
DQN在更新参数的时候,又使用了自己对下个动作的预测值,这是一种Bootstrapping(自举)。

用TD算法训练DQN会存在高估问题,原因有二:TD Target中的最大化操作导致高估,再用自己更新自己(自举)会加大高估。

DQN相当于对动作价值加了噪声的估计,加噪声不影响均值,但会影响最大值,对它求最大化会导致高估真实动作价值。

总之,求最大化导致高估TD Target,导致DQN高估。

用高估的值再作为目标来更新,更加剧了高估。

高估本身不是问题,因为最终从DQN的输出中选择的是价值最大动作,只要高估是均匀的,并不会影响结果。但不幸的是,因为每一次更新都会加剧高估,所以高估的程度和同一个
(
s
t
,
a
t
)
(s_t,a_t)
(st,at)的transition出现的频率有关,而这显然是不均匀的。

介绍缓解高估问题的2个方式:Target Network 和 Double DQN。
Target Network 是使用一个新的网络来计算TD Target,这样可以缓解Bootstrapping带来的问题。

和原来唯一的区别就是TD Target是用Target Network计算的。

Target Network的参数隔一段时间更新,可以直接拷贝源网络的参数,也可以用加权平均。

因为最大化方式的存在,而且Target Network依赖于原网络,并不能完全解决高估问题。
在Target Network基础上,Double DQN做了个非常小的改动,但能取得更好的效果,缓解最大化导致的高估问题。
我们把计算TD Target分成2步,第一步是选择动作
a
∗
a^*
a∗,第二步是带入动作计算TD Target。Target Network就是把原来在DQN上进行的这两步,都变成了在Target Network上进行。而Double DQN则是在DQN上选择动作,在Target Network上计算TD Target,显然这样得到的TD Target值会较小。

Double DQN同时缓解了最大化和自举两个方面的高估影响。
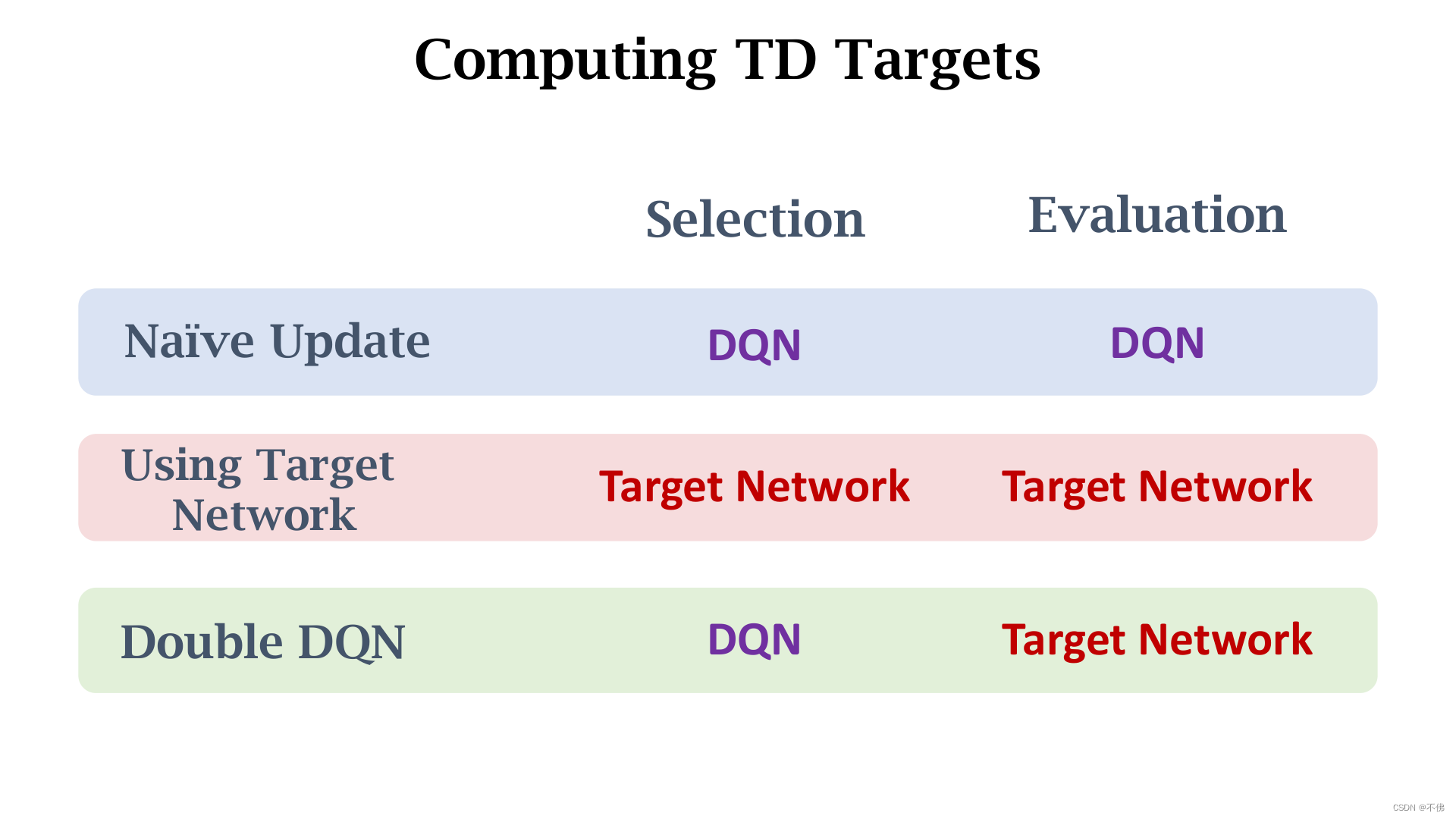
Dueling Network
Dueling Network是对DQN网络结构的改进,在介绍它之前要先做一些数学定义和推导。

定义最优优势函数
A
∗
A^*
A∗为最优动作价值函数
Q
∗
Q^*
Q∗和最优状态价值函数
V
∗
V^*
V∗的差。
Q
∗
Q^*
Q∗评价当前状态下做动作
a
a
a的好坏,
V
∗
V^*
V∗评价当前状态的好坏,将
V
∗
V^*
V∗作为baseline,
A
∗
A^*
A∗表示动作
a
a
a对于baseline的优势。动作
a
a
a越好,
A
∗
A^*
A∗越大。

这里直接给出定理1:
V
∗
V^*
V∗等于
Q
∗
Q^*
Q∗对动作
a
a
a求最大化。
对最优优势函数等式两边关于动作
a
a
a求最大化,等式依然成立。可以得到
A
∗
A^*
A∗关于
a
a
a的最大化等于0。

将最优优势函数的定义移项,并在最后减去上一步我们推出的等于0的这一项,减去这一项的作用我们之后讲。这就得到了Dueling Network中最重要的等式,记作定理2。

用两个网络分别近似
V
∗
V^*
V∗和
A
∗
A^*
A∗,通过两个网络组合得到Dueling Network,跟DQN一样也记作
Q
Q
Q网络。Q网络就是对最优动作价值函数的近似,它和DQN具有完全相同的作用。
A
A
A网络和
V
V
V网络共用卷积层参数,
A
A
A网络的输出是一系列动作的价值,
V
V
V网络的输出是一个实数,它们相加之后再减去
A
A
A网络输出中的最大值,就是Dueling Network的输出,和普通DQN的输出含义完全一样。
Dueling Network只是网络结构的改进,训练过程跟DQN也完全一样,没有任何区别,同样可以应用前几节的价值学习技巧,效果更好。唯一要注意的是,Dueling Network也是作为一个网络一起训练的,并不是单独训练
A
A
A网络和
V
V
V网络。

最后回答一下为什么需要在等式最后减去等于0的一项,这是为了解决不唯一性的问题,不唯一性是指对同一个
Q
Q
Q网络的输出,
A
A
A网络和
V
V
V网络不是唯一确定的,例如
A
A
A网络输出都增大10,
V
V
V网络输出减少10,那么总的网络输出不变。这样会导致网络可以随意波动不易训练,而减去
A
A
A网络输出的最大值可以避免这个问题,对训练中保持网络的稳定很重要。

实际中,用mean代替max效果更好,暂无理论依据,纯粹是实验结果。

策略梯度中的baseline
接下来讲策略学习中的baseline,如果对策略学习的流程已经迷糊了,可以先回去复习一下。
Baseline
回顾一下策略梯度,之前推导过。

下面一通操作,就是把
l
n
ln
ln的求导展开,证明只要
b
b
b和
A
A
A无关,这个式子恒等于0,所以可以把它作为baseline。

得到带有baseline的策略梯度:

回忆一下,策略学习中我们是用蒙特卡洛近似,用
g
(
a
t
)
g(a_t)
g(at)来近似策略梯度进行梯度上升。

我们已经证明了
b
b
b的取值不会影响
g
(
a
t
)
g(a_t)
g(at)的期望,但会影响具体
g
(
a
t
)
g(a_t)
g(at)的值,也就是说会影响方差,如果b选的比较好,比较接近
Q
π
Q_\pi
Qπ,可以降低蒙特卡洛近似的方差,加快梯度上升的收敛。
李宏毅老师是这么解释baseline的作用的:如果不加baseline,可能价值函数对动作的打分都是正的,虽然看似不影响每个动作分数的相对关系,但实际上我们训练的过程只是做了少量的采样,所以采样是不公平的,有些动作可能根本没有被采样过,但因为别的被采样的动作得分都上升导致它得分下降,这是不合理的,设立baseline可以让这个得分有正有负,每个动作被选择的概率上升还是下降,取决于它得分和baseline的相对关系。
所谓的降低方差听起来不好理解,实际就是方差小的时候,做少量的采样就能得到不错的近似,而方差大的时候,少量的采样很可能偏离真实值。
b
b
b取0就是不使用baseline,没什么好说的。
b
b
b另一个常见的取值是
V
π
V_\pi
Vπ,因为
V
π
V_\pi
Vπ是
Q
π
Q_\pi
Qπ的期望,它很接近
Q
π
Q_\pi
Qπ,且与动作
A
A
A无关。


最后在这里填一下远古的坑,在Actor-Critic章节的最后,提了一下用
δ
t
\delta_t
δt代替
q
t
q_t
qt,算是一种baseline,视频中没有比较过这种baseline的好坏,但我觉得效果肯定是不如用
V
π
V_\pi
Vπ的,不然何至于如此麻烦,下一节还要专门用一个网络来近似
V
π
V_\pi
Vπ。
REINFORCE with Baseline
策略学习的核心就是近似策略梯度,回忆一下,在Actor-Critic章节中,我们用两个神经网络近似了 π \pi π函数和 Q π Q_\pi Qπ函数,一个负责行动,一个负责打分。当时提到过,如果不用神经网络近似 Q π Q_\pi Qπ,还可以选择玩完一局游戏,用真实的回报 u t u_t ut来近似 Q π Q_\pi Qπ,这种方式叫REINFORCE ,这节介绍的就是带上了baseline的REINFORCE。
Q π Q_\pi Qπ用 u t u_t ut近似了,可又多了一个baseline V π V_\pi Vπ,,这项怎么算呢?还是用万能神经网络近似。


这里用了3个近似:策略梯度的近似;
Q
π
Q_\pi
Qπ的近似;
V
π
V_\pi
Vπ的近似;前两个都是蒙特卡洛近似。


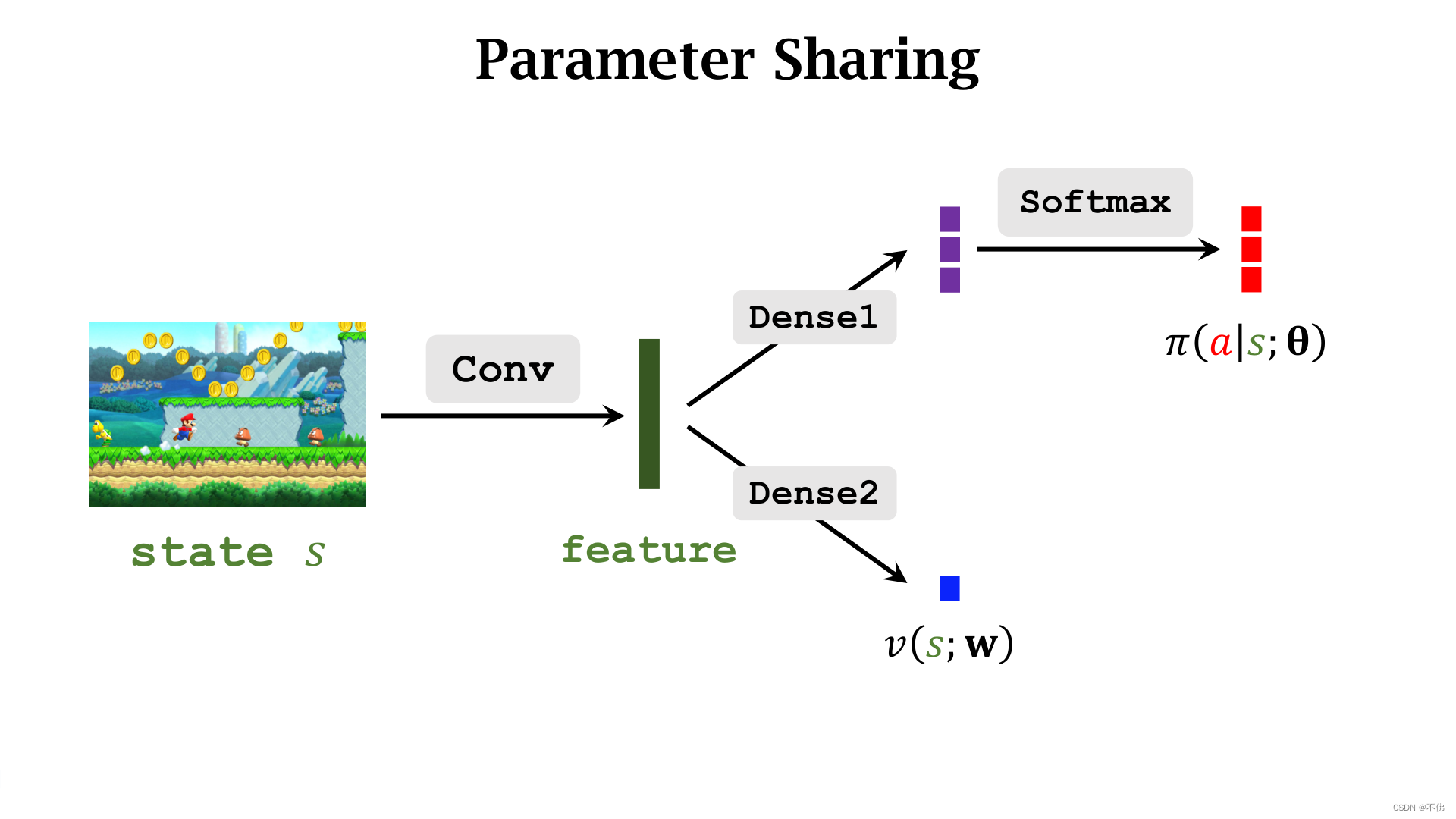
策略网络
π
\pi
π和价值网络
v
v
v可以共用卷积层,
v
v
v网络的输出是一个实数。结构如下图:
用梯度上升来学习策略网络。

用回归来学习价值网络。
V
π
V_\pi
Vπ是对回报的期望,所以回归的目标就是真实的回报
u
t
u_t
ut。

算法步骤总结。需要注意的是:玩完游戏得到的一系列轨迹,并不是只能作为一条数据来学习,对于每个时刻都可以算一次
u
t
u_t
ut,有n个时刻就可以更新网络n次。

Advantage Actor-Critic (A2C)
将baseline应用在Actor-Critic上,就得到了Advantage Actor-Critic (A2C)。
A2C最终的算法实现很简单,困难的是它使用的公式是怎么得到的,以下数学推导部分小盆友们根据心情自行取用。
数学警告!!!
首先,根据A2C的名字,可以猜到它是在Actor-Critic上增加了baseline,用到了优势函数,因此它在更新策略网络时使用的策略梯度,应该是以下形式:

这个策略梯度和上一节REINFORCE with Baseline中是一样的,策略函数
π
\pi
π已经用神经网络近似了,但
Q
π
Q_\pi
Qπ和
V
π
V_\pi
Vπ还不知道怎么算,REINFORCE方法是用真实的
u
t
u_t
ut近似
Q
π
Q_\pi
Qπ,用另一个网络近似
V
π
V_\pi
Vπ,A2C不是这样做的。
根据
Q
π
Q_\pi
Qπ的定义,通过以下推导,建立了
Q
π
Q_\pi
Qπ和
V
π
V_\pi
Vπ的联系,得到定理一。

将定理一代回
V
π
V_\pi
Vπ的定义,得到定理二。

这两个定理分别把
Q
π
Q_\pi
Qπ和
V
π
V_\pi
Vπ写成期望的形式,这样是为了做蒙特卡洛近似。
这里我产生了一个疑问,这怎么能近似成同一个东西的?那带入到策略梯度的式子里,
Q
π
−
V
π
Q_\pi-V_\pi
Qπ−Vπ不是没了??
思考后我觉得是这样的:定理2的期望是跟动作
A
A
A有关,baseline的基本要求就是不能和
A
A
A有关,所有第二个近似是不能代人策略梯度的。

把定理1代人策略梯度,这样括号内就只跟
V
π
V_\pi
Vπ有关了,这样就可以用一个神经网络来近似它。

接下来就是常规操作了,用梯度上升更新策略网络
π
\pi
π。

定理2是为了应用TD算法更新价值网络
v
v
v,因为之前的价值学习都是学的
Q
π
Q_\pi
Qπ,而这次是
V
π
V_\pi
Vπ。
思路理清楚接下来就简单了,还是用TD算法,跟之前学
Q
π
Q_\pi
Qπ的步骤完全一样。


最后理解一下,策略梯度的括号里应该是价值函数对动作的评价(动作的优势),用来指导策略网络的学习,可是括号内并没有动作,它是怎么评价动作的呢?下图中框出的两项都表示价值网络对当前时刻的评价(未来价值的期望),区别在于前一项是在下一时刻作出的,和当前动作
a
t
a_t
at有关,后一项是在当前时刻作出的,和
a
t
a_t
at无关,所以它们的差可以反映动作
a
t
a_t
at带来的优势,
a
t
a_t
at越好,这个差值越大。

数学警告结束!!!
总之,一通推导的最终作用是:学习 V π V_\pi Vπ来评价动作价值,而不是学习原来AC里的 Q π Q_\pi Qπ。
推出公式后,A2C的网络结构和训练步骤就都很简单了,相较AC还省去了采样下个时刻动作的步骤。我贴一下图,不再详解。

REINFORCE vs A2C
对比一下前两节课讲的REINFORCE with Baseline和A2C的异同。首先他们的网络结构完全一样,区别在于 v v v网络的作用不一样,在REINFORCE中只是作为baseline,而再A2C中是作为critic评价动作的好坏。
再对比一下训练过程,唯一的区别就是在计算error时,A2C用的
y
t
y_t
yt,REINFORCE用的
u
t
u_t
ut。


如果把A2C中的TD Target改写成多步的形式,在计算
y
t
y_t
yt时可以使用多步的真实奖励。

可以发现,如果使用了之后全部的真实奖励,那么
y
t
y_t
yt就等于了总回报
u
t
u_t
ut。
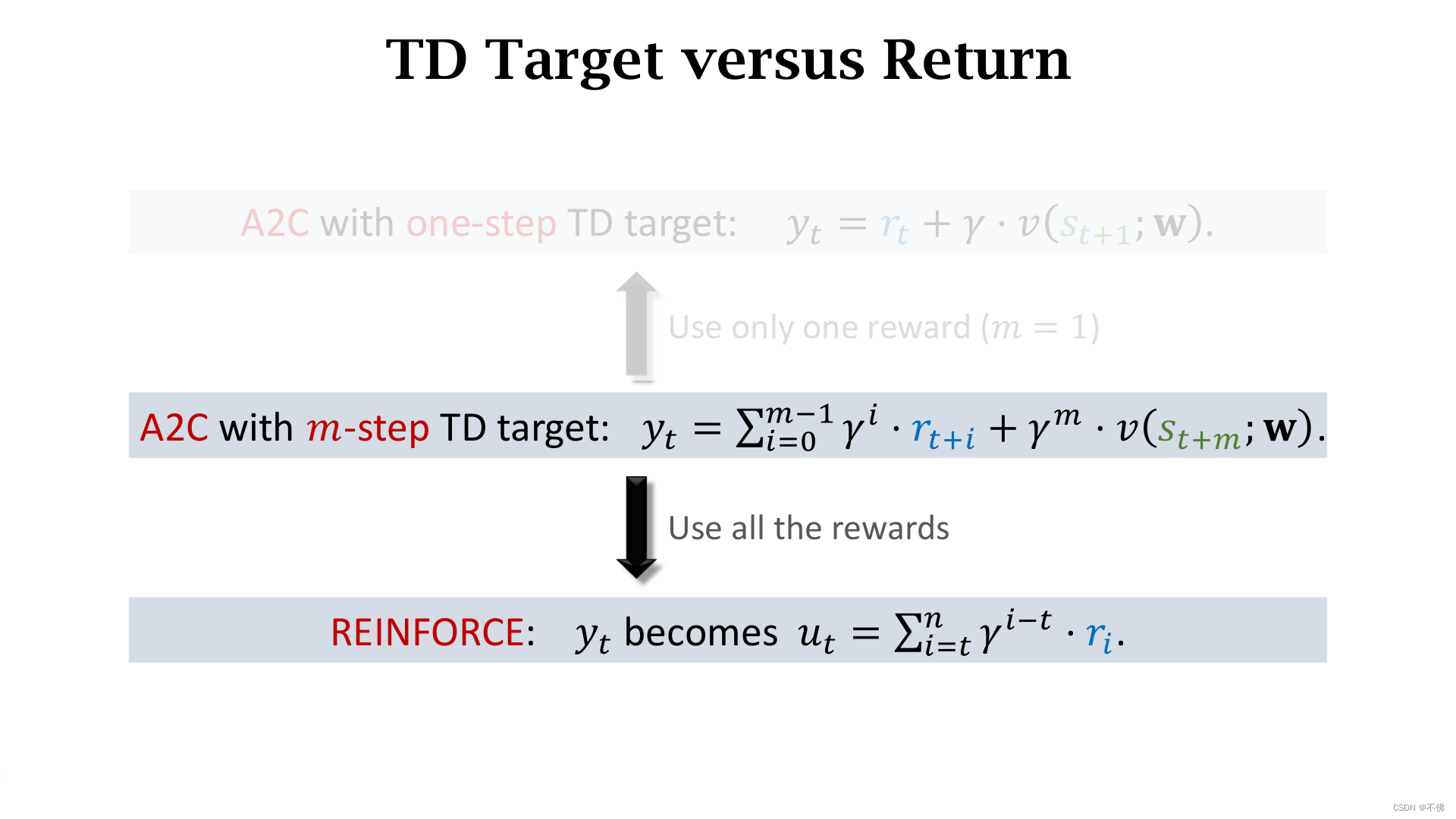
结论:使用了baseline的REINFORCE是使用了多步TD Target的A2C的一个特例。
这结论还挺神奇的,两个思路殊途同归了。如果使用了全部真实回报,就不存在自举的问题。

A2C代码
A2C的流程看着很简单,我就自己上手写了一下代码,只有真正实现过才能透彻理解,对代码没兴趣的可跳过。
直接贴:
import numpy as np
import gymnasium as gym
import torch
from torch import nn, optim
from torch.distributions.categorical import Categorical
from matplotlib import pyplot as plt
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.base = nn.Sequential(
nn.Linear(4, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU()
)
self.fc1 = nn.Linear(64, 2)
self.fc2 = nn.Linear(64, 1)
def forward(self, x):
y_base = self.base(x)
pi = nn.Softmax(dim=0)(self.fc1(y_base))
v = self.fc2(y_base)
# 分别近似 策略函数pi 状态价值函数v
return pi, v
class Game:
def __init__(self):
self.device = torch.device("cuda")
self.env = gym.make("CartPole-v1", render_mode="rgb_array")
self.net = Net().to(self.device)
self.opt = optim.Adam(self.net.parameters())
self.gamma = 0.99 # 回报折扣因子
def __call__(self):
avg_ret = 0
avg_ret_list = []
step = 0
for i in range(int(1e8)):
state, _ = self.env.reset()
x = torch.FloatTensor(state).to(self.device)
ret = 0
while True:
pi_t, v_t = self.net(x) # t时刻
dist = Categorical(pi_t) # 把概率转成分布
action = dist.sample() # 根据策略函数采样得到动作
next_state, reward, terminated, truncated, info = self.env.step(action.cpu().numpy())
state = next_state
x = torch.FloatTensor(state).to(self.device)
y_t = float(reward) + self.gamma * self.net(x)[1] * (1 - terminated) # 用下一时刻的v值算TD target
delta_t = v_t - y_t.detach() # TD error
loss_actor = dist.log_prob(action) * delta_t.detach() # 根据采样动作计算损失
loss_critic = delta_t.pow(2) / 2
loss = loss_actor + loss_critic
self.opt.zero_grad()
loss.backward()
self.opt.step()
step += 1
ret += reward
if terminated:
avg_ret = 0.9 * avg_ret + 0.1 * ret
avg_ret_list.append(avg_ret)
print(v_t.item(), step, ret, avg_ret)
break
# 每100局保存参数 保存图
if (i + 1) % 100 == 0:
torch.save(self.net, "net.pt")
plt.ylabel("avg_ret")
plt.xlabel("episode")
plt.plot(avg_ret_list, color='r')
plt.savefig('avg_ret.png')
if __name__ == '__main__':
g = Game()
g()

这应该是全网A2C最潦草的代码了吧,没有并行也没有多步TD Target,只是为了实现一下流程,结果还是踩了几个小坑…
说明:
- 我用的新版的gymnasium,和老版gym有点不太一样。游戏选的是CartPole-v1版本,不像v0版本到500分自动结束,可以一直玩。
- 一开始我reward忘记乘(1 - terminated),导致TD算法评分越来越高,直接nan爆炸了。
- 我的 π \pi π网络和 v v v网络参照课程中的结构,共用了部分参数,但我看网上的版本很少是共用参数的。
- 尽管共用了部分参数,在更新 π \pi π网络的时候,跟 v v v网络应该无关,因此 δ t \delta_t δt不应该算梯度。在更新 v v v网络的时候, y t y_t yt应该也视为一个常数目标,不应该算梯度。我看网上有的代码没有把这两项的梯度去掉,居然也能训练的出来…可能是平衡车这个游戏太简单了吧,我试了一下,不去掉梯度前期还是可以学习的,后期就崩了。
滑动平均回报的学习效果如下图,就是震荡挺大的,而且中间死了一段时间,最好又死了,但是最好的时候效果特别好,能活上万个step。每次学到一个好的效果之后,就会突然摆烂躺平。我不太确定是什么问题导致的,试着改了一下网络结构和超参,加上了多步TD Target,没有效果。

多次实验后我观察到这种崩溃都是在玩了特别长的一局之后出现的,学到后边的极端情况是连续的2局,一局得几万分,然后下一局上来就挂了,只能得几分,再下一局又能得几万分,交替出现。
我猜想可能的原因是:
特别长的一局使得网络在最近几万次更新中见到的都是杆子几乎直立的状态,它忘记了怎么应对倾斜角度较大的状态。
如果是这个原因,可以限制每局游戏的最大步长或者最大更新次数。
连续控制问题
Discrete vs Continuous Control
进入一个新话题,之前讨论的都是离散动作,不管是DQN还是策略网络,输出的都是离散值,无法直接用在连续控制上。
例如机械手臂的转动角度是个连续值,有无穷多个取值。
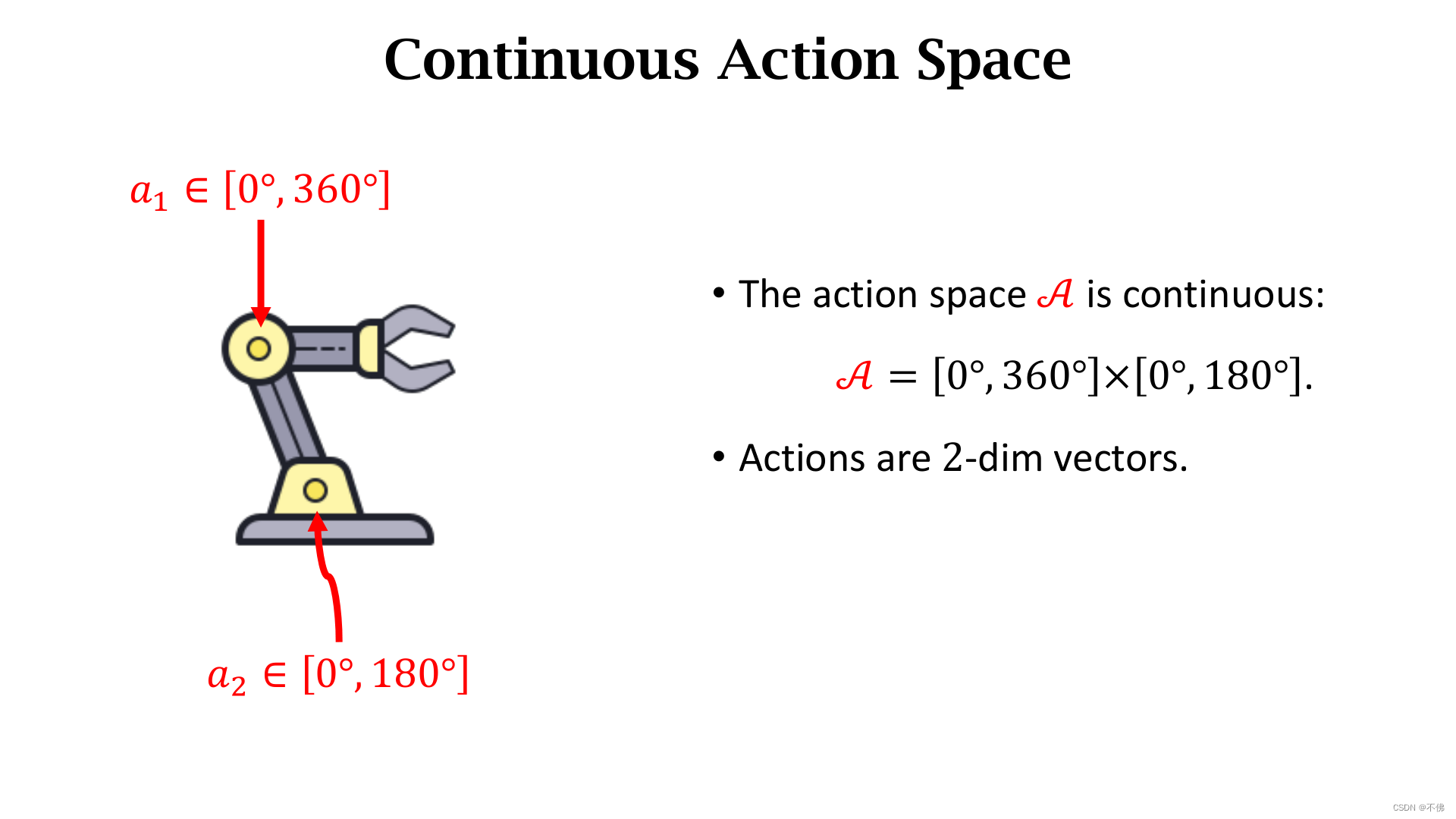
解决连续问题的一种办法是把连续动作离散化,例如把连续的角度分割成有限个取值。

离散后的动作取值显然会随着动作维度增大而指数增长,会导致维度灾难,网络难以训练,因此这种办法只适用于动作维度较低的情况。

Deterministic Policy Gradient (DPG)
确定策略梯度 (DPG)是解决连续控制问题的一种方式,它是一个Actor-Critic方法。它的网络结构和AC完全一样,唯一的区别就是策略网络的输出不是一系列动作的概率,而是一个确定(Deterministic)的动作向量,因而就可以表示一个连续动作,比如输出
(
45.2
,
90.8
)
(45.2, 90.8)
(45.2,90.8)可以代表机械手臂的2个转动角度。
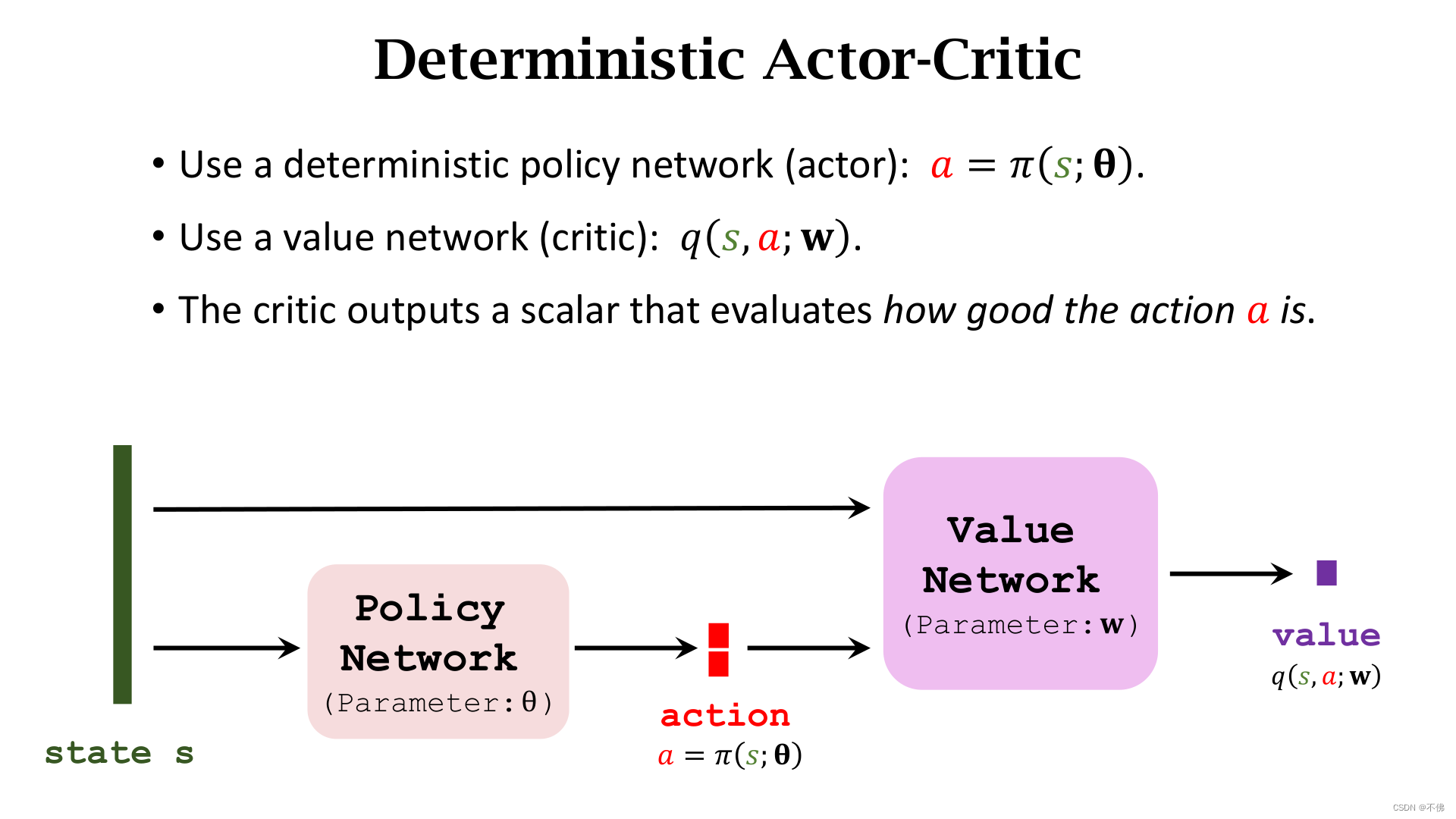
理解这个本质区别之后就很简单了,更新价值网络用的还是TD算法,没有区别。
只需注意这里下一时刻的动作也是一个确定值,并且不会真正执行,只是用来计算。

更新策略网络有所区别,不再用AC中的策略梯度,而是确定策略梯度(DPG)。我们希望策略网络输出的动作可以被价值网络打出更高的分数,更新策略网络时,价值网络是确定的,输出只和策略网络参数
θ
\theta
θ有关。因为动作是一个确定的向量,所以确定策略梯度的形式比策略梯度更简单,只需要输出价值
q
q
q对策略网络参数
θ
\theta
θ求梯度然后用梯度上升更新,用链式法则展开,就是
q
q
q先对动作
a
a
a求导,再乘上
a
a
a对
θ
\theta
θ求导。
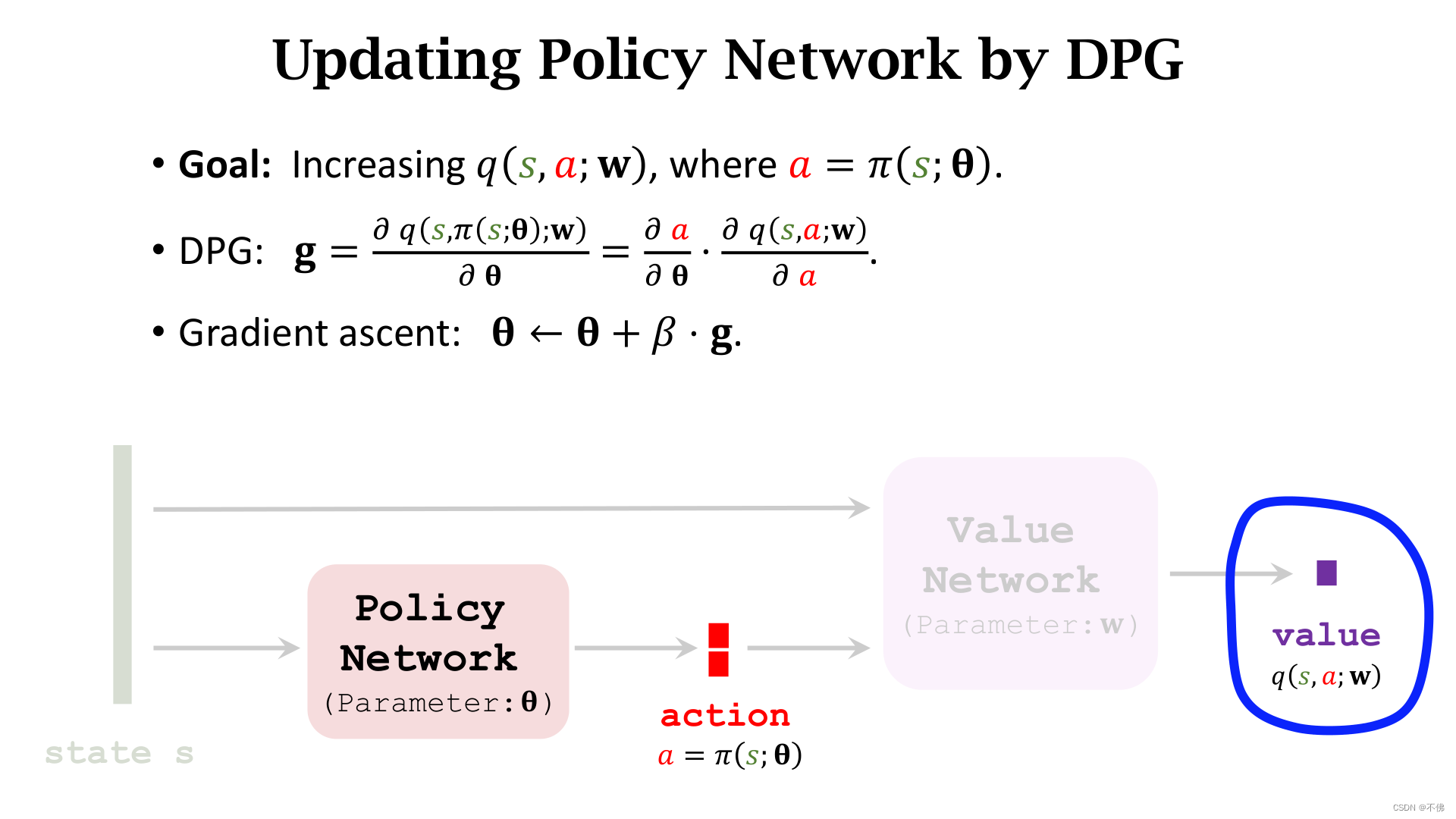
DPG就讲完了,挺简单的对吧,接下来讲一下改进。
在使用TD算法更新价值网络的时候,用
q
t
+
1
q_{t+1}
qt+1更新
q
t
q_t
qt,显然是Bootstrapping。我们可以用target network来缓解这个问题,需要准备2个结构一样的策略网络和价值网络,用它们计算
q
t
+
1
q_{t+1}
qt+1。
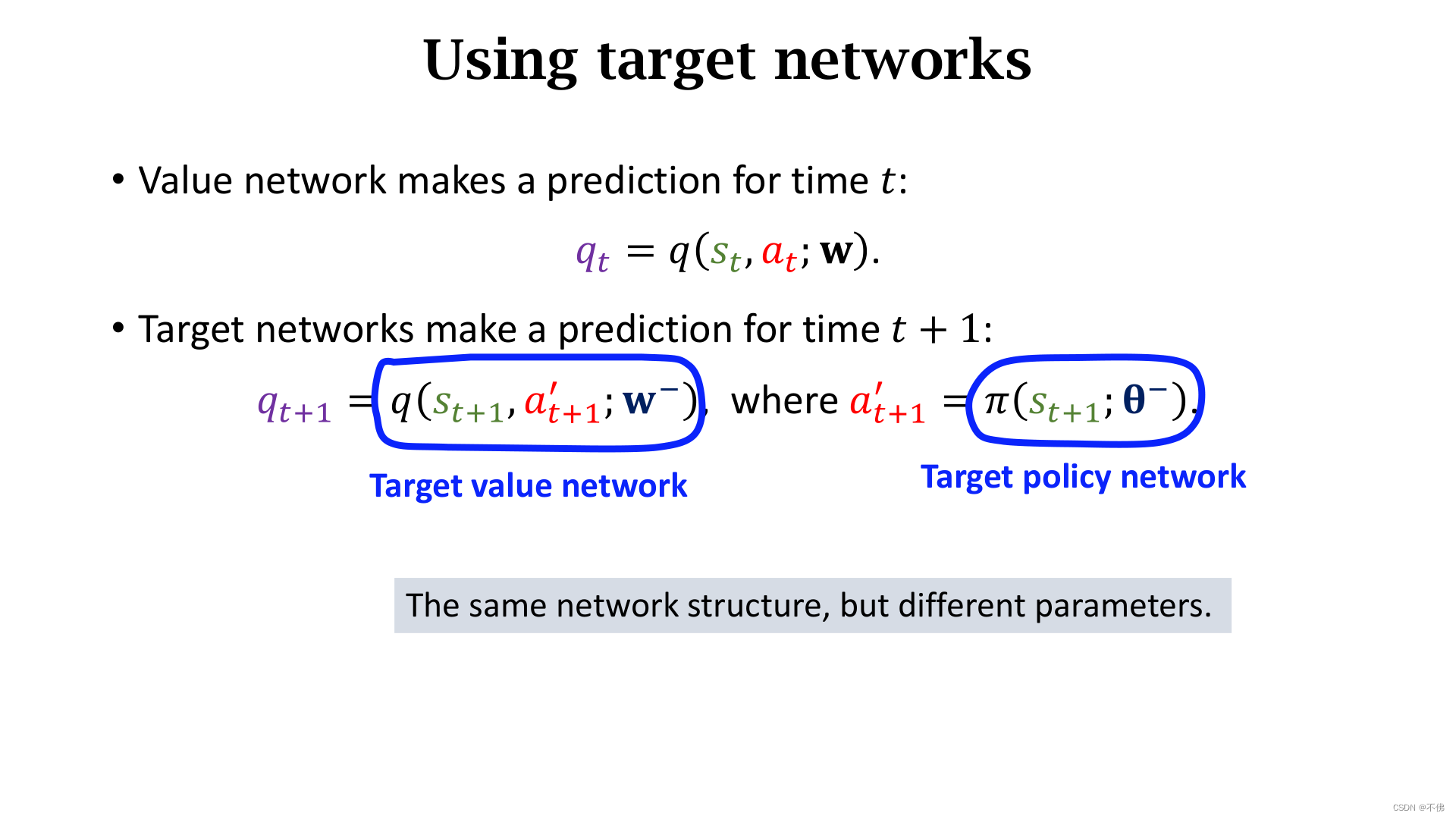

target network的参数更新我们之前讲过,可以用加权平均来更新。

除了target network,之前讲过的改进,比如经验回放和多步TD target也都可以用。
最后看一下随机策略和确定策略的对比,核心就是随机策略输出的是动作概率,通过采样得到动作,确定策略直接输出确定动作。
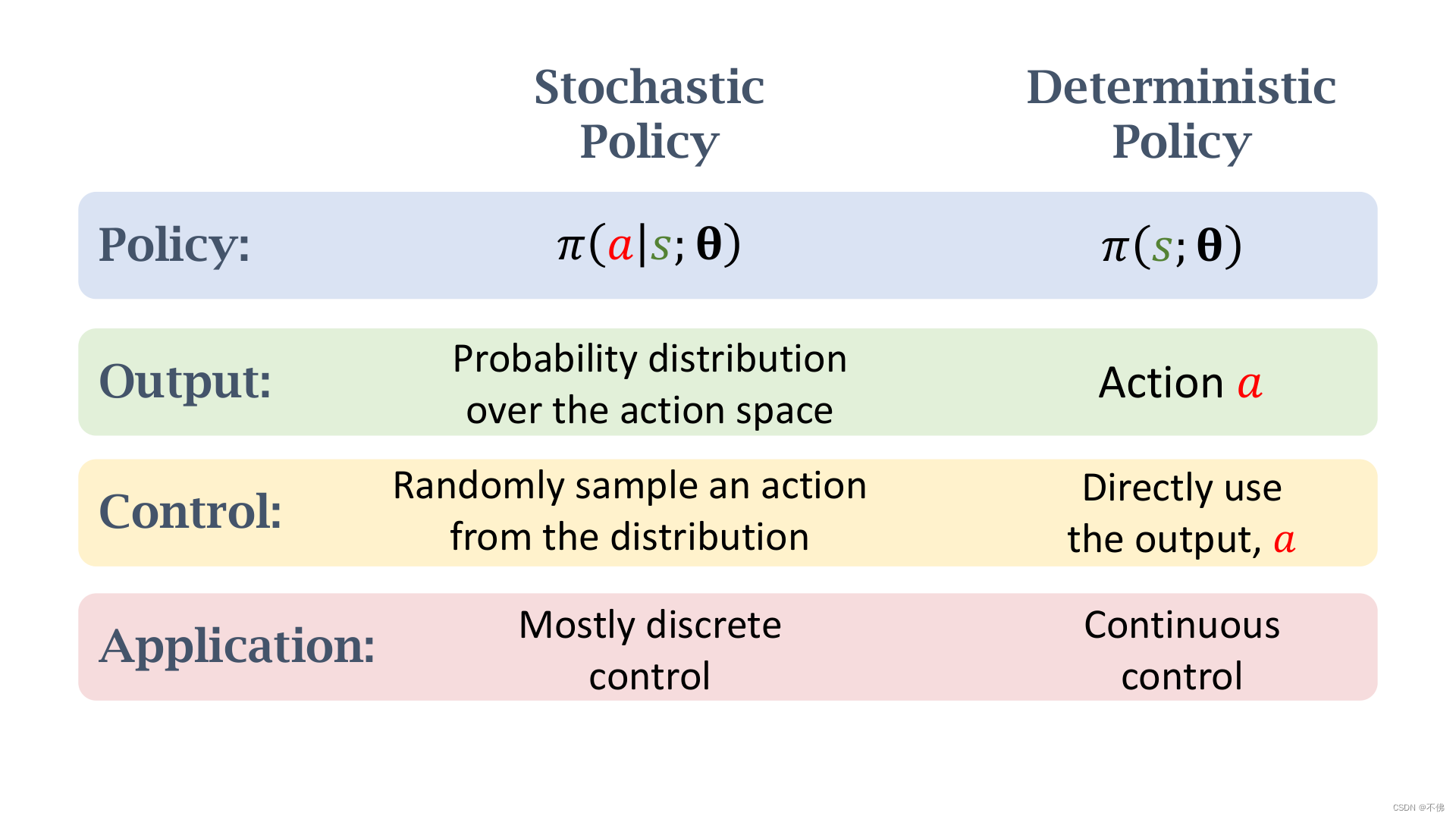
Stochastic Policy for Continuous Control
有时候我们还是希望让Agent的运动是有随机性的,除了把策略函数改成确定性的,有没有其他办法解决连续运动问题呢?
核心思路是这样的:因为运动是连续的,不能穷取,又希望保有随机性,那么这个动作可以从一个概率分布中采样得到,而描述一个概率分布的参数是有限的,只要让网络学习这个参数就可以了。
不知道用什么概率分布,正态分布自然就是首选了。这里的动作 a a a有 d d d维的自由度,也就是一个 d d d维的向量, μ \mu μ和 σ \sigma σ也一样。如果各个维度的动作相互独立,策略函数 π \pi π可以写成每一维概率密度函数连乘的形式。注意:最终使用的时候并不是用 π \pi π函数采样,每个维度的动作是分别采样的, π \pi π函数只用来推导策略梯度。
话说,这个6.28我第一眼看还有点懵,然后才想起来是2
π
\pi
π……为啥要这么写,是因为符号和
π
\pi
π函数重复啦?

只要用2个神经网络分别学习
μ
\mu
μ和
σ
\sigma
σ就好了,直接学
σ
\sigma
σ效果不太好,定义
ρ
\rho
ρ为
σ
\sigma
σ平方的对数,也就是方差的对数,让网络学习
ρ
\rho
ρ。

网络结构没什么好说的,就是共享卷积层。
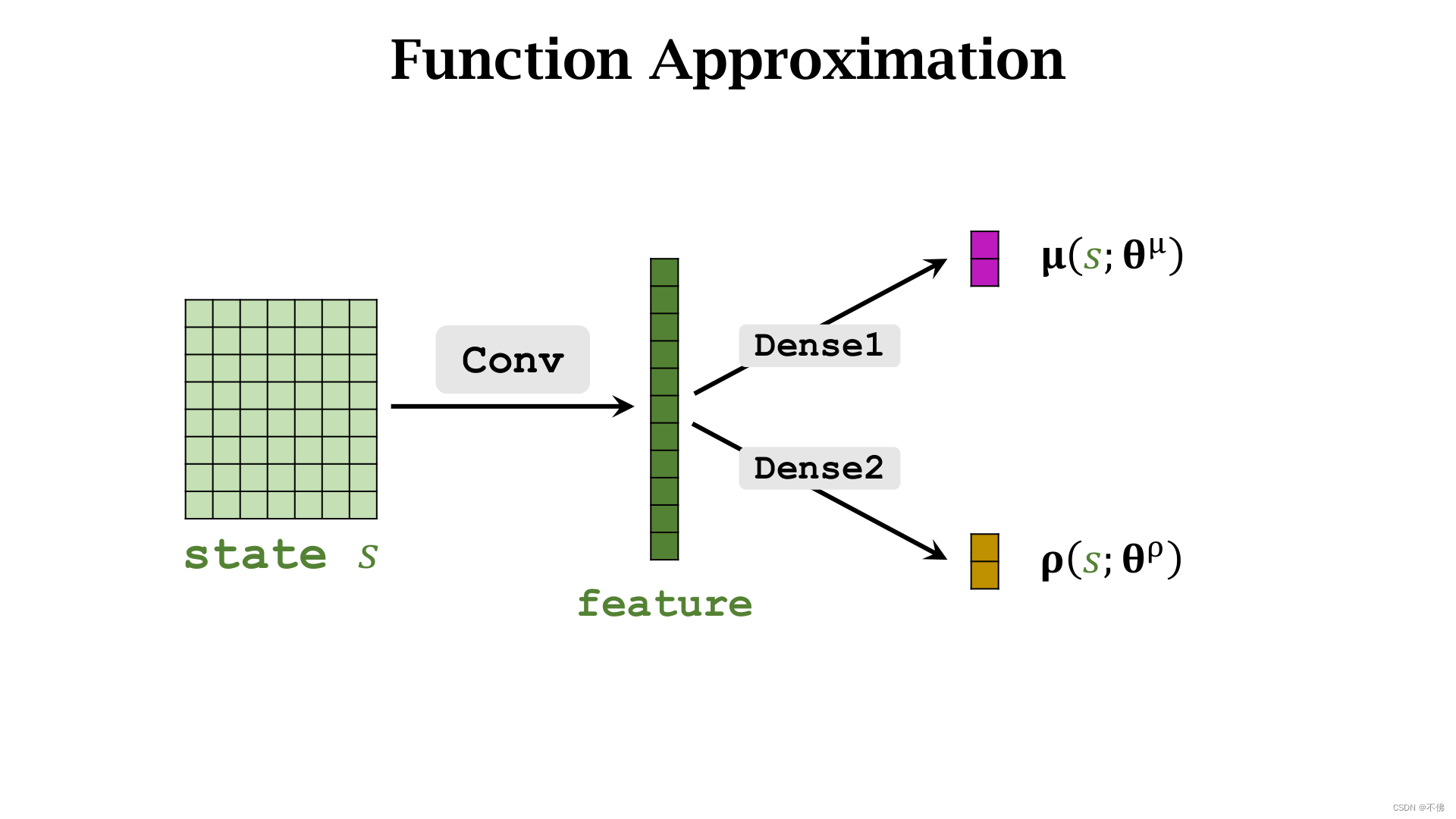
第
i
i
i个维度的动作
a
i
a_i
ai,就可以从确定的正态分布中采样得到。

接下来的重点就是怎么计算策略梯度。
回忆一下策略梯度的式子,里面用到了
ln
π
\ln{\pi}
lnπ对参数的导数,根据
π
\pi
π函数的定义,
ln
π
\ln{\pi}
lnπ可以写成下图中蓝色项加上一个常数项的形式。

接下来要求
ln
π
\ln{\pi}
lnπ对参数的导数,常数项和求导无关,不用管,这里把
θ
μ
\theta^\mu
θμ和
θ
ρ
\theta^\rho
θρ统称为
θ
\theta
θ,为了方便求这个导数,我们把这个蓝色项记作一个辅助函数
f
f
f,用网络的输出和采样得到的动作
a
a
a计算
f
f
f,这样做的好处是,只要计算得到
f
f
f,就可以用深度学习框架(如Pytorch)自动算出
f
f
f对所有网络参数
θ
\theta
θ的导数。
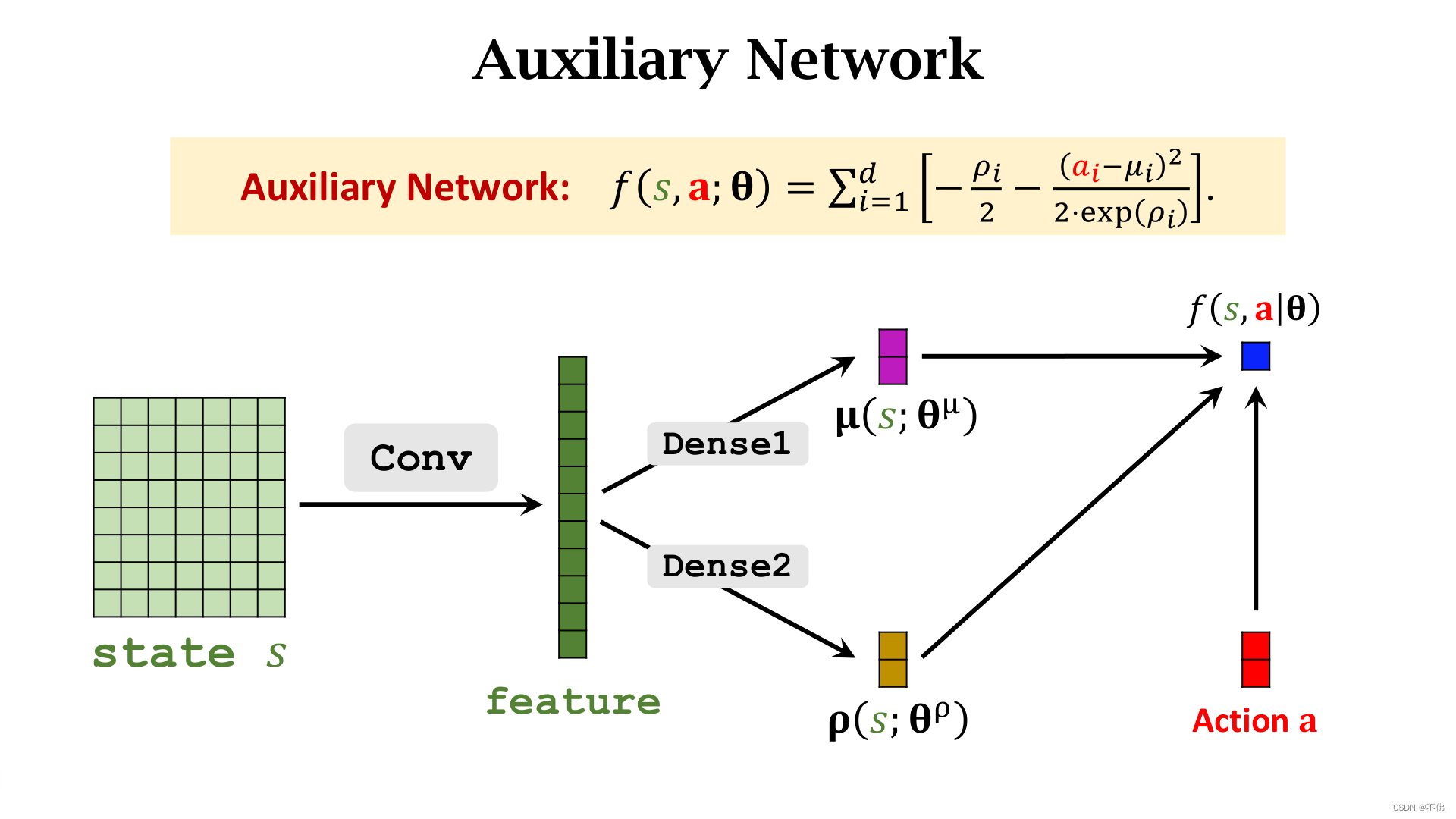
求导根据链式法则进行,不用我们操心。
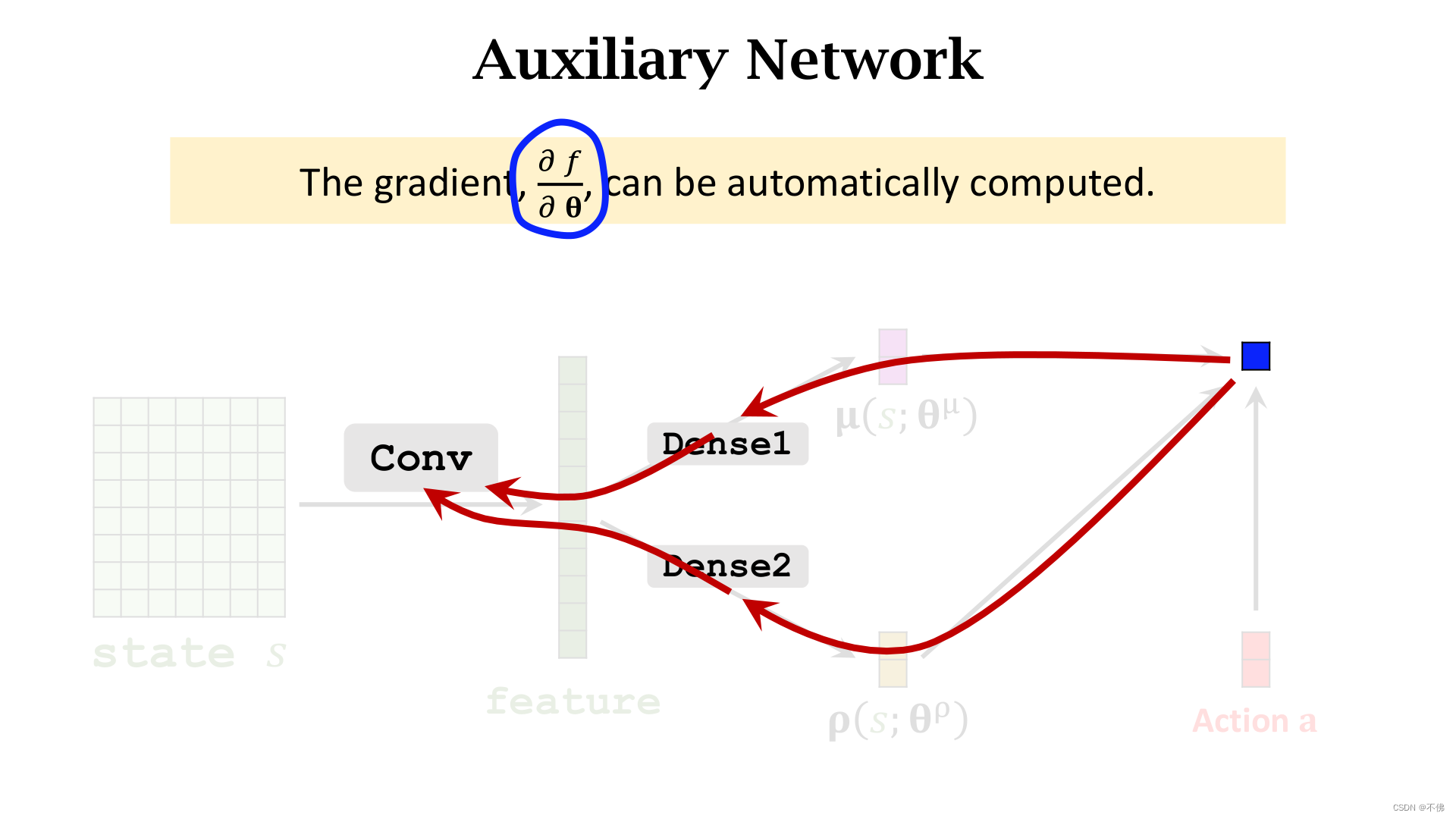
求得这个导数,就可以代回策略梯度的式子了。

之后就和一般的策略学习完全一样了,用蒙特卡洛近似得到随机策略梯度
g
g
g,进行梯度上升,但动作价值函数
Q
π
Q_\pi
Qπ还不知道怎么算,可以用另一个网络近似(Actor-Critic方法),或者用真实回报
u
t
u_t
ut近似(REINFORCE方法),不再赘述。

视频课程里还有2节介绍Multi-Agent Reinforcement Learning(MARL),主要是介绍基本概念和3种框架。我觉得MARL是个天坑,给这2节课做笔记意义不大,之后有机会再做梳理吧。














 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









