






一.强化学习专业术语
1.
- state:状态 s
- action:动作 a
- agent:动作的发出者
- policy:策略 π
根据观测到的状态做出决策来控制agent运动,强化学习学的就是policy函数。agent动作随机,根据policy来做动作。
- reward:奖励R RR
agent做出一个动作后会得到一个奖励,通常需要自己定义
奖励定义的好坏十分影响强化学习的结果
强化学习的目标:获得的奖励总和尽量高 - state transition:状态转移
当前状态下做出一个动作后转移到新的状态
状态转移可以是确定的也可以是随机的,通常是随机的(随机性来源于环境)
状态转移函数: p(s'|s,a)=P(S'=s'|S=s,A=a) -
agent与environment交互
1.环境给出当前state
2.agent根据,做出动作
3.环境更新状态state为,并给agent奖励
-
trajectory:轨迹 (state, action, reward)
2.强化学习的随机性来源
1. action
action是由policy函数随机抽样得到的
P[A=a∣S=s]=π(a∣s)
2. state transition
环境用状态转移函数p(⋅∣s,a)算出概率,用概率随机抽样得到下一个状态S '
P[S'=s'|S=s,A=a]=p(s'|s,a)
3.Rewards, Returns & Value Fuctions
1. Return
Return:回报(aka cumulative future reward,即未来累计奖励)
- t时刻的回报 :
从 t 时刻的奖励开始一直加到结束
- 未来的奖励
没有现在的奖励
值钱 →
Discounted return:折扣回报(aka cumulative discounted future reward)
- γ \gammaγ:折扣率,γ∈[0,1],超参数,需要自己调
未来的权重和现在一样:γ = 1
未来奖励越不重要,γ 越小
- t时刻的折扣回报:
2. Value Function
Value Function:价值函数
是随机变量,依赖于未来的所有动作
,以及未来的所有状
,
Action-value Function:动作价值函数
与当前的状态 和动作
以及policy函数π有关
直观意义:已知policy函数π,给当前状态下所有的动作a打分,从而得知动作的好坏
Optimal action-value function:最优动作价值函数
对关于π 求最大值,即选择使用让
值最大的π
直观意义:观测到状态 后对动作a 做评价,agent可以根据此对动作做出决策
State-value function:状态价值函数
from numpy.random import choice
# 随机抽样
samples = choice(['R', 'G', 'B'], size=100, p=[0.2, 0.5, 0.3])
print(samples)
import gym
env = gym.make('CartPole-v0', render_mode="human") # 环境
state = env.reset() # 重置环境
for t in range(100):
env.render() # 渲染,把游戏显示给人看
print(state)
action = env.action_space.sample() # 随机均匀抽样动作(不应该随机)
state, reward, done, info, _ = env.step(action) # 真的做动作,然后更新状态,如果游戏结束done=1
if done:
print('Finished')
break二、 Value-based Reinforcement learning
Deep Q-Network (DQN)
七.Random Permutation(随机排列)
1.uniform random permutation
The permutation of {A, B, C}:
If a set contains n items, then there are n! permutation.
- Uniformly selecting one out of the n! possible sequences.
- An element appears in any of the n the positions with probability
.
- A position is filled with any of the n items with probility
2.Fisher-Yates Shuffle: Original Version
抽取一个元素放进序列中之后,将后面的元素平移填补空位。
时间复杂度:O()
3.Fisher-Yates Shuffle: Modern Version
第一轮循环中,随机抽取一个元素,与第一个元素交换位置,并且固定第一个位置。接下来的序列以此类推。最后一个位置,剩下的一个元素就就留在这个位置,不用管了。
时间复杂度:O(n)
这个改进版本时间复杂度降低,且不需要额外内存。
void permute(int arr[], int n){
int i;
for (i=0; i<=n-2; i++){
// k is sampled from {0,1,..., n-i-1}
int k = uniform(n-i);
// j is in {i, i+1, ..., n-1}
int j = i + k;
// put arr[j] at the i-th position
swap(arr, i, j);
}
}八.Sarsa(TD Learning)
1.Sarsa: Tabular Version

- 每次观测到一个四元组transition(
)
- 用策略函数
计算下个一个动作
~
- 计算TD target:
,根据table查出
- 求出TD error:
- Update:
Sarsa name: State-Action-Reward-State-Action
- Use (
) for update
.
2.Sarsa: Neural Network Version


九.Q-Learning(TD Learning)


Derive TD Target:
- 已经证明价值函数
.
- 最优策略
,则
.
- 最优动作价值函数
通常记作
identity:
- 选出动作
- 因此,
identity:
TD Target

表格使用条件:状态和动作都有限。

区别: Q-Learning学习,Sarsa学习
.
十.Multi-Step TD Target
Identity:
Identity:
也可以包含三个奖励,或者更多个。
- m-step TD target for Sarsa:
- m-step TD target for Q-Learning:
十一.Experience Replay
Temporal Difference(TD) leraing:
- Shortcoming1: Waste of Experience
A transition: ().
Experience: all the transition, for t=1,2,...
- Shortcoming2: Correlated Updates
按照顺序使用每一条transition()更新w,前后transition有很强的关联,实验证明这样的相关性是有害的,如果把序列打散,消除相关性,则有利于把DQN训练的更好。
Experience Replay:
A transition: ().
把transition存到一个队列replay buffer里,容量为n,最多存n个transition,如果存满了,再存入新的就把最老的那个删了。
n是一个超参数: n is typically large, e.g.,~
.
TD with Experience Replay:

这里只用了一个transition更新w,实践中通常使用minbatch SGD,每次随机抽取多个transition,算多个梯度,用梯度的平均更新w。
Benefits of Experience Replay:
1.打破序列的相关性
2.重复利用过去的经验
Prioritized Experience Replay:
区别:用非均匀抽样代替均匀抽样

Scaling Learning Rate:
如果做均匀抽样,所有的transition都用相同的学习率;
如果做非均匀抽样,根据抽样概率调整学习率, 如果一条transition有较大的抽样概率,应该把它的学习率设置的比较小。

Update TD Error:
- 每一条transition都标上TD Error,
.
- 如果一条transition刚刚被收集到,还没被用来训练DQN,不知道它的
直接将设置为最大值,给他最高的权重
- 在训练DQN时,对
越大 ——> 抽样概率越大——>学习率小,抵消大抽样概率造成的偏差
十二.高估问题、Target Network、Double DQN
bootstrapping
用一个估算去更新同类的估算

::
一部分是 t+1时刻的估计,我们用到了DQN在 t+1时刻的估计,这就是用一个估计值去更新它本身。
Problem of Overestimation

Reason 1:Maximization



Reason 2:Bootstrapping

不过,均匀高估不是问题。麻烦的是非均匀高估,实际上,DQN是非均匀的。
(s, a)在replay buffer中越频繁出现,就会导致DQN对(s,a)的高估越严重,结论就是DQN对价值的高估是非均匀的,非均匀高估非常有害。
Solutions
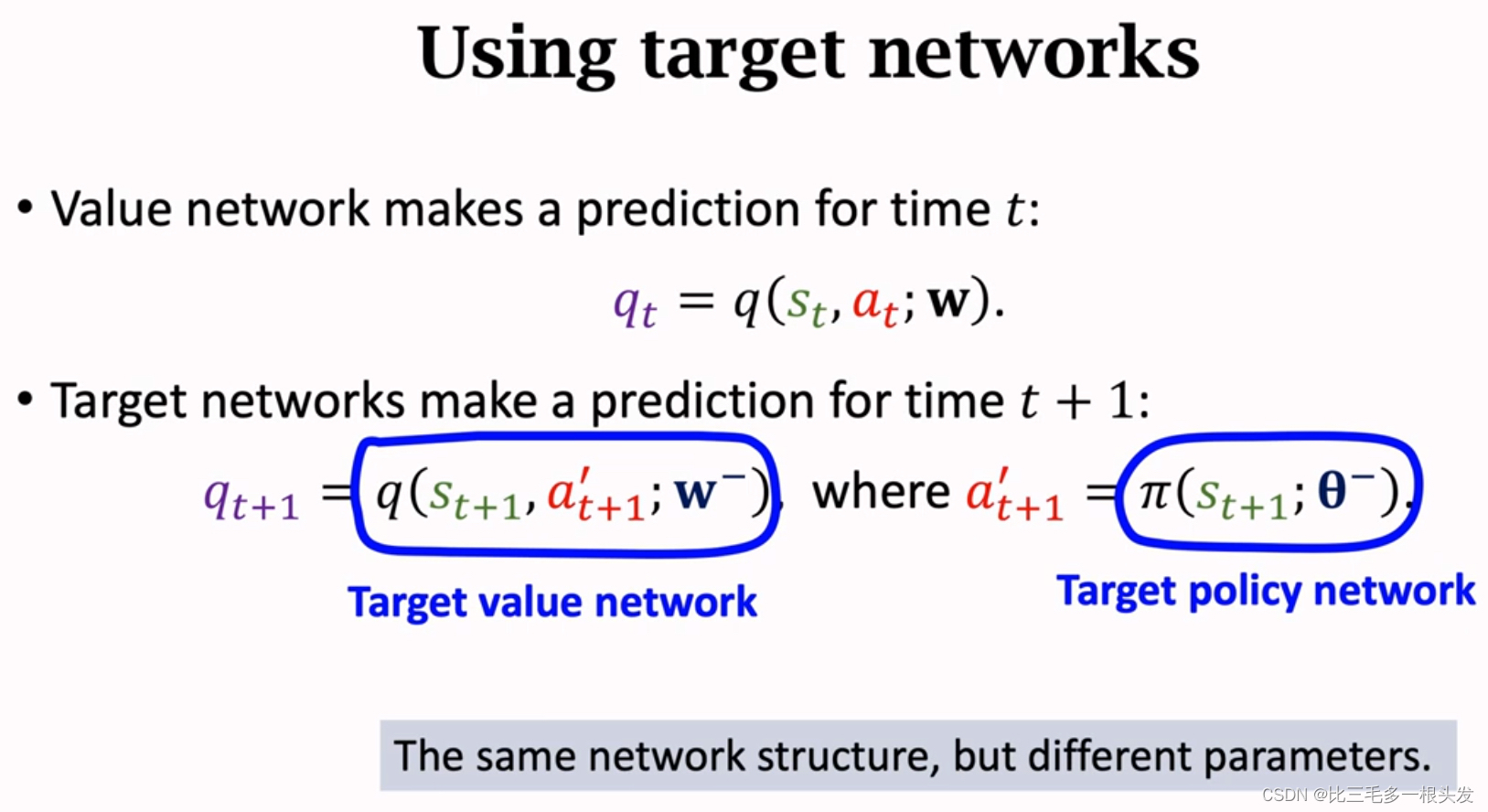
1.避免Boostrapping:不要用DQN自己算出来的TD target来更新DQN。而是用另一个神经网络来计算TD target。另一个神经网络被称为target network.
2.缓解maximization造成的高估:double DQN,也用target network
Target Network
与DQN,结构一样,但参数不一样。
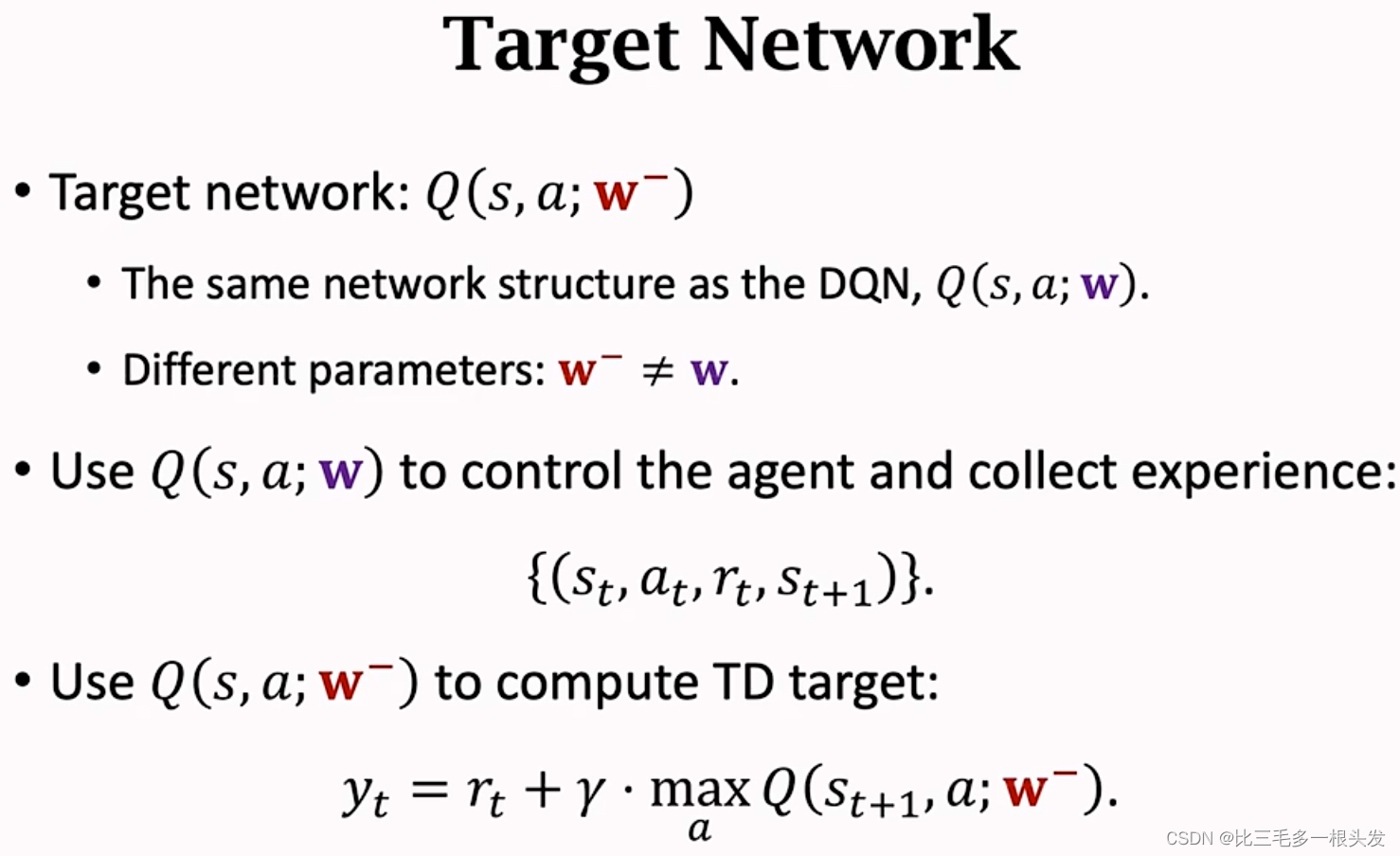

target network 隔一段时间更新一次.

target network 会用到DQN的参数,无法独立于DQN,所以无法完全避免bootstrapping.
Double DQN
可以更好缓解高估问题。




十三.Dueling Network
advantage function(优势函数)


回顾 DQN:
是神经网络对最优动作价值函数
的近似。
优势函数Advantage Function的近似:
Approximate by a neural network,
,输出向量。
Approximate State-Value Function:
Approximate by a neural network,
,输出一个实数。
Thus, approximate by the dueling network:
是最优动作价值函数的近似,与DQN有完全相同的作用。不要单独训练V和A。

Overcome Non-identifiability不唯一性:

等式1有个缺点,无法通过唯一确定
和
。在训练过程中,如果神经网络V和A上下波动,幅度相同但方向相反,那么Dueling Network输出毫无差别,两个神经网络都不稳定,都训练不好。

用平均值效果更好。
十四.Policy Gradient with Baseline
在策略梯度中加入baseline,这样可以降低方差,让收敛更快。

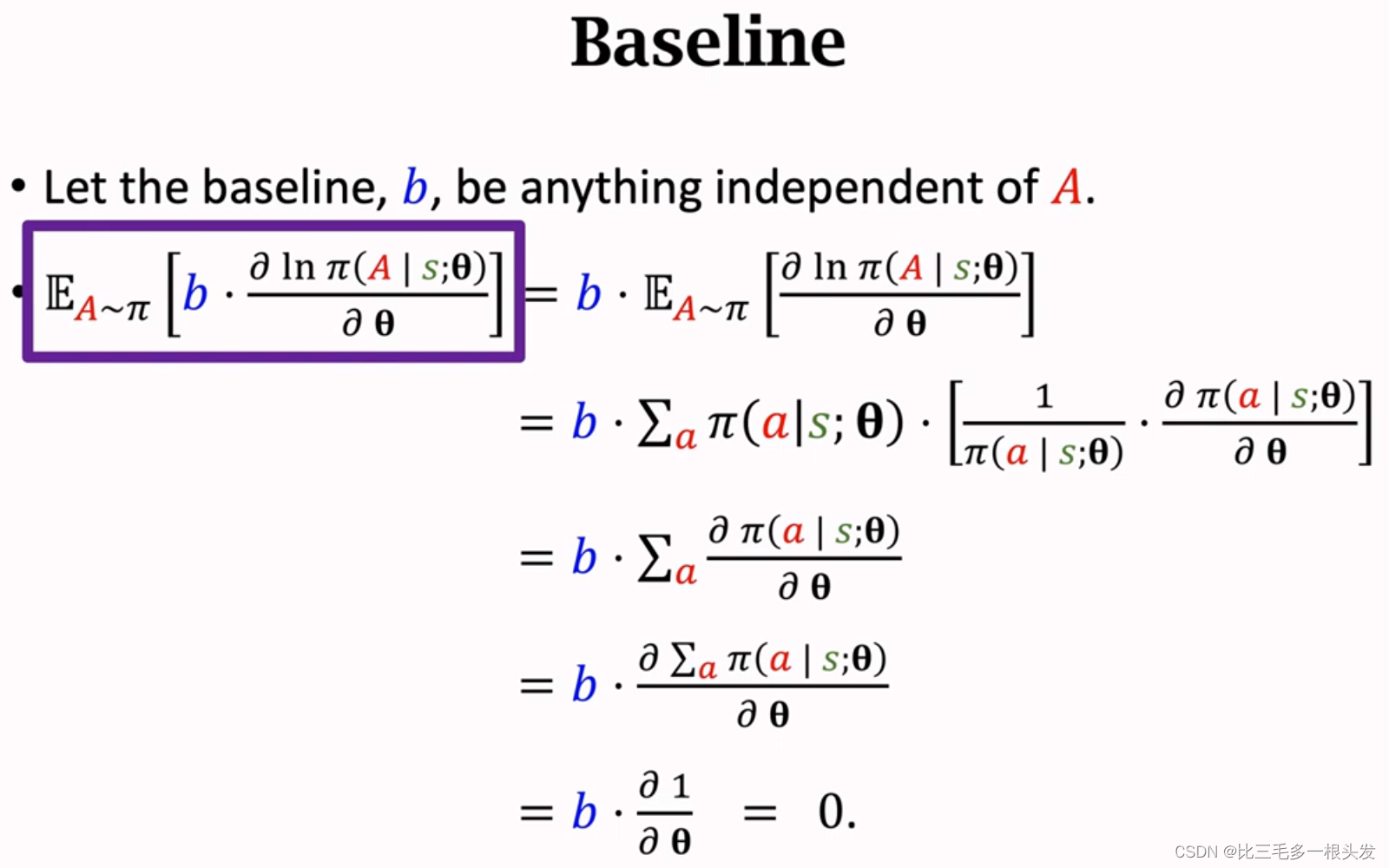
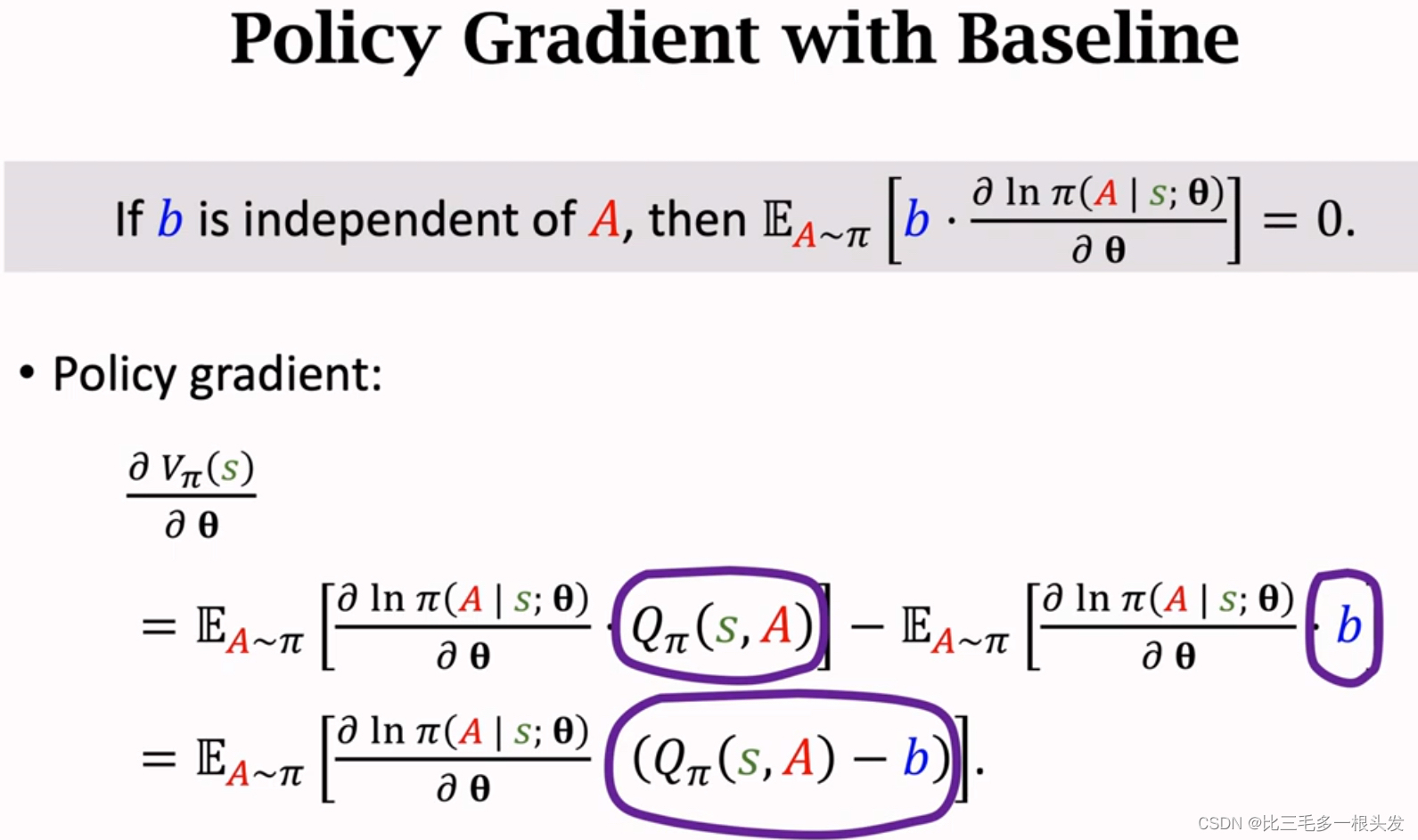
算法里真正用的策略梯度不是这个公式,而是对它的蒙特卡洛近似,b不会影响期望,但是会影响蒙特卡洛近似,如果选的b比较好,比较接近,那么b会让蒙特卡洛近似的方差降低,算法会收敛更快。


- 只要b和动作
无关,b就不会影响策略梯度的正确性,即不会影响
.
- 但b会影响
.
- 如果选的b比较好,比较接近
Choice of Baselines


十五.REINFORCE with Baseline

- Approximate
by the value network,
.

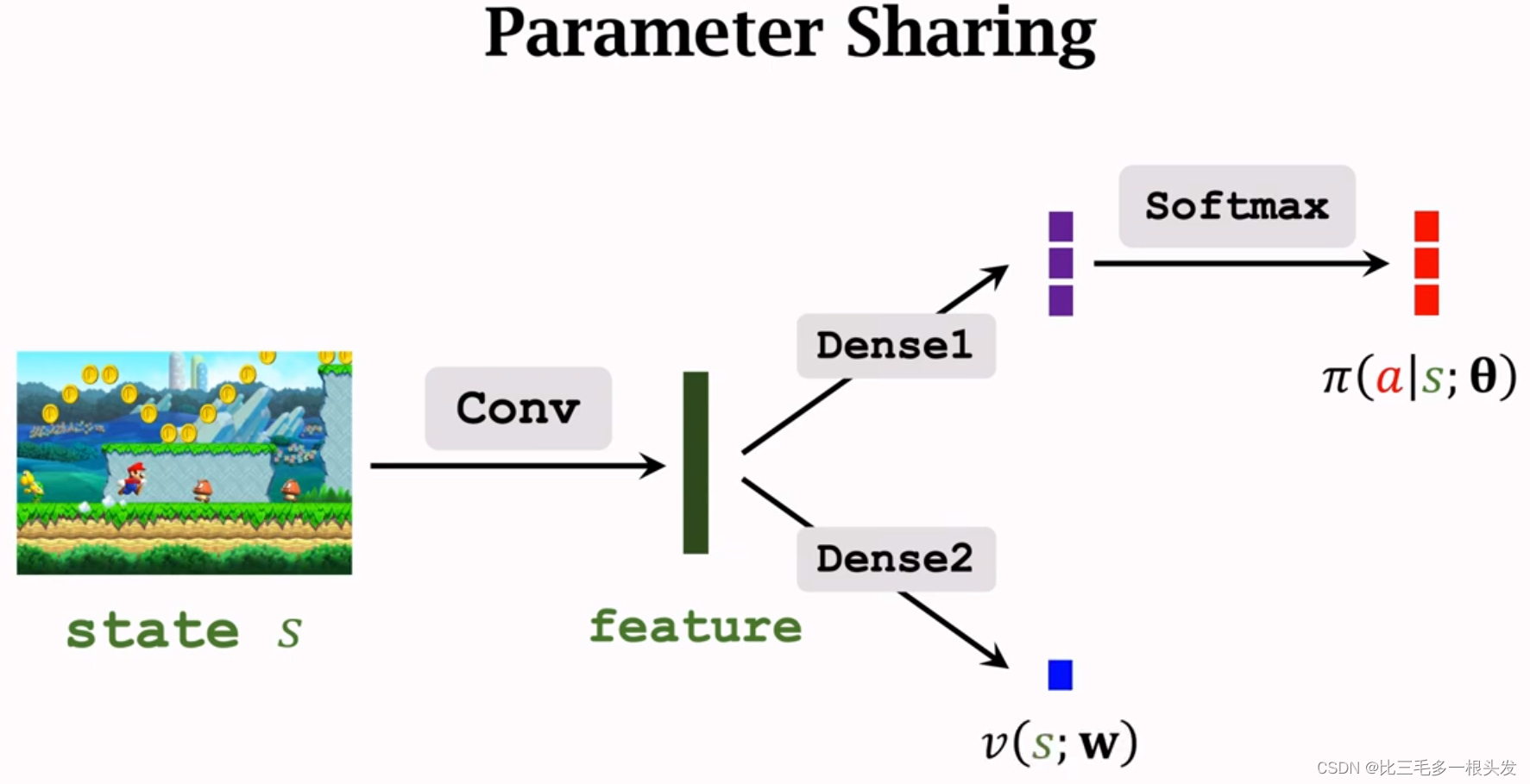
Policy and Value Network
Policy Network
Approximate policy function, , by policy network,
.
输出动作概率向量。
Value Network
Approximate state-value, , by value network,
.
两个网络共享卷积层。
Reinforce with Baseline
用reinforce算法训练策略网络,用回归方法训练价值网络。

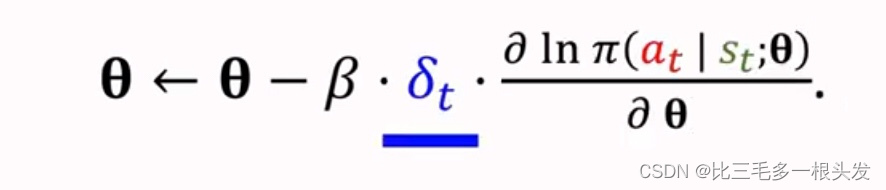


十六.Advantage Actor-Critic(A2C)

之前的Actor-Critic用的是动作价值,这是状态价值,它只依赖于状态,所以V比Q更好训练。

十七.REINFORCE versus A2C
两者用的神经网络完全一样,但是价值网络的功能有区别。
A2C的价值网络叫Critic, 用来评价actor 的表现,而REINFORCE的价值网络仅仅是个baseline,不会评价动作的好坏,baseline唯一用途就是降低随机梯度造成的方差。
A2C with Multi-Step TD Target

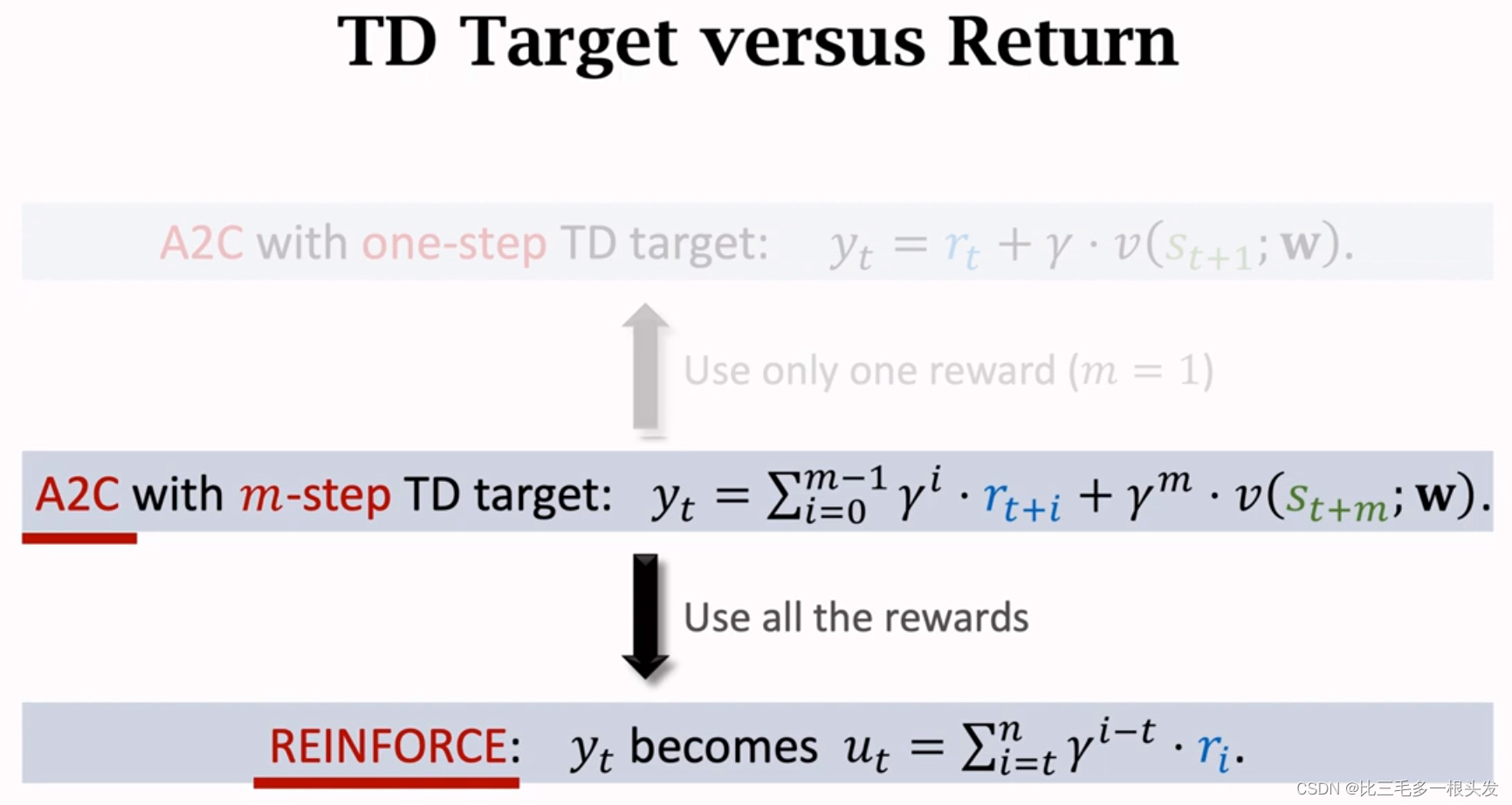
由此可见,REINFORCE 是A2C的一种特例。唯一区别是回报。
十八.Discrete VS Continuous Control
Discrete Action Space
动作空间有限

Continuous Action Space
动作空间无限

连续空间离散化
- 画一个网格,只考虑网格上的点,忽略其他所有点
- 这样,动作的数量是有限的,网格上有多少点,离散动作空间就有多少种动作
- 这样离散化的缺点:
把控制问题的自由度记为d,在机械手臂的例子中,有两个关节可以转动,所以自由度d=2,那么动作空间就是二维空间的一个子集,做离散化时,空间的纬度越高,网格上的点越多,网格点的数量随d指数增长,这会造成维度灾难。如果d=10或20,那网格上的点多的可怕,会导致训练困难,学不好DQN或者策略网络。
离散化只适合自由度小的问题,如果d比较大,应该使用其他方法。
十九.Deterministic Policy Gradient(DPG)确定策略梯度
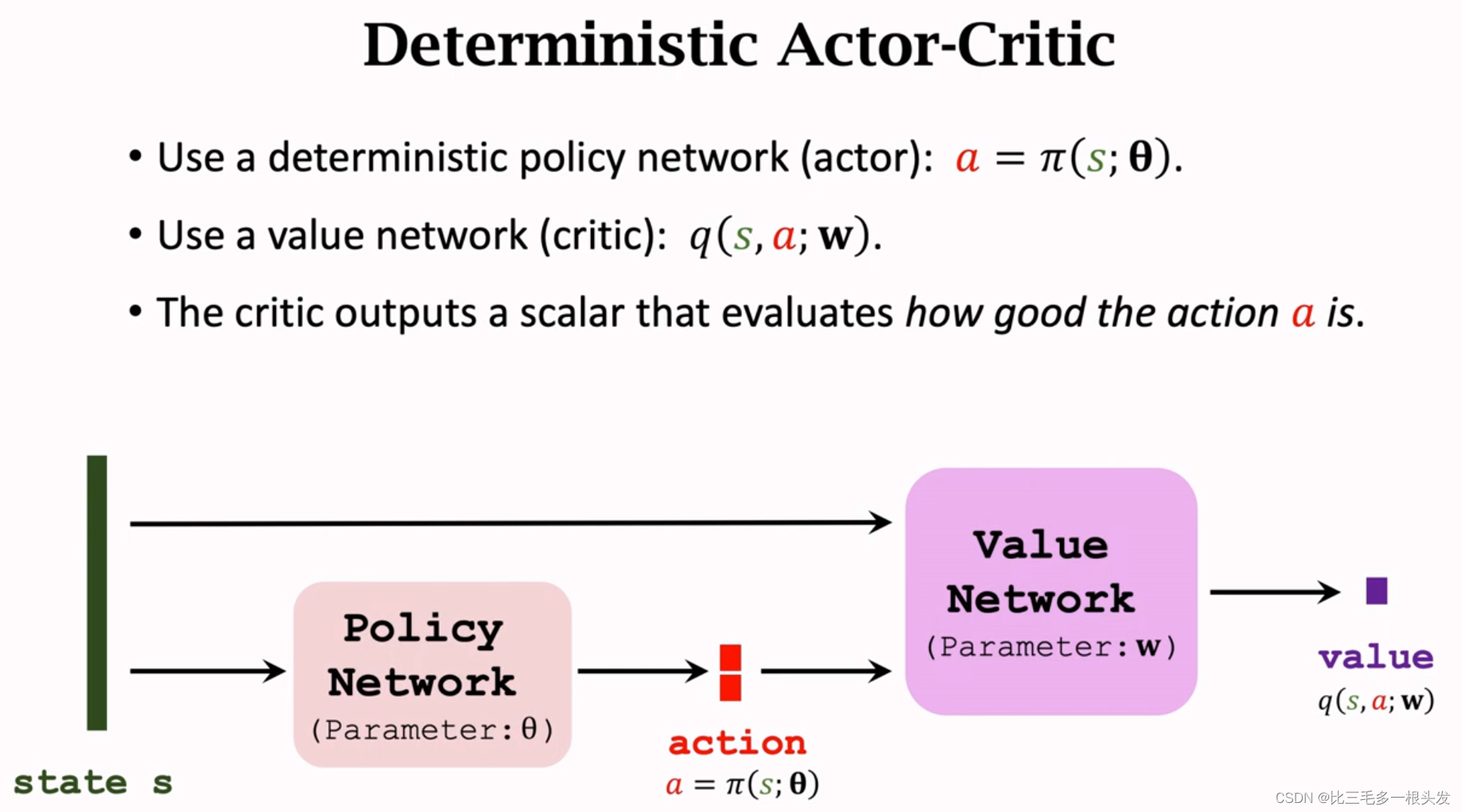
Deterministic Actor-Critic
输出的a是确定的,没有随机性,a可以是实数,也可以是向量。a的维数就是动作空间的维度。
两个神经网络的训练:
- 使用TD算法更新价值网络:
transition:
让价值网络预测t时刻的价值,
再让价值网络预测t+1时刻的价值,。我们知道t+1时刻的状态
,
把输入策略网络
,算出下一个动作
,这个动作并不是agent真正执行的动作,只是用来更新价值网络而已。
TD error:
Update:
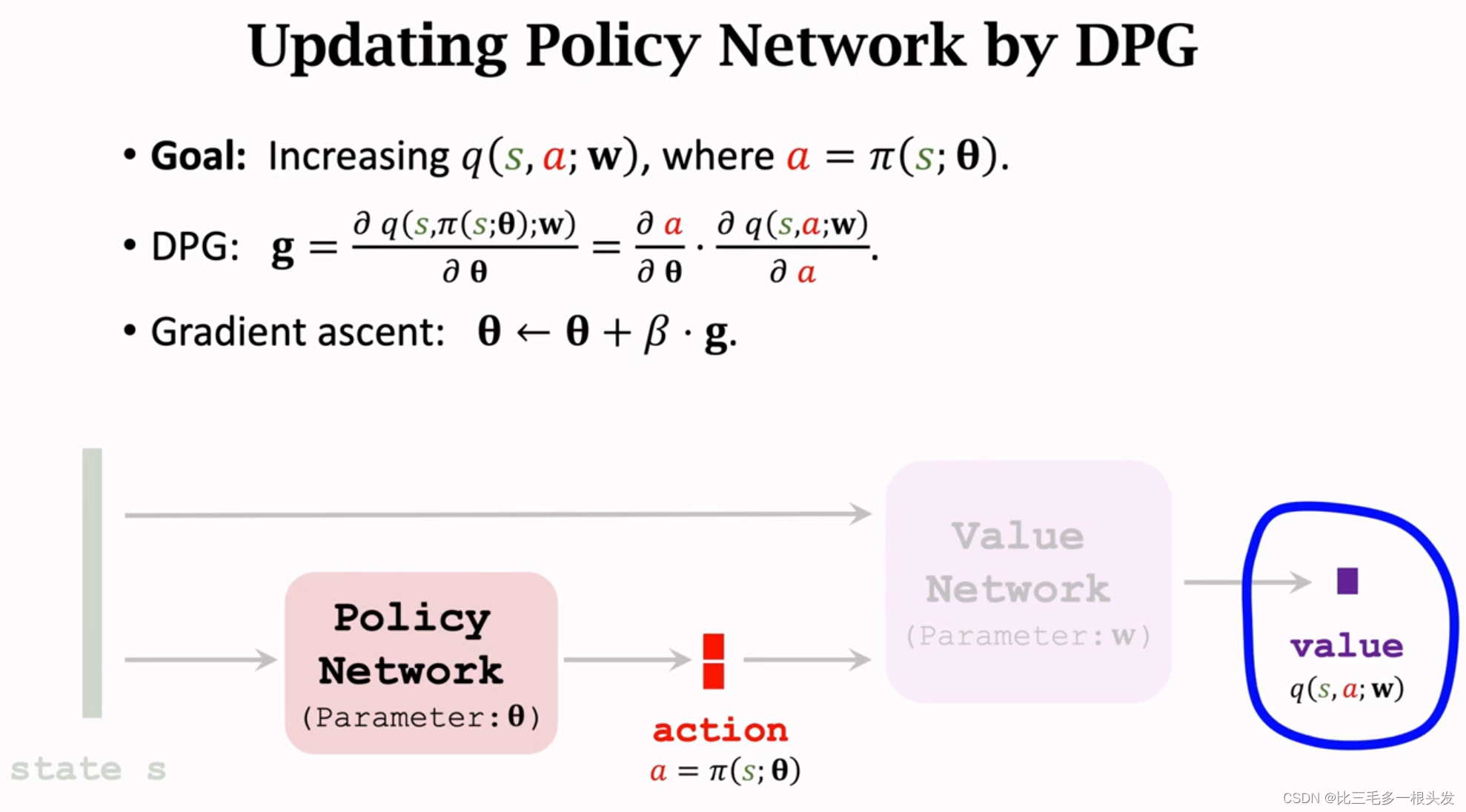
- Updating Policy Network by DPG
价值网络评价动作a的好坏,从而做出改进。改进策略网络的参数,让价值网络的输出越大越好。
对于确定的状态s,策略网络会输出确定的动作a,如果输入的状态是固定的,而且价值网络也是固定的,那么唯一会影响价值网络的因素就是参数。所以做梯度上升更新
,让价值q变大。这个梯度就叫确定策略梯度DPG。
Improvement: Using Target Network

解决方案:用不同的神经网络计算TD Target,尽量避免Bootstrapping。




二十.Stochastic Policy for Continuous Control随即策略做连续控制
Policy Network
- 假定自由度为一
(mean)和
(std)都是状态s的函数
- 用正态分布的函数作为策略密度的函数
- 把自由度记为d,a就是d维向量
都是d维向量,是状态s的函数
都是它们各自向量的第i个元素
- 则策略密度函数
但向量未知,解决方法:用神经网络做近似。

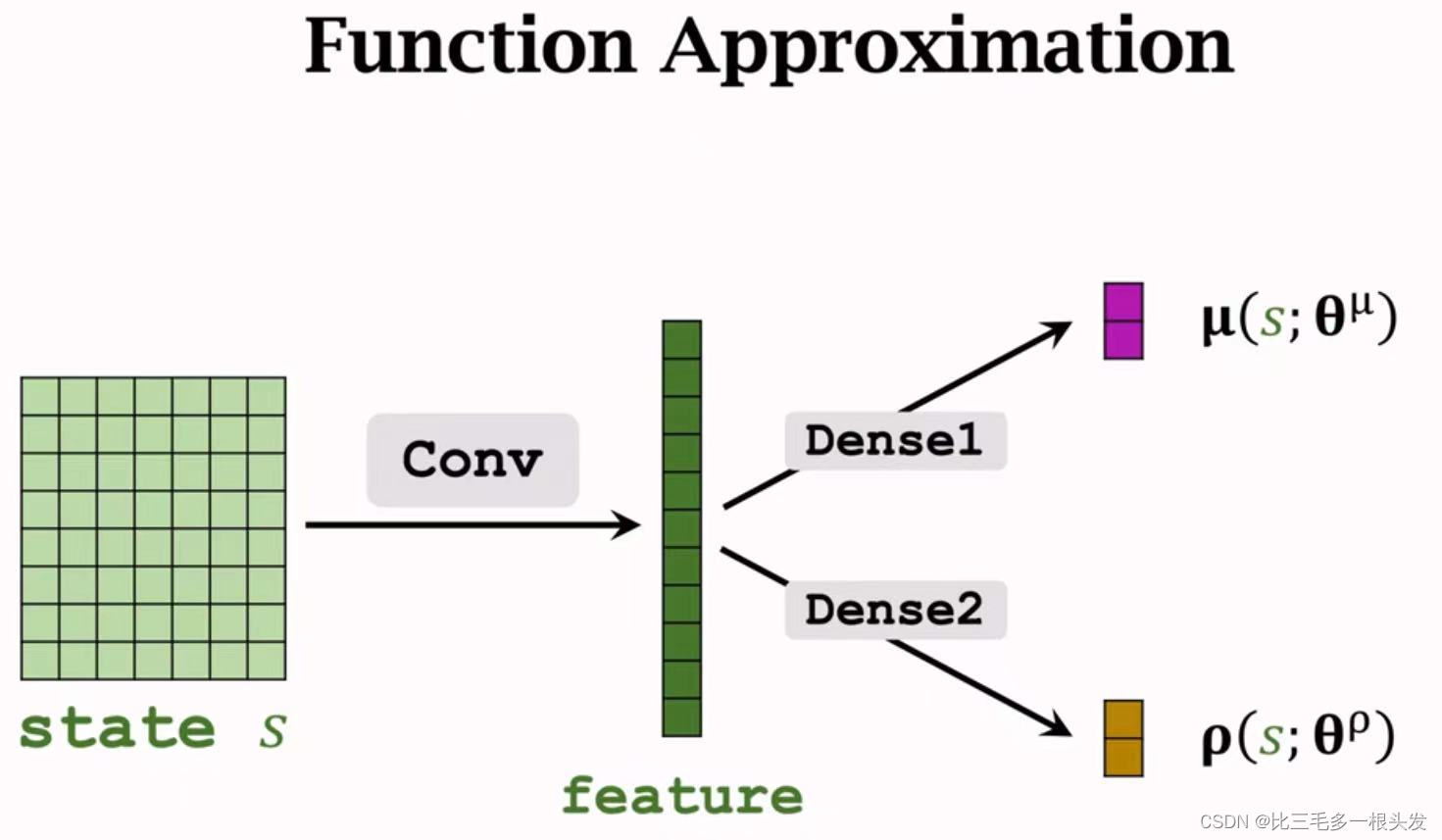
连续控制
- 每次观测但一个状态s
- 把s输入神经网络,神经网络两个头分别输出均值
和方差对数
,都是d维向量
- 用
计算方差
,i=1,...,d
- 随机抽样动作a,















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









