







许多现有的DL框架需要一个分离的集群进行深度学习,而一个典型的机器学习管道需要创建一个复杂的程序(如图1)。分离的集群需要大型的数据集在它们之间进行传输,从而系统的复杂性和端到端学习的延迟不请自来。
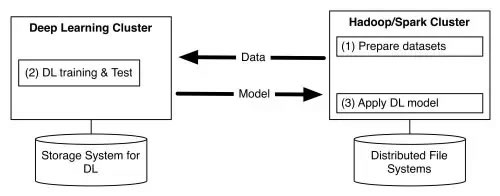
雅虎认为,深度学习应该与现有的支持特征工程和传统(非深度)机器学习的数据处理管道在同一个集群中,创建CaffeOnSpark意在使得深度学习训练和测试能被嵌入到Spark应用程序(如图2)中。

CaffeOnSpark:API&配置和CLI
CaffeOnSpark被设计成为一个Spark深度学习包。Spark MLlib支持各种非深度学习算法用于分类、回归、聚类、推荐等,但目前缺乏深度学习这一关键能力,而CaffeOnSpark旨在填补这一空白。CaffeOnSpark API支持dataframes,以便易于连接准备使用Spark应用程序的训练数据集,以及提取模型的预测或中间层的特征,用于MLLib或SQL数据分析。

系统架构:

CaffeOnSpark系统架构如图4所示(和之前相比没有变化)。Spark executor中,Caffe引擎在GPU设备或CPU设备上,通过调用一个细颗粒内存管理的JNI层。不同于传统的Spark应用,CaffeOnSpark executors之间通过MPI allreduce style接口通信,通过TCP/以太网或者RDMA/Infiniband。这个Spark+MPI架构使得CaffeOnSpark能够实现和专用深度学习集群相似的性能。
许多深度学习工作是长期运行的,处理潜在的系统故障很重要。CaffeOnSpark支持定期快照训练状态,因此job出现故障后能够恢复到之前的状态。
雅虎已经在多个项目中应用CaffeOnSpark,如Flickr小组通过在Hadoop集群上用CaffeOnSpark训练数百万张照片,显著地改进图像识别精度。现在深度学习研究者可以在一个AWS EC2云或自建的Spark集群上进行测试CaffeOnSpark。
如果你还想学习Java工程化、高性能及分布式、深入浅出。性能调优、Spring,MyBatis,Netty源码分析等知识点可以来找我。
而现在我就有一个平台可以提供给你们学习,让你在实践中积累经验掌握原理。主要方向是JAVA架构师。如果你想拿高薪,想突破瓶颈,想跟别人竞争能取得优势的,想进BAT但是有担心面试不过的,可以加我的Java架构进阶群:514790886
注:加群要求
1、具有2-5工作经验的,面对目前流行的技术不知从何下手,需要突破技术瓶颈的可以加。
2、在公司待久了,过得很安逸,但跳槽时面试碰壁。需要在短时间内进修、跳槽拿高薪的可以加。
3、如果没有工作经验,但基础非常扎实,对java工作机制,常用设计思想,常用java开发框架掌握熟练的,可以加。
4、觉得自己很牛B,一般需求都能搞定。但是所学的知识点没有系统化,很难在技术领域继续突破的可以加。
5.阿里Java高级大牛直播讲解知识点,分享知识,多年工作经验的梳理和总结,带着大家全面、科学地建立自己的技术体系和技术认知!
6.小号加群一律不给过,谢谢。















 6159
6159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









