






记者:周建丁(邮箱:zhoujd@csdn.net,微信:jianding_zhou)
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2016年《程序员》
Andy Feng是Apache Storm的Committer,同时也是雅虎公司负责大数据与机器学习平台的副总裁。他带领雅虎机器学习团队基于开源的Spark和Caffe开发了深度学习框架CaffeOnSpark,以支持雅虎的业务团队在Hadoop和Spark集群上无缝地完成大数据处理、传统机器学习和深度学习任务,并在CaffeOnSpark较为成熟之后将其开源(https://github.com/yahoo/CaffeOnSpark)。Andy Feng接受《程序员》记者专访,从研发初衷、设计思想、技术架构、实现和应用情况等角度对CaffeOnSpark进行了解读。
CaffeOnSpark概况
CaffeOnSpark研发的背景,是雅虎内部具有大规模支持YARN的Hadoop和Spark集群用于大数据存储和处理,包括特征工程与传统机器学习(如雅虎自己开发的词嵌入、逻辑回归等算法),同时雅虎的很多团队也在使用Caffe支持大规模深度学习工作。目前的深度学习框架基本都只专注于深度学习,但深度学习需要大量的数据,所以雅虎希望深度学习框架能够和大数据平台结合在一起,以减少大数据/深度学习平台的系统和流程的复杂性,也减少多个集群之间不必要的数据传输带来的性能瓶颈和低效(如图1)。
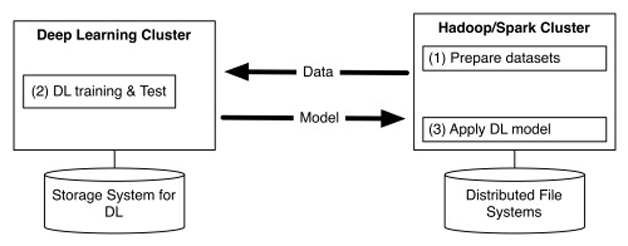
CaffeOnSpark就是雅虎的尝试。对雅虎而言,Caffe与Spark的集成,让各种机器学习管道集中在同一个集群中,深度学习训练和测试能被嵌入到Spark应用程序,还可以通过YARN来优化深度学习资源的调度。
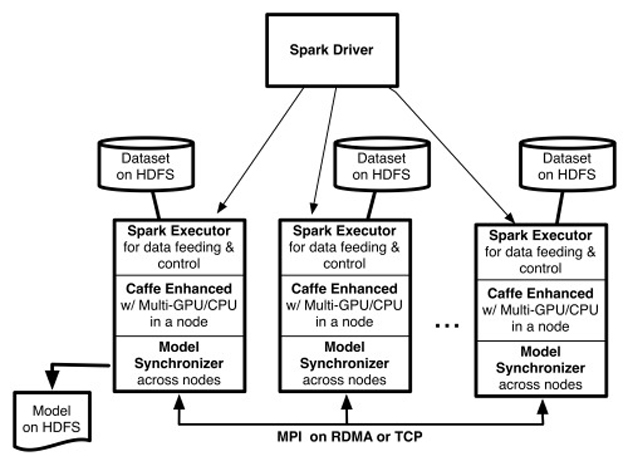
CaffeOnSpark架构如图2所示,Spark on YARN加载了一些执行器(用户可以指定Spark执行器的个数(–num-executors <# of EXECUTORS>),以及为每个执行器分配的GPU的个数(-devices <# of GPUs PER EXECUTOR>))。每个执行器分配到一个基于HDFS的训练数据分区,然后开启多个基于Caffe的训练线程。每个训练线程由一个特定的GPU处理。使用反向传播算法处理完一批训练样本后,这些训练线程之间交换模型参数的梯度值,在多台服务器的GPU之间以MPI Allreduce形式进行交换,支持TCP/以太网或者RDMA/Infiniband。相比Caffe,经过增强的CaffeOnSpark可以支持在一台服务器上使用多个GPU,深度学习模型同步受益于RDMA。
考虑到大数据深度学习往往需要漫长的训练时间,CaffeOnSpark还支持定期快照训练状态,以便训练任务在系统出现故障后能够恢复到之前的状态,不必从头开始重新训练。从第一次发布系统架构到宣布开源,时间间隔大约为半年,主要就是为了解决一些企业级的需求。
CaffeOnSpark解决了三大问题
《程序员》:在众多的深度学习框架中,为什么选择了Caffe?
Andy Feng:Caffe是雅虎所使用的主要深度学习平台之一。早在几个季度之前,开发人员就已将Caffe部署到产品上(见Pierre Garrigues在RE.WORK的演讲),最近,我们看到雅虎越来越多的团队使用Caffe进行深度学习研究。作为平台组,我们希望公司的其它小组能够更方便地使用Caffe。
在社区里,Caffe以图像深度学习方面的高级特性而闻名。但在雅虎,我们也发现很容易将Caffe扩展到非图像的应用场景中,如自然语言处理等。
作为一款开源软件,Caffe拥有活跃的社区。雅虎也积极与伯克利Caffe团队和开发者、用户社区合作(包括学术和产业)。
《程序员》:除了贡献到社区的特性,雅虎使用的Caffe相对于伯克利版本还有什么重要的不同?
Andy Feng:CaffeOnSpark是伯克利Caffe的分布式版本。我们对Caffe核心只做了细微改动,重点主要放在分布式学习上。在Caffe的核心层面,我们改进Caffe来支持多GPU、多线程执行,并引入了新的数据层来处理大规模数据。这些核心改进已经加入了伯克利Caffe的代码库,整个Caffe社区都能因此而受益。
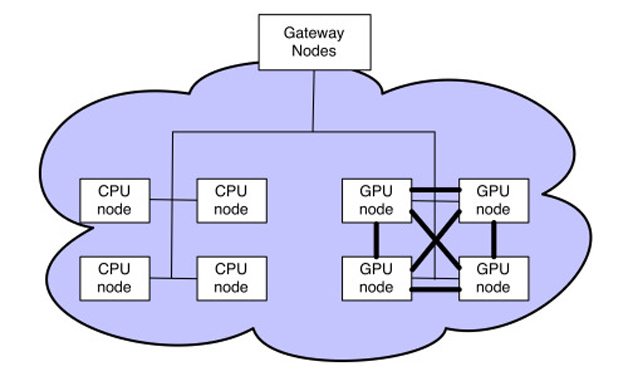
如图3所示,CaffeOnSpark支持在由网络连接的GPU和CPU服务器集群上进行分布式深度学习(用户可以自行选择向成本还是性能倾斜)。只需稍微调整网络配置,就能在自己的数据集上进行分布式学习。
《程序员》:CaffeOnSpark希望填补Spark在分布式深度学习方面的空白,但Caffe设计的初衷是解决图像领域的应用问题,而深度学习的应用不止于图像,能否介绍CaffeOnSpark目前具体支持的算法,以及使用场景有哪些?
Andy Feng:正如之前所提到的,Caffe在深度学习的应用远不止图像。举个例子,Caffe可以为搜索引擎训练Page Ranking模型。在那种场景下,训练数据由用户的搜索会话组成,包括搜索词、网页的URL和内容。
《程序员》:Caffe在与Spark的集成需要解决哪些问题?您的团队克服了哪些主要挑战?
Andy Feng:我们主要做了三个方面的事情:
性能
CaffeOnSpark是按照专业深度学习集群的性能标准而设计。
典型的Spark应用分配多个执行器(Executor)来完成独立的学习任务,并且用Spark驱动器(Driver)同步模型更新。二级缓存之间是相互独立的,没有通信。这样的结构需要模型数据在执行器的GPU和CPU之间来回传输,驱动器成了通讯的瓶颈。
为了实现性能标准,CaffeOnSpark在Spark执行器之间使用了peer-to-peer的通讯模式。最开始我们尝试了开源的OpenMPI,但OpenMPI的应用需要提前选好一些机器构建MPI集群,而CaffeOnSpark其实并不知道会用到哪些机器,所以我们研发了自己的MPI。
如果有无限的带宽连接,这些执行器就能够直接读取远端执行器的GPU内存。我们的MPI实现将计算和通讯的消耗分布到各个执行器上,因此消除了潜在的瓶颈。
大数据
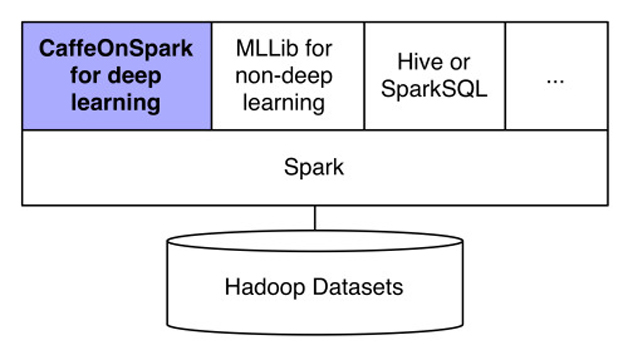
Caffe最初的设计只考虑了单台服务器,也就是说输入数据只在本地文件系统上。对于CaffeOnSpark,我们的目的是处理存储在分布式集群上的大规模数据,并且支持用户使用已经存在的数据集(比如LMDB数据集)。CaffeOnSpark引入了Data Source的概念,提供了LMDB的植入实现、数据框架、LMDB和序列文件。CaffeOnSpark不仅提供了深度学习的高级API,也提供了非深度学习和普通数据分析/处理的接口。详见我们博文的介绍。
编程语言
尽管Caffe是用C++实现的,但作为Spark的产品,CaffeOnSpark也支持Scala、Python和Java的可编程接口。内存管理对在JVM上长期运行的Caffe任务是一个挑战,因为Java的GC机制并没有考虑JNI层的内存分配问题。我们在内存管理上做了重大改变,通过一个自定义JNI实现。
《程序员》:目前Spark+MPI架构相比深度学习专用HPC集群的性能差异如何?TCP方法和RDMA方法的差别又是多大?
Andy Feng:我们的设计和Spark+MPI实现旨在取得和HPC集群相似的性能。这也是我们支持诸如无限带宽连接接口的原因。关于差别,我们还需要做一些扩展性的对照测试。
《程序员》:关于并行训练中常用的参数服务器(Parameter Server),CaffeOnSpark是如何设计的?
Andy Feng:参数服务器的主要目的是可以建立很大的模型,但目前的深度学习模型还很小,所以参数服务器的用处还不是很大。当然,我们也提供了参数服务器的功能,在需要的时候启用即可。
《程序员》:另一款Spark深度学习框架是伯克利AMPLab出品的SparkNet,此外《程序员》曾刊载过百度团队研发的Spark on PADDLE(),也是针对HDFS数据传输的瓶颈做了优化。您如何看待这些框架的不同?
Andy Feng:CaffeOnSpark和SparkNet都是为了在Spark集群上运行基于Caffe的深度学习项目。SparkNet用标准的Spark结构,在Spark执行器内用Spark驱动器和Caffe处理器通讯。
然而,CaffeOnSpark在Caffe处理器之前使用peer-to-peer通讯(MPI),避免驱动器潜在的扩展瓶颈。CaffeOnSpark支持Caffe用户已有数据集(LMDB)和配置、增量学习、以及机器学习管道的高级接口。详情参见 https://github.com/yahoo/CaffeOnSpark#why-caffeonspark。
对于Spark on PADDLE,我简单地浏览了《程序员》的文章,它的框架结构(和CaffeOnSpark)非常相似。由于Spark on PADDLE项目没有公开,不清楚它是怎么和Spark生态系统整合的,比如MLlib或者Spark SQL。
《程序员》:能否介绍CaffeOnSpark社区的规划,对开发者有什么要求?
Andy Feng:我们正在组织一个活跃的CaffeOnSpark社区。我们欢迎社区成员尝试使用CaffeOnSpark、提出问题、查找缺陷以及贡献解决方案。我们会采用GitHub审阅流程来确保所有代码都是高质量的。
《程序员》:能否介绍CaffeOnSpark开源之后的应用反馈?接下来它的功能改进和问题解决重点包括哪些?
Andy Feng:目前CaffeOnSpark支持同步分布式学习,我们计划在不久的将来支持异步分布式学习。我们的MPI也能通过改进来处理系统崩溃问题。
如我们预计,CaffeOnSpark开源之后,每天的访问量都在增长,包括一些国内的用户。很多人为他们在使用过程中遇到的一些问题向我们寻求帮助(估计用于图像类的应用比较多)。
例如,CaffeOnSpark发布的API主要是Scala API,一些用户提出了Java API的需求。这个请求是合理的,因为Spark支持Scala、Python和Java三种语言的API。我们会根据需求的强烈程度规划改进,但预计Python API很快就会出来。另外一个是UI方面的问题,我们后续也会逐步改进。
同时,用户之间也在交流他们使用的经验。因为雅虎能够自己测试的实际环境比较有限,针对一些问题我们也只能给出建议,用户相互的交流会找到一些方案,让CaffeOnSpark的发展更好。
《程序员》:您对CaffeOnSpark在Spark社区的发展有什么样的期待?
Andy Feng:我们希望CaffeOnSpark促使Spark社区致力于深度学习领域。在雅虎,我们已经看到深度学习在大数据集上取得的显著成果,也期待着听到社区成员传来更多的好消息。
订阅2016年程序员(含iOS、Android及印刷版)请访问 http://dingyue.programmer.com.cn

订阅咨询:
• 在线咨询(QQ):2251809102
• 电话咨询:010-64351436
• 更多消息,欢迎关注“程序员编辑部”















 6144
6144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









