







这里写目录标题
一、爬虫概念【2023.3.3】
通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。
价值:
抓取互联网上的数据,为我所用,有了大量的数据,就如同有了一个数据银行一样,下一步做的就是如何将这些爬取的数据产品化,商业化。
法律风险:
只要不影响网站的恶意运行就是善意爬虫和审查好抓取的不涉及个人隐私就没有法律风险。
分类:
通用爬虫(抓取系统-如google重要组成部分。抓取的是一整张页面数据。)
聚焦爬虫(是建立在通用爬虫的基础之上。抓取的是页面中特定的局部内容。)
增量式爬虫(监测网站中数据更新的情况。只会抓取网站中最新更新出来的数据。)
反爬机制:
门户网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
反反爬策略:
爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而获取门户网站信息。
【3.9】其余概念补充
离线爬虫是指根据条件直接将线上数据爬取之后保存在数据库中,待使用方需要时直接从库里提供数据的爬虫。
离线爬虫的数据量较大,适用于数据相对稳定并且使用范围较广的情况,不需要实时爬取,根据需要配置定时任务爬取并更新数据即可。这种爬虫常见于爬取房源、车源等数据。提供数据的方式一般是通过接口提供,请求参数中带查询条件即可,或者不需要请求参数直接返回所有数据。
实时爬虫是有请求触发后再去爬取的爬虫,实时爬虫根据是否需要授权又分授权爬虫和非授权爬虫。授权爬虫是指需要登录才可以获取的,如运营商数据、网银账单、淘宝记录等。授权爬虫的数据采集和解析对风控有非常重要的作用。这种爬虫需要谨慎处理。
-授权爬虫需要关注数据的解析、入库和计算,并且测试范围尽可能覆盖较多场景。授权爬虫的要求较高,技术难度较大,目前市面上有很多授权爬虫产品服务。
-非授权爬虫是不需要登录但是需要其它请求条件的爬虫,适用于数据使用范围较窄、实时性要求高的情况,比如舆情爬虫,需要查找某关键字时再进行实时爬取
二、反爬机制
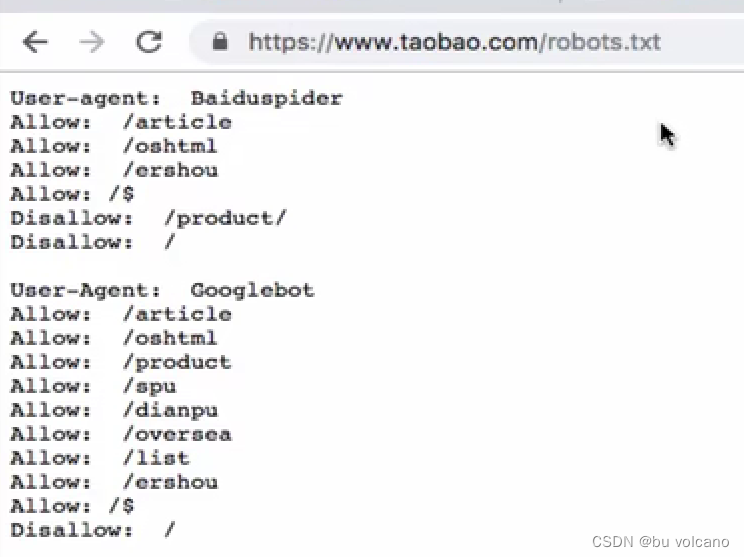
robots.txt协议
是一个君子协议。规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬取。
示例:disallow不允许以下目录
http(超文本传输协议)协议:
是服务器和客户端进行数据交互的一种形式。
https(security安全的超文本传输协议加密方式)协议:
①对称秘钥加密
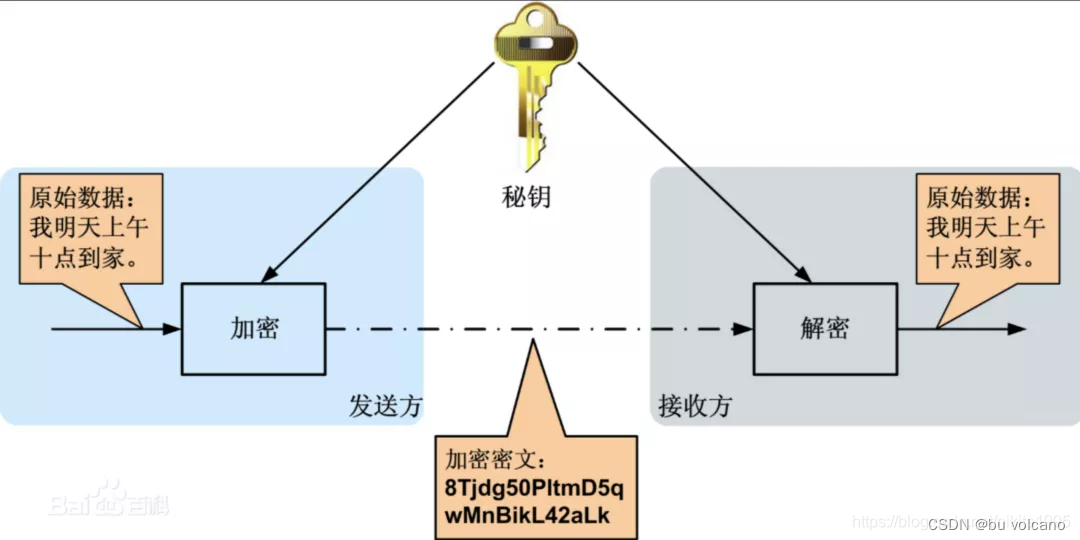
一旦截取密钥就不安全
②非对称秘钥加密
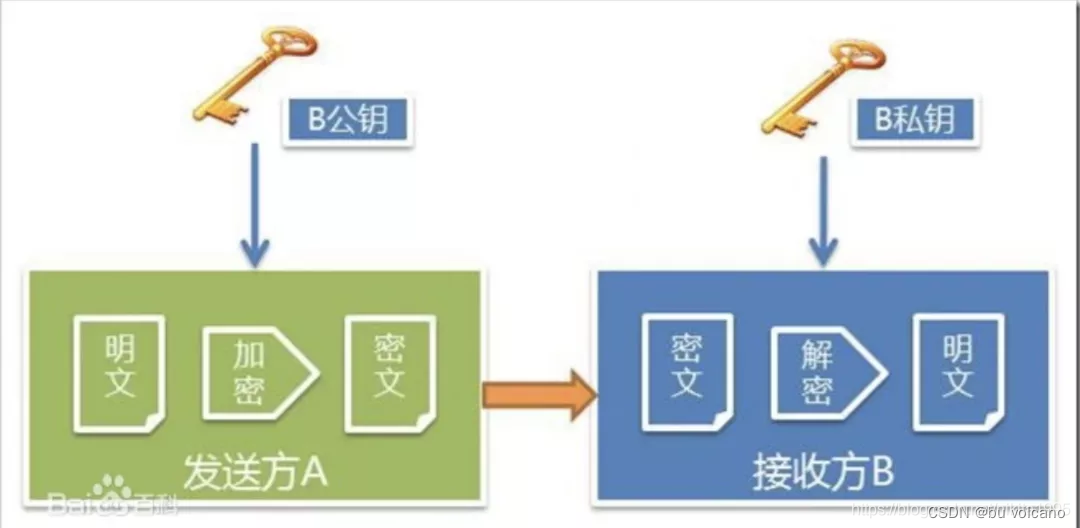
一旦截取到服务器给的公钥,可以篡改后再发送给客户端
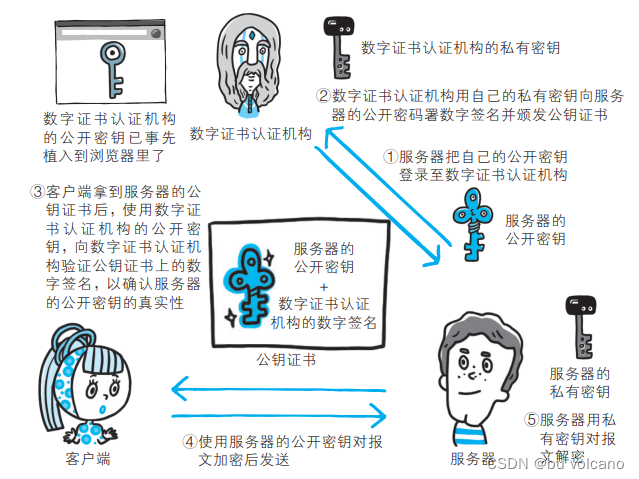
③证书秘钥加密
常用请求头信息:
-User-Agent:请求载体的身份标识
-Connection:请求完毕后,是断开连接还是保持连接
常用响应头信息:
-Content-Type:服务器响应回客户端的数据类型
【2023.3.4】
三、请求模块
requests模块:python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
作用:模拟浏览器发请求。
如何使用:(requests模块的编码流程)
(1)指定url
①伪装头信息
②封装参数信息
(2)发起请求
(3)获取响应数据
(4)持久化存储
【2023.3.5-6】
药监总局练习
【2023.3.9】
四、聚焦爬虫
概念爬取页面中指定的内容
原理 解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储
数据解析分类
步骤
获取响应数据后进行数据解析
1.进行指定标签的定位
2.标签或者标签对应的属性中存储的数据值进行提取(解析)
方式:
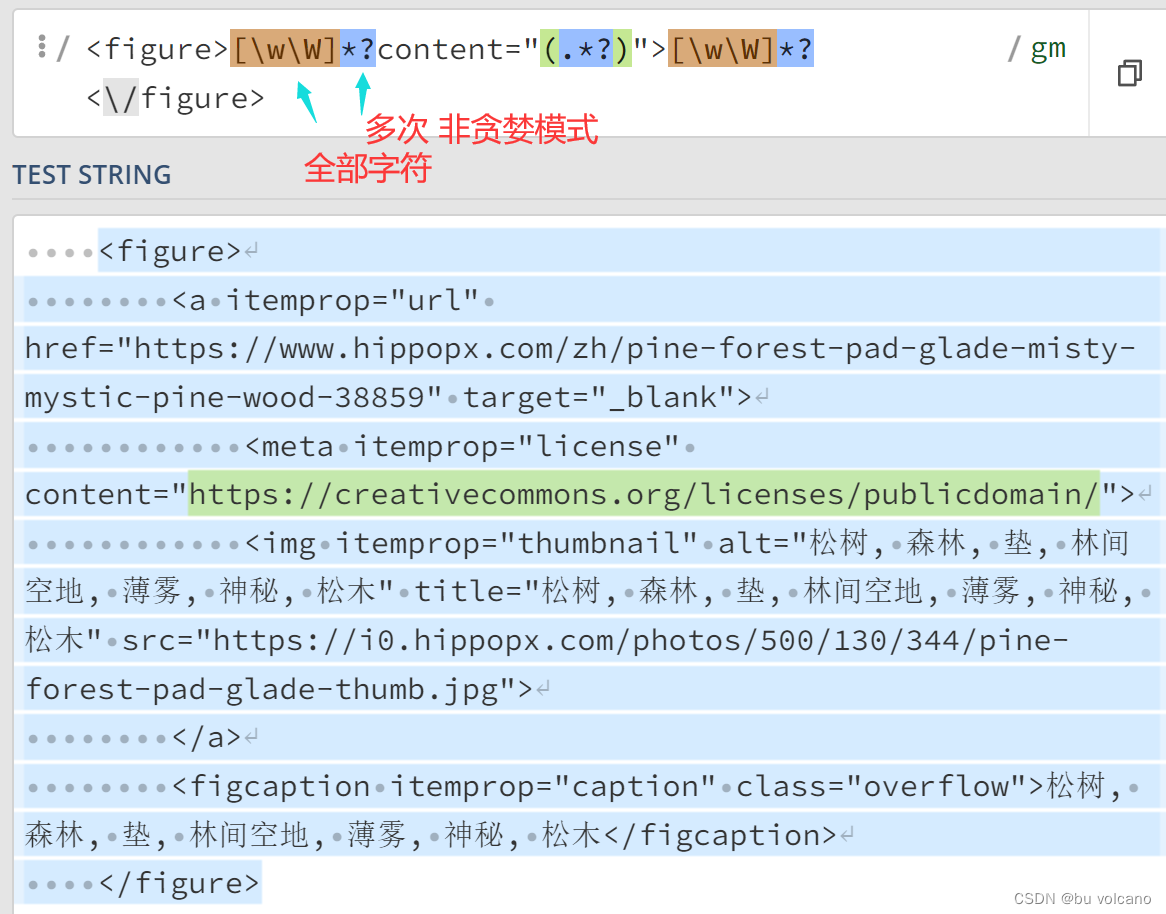
(1)正则
通配符的增强版
.*? (.是任意字符,*是匹配多次,?是非贪婪模式,但是没有包含换行符;因此使用编译标志re.DOTALL也可以是re.S又加上\n)
【3.31】

^ 表示匹配字符串的开始位置
[^\d\::]+? 表示匹配任意非数字、冒号、中文冒号的一个或多个字符,非贪婪匹配
(有限|股份) 表示匹配“有限”或“股份”
【3.10】
(2)bs4
【3.11】
(3)xpath
1.实例化etree对象,且需要将被解析的页面源码数据加载到该对象中。
如何实例化一个etree对象:from lxml import etree
①将本地的html文档中的源码数据加载到etree对象中:
etree.parse(filePath)
②可以将从互联网上获取的源码数据加载到该对象中
etree.HTML( ’ page_text’)
2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。
使用xpath(‘xpath表达式’)
form lxml import etree
/表示的是从根节点开始定位。表示的是一个层级。
//表示的是多个层级。可以表示从任意位置开始定位。
./局部的数据解析带点
属性定位://div[class=“song”] =tag [@attrName=“attrValue”]
索引定位://div[class=“song”]/p[3] 索引是从1开始的。
-取文本:
/text() 获取的是标签中直系的文本内容
//text() 获取的是标签中非直系的文本内容(所有的文本内容)
-取属性:
/@attrName
#通用处理中文乱码的解决方案
img_name = li.xpath( ’ ./a/ img/@alt ’ )[0]+‘.jpg’
img_name = img_name.encode( ‘iso-8859-1 ‘).decode( ’ gbk ’ )
#可以同时使用两个解析表达式 中间加|表示或者
【3.13】
图片练习
【3.15】selenium
基于浏览器自动化的一个模块。
【3.16】各种selenium操作
定位元素点击元素:
from selenium.webdriver.common.by import By
①打开F12复制xpath
②el = find_element(By.XPATH,’’)
③el.click()
定位输入框输入key+回车
from selenium.webdriver.common. keys import Keys #键盘按键包
el = find_element(By.XPATH,‘’).send_keys(“文本”,Keys.ENTER) ##键盘操作
获取文本信息
【3.17】无头浏览器
处理select下拉列表
from selenium.webdriver.support.select import Select
ele = driver.find_element(By. ID, 'selectA"》select = Select(ele)
s leep(1)
select.select_by_index(2)slenp(1)
select.select_by_walue("bj-》sleep(1)
select.select_by_visible_text("A重庆"》
【2023.7.27】页面等待
①强制等待 time.sleep()
②显示等待 等待某个元素出现为止
③隐式等待 deiver.implicitly_wait() 等待所有元素加载完毕
【7.28】CSS选择器
find_element_by_css_selector(“#属性名”).send_keys(“属性值”)
#代表id .代表class
find_element_by_css_selector(“[value=百度一下]”).send_keys(“属性值”)


【7.29】页面滚动
通过执行js代码
js_str =“window.scrollTo(0,10000)”#滚动到最下面
driver.execute_script(js_str)
警告框
就是通过js 中的alert、confirm、prompt方法弹出的框。它会阻挡我们对网页的继续操作。
相应方法步骤:
1.获得警告框 alert=driver.switch_to.alert
2.关闭警告框:适用于三种警告框alert.dismiss()
3.确认(也会自动关闭):适用于confirm和prompt alert.accept()
其余操作:
输入文字;适用于prompt alert.send_keys()
获得警告框中的文字alert.text
Frame
在Web Ui自动化的测试中,如果一个元素定位不到,那么最大的可能
定位的元素属性是在 iframe 框架中,iframe 是 html 中的框架,在 html 中,
所谓框架就是可以在同一个浏览器窗口中显示不止一个页面,一个页面嵌套了另外一个页面。
1.切到frame中
driver.switch_to.frame(0) # 1.用frame的index来定位,第一个是0
driver.switch_to.frame(“frame1”) # 2.用id来定位
driver.switch_to.frame(“myframe”) # 3.用name来定位
driver.switch_to.frame(driver.find_element_by_tag_name(“iframe”)) # 4.用WebElement对象来定位
切换页面
1.driver.window_handles 窗口的句柄
2.driver.switch_to.window(driver.window_handles[要去到的窗口位置])
截图
driver.get_screenshot_as_file(“文件位置”)
Cookies
driver.add_cookie(“name”:“”,“value”:“”)
time.sleep(2)
driver.refresh()
五、scrapy框架【3.23】
概念:
框架就是一个集成了很多功能并且具有很强通用性的一个项目模板。
前期先专门学习框架封装的各种功能的详细用法,然后再学习底层源码。
scrapy是一个使用率较高的python爬虫中封装好的框架。
功能:
高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式
基本使用:
windows安装:##python3.6
- pip install wheel
-下载twisted,(借用它实现异步数据下载)下载地址为http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
-安装twisted: pip install Twisted-17.1.0-cp36-cp36m-win_amd64.whl - pip install pywin32(捕获窗口、模拟鼠标键盘动作、自动获取某路径下文件列表)
- pip install scrapy
测试:在终端里录入scrapy指令,没有报错即表示安装成功!
【3.25】
-创建一个工程:
-scrapy startproject xxxPro
-cd xxxPro 在spiders子目录中创建一个爬虫文件
-scrapy genspider spliderName www. XXX.com
-执行工程:
-scrapy crawl spiderName
【3.27】
-crapy数据解析
【3.28】
-scrapy持久化存储
①基于终端指令:
要求:只可以将解析方法的返回值存储到本地的文本文件中
注意:持久化存储对应的文本文件的类型只可以为:‘json’,‘jsonlines’,‘j1’,‘csv’,‘xml’,-指令:scrapy爬行xxx-o filePath
好处:简介高效便捷
缺点:局限性比较强(数据只可以存储到指定后缀的文本文件中)
②基于管道:
编码流程:
先数据解析
在item类中定义相关的属性
将解析的数据封装存储到item类型的对象
将item类型的对象提交给管道进行持久化存储的操作
在管道类的processitem中要将其接受到的item对象中存储的数据进行持久化存储操作-在配置文件中开启管道
好处:通用性强
【4.8】scrapy 全站数据爬取
基于Spider的全站数据爬取
-就是将网站中某板块下的全部页码对应的页面数据进行爬取一需求:爬取校花网中的照片的名称
-实现方式:
-将所有页面的url添加到start_urls列表(不推荐)-自行手动进行请求发送(推荐)
-手动请求发送:
- yield scrapy.Request(url,callback) :callback专门用做于数据解析
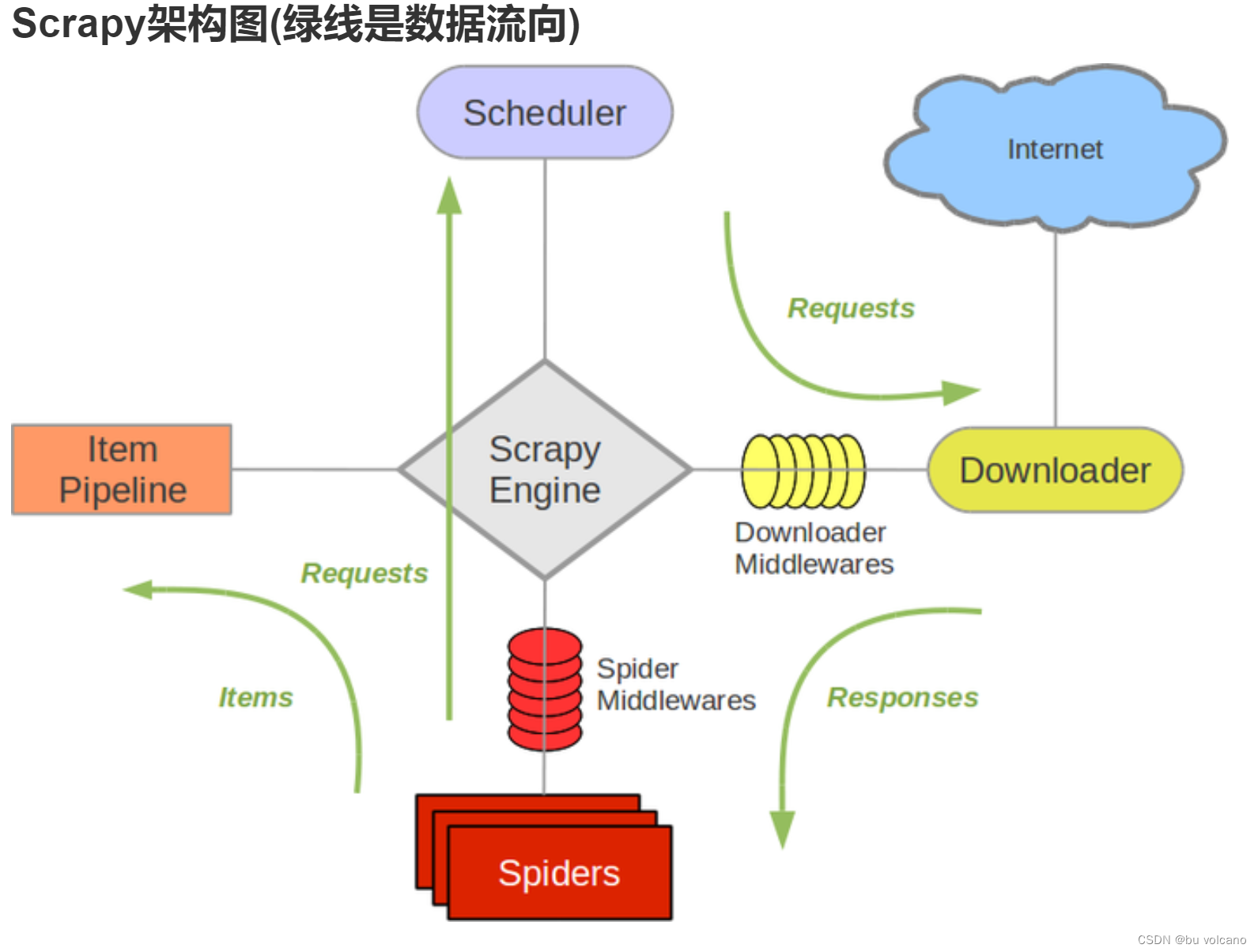
【4.9】五大组件
1.引擎(Scrapy)
用来处理整个系统的数据流处理,触发事务(框架核心)
2.调度器(Scheduler)
用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回.可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址
3.下载器(Downloader)
用于下载网页内容,并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
4.爬虫(Spiders)
爬虫是主要干活的,用于从特定的网页中提取自己需要的信息,即所谓的实体(ltem)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
5.项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
六、综合案例–爬取农业银行所有网点地址信息
6.1 实操练习:爬取中国农业银行所有网点的名称、具体地址
6.2 所用技术栈
requests.GET
XPATH
Selenium
学习过程笔记:CSDN
6.3 过程分析
目标地址:http://app.abchina.com/Branch/Default.aspx
目标网页:
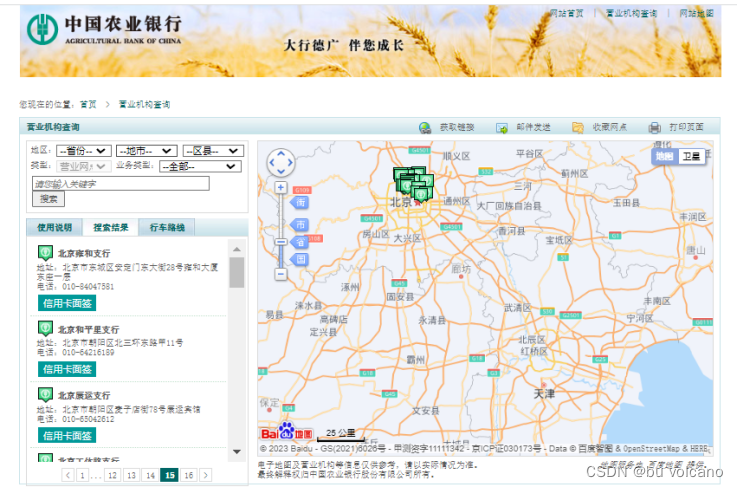
1.静态动态网页分析:
(1)通过观察网页后缀发现为aspx,这与htm、html相反属于动态网页。
易混淆点: html与shtml的区别是:前者为纯静态(客户端浏览器读取html文件是什么就呈现什么内容);而后者shtml则可以使用SSI指令(客户端浏览器读取html文件A,其中使用了include B的SSI指令,则会在A页面显示A+B的内容;但是当我们查看网页源代码,不会发现B页面引入痕迹,而是看到B页面内容完全在A页面里)。
(2)通过禁止JavaScript可以看出select下拉框无选项了。因此考虑爬取动态网页方法。

2.步骤设计
总体步骤:首先检查源码得到网点名称和地址是通过AJax动态请求的并确定URL携带两个本次可用参数P(省份)和i(页码);其次使用requests.get( )得到对应p;然后使用selenium对下拉框进行模拟得到页面源码后通过xpath定位得到i;最后将循环请求得到网点名称和地址进行存储。
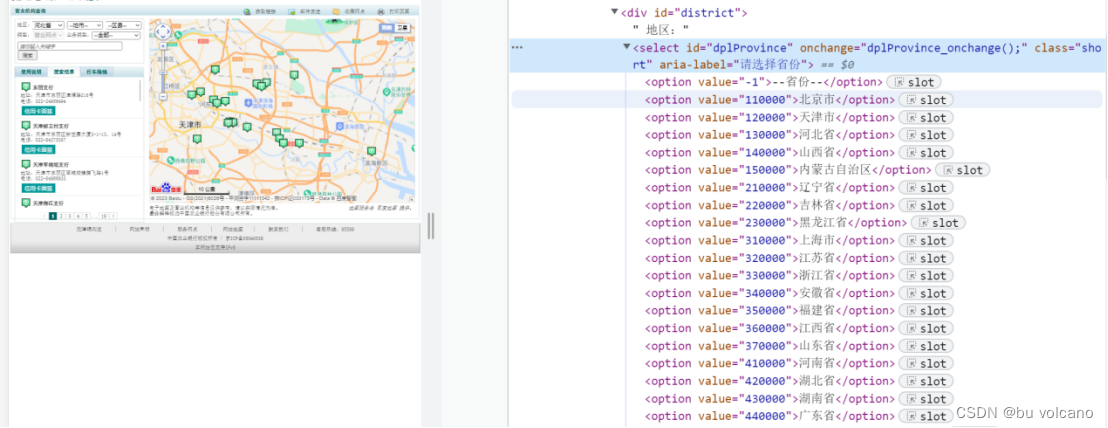
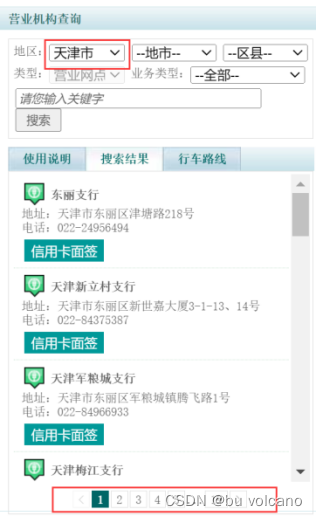
(1)问题:观察页面看到左边栏有三级下拉框(图1),但是通过查询省选项可以得到本省的所有网点。并且通过‘检查’源码定位到后可以得到每个省份对应着一个value(图2)。
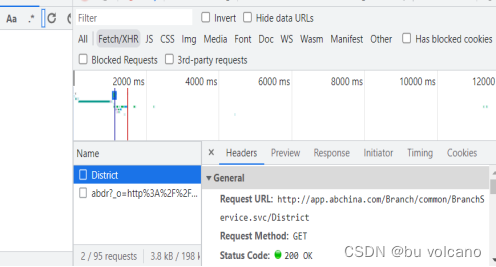
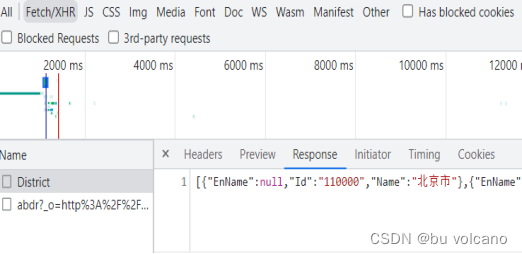
通过观察XHR可以看到网页刚开始加载完毕时已经请求到了所有省份对应value信息(图3)。
解决方法:通过GET请求获取到每个省份对应的值,以备后续使用。
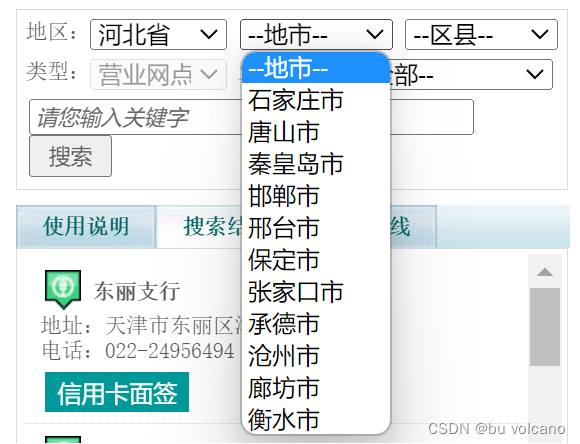
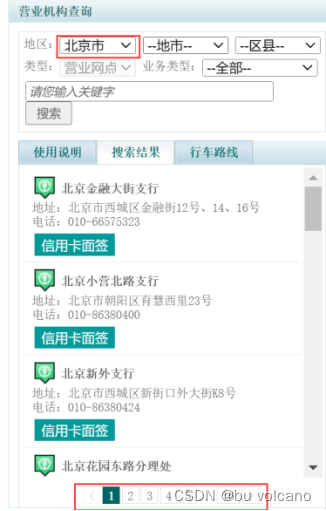
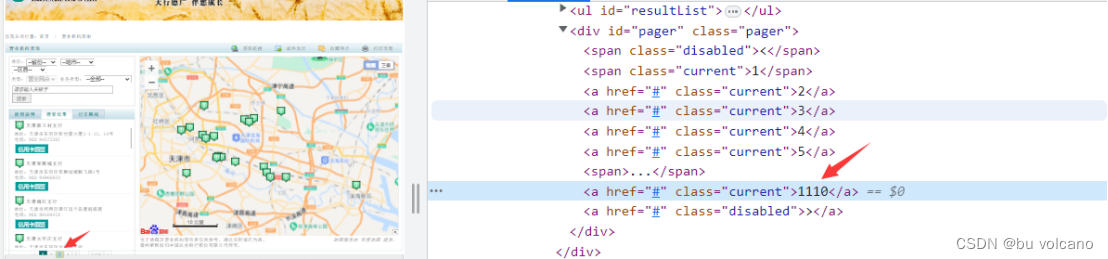
(2)问题:通过观察网页左栏可以看出省份不一样时银行网点个数也不一样(图4),从而导致页码数不一样。通过观察源码可以发现只有click搜索时才能得到对应的page数(图5)。
解决方法:通过selenium对下拉菜单进行模拟得到每个省份对应的page请求;然后通过xpath定位取到最大page数。
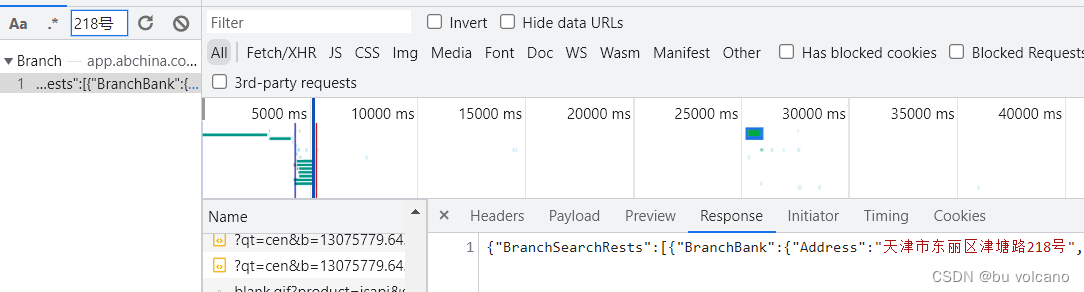
(3)问题:通过观察请求银行网点信息的URL可以得到其携带着province参数和page参数。(图6)
解决方法:通过遍历前面得到province和page对p和i赋值,然后解析得到的response得到网点名称和地址,最后进行永久存储。
http://app.abchina.com/Branch/common/BranchService.svc/Branch?p=110000&c=-1&b=-1&q=&t=1&z=0&i=0
http://app.abchina.com/Branch/common/BranchService.svc/Branch?p=120000&c=-1&b=-1&q=&t=1&z=0&i=5
6.4 爬取中间结果及源码
import requests
import time
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
'''
爬取农业银行所有的地址信息
分析:
得到所有的省份option代号和对应的最大page
通过GET即可循环取得所有地址
'''
# url = "https://b.pingan.com.cn/papb/ebank/pc-map/geren/fuwuwangdian/map.shtml"
url1 = "http://app.abchina.com/Branch/common/BranchService.svc/District"
header = {
'user_Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Mobile Safari/537.36'
}
#1.获取所有的省份value
response = requests.get(url=url1,headers=header).json()
province_list = []
for i in response:
province_list.append(i["Id"])
# print(province_list)
# ex = '/value="(\d*?)">'
# province_list = re.findall(ex,response,re.S)
##2.获取所有对应省份的最大page
#定位下拉列表
url2 = "http://app.abchina.com/Branch/Default.aspx#"
bro = Edge()
bro.get(url2)
sel_el1 = bro.find_element(By.XPATH,'//*[@id="dplProvince"]')
# ##对元素进行包装,包装成下拉菜单
sel_Province = Select(sel_el1)
# ##让浏览器进行选项调整
# ##获取所有的选项
page_max_list = []
for i in range(len(sel_Province.options)):
print('province',i)
sel_Province.select_by_index(i)
time.sleep(2)
el_Serch = bro.find_element(By.XPATH,'//*[@id="btnSearch"]').click()
time.sleep(2)
div_pager_max = bro.find_element(By.XPATH,'//*[@id="pager"]/a[last()-1]').text##获取最大page 第一个后面舍弃
page_max_list.append(div_pager_max)
print(page_max_list)
##循环爬取所有网点信息
url3 = "http://app.abchina.com/Branch/common/BranchService.svc/Branch"
name_list=[]
address_list =[]
for ind, province_value in enumerate(province_list):
page_max = page_max_list[1:][ind]##从第二个最大页数开始
for page in range(int(page_max)):
print(page)
params = {
'p': province_value,
'c': '-1',
'b': '-1',
'q': '',
't': '1',
'z': '0',
'i': page,
}
response_final = requests.get(url=url3,headers=header,params=params).json()["BranchSearchRests"]
# print(response_final)
for i in response_final:
name_list.append(i["BranchBank"]["Name"])
address_list.append(i["BranchBank"]["Address"])
# #step4:持久化存储















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











