







Time Interval Aware Self-Attention for Sequential Recommendation
WSDM ’20
ABSTRACT
顺序推荐系统寻求利用用户交互的顺序,以便根据用户最近所做的事情来预测他们的下一步行动。传统上,马尔可夫链(MCs)和最近的循环神经网络(RNNs)和自我注意(SA)由于它们捕捉序列模式的动态的能力而得到广泛发展。然而,大多数这些模型所做的一个简化假设是将互动历史视为有序的序列,而不考虑每个互动之间的时间间隔(即,它们模拟了时间顺序,但没有实际的时间戳)。在本文中,我们试图在一个顺序建模框架内明确地对交互的时间戳进行建模,以探索不同时间间隔对下一个项目预测的影响。我们提出了TiSASRec(时间间隔感知自我注意的序列推荐),它既建模了项目的绝对位置,也建模了它们之间的时间间隔。广泛的实证研究显示了TiSASRec在不同设置下的特点,并比较了自我注意与不同位置编码的表现。此外,实验结果表明,该方法在稀疏和稠密数据集以及不同评价指标上均优于各种先进的序列模型。
1 INTRODUCTION
在电子商务、朋友建议、新闻推荐等应用程序中,对顺序交互进行建模是必不可少的。有两条重要的工作线试图挖掘用户的交互历史:时间推荐和顺序推荐。时间推荐[17,29,31,35]侧重于对绝对时间戳进行建模,以捕获用户和商品的时间动态。例如,在不同的时间段,一个项目的受欢迎程度可能会改变,或者用户的平均评分可能会随着时间的推移而增加或减少。这些模型在研究数据集的时间变化时很有用。他们考虑的不是顺序模式,而是依赖于时间的时间模式。
以前的大多数顺序推荐者都是根据交互时间戳对项目进行排序,并将重点放在顺序模式挖掘上,以预测可能与之交互的下一个项目。一个典型的解决方案是基于马尔科夫链的方法[7, 8, 21],其中一个L阶马尔科夫链根据之前的L个行动提出建议。基于马尔科夫链的方法已经成功地被采用来捕捉短期的项目转换以进行推荐[14]。 它们通过强有力的简化假设在高稀疏度环境中表现良好,但在更复杂的情况下可能无法捕捉到错综复杂的动态变化。循环神经网络(RNNs)[11, 12]也被应用于这种环境。虽然RNN模型在用户的偏好上有很长的 “记忆”,但它们需要大量的数据(尤其是密集的数据),然后才能超越更简单的基线。为了解决马尔科夫链模型和基于rnn的模型的缺点,[14]受到机器翻译的Transformer[26]的启发,提出将自注意机制应用于顺序推荐问题。基于自注意的模型明显优于最新的基于MC/CNN/ rnn的顺序推荐方法。
通常,以前的顺序推荐方法丢弃时间戳,只保留项目的顺序,也就是说,这些方法(隐式地)假定序列中所有相邻的项目具有相同的时间间隔。影响下一个项目的因素仅仅是前一个项目的位置和身份。但是,直观地看,时间戳越近的项目对下一个项目的影响越大。 例如,两个用户有相同的交互序列,但其中一个用户在一天内产生了这些交互,而另一个用户在一个月内完成了这些交互,因此,这两个用户的交互应该对下一个项目产生不同的影响,即使他们的序列位置相同。然而,以前的顺序推荐技术将这两种情况视为相同,因为它们只考虑顺序位置。

在本文中,我们认为用户交互序列应该被建模为一个具有不同时间间隔的序列。图2表明交互序列有不同的时间间隔,其中一些时间间隔可能很大。以往的工作省略了这些时间间隔及其对预测项目的影响。为了解决上述局限性,在相对位置表征的自我关注的启发下[22],我们提出了一个时间感知的自我关注机制。这个模型不仅考虑了像SASRec[14]这样的项目的绝对位置,而且考虑了任意两项之间的相对时间间隔。从我们的实验中,我们观察到我们的模型在稠密和稀疏数据集上都优于最先进的算法。最后,我们的贡献总结如下:
我们建议将用户的交互历史视为一个具有不同时间间隔的序列,并将不同的时间间隔建模为任意两个交互之间的关系。
我们结合了绝对位置和相对时间间隔编码的在自我注意方面的优点,设计了一种新的时间间隔感知自注意机制来学习不同项目的权重、绝对位置和时间间隔来预测未来项目。
我们进行了全面的实验,研究绝对位置和相对时间间隔以及不同组件对TiSASRec性能的影响,并表明它在两个排名指标方面优于最先进的基线。
2 RELATED WORK
2.1 Sequential Recommendation
顺序推荐系统在用户交互序列中挖掘模式。一些捕获项目-项目转换矩阵来预测下一个项目。例如,FPMC[21]通过矩阵分解和转换矩阵对用户的长期偏好和动态转换进行建模。转换矩阵是一阶马尔可夫链(MC),它只考虑当前项与前一项之间的关系。Fossil[8]使用基于相似性的方法和高阶马尔可夫链,该方法假设下一个项目与之前的几个项目相关,[7]证明基于高阶MC的模型在稀疏数据集上有很强的性能。基于CNN(卷积神经网络)的方法[24, 25]也被提出来,将之前的几个项目视为一个 “图像”,并通过CNN在union-level上挖掘项目之间的转换。MARank[34]通过结合残差网络和多阶注意,统一了individual-level和union-level的前一项转换。SHAN[33]通过两层关注机制对用户的前几项和长期历史进行建模,获得用户的短期和长期偏好。
基于rnn(循环神经网络)的模型,如[3,12,13,18]使用rnn来建模整个用户序列。这些方法在密集数据集上表现良好,但在稀疏数据集上表现较差。
2.2 Attention Mechanisms
注意机制已被证明在各种任务中是有效的,如图像说明[32]和机器翻译[2]。本质上,注意力机制背后的想法是,输出依赖于输入中相关的特定部分。这种机制可以计算输入的权重,使模型更易于解释。最近,注意机制已经被纳入推荐系统[5,28,30]。一种纯粹基于注意力的序列到序列的方法,Transformer[26],在机器翻译任务上取得了最先进的性能。Transformer使用了缩放的点积注意力,定义为:
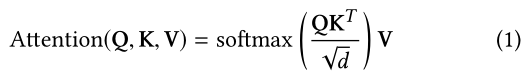
其中 Q 、 K 、 V Q、K、V Q、K、V分别表示查询、键和值。在self-attention中,三种输入通常使用同一个对象。
Transformer的自关注模块也被应用到推荐系统[14]中,在顺序推荐方面取得了较好的效果。由于自注意模型不包括任何循环或卷积模块,它不知道前面项目的位置。一种解决方案是在输入中添加位置编码,可以是确定性函数或可学习的位置嵌入[23,26]。另一种解决方案使用相对位置表示[4,22]。它们将两个输入元素之间的相对位置建模为成对关系。受相对位置self-attention的启发,我们将绝对位置和相对位置相结合,设计出具有时间意识的自注意模型,该模型模拟了项目的位置和时间间隔。
3 PROPOSED METHOD
在这一节中,我们首先提出我们的下一个物品推荐问题,然后描述我们获得时间间隔的方法和TiSASRec的组成部分,其中包括个性化的时间间隔处理、嵌入层、时间感知的自我注意块和预测层。我们嵌入项目、它们的绝对位置和相对时间间隔。注意力权重是通过这些嵌入来计算的。如图1所示,我们的模型在不同的时间间隔下会有不同的预测项目,即使之前的几个项目是相同的。为了学习参数,我们采用二元交叉熵损失作为我们的目标函数。TiSASRec的目标是捕获序列模式,并探索时间间隔对序列推荐的影响,这是一个未探索的领域。

3.1 Problem Formulation
让 U U U和 I I I分别表示用户集和项目集。在时间感知的序列推荐设置中,对于每个用户 u ∈ U u∈U u∈U,我们给出用户的行为序列,记为 S u = ( S 1 u , S 2 u , . . . , S ∣ S u ∣ u ) , S^{u}= (S_{1}^{u},S_{2}^{u}, . . .,S_{|S^{u}|}^{u}), Su=(S1u,S2u,...,S∣Su∣u),其中 S t u ∈ I S_{t}^{u}∈I Stu∈I,时间序列 T u = ( T 1 u , T 2 u , … T ∣ T u ∣ u ) T^{u}= (T_{1}^{u},T_{2}^{u},…T_{|T^{u}|}^{u}) Tu=(T1u,T2u,…T∣Tu∣u)对应行为序列。在训练过程中,在时间步长 t t t时,模型根据前 t t t个项目以及项目 i i i和 j j j之间的时间间隔 r i j u r_{ij}^{u} riju预测下一个项目。 我们的模型的输入是 ( S 1 u , S 2 u , . . . , S ∣ S u ∣ − 1 u ) (S_{1}^{u},S_{2}^{u}, . . .,S_{|S^{u}|-1}^{u}) (S1u,S2u,...,S∣Su∣−1u)和序列中任何两个项目之间的时间间隔 R u R^{u} Ru,其中 R u ∈ N ( ∣ S u ∣ − 1 ) × ( ∣ S u ∣ − 1 ) R^{u}∈N^{(|S^{u}|-1)×(|S^{u}|-1)} Ru∈N(∣Su∣−1)×(∣Su∣−1)。每次我们想要的输出都是下一个项目: ( S 2 u , S 3 u , . . . , S ∣ S u ∣ u ) (S_{2}^{u},S_{3}^{u}, . . .,S_{|S^{u}|}^{u}) (S2u,S3u,...,S∣Su∣u)。
3.2 Personalized Time Intervals
我们转换训练序列 ( S 1 u , S 2 u , . . . , S ∣ S u ∣ − 1 u ) (S_{1}^{u},S_{2}^{u}, . . .,S_{|S^{u}|-1}^{u}) (S1u,S2u,...,S∣Su∣−1u)化为定长序列 s = ( s 1 , s 2 , . . . , s n ) s = (s_{1},s_{2}, . . .,s_{n}) s=(s1,s2,...,sn)<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1426
1426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









