






点击上方,选择星标,每天给你送干货!
干货
作者:一元,四品炼丹师
来自:炼丹笔记
Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation(AAAI2021)
1. 前言
序列推荐系统的目标是从用户的历史行为中对用户的兴趣进行建模,从而进行时间相关的个性化推荐。
早期的模型,比如CNN和RNN等深度学习方法在推荐任务中都取得了显著的提升。近年来,BERT框架由于其在处理序列数据时的self-attention机制,已经成为了一种最好的方法。然而,原BERT框架的一个局限性是它只考虑自然语言符号的一个输入源。
在BERT框架下如何利用各种类型的信息仍然是一个悬而未决的问题。
尽管如此,利用其他方面的信息,如商品的类别或tag标签,进行更全面的描述和更好的推荐,在直觉上还是很有吸引力的。在我们的初步实验中,我们发现一些简单的方法,直接将不同类型的附加信息融合到商品embedding中,通常只带来很少甚至负面的影响。
因此,本文在BERT框架下提出了一种有效利用边信息的无创自我注意机制(NOVA,NOninVasive self-Attention mechanism)。NOVA利用side信息来产生更好的注意力分布,而不是直接改变商品嵌入,这可能会导致信息泛滥。
我们在公共数据集和商业数据集上都验证了NOVA-BERT模型,并且我们的方法在计算开销可以忽略的情况下可以稳定地优于最新的模型。
序列化推荐的目标之一基于用户的历史行为,预测用户下一个感兴趣的商品。和用户级别或者基于相似度的静态方法相比,序列化推荐系统还会对用户变化的兴趣进行建模,因此对于现实的应用会更为受欢迎。
在大量的实验中,我们发现基于transformer的模型被认为是处理序列化数据最好的选择。而其中,最为出名的就是Bert模型,通过利用bert模型,Bert4Rec取得了当时的SOTA效果。尽管Bert框架在许多任务上都取得了SOTA的效果,但是还存在一个较大的问题。
对于利用不同类型的side信息,还没有进行过系统的研究;
除了Item的ID信息,我们还存在非常多的side信息,例如评分和商品描述。然而,BERT框架最初设计为只接受一种类型的输入(即wordid),限制了side信息的使用。通过试点实验,我们发现现有的方法通常利用side信息(图1),但很少有效果。
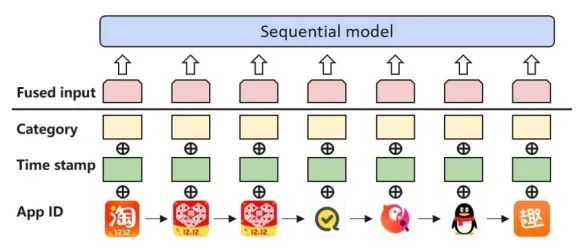
但是理论上来说,side信息通过提供更多的数据是可以带来帮助的,但是,如何使用好这些额外的信息来设计模型是非常有挑战的。
在本文中,我们研究如何使用大量的side信息,并提出了NOVA(Non-inVasive self-Attention mechanism),通过使用side信息来提升模型的预测准确率并且取得了非常好的效果。
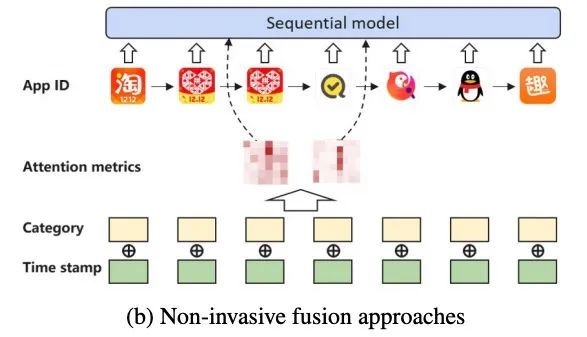
在NOVA中,side信息作为self-attention模块的辅助信息来学习更好的注意分布,而不是融合到Item表示中,这可能会导致信息压倒性等副作用。我们在实验室数据集和从真实应用商店收集的私有数据集上验证了NOVA-BERT设计效果。结果证明了该方法的优越性。本文的核心贡献有三点:
提出了NOVA-BERT框架,该框架可以有效地利用各种side信息进行序列化的推荐任务;
我们提出了非切入(non-invasive)的self-attention机制(NOVA),这是一种新的设计,可以实现对复合序列数据的self-attention;
基于可视化给出了模型的可解释性。
2. 相关工作
2.1 不同类型的模型比较
从早期的CNN->RNN->Attention的演化中,我们发现基于BERT类型的模型可以获得最好的效果。

2.2 序列化推荐模型的问题
在之前诸多的问题中,大家都知道side information是非常重要的,但是关于side information如何使用的问题却很少研究,之前的框架都是基于invasive fusion的方式;关于Invasive fusion的方法包括:
Summation
Concatenation
Gated Sum
通过上面的操作,然后将混合的信息输入到NN中,我们称此类方法为Invasive的方法,因为它们改变了原始的表示。
以前的CNN和RNN工作都试图利用side信息,将side信息直接融合到商品embedding中,并进行concatenation和addition等操作。
其它一些工作如GRU等提出了更复杂的特征融合门机制和其它训练技巧,试图使特征选择成为可学习的过程。然而,根据他们的实验结果,简单的方法不能有效地利用各种场景下的丰富信息。尽管Hidasi等人通过为每种类型的side信息部署一个并行子网来提高预测精度,但该模型变得繁琐且不灵活。
还有一些研究,并不直接改变商品的embedding,而是使用RNN模型通过item boosting的trick来加入停留时间,这么做我们希望损失函数能意识到dwell time,用户看一个商品的时间越长,她/他可能对某件商品更加感兴趣,但是该trick却更加依赖于启发式。另一方面,一些与商品相关的辅助信息(如价格)描述了商品的内在特征,这些特征与停留时间不同,不容易被此类方式利用。
3. 方法
3.1 问题描述
给定一个用户的历史交互,顺序推荐任务要求与下一个商品交互,或者执行下一个操作。我们用 表示一个用户, 他的历史交互可以被表示为:
其中商品 表示第 个交互(也可以表示为行为),当有一类行为并且没有side信息,每个交互可以通过商品的id进行表示:
其中 表示第 个商品ID,
是所有商品的vocabulary, 是字典大小,给定用户的历史,我们的目标是预测用户最有可能交互的下一个商品。
3.2 Side信息
Side信息可以是为推荐提供额外有用信息的任何内容,可以分为两种类型:
商品相关信息或行为相关信息。
基于商品的side信息是固有的,它们可以表述商品,除了商品ID等还可以加入(price,商品的日期,生产者等等)。
与行为相关的side信息与用户发起的交互有关,例如操作类型(例如,购买、打分)、执行时间或用户反馈分数。每个交互的顺序(即,原始BERT中的位置ID)也可以作为一种行为相关的side信息。如果加入side信息,那么我们的交互就变为:
其中 表示用户 的第 个交互行为相关的side信息, 表示一个商品,包括了商品的ID和许多商品相关的成分 。商品相关的side信息是静态的,并且包含了每个特定商品的内部特征,所以我们的词典可以被重新表示为:
我们的目标是预测下一个商品的ID:
其中, 是潜在行为相关的side信息。
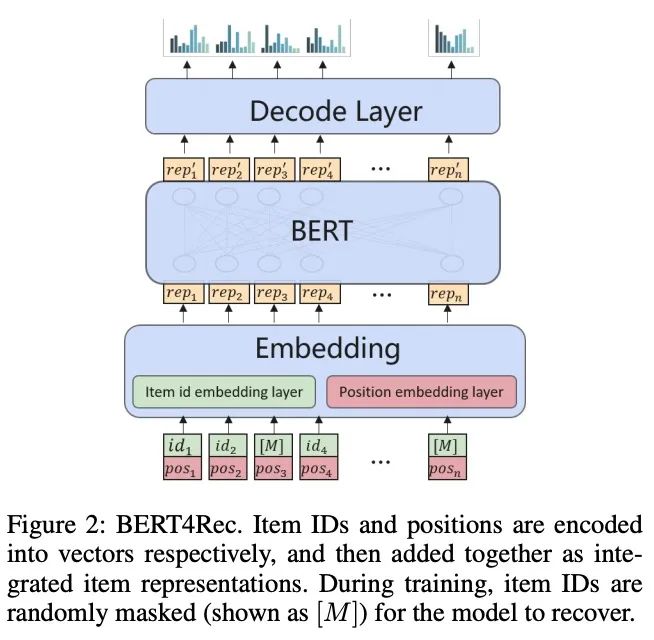
3.3 BERT和Invasive的self-attention
BERT4Rec是第一次将BERT框架用于序列化推荐任务的,并且取得了SOTA的效果,在BERT框架下面,Item被表示为向量,在训练的过程中,一些商品被随机mask掉,BERT模型需要尽力将它们的向量表示恢复过来,
其中 是softmax函数, 是比例因子。BERT使用encoder decoder的设计形式对每个输入的序列中的商品产出一个上下文的表示,BERT使用embedding层来存储 个向量,每个对应词典中的一个商品。
为了更好地使用side信息,传统方法经常会使用分开的embedding层来将side信息编码为向量,然后将它们fuse加入到ID的embedding中,
是用户 的第 个交互的集成embedding, 是embedding层,然后我们将集成的embedding序列输入到模型当中。
BERT使用self-attention机制来更新表示层,
我们知道self-attention操作是位置不变的函数,所以此处我们将位置embedding编码加入其中。也就是说,此处我们的BERT仅仅是将位置信息作为了side信息,并且使用addition作为fusion函数。
3.4 Non-invasive Self-attention
如果我们考虑端到端的BERT框架,它是一个自动编码器,具有堆叠的self-attention层。相同的embedding映射用于编码商品ID和解码还原的向量表示。因此,我们认为
invasive方法有复杂嵌入空间的缺点,
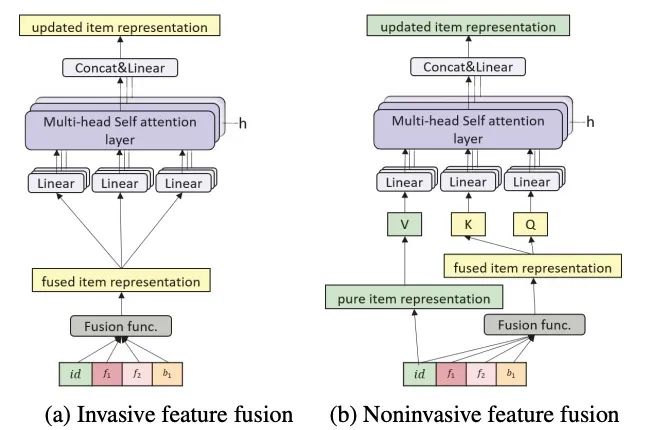
因为商品ID不可逆地与其他边信息融合。混合来自id的信息和其他辅助信息可能会使模型难以解码商品ID。对应地,我们提出了一种新的方法,即non-invasive自注意(NOVA),在利用side信息对序列进行更有效建模的同时,保持嵌入空间的一致性。其思路是:
修改自我注意机制,仔细控制自已组件的信息源,即Q、K和V
NOVA不仅是第3.3节中定义的集成嵌入E,还保留了纯ID嵌入的分支。
因此,对于NOVA,用户的历史由两个表示集合表示,纯ID embedding以及集成的embedding。
NOVA从集成的embedding R,来自于商品ID的emebdding 中计算Q和V,实践中,我们以张量的形式处理整条序列。
其中 是Batch size, 是序列长度, 是embedding向量的大小, NOVA可以被表示为:
其中 是通过线性转化得到:
NOVA和invasive方法的比较可以通过下图看到:
3.5 Fusion操作
NOVA和invasive方法在使用side信息下的不同在于,NOVA将其作为一个辅助的并通过fusion函数 将side信息作为Keys和Querys输入。此处我们定义concatfusion, 来将所有的side信息进行fusion,后面会接一个全链接层。
我们可以使用从上下文中提取可训练的系数来设计gating的fusion,
其中, 是所有特征的矩阵形式, , 是可训练的参数, 是被fused的特征向量的维度,
3.6 NOVA-BERT
每个NOVA层接受两个输入,
side信息
商品表示序列
然后输出相同形状的更新表示,再将这些表示输送送到下一层。
对于第一层的输入,商品表示是纯商品ID嵌入。由于我们只使用side信息作为辅助来学习更好的注意分布,side信息不会随着NOVA层传播。为每个NOVA层明确提供相同的side信息集。
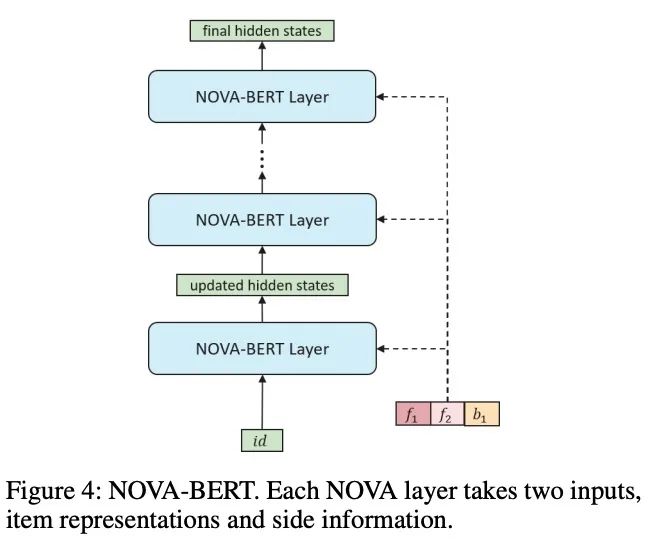
NOVA-BERT遵循原始的BERT框架,除了将self-attention层替换为了NOVA层之外,所以额外的参数和计算是可以忽略的。
我们认为,在NOVA-BERT算法中,隐藏表示保持在相同的嵌入空间中,这将使解码过程成为一个齐次向量搜索,有利于预测。
4. 实验
4.1 效果比较
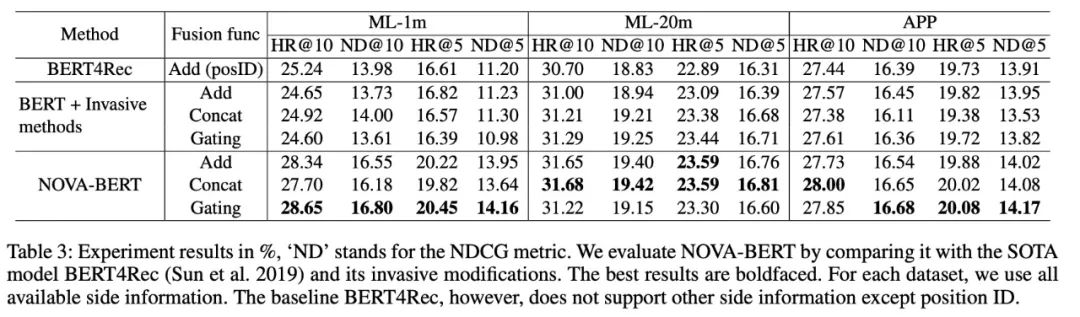
NOVA-BERT的效果比其它的都要好;
与Bert4Rec仅利用位置ID相比,invasive式方法使用了多种side信息,但改进非常有限甚至没有正向效果。相反,NOVA-BERT方法能有效地利用side信息,性能稳定,优于其他方法。
在我们实验中,发现越大的denser数据集,模型提升的幅度会下降;我们假设,在语料库更为丰富的情况下,这些模型甚至可以从商品的上下文中学习到足够好的商品embedding,从而为辅助信息的补充留下更小的空间。
NOVA-BERT的鲁棒性是非常好的;不管我们使用什么fusion函数,Nova-Bert的效果一直比baseline模型要好;
最佳融合函数可能取决于数据集。一般来说,gating方法具有很强的性能,这可能得益于其可训练的gating机制。结果还表明,对于实际部署,融合函数的类型可以是一个超参数,并应根据数据集的内在属性进行调整,以达到最佳的在线性能。
4.2 不同side信息的贡献
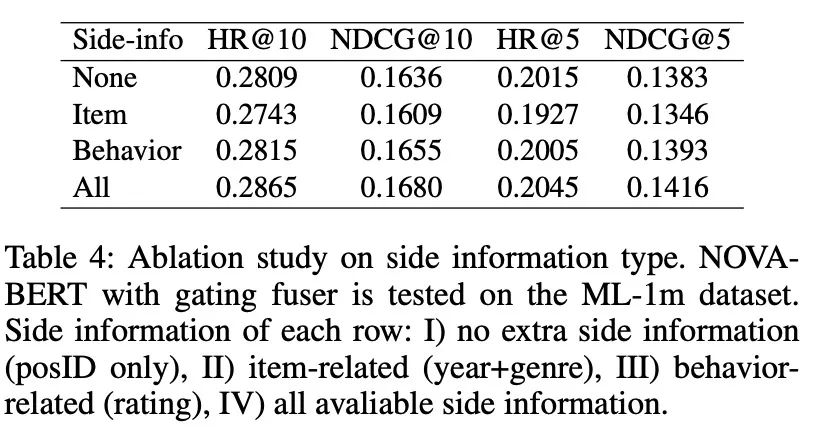
None:是原始的Bert+position ID;
商品相关和行为相关的side信息并未带来准确率的明显提升;
如果结合了与行为相关的side信息,则改进的效果明显大于其中任何一个带来的改进的总和;也就是说不同类型的side信息并不是独立的;
NOVA-BERT从综合信息中获益更多,并且有很强的能力利用丰富的数据而不受信息的困扰;
4.3 Attention 分布的可视化

NOVA-BERT的注意力得分在局部性方面表现出更强的模式,大致集中在对角线上。另一方面,在基线模型的图中没有观察到。
根据我们对整个数据集的观察,这种对比是普遍存在的。我们注意到侧边信息导致模型在早期层次形成更明显的attention。实验结果表明,NOVA-BERT算法以side信息作为计算attention矩阵的辅助工具,可以学习目标的注意分布,从而提高计算的准确性。
此外,我们也进行个案研究,以了解NOVA的注意分布,并进行更详细的分析。详情请参阅附录。
4.4 NOVA-BERT的部署和代价
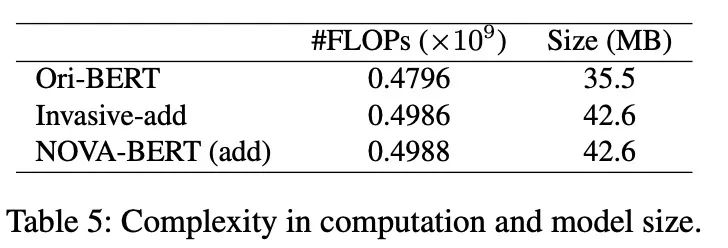
NOVA-BERT几乎没有额外的计算开销,与invasive方法的大小相同。
5. 结论
在本文中,我们提出了NOVA-BERT推荐系统和Non-invasive自我注意机制(NOVA)。提出的NOVA机制没有将sidw信息直接融合到商品表示中,而是利用side信息作为方向引导,保持商品表示在向量空间中不被掺杂。我们在实验数据集和工业应用两个方面对NOVA-BERT进行了评估,在计算和模型尺寸方面的开销可以忽略不计的情况下实现了SOTA性能。
参考文献

https://www.aaai.org/AAAI21Papers/AAAI-5262.LiuC.pdf
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









