






(FDSA)基于特征级的深度自注意力网络的序列化推荐
Abstract
序列化推荐的目的是推荐用户在不久的将来可能进行交互的下一项物品,在各种互联网应用中已经变得极为重要。现有的文章通常考虑的是物品之间的转换模式,但是忽略了物品的特征之间的转换模式。论文中认为仅仅物品级别的序列不能完全的揭示序列模式,而显式和隐式特征级序列可以帮助提取完整的序列模式。本文提出了一种基于特征级的深度自注意力网络的序列化推荐。FDSA首先通过vanilla注意力机制将物品的不同异构特征集成到具有不同权重的特征序列中。然后,FDSA分别对物品级序列和特征级序列应用自注意力块,对物品转换模式和特征转换模式分别进行建模。最后,将两个块的输出拼接起来输入一个全连接层做next item prediction。
Introduction
之前的序列化推荐大多用RNN来进行序列化建模,基于RNN的方法需要一步一步向前传递相关信息,这使得神经网络很难并行化。最近,自注意力网络在各种NLP任务中显示出良好的效果,自注意力网络的一个优点是通过计算一个序列中每对物品之间的注意权重来捕获长期依赖关系,很容易并行化并且捕捉长距离依赖。受到SAN的启发,Kan等人提出了SASRec,应用自注意力机制代替传统的RNN做序列化推荐,取得了SOTA。但是,它只考虑物品之间的顺序模式,而忽略了有助于捕获用户细粒度兴趣偏好的特征之间的顺序模式。
事实上,我们的日常活动经常呈现物品特征级别的转换模式。例如,用户在买了衣服之后更可能买鞋子,显示出了下一个产品的类别与当前产品的类别具有高度的相关性。在这里,我们将用户对结构化属性(例如类别)不断变化的需求称为显式的特征转换。此外,物品还可能包含一些非结构化属性,如描述文本或图像,这些属性表示物品的更多细节。因此,我们希望从这些非结构化属性中挖掘用户潜在的特征级别模式,我们称之为隐式特征转换。
创新点:
通过对物品序列和特征序列分别应用不同的自注意块,对显式和隐式特征转换进行建模。为了获得隐式的特征转换,增加了一种vanilla注意机制,以帮助基于特征的自注意力块自适应地从各种物品属性中选择重要的特征。
FDSA
1.问题定义
定义U = {u1, u2, u3,…, un}为用户集合,I = {i1, i2, …, im}为物品集合,N和M分别为用户数和物品数。S = {s1, s2, …, s|s|}表示用户之前与之交互的按时间顺序排列的物品序列。$ s_i\in\mathbb I $.每个物品i都有一些属性,比如目录,品牌和描述文本。以目录为例,物品i的目录标记为 $ c_i\in\mathbb C $, C是目录集合。序列推荐的目标是,根据用户与物品的历史交互信息,推荐用户可能交互的下一个项目。
2.模型结构
如图1,FDSA由5部分组成,Embedding layer, Vanilla attention layer, Item-based self-attention block, Feature-based self-attention block, 以及FFN。首先将稀疏的物品以及物品的离散属性映射到低维稠密向量。对物品的文本属性,利用主题模型提取关键词,然后利用word2vec获得关键词的文本向量表示。由于物品的特征通常是异构且来自于不同的域和数据类型。因此,我们利用vanilla注意机制来帮助自注意网络自适应地从物品的各种特征中选择重要的特征。之后,用户的序列模式通过两层的自注意力网络学习得到,物品级的序列和特征级的序列分开学习,不共用网络。最后,将两个自注意力块的输出拼接到一起输入到全连接层获得最后的预测结果。

2.1 Embedding Layer
由于用户的行为序列是不固定的,因此,我们从用户历史序列中取一个定长的序列 s = {s1, s2, …, sn}来计算用户的历史兴趣,n表示模型处理的最大序列长度。如果用户行为序列长度小于n,则在序列的左侧补0将用户行为序列变为定长。如果用户序列长度大于n,则取最近的n个历史行为序列。对特征序列的处理方式也一样。
2.2 Vanilla attention layer
因为物品的属性通常是异构的,很难知道那个特征决定用户的选择。因此,采用vanilla注意力机制帮助基于特征的自注意力网络捕捉用户对不同属性的不同偏好。给定一个物品i,它的属性可以被嵌入为
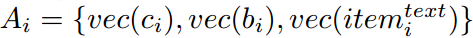
$ vec(c_i), vec(b_i) $ 分别表示物品i的category和brand的稠密向量表示。$ vec(item_i^{text}) $ 表示文本i的文本特征表示。注意力网络定义如下:
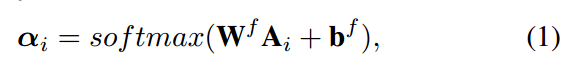
$ W^f $ 是一个dxd的矩阵,$ b^f $ 是一个b维的向量, 最后我们将第i项的特征表示计算为第i项的属性向量表示的和,并通过注意权重加权:$ f_i = \alpha_iA_i$
2.3 Feature-based self-attention block
两边自注意力网络的结构是一样的,这里就只介绍一种。给定一个用户,特征序列为
f
=
{
f
1
,
f
2
,
.
.
.
,
f
n
}
f = \{f_1, f_2, ..., f_n \}
f={f1,f2,...,fn} , 加入一个位置矩阵$ P \in\mathbb R^{n\times d}$到输入向量中,因此,featuee-based self-attention block的输入矩阵为:
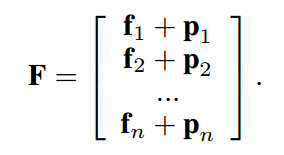
scaled dot-production attention(SDPA) 定义为:
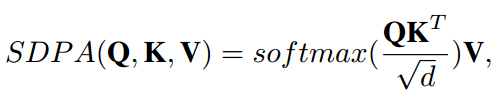
2.4 Item-based self-attention block
结构和上面类似,给定一个用户,可以得到相应矩阵为S的项动作序列s,从而构造堆叠的基于自注意块的输出如下:$ Q_s^{(q)} = S $, 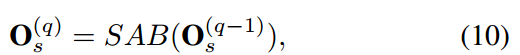
2.5 Fully-connected layer
为了同时捕获物品和特征的转换模式,我们将基于物品的自注意块的输出
Q
s
(
q
)
Q_s^{(q)}
Qs(q) 与基于特征的自注意块的输出 $ Q_f^{(q)} $ 串联起来,并将它们映射到一个全连接层中。
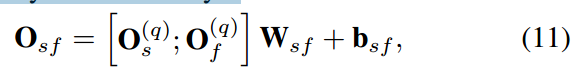
2.6 The Loss Function for Optimization
也是采用的二分类交叉熵损失函数:
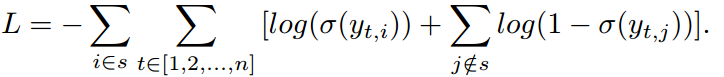
















 1080
1080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









